【算法】递归与分治策略
一、算法整体思想
一般情况下,问题的规模越大,解题所需的计算时间越长,并且解题的难度可能会变得很大。
问题的规模越小,解题所需的计算时间往往越短,也比较容易处理。
当直接解决一个较大的问题时,有时是相当困难的。
一个可能的做法是将一个难以直接解决的大问题,分割成一些规模较小的问题,以便各个击破,分而治之。
凡治众如治寡,分数是也;斗众如斗寡,形名是也。------孙子兵法
如果原问题可分割成k个子问题,1<k≤n,并且这些子问题都可解。
对k个子问题分别求解。
将求出的小规模的问题的解合并为一个更大规模的问题的解,自底向上逐步求出原来问题的解。
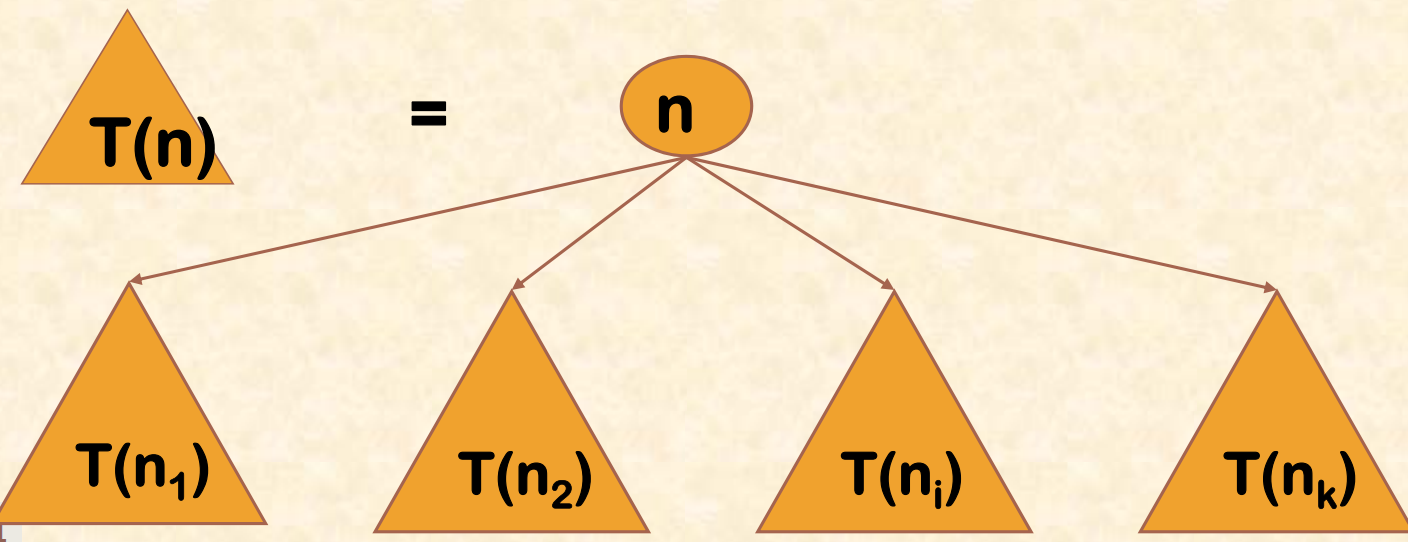
分治法的设计思想是,将一个难以直接解决的大问题,分割成一些规模较小的相同问题,以便各个击破,分而治之。
由分治法产生的子问题往往是原问题的较小模式,这就为使用递归技术提供了方便。在这种情况下,反复应用分治手段,可以使子问题与原问题类型一致而其规模却不断缩小,最终使子问题缩小到很容易直接求出其解。这自然导致递归过程的产生。
分治与递归像一对孪生兄弟,经常同时应用在算法设计之中,并由此产生许多高效算法。
二、递归的概念
在定义一个过程或函数时出现调用本过程或本函数的成分,称之为递归。
若调用自身,称之为直接递归。若过程或函数p调用过程或函数q,而q又调用p,称之为间接递归。
任何间接递归都可以等价地转换为直接递归。
在实际应用中,多为直接递归,也常简称为递归。
如果一个递归过程或递归函数中递归调用语句是最后一条执行语句,则称这种递归调用为尾递归。
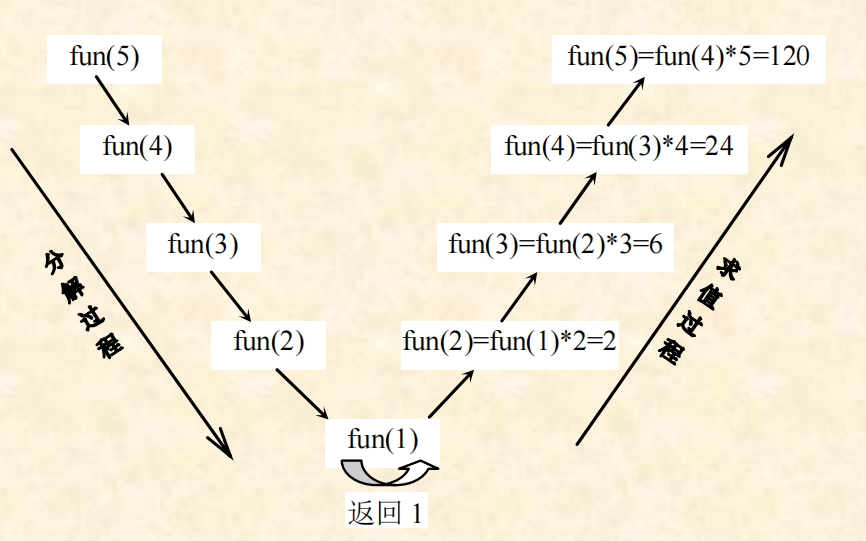
1. 示范案例:阶乘函数
设计求n!(n为正整数)的递归算法
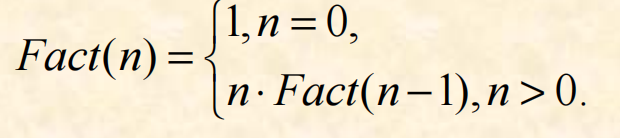
对应递归函数如下:
int fun(int n) {if (n==1) //语句1return(1); //语句2else //语句3return(fun(n-1)*n); //语句4
}
在该函数fun(n)求解过程中,直接调用fun(n-1)(语句4)自身,所以它是一个直接递归函数。
一般来说,能够用递归解决的问题应该满足以下三个条件:
- 需要解决的问题可以转化为一个或多个子问题来求解,而这些子问题的求解方法与原问题完全相同,只是在数量规模上不同。
- 递归调用的次数必须是有限的。
- 必须有结束递归的条件来终止递归。
2. 示范案例二:斐波那契(Fibonacci)数列
著名的意大利数学家斐波那契(Fibonacci)在他的著作《算盘书》中提出了一个“兔子问题”:假定小兔子一个月就可以长成大兔子,而大兔子每个月都会生出一对小兔子。如果年初养了一对小兔子,问到年底时将有多少对兔子?
(当然得假设兔子没有死亡而且严格按照上述规律长大与繁殖)

仔细研究上述表格,你会发现每一个月份的大兔数、小兔数与上一个月的数字有某种联系
“兔子问题”很容易列出一条递推式而得到解决。假设第N个月的兔子数目是Fib(N),我们有如下:
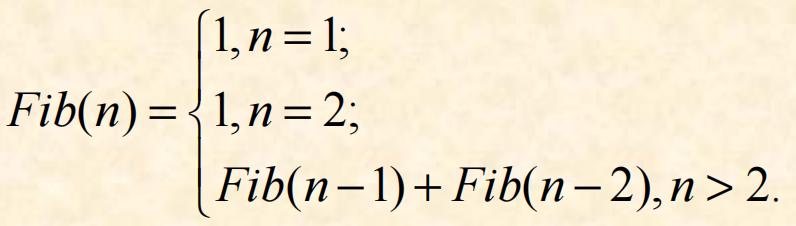
每月的大兔子数目一定等于上月的兔子总数,而每个月的小兔子数目一定等于上月的大兔子数目(即前一个月的兔子的数目)。
对应的递归函数如下:
int Fib(int n)
{
if ( n==1 ) return 1;
if ( n==2 ) return 1;
return Fib(n-1)+Fib(n-2);
}
自然界中 Fibonacci数列

3. 递归的数据结构
例如单链表就是一种递归数据结构,其结点类型声明如下
typedef struct LNode
{ElemType data;struct LNode *next;
} LinkList;
结构体LNode的定义中用到了它自身,即指针域next是一种指向自身类型的指针,所以它是一种递归数据结构。
4. 问题的求解方法是递归的
Hanoi塔问题求解
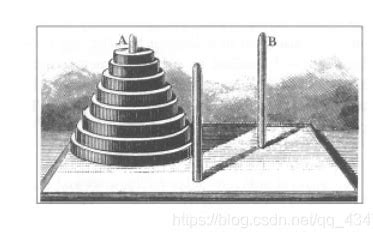
有3个塔座a、b、c和n个大小不同的圆盘片。盘片移动时必须遵守以下规则:每次只能移动一个盘片;盘片可以插在 a、b 和 c中任一塔座;
任何时候都不能将一个较大的盘片放在较小的盘片上。
Hanoi塔问题递归求解算法如下:
void hanoi(int n, int a, int b, int c) //n个盘片从a通过b移到c上
{if (n > 0){hanoi(n-1, a, c, b); //n-1个盘片从a通过c移到b上move(n, a, c); //第n个盘片从a移到c上hanoi(n-1, b, a, c); //n-1个盘片从b通过a移到c上}
}
当n=1时,直接从塔座a移到塔座c;
当n>1时,需要利用塔座b作为辅助,首先递归地将n-1个较小的圆盘片依照移动规则从塔座a移到塔座b上;接着将剩下的最大的圆盘片从塔座移到塔座c上;然后再递归地将n-1个较小的圆盘片依照移动规则从塔座b移到塔座c上。
Hanoi塔问题 递归求解算法的时间复杂度
设n个盘片的移动次数为T(n),根据递归算法,有
T(n) = 2 T(n - 1) + 1 ,
T(1) = 1
求解递推方程,得到
T(n) = 2n-1
假设1秒移1个盘子,64个盘片要多久? 5000亿年!
假设1秒移千万亿次,64个盘片要多久?4个多小时!
这是一个难解的问题,不存在多项式时间算法!
三、递归模型
递归模型是递归算法的抽象,它反映一个递归问题的递归结构。例如前面的递归算法对应的递归模型如下:

第一个式子给出了递归的终止条件,第二个式子给出了fun(n)的值与fun(n-1)的值之间的关系,我们把第一个式子称为递归出口,把第二个式子称为递归体。
一般地,一个递归模型是由递归出口和递归体两部分组成,前者确定递归到何时结束,后者确定递归求解时的递推关系。
递归出口的一般格式如下:
f(s1)=m1
这里的s1与m1均为常量,有些递归问题可能有几个递归出口。
1. 递归算法的执行过程
一个正确的递归程序虽然每次调用的是相同的子程序,但它的参量、输入数据等均有变化。
在正常的情况下,随着调用的不断深入,必定会出现调用到某一层的函数时,不再执行递归调用而终止函数的执行,遇到递归出口便是这种情况。
递归调用是函数嵌套调用的一种特殊情况,即它是调用自身代码。也可以把每一次递归调用理解成调用自身代码的一个复制件。
由于每次调用时,它的参量和局部变量均不相同,因而也就保证了各个复制件执行时的独立性。
系统为每一次调用开辟一组存储单元,用来存放本次调用的返回地址以及被中断的函数的参量值。
这些单元以系统栈的形式存放,每调用一次进栈一次,当返回时执行出栈操作,把当前栈顶保留的值送回相应的参量中进行恢复,并按栈顶中的返回地址,从断点继续执行。
特点:
每递归调用一次,就需进栈一次,最多的进栈元素个数称为递归深度,当n越大,递归深度越深,开辟的栈空间也越大。
每当遇到递归出口或完成本次执行时,需退栈一次,并恢复参量值,当全部执行完毕时,栈应为空
归纳起来,递归调用的实现是分两步进行的,第一步是分
解过程,即用递归体将“大问题”分解成“小问题”,直到递
归出口为止,然后进行第二步的求值过程,即已知“小问题”,
计算“大问题”。
在递归函数执行时,形参会随着递归调用发生变化,但每次调用后会恢复为调用前的形参,将递归函数的非引用型形参的取值称为状态。
递归函数的引用型形参在执行后会回传给实参,有时类似全局变量,不作为状态的一部分,在调用过程中状态会发生变化,而一次调用后会自动恢复为调用前的状态。
2.递归的效率很低,通常把递归算法转化为非递归算法
把递归算法转化为非递归算法有如下两种基本方法:
- 直接用循环结构的算法替代递归算法。
- 用栈模拟系统的运行过程,通过分析只保存必须保存的信息,从而
用非递归算法替代递归算法。
第(1)种是直接转化法,不需要使用栈。第(2)种是间接转化法,需要使用栈。
示例: n!的非递归算法fun(n)和采用循环结构求解的非递归算法fun1(n):
int fun(int n)
{if (n==1)return(1);elsereturn(fun(n-1)*n);
}
int fun1(int n)
{int f=1,i;for (i=2;i<=n;i++)f=f*i;return(f);
}
四、递归的优缺点
优点:结构清晰,可读性强,而且容易用数学归纳法来证明算法的正确性,因此它为设计算法、调试程序带来很大方便。
缺点:递归算法的运行效率较低,无论是耗费的计算时间还是占用的存储空间都比非递归算法要多。
五、分治算法 基本思想
将一个规模为n的问题分解成k个规模较小的子问题,这些子问题互相独立且与原问题相同。递归地解这些子问题,然后将各子问题的解合并得到原问题的解。
适用条件
- 问题的规模缩小到一定的程度就可以容易地解决;
- 问题可以分解为若干个规模较小的相同问题,即该问题具有最优
子结构性质; - 问题分解出的子问题的解可以合并为该问题的解;
- 问题所分解出的各个子问题是相互独立的,即子问题之间不包含
公共的子问题。
1. 分治法 启发式规则
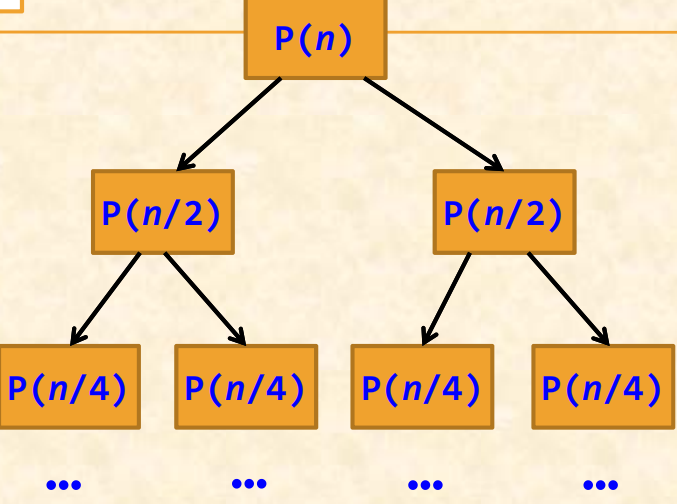
平衡子问题:最好使子问题的规模大致相同。将一个问题划分成大小相等的k个子问题(通常k=2,即二分法),这种使子问题规模大致相等的做法是出自一种平衡(Balancing)子问题的思想,它几乎总是比子问题规模不等的做法要好。
独立子问题:各子问题之间相互独立,这涉及到分治法的效
率,如果各子问题不是独立的,则分治法需要做许多不必要
的工作,重复地解公共的子问题。(此时虽然也可用分治法,但一般用动态规划较好。)
2. 分治法 求解过程
- 划分:既然是分治,当然需要把规模为n的原问题划分为k个规模较小的子问题,并尽量使这k个子问题的规模大致相同。
- 求解子问题:各子问题的解法与原问题的解法通常是相同的,可以用递归的方法求解各个子问题,有时递归处理也可以用循环来实现。
- 合并:把各个子问题的解合并起来,合并的代价因情况不同有很大差异,分治算法的有效性很大程度上依赖于合并的实现。
如果子问题的输入规模大致相等且一分为二,则分治法的计算时间可表示为:

T(n)是输入规模为 n 的分治法的计算时间;
g(n)是对足够小的 n 直接求解的时间;
f(n)是Merge的计算时间。
3.分治法 时间复杂度
假设一个分治法将规模为n的问题分成k个规模为n/m的子问题。为简单起见,设分解阈值n0=1,且adhoc解规模为1的问题耗费1个单位时间。再设将原问题分解为k个子问题以及用merge将k个子问题的解合并为原问题的解需用f(n)个单位时间。用T(n)表示该分治法解规模为|P|=n的问题所需的计算时间,则有
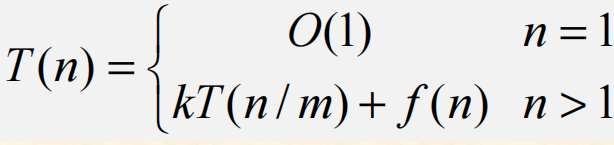
通过迭代法求得方程的解
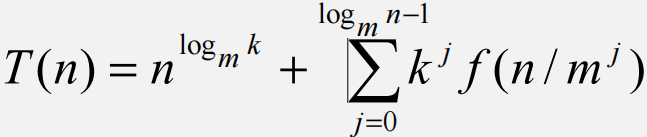
递归方程及其解只给出n等于m的方幂时T(n)的值,但是如果认为T(n)足够平滑,那么由n等于m的方幂时T(n)的值可以估计T(n)的增长速度。通常假定T(n)是单调上升的,从而当mi≤n<mi+1时,T(mi)≤T(n)<T(mi+1)。
在分析分治法的计算效率时,通常得到如下递归不等式:
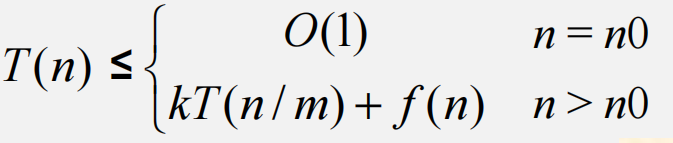
在讨论最坏情况下的计算时间复杂度时,等号或小于等于没有本质区别。
4. 递推方程 求解
在分析算法的效率时,通常得到如下形式的递归方程:
T(n) = a T(n/b) + f(n)
a:规约后的子问题的个数
n/b:规约后子问题的规模
f(n) :规约过程及组合子问题的解的工作量
T(n)如何求解,常见的求解方法有:
猜测法
迭代法
换元法
差消法
递归树
主定理
1. 二分搜索(检索/查找)/ 折半查找 技术
问题:给定已排序的n个元素a[0:n-1],在在这n个元素中找出一特定元素x。
方法1:顺序搜索,逐个比较a[0:n-1]中的元素,直到找到元素x或确定x不在其中。 顺序搜索法计算时间复杂性为O(n)
方法2:二分搜索算法
基本思路:设 a[low…high]是当前的查找区间,首先确定该区间的中点位置mid=(low+high)/2;然后将待查的k值与a[mid].key比较:
(1)若k==a[mid],则查找成功并返回该元素的物理下标;
(2)若k<a[mid],则由表的有序性可知a[mid…high]均大于k,因此若表中存在关键字等于k的元素,则该元素必定位于左子表a[low…mid-1]中,故新的查找区间是左子表a[low…mid-1];
(3)若k>a[mid],则要查找的k必在位于右子表a[mid+1…high]中,即新的查
找区间是右子表a[mid+1…high]。
下一次查找是针对新的查找区间进行的。
二分搜索(折半查找)算法实现(使用递归):
int BinSearch(int a[],int low,int high,int k)
//二分搜索/折半查找 算法
{ int mid;if (low<=high) //当前区间存在元素时{mid=(low+high)/2; //求查找区间的中间位置if (a[mid]==k) //找到后返回其物理下标midreturn mid;if (a[mid]>k) //当a[mid]>k时return BinSearch(a,low,mid-1,k);else //当a[mid]<k时return BinSearch(a,mid+1,high,k);}else return -1; //若当前查找区间没有元素时返回-1
}
二分搜索/折半查找算法的主要时间花费在元素比较上,对于含有n个元素的有序表,采用折半查找时最坏情况下的元素比较次数为C(n),则有:

折半查找的主要时间花在元素比较上,所以算法的时间复杂度为 O(log2n)
5. 二分归并排序
问题:将待排序元素分成大小大致相同的2个子集合,分别对2个子集合进行排序,最终将排好序的子集合合并成为所要求的排好序的集合。
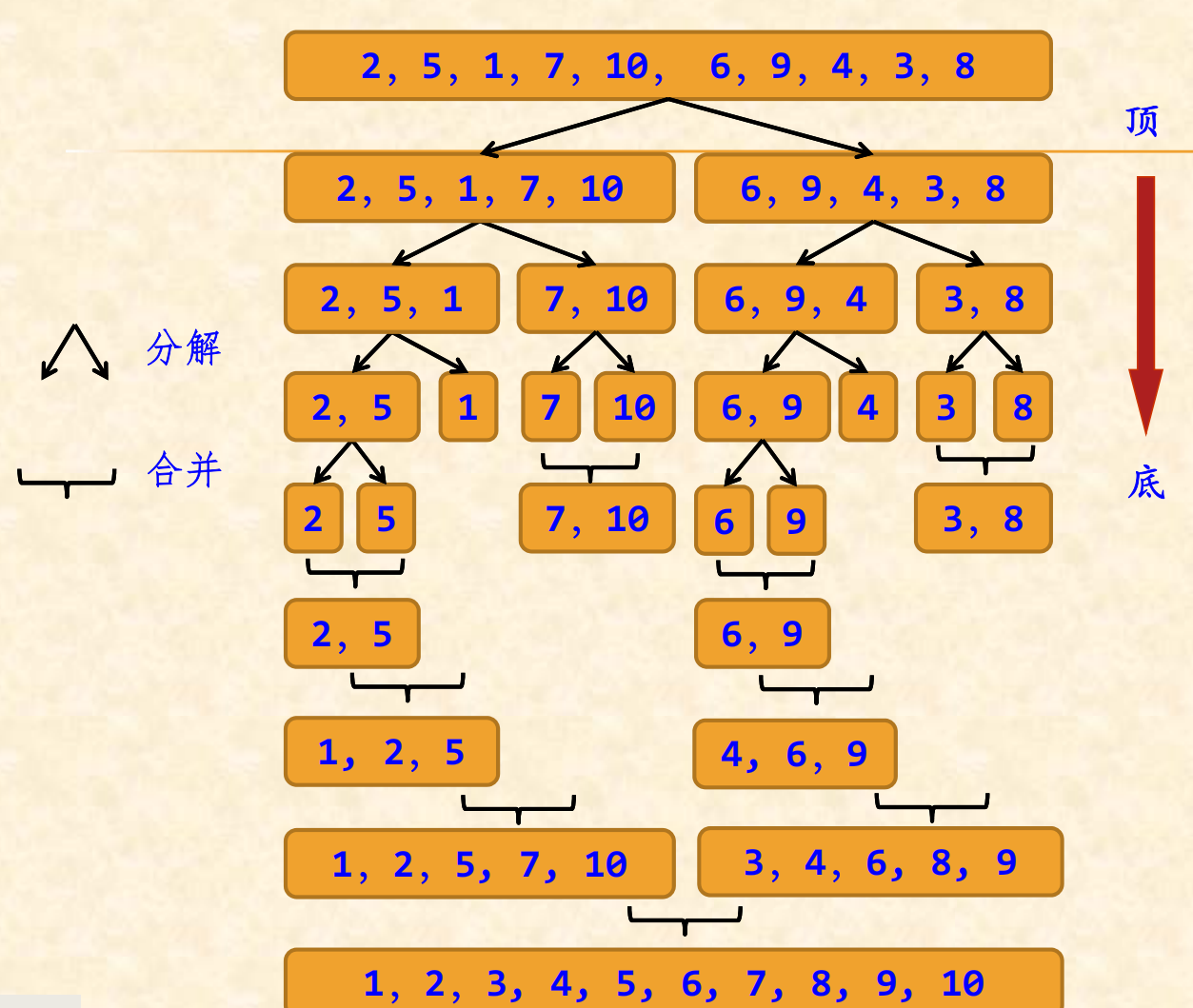
例如,对于{2,5,1,7,10,6,9,4,3,8}序列,说明其自顶向下
的二路归并排序的过程
设归并排序的当前区间是a[low…high],则递归归并的两个步骤如下:
-
分解:将序列a[low…high]一分为二,即求mid=(low+high)/2;递归地对两个子序列a[low…mid]和a[mid+1…high]进行继续分解。其终结条件是子序列长度为1(因为一个元素的子表一定是有序表)。
-
合并:与分解过程相反,将已排序的两个子序列a[low…mid]和a[mid+1…high]归并为一个有序序列a[low…high]。
对应的二分归并排序算法如下
void MergeSort(int a[],int low,int high)
//二分归并算法
{int mid;if (low<high) //子序列有两个或以上元素{mid=(low+high)/2; //取中间位置MergeSort(a,low,mid); //对a[low..mid]子序列排序MergeSort(a,mid+1,high); //对a[mid+1..high]子序列排序Merge(a,low,mid,high); //将两子序列合并,见前面的算法}
}
6. 快速排序
基本思想:
在待排序的n个元素中任取一个元素(通常取第一个元素)作为基准,把该元素放入最终位置后,整个数据序列被基准分割成两个子序列,所有小于基准的元素放置在前子序列中,所有大于基准的元素放置在后子序列中,并把基准排在这两个子序列的中间,这个过程称作划分。
然后对两个子序列分别重复上述过程,直至每个子序列内只有一个记录或空为止。
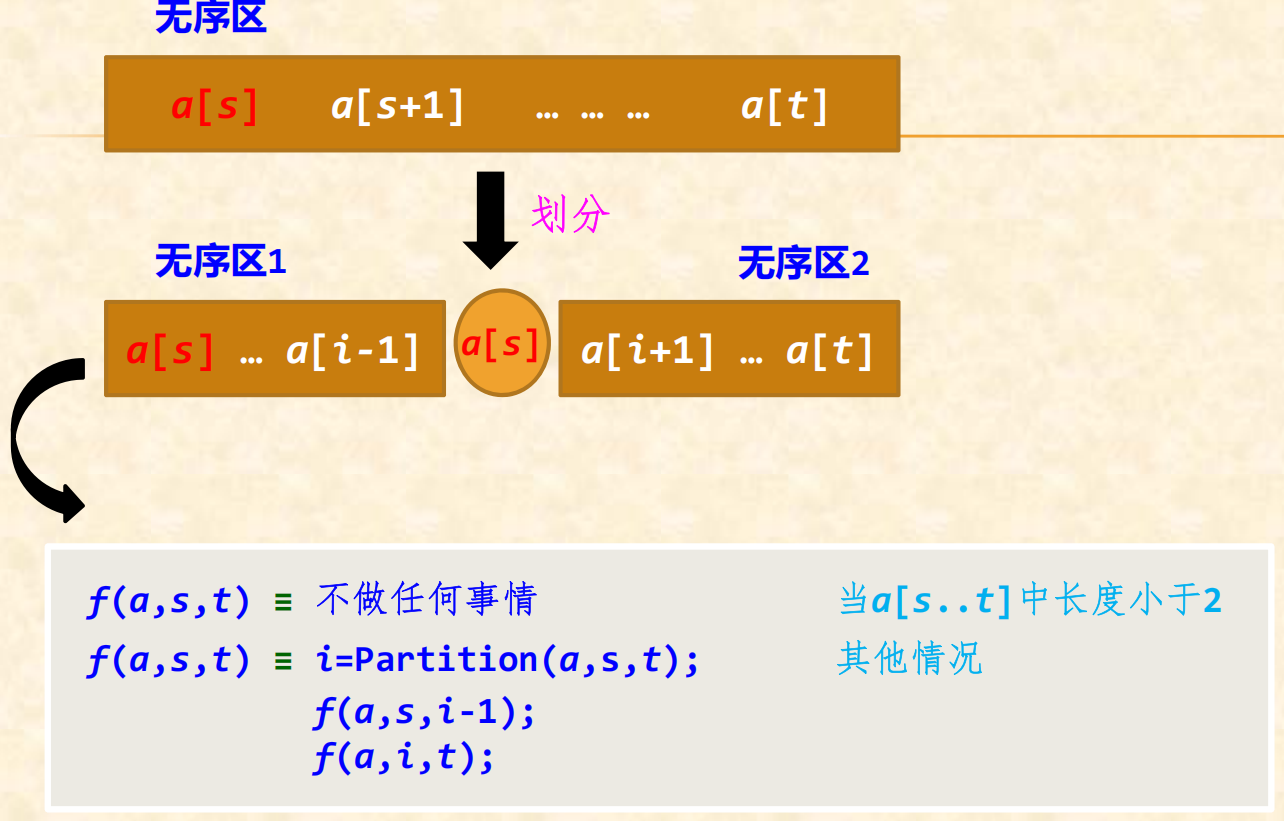
分治策略:
- 分解:将原序列a[s…t]分解成两个子序列a[s…i-1]和a[i+1…t],
其中i为划分的基准位置。 - 求解子问题:若子序列的长度为0或为1,则它是有序的,直接返回;
否则递归地求解各个子问题。 - 合并:由于整个序列存放在数组中a中,排序过程是就地进行的,合并
步骤不需要执行任何操作
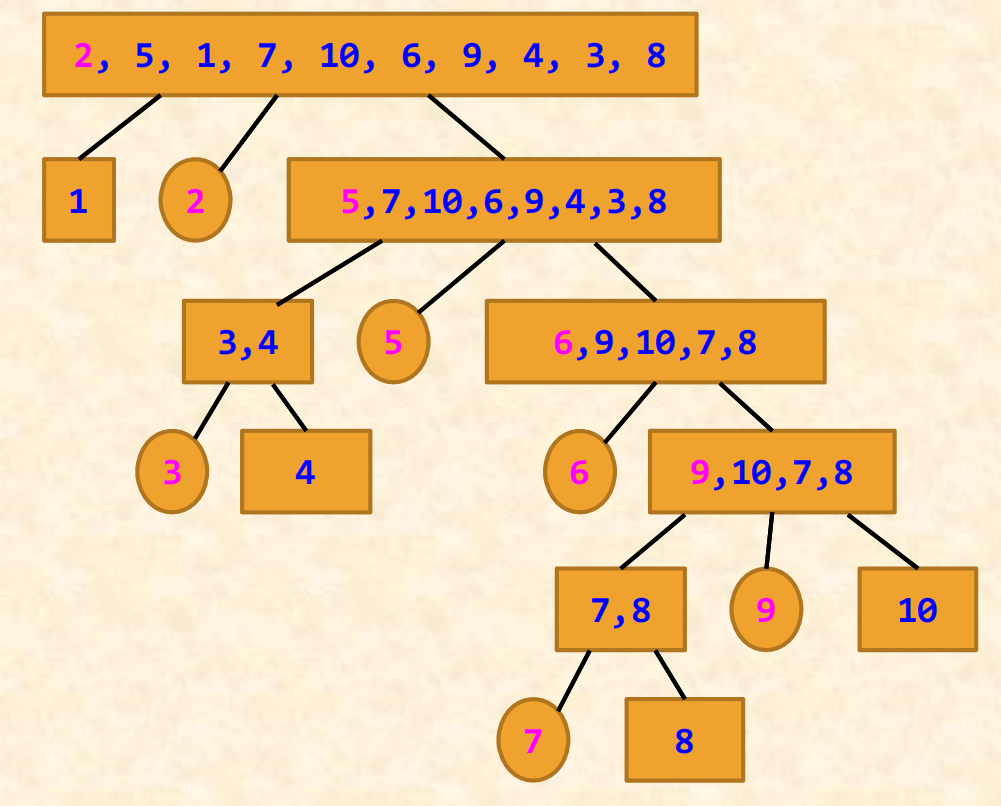
例如,对于{2,5,1,7,10,6,9,4,3,8}序列,其快速排序过程如下图所示。
快速排序算法:
int Partition(int a[],int s,int t) //划分算法
{int i=s,j=t;int tmp=a[s]; //用序列的第1个记录作为基准while (i!=j) //从序列两端交替向中间扫描,直至i=j为止{while (j>i && a[j]>=tmp) j--; //从右向左扫描,找第1个关键字小于tmp的a[j]a[i]=a[j]; //将a[j]前移到a[i]的位置while (i<j && a[i]<=tmp) i++; //从左向右扫描,找第1个关键字大于tmp的a[i]a[j]=a[i]; //将a[i]后移到a[j]的位置}a[i]=tmp;return i;
}
void QuickSort(int a[],int s,int t)
//对a[s..t]元素序列进行递增排序
{if (s<t) //序列内至少存在2个元素的情况{int i=Partition(a,s,t);QuickSort(a,s,i-1); //对左子序列递归排序QuickSort(a,i+1,t); //对右子序列递归排序}
}
算法分析:
快速排序的时间主要耗费在划分操作上,对长度为n的区间进行划分,共需n-1次关键字的比较,时间复杂度为O(n)
对n个记录进行快速排序的过程构成一棵递归树,在这样的递归树中,每一层至多对n个记录进行划分,所花时间为O(n)。当初始排序数据正序或反序时,此时的递归树高度为n,快速排序呈现最坏情况,即最坏情况下的时间复杂度为O(n2);当初始排序数据随机分布,使每次分成的两个子区间中的记录个数大致相等,此时的递归树高度为log2n,快速排序呈现最好情况,即最好情况下的时间复杂度为O(nlog2
n)。
快速排序算法的平均时间复杂度也是O(nlog2n)。
6. 求解 查找问题
查找最大和次大元素
问题:对于给定的含有n元素的无序序列,求这个序列中最大和次大的两个不同的元素。
例如:(2, 5, 1, 4, 6, 3),最大元素为6,次大元素为5
【问题求解】对于无序序列a[low.high]中,采用分治法求最大元素
max1和次大元素max2的过程如下:
- a[low.high]中只有一个元素:则max1=a[low],max2=-INF(-∞)(要求它们是不同的元素)。
- a[low.high]中只有两个元素:则max1=MAX{a[low],a[high]},
max2=MIN{a[low],a[high]}。 - a[low.high]中有两个以上元素:按中间位置mid=(low+high)/2划分为a[low…mid]和a[mid+1…high]左右两个区间(注意左区间包含a[mid]元素)。
求出左区间最大元素lmax1和次大元素lmax2,求出右区间最大元素rmax1和次大
元素rmax2。
合并:若lmax1>rmax1,则max1=lmax1,max2=MAX{lmax2,rmax1};否则
max1=rmax1,max2=MAX{lmax1,rmax2}。
void solve(int a[],int low,int high,int &max1,int &max2)
{if (low==high) //区间只有一个元素{ max1=a[low]; max2=-INF; }else if (low==high-1) //区间只有两个元素{ max1=max(a[low],a[high]); max2=min(a[low],a[high]); }else //区间有两个以上元素{int mid=(low+high)/2;int lmax1,lmax2;solve(a,low,mid,lmax1,lmax2); //左区间求lmax1和lmax2int rmax1,rmax2;solve(a,mid+1,high,rmax1,rmax2); //右区间求lmax1和lmax2if (lmax1>rmax1){max1=lmax1;max2=max(lmax2,rmax1); //lmax2,rmax1中求次大元素}else{max1=rmax1;max2=max(lmax1,rmax2); //lmax1,rmax2中求次大元素}}
}
7. 查找 一个序列中第k小元素
问题描述:对于给定的含有n元素的无序序列,求这个序列中第k(1≤k≤n)小的元素。
【问题求解】假设无序序列存放在a[0…n-1]中,若将a递增排序,则第k小的元素为a[k-1]。采用类似于快速排序的思想
对于序列a[s…t],在其中查找第k小元素的过程如下:将a[s]作为基准划分,其对应下标为i。
3种情况:
若k-1=i,a[i]即为所求,返回a[i]。
若k-1<i,第k小的元素应在a[s…i-1]子序列中,递归在该子序列中求解并返回其结果。
若k-1>i,第k小的元素应在a[i+1…t]子序列中,递归在该子序列中求解并返回其结果。
int QuickSelect(int a[],int s,int t,int k)
//在a[s..t]序列中找第k小的元素
{int i=s,j=t,tmp;if (s<t){tmp=a[s];while (i!=j) //从区间两端交替向中间扫描,直至i=j为止{while (j>i && a[j]>=tmp) j--;a[i]=a[j]; //将a[j]前移到a[i]的位置while (i<j && a[i]<=tmp) i++;a[j]=a[i]; //将a[i]后移到a[j]的位置}a[i]=tmp;if (k-1==i) return a[i];else if (k-1<i) return QuickSelect(a,s,i-1,k);//在左区间中递归查找else return QuickSelect(a,i+1,t,k);//在右区间中递归查找}else if (s==t && s==k-1) //区间内只有一个元素且为a[k-1]return a[k-1];
}
【算法分析】对于QuickSelect(a,s,t,k)算法,设序列a中含有n个元素,其比较次数的递推式为:
T(n)=T(n/2)+O(n)
可以推导出T
(n)=O(n),这是最好的情况,即每次划分的基准恰好是中位数,将一个序列划分为长度大致相等的两个子序列。
在最坏情况下,每次划分的基准恰好是序列中的最大值或最小值,则处理区间只比上一次减少1个元素,此时比较次数为O(n2)。
在平均情况下该算法的时间复杂度为O(n)。
六、改进分治法的途径
在分析算法的效率时,通常得到如下形式的递归方程:
T(n) = a T(n/b) + f(n)
a:规约后的子问题的个数
n/b:规约后子问题的规模
f(n) :规约过程及组合子问题的解的工作量
提高分治算法效率的方法
- 减少子问题的个数a,与 有关
- 增加预处理,减少f(n)