深入理解交叉熵损失函数——全面推演各种形式
带你从不一样的视角综合认识交叉熵损失,阅读这篇文章,帮你建立其分类问题,对比学习,行人重识别,人脸识别等问题的联系,阅读这篇文章相信对你阅读各种底层深度学习论文有帮助。
引言
1. 重新理解全连接层:不只是线性变换
1.1 全连接层的双重身份
1.2 几何直觉:相似度计算
1.2.1 输入特征矩阵 A(上左图)
1.2.2. 类别原型矩阵 B(上右图)
1.2.3. 相似度矩阵 X = A·B(下图)
1.2.4 几何解释
几何解释两向量夹角θ的余弦值即为相似度:编辑
1.3 分类的本质目标
2. 从损失函数设计需求到交叉熵
2.1 损失函数的设计原则
2.2 候选函数分析
2.3 Softmax交叉熵损失函数
2.4 对交叉熵损失的深度解释
2.4.1 梯度下降法
2.4.2 几何解释:
2.4.3 概率空间几何解释
2.4.4 海森矩阵与凸性分析
2.4.5 信息几何视角
2.4.6 梯度行为的深入分析
2.5 简单例子
3. 交叉熵的数值稳定性
3.1 数值不稳定的根本原因
3.1.1 理论分析
3.1.2 Softmax函数的数值问题
3.2 数值不稳定常见的PyTorch报错原因
3.2.1 数值溢出错误
3.2.2 梯度爆炸/消失
3.2.3 类别标签未定义错误
3.2.4 维度不匹配错误
3.3 数值不稳定的解决方案
3.3.1 使用数值稳定的实现
3.3.2 避免不稳定的做法
3.3.4 梯度裁剪
4. 对比学习中的交叉熵公式变体
4.1 重新审视分类:从原型对比到样本对比
4.1.1 分类任务的对比本质
4.1.2 从固定原型到动态样本
4.1.3 交叉熵的自然延伸
4.2 InfoNCE
4.2.1 从分类交叉熵到InfoNCE
4.2.2 温度参数τ的交叉熵理解
4.2.3 为什么使用 InfoNCE 进行大规模数据训练?
1. 类别爆炸问题
2. 负样本代替类别原型
3. 负样本过多但可采样处理
4. 端到端优化相似性度量
5. 适用于自监督与弱监督学习
4.3 监督对比学习:多正样本的交叉熵扩展
4.3.1 从单一正确答案到多个正确答案
4.3.2 多标签交叉熵的自然扩展
4.4 Circle Loss:重新参数化的交叉熵
4.4.1 从欧氏距离到余弦相似度
4.4.2 隐藏的二分类交叉熵结构
4.4.3 动态权重的交叉熵解释
4.5 Triplet Loss
4.6 小结
引言
当我们面对一个分类问题时,本质上是在高维特征空间中寻找合适的决策边界。神经网络通过多层特征提取,最终需要在最后一层做出分类决策。这个决策过程的核心就是全连接层+Softmax+交叉熵损失的组合。它不仅仅是数学公式,更是一个几何上的相似度匹配过程。
交叉熵损失函数(Cross-Entropy Loss)是深度学习中最重要的损失函数之一,几乎所有的分类任务都会用到它。本文深入探讨其背后的几何直觉、工程实现和现代应用。我想从实际写代码的角度来写一篇关于交叉熵的深入理解,可能与大多数介绍交叉熵的文字不同,但对于实际的代码编写尤其是理解各种复杂的交叉熵变体有一定帮助。
1. 重新理解全连接层:不只是线性变换
在深入交叉熵之前,我们可以重新认识下分类网络的最后一层——全连接层。
1.1 全连接层的双重身份
假设我们有一个分类网络,输入batch_size为b的图片,网络输出特征矩阵A ∈ R^(b×f),其中f是特征维度。全连接层的参数矩阵B ∈ R^(f×n),n是类别数。
# 伪代码示例
features = backbone(images) # A: [batch_size, feature_dim]
logits = fc_layer(features) # X = A @ B: [batch_size, num_classes]另一个视角的理解:矩阵B不仅仅是一个线性变换的参数,它也可以看坐上是一个分类器,存储着各个类别的典型特征向量。全连接层的权重矩阵B实际上存储了每个类别的"原型特征"。当我们计算时,实际上是在计算第i个样本与第j个类别原型的内积相似度。
- A[i]:第i个样本的特征向量
- B[:, j]:第j个类别的典型特征向量
- X[i, j] = A[i] · B[:, j]:第i个样本与第j个类别的相似度
1.2 几何直觉:相似度计算
如果我们对特征A和分类器B都进行L2归一化:
A_norm = F.normalize(A, dim=1) # 样本特征归一化
B_norm = F.normalize(B, dim=0) # 类别特征归一化
X = A_norm @ B_norm # 余弦相似度矩阵此时,X[i, j]就是第i个样本与第j个类别的余弦相似度,取值范围为[-1, 1]。
输入特征矩阵 A (b×f) 类别原型矩阵 B (f×n)[A₁₁ A₁₂ ... A₁f] [B₁₁ B₁₂ ... B₁n][A₂₁ A₂₂ ... A₂f] [B₂₁ B₂₂ ... B₂n][ ... ... ... ...] × [ ... ... ... ...][Ab₁ Ab₂ ... Abf] [Bf₁ Bf₂ ... Bfn]│ │└─────────┬───────────┘↓相似度矩阵 X = A·B (b×n)[X₁₁ X₁₂ ... X₁n][X₂₁ X₂₂ ... X₂n][ ... ... ... ...][Xb₁ Xb₂ ... Xbn]其中 X[i,j] = A[i]·B[:,j] = ‖A[i]‖‖B[:,j]‖cosθ直观图解:
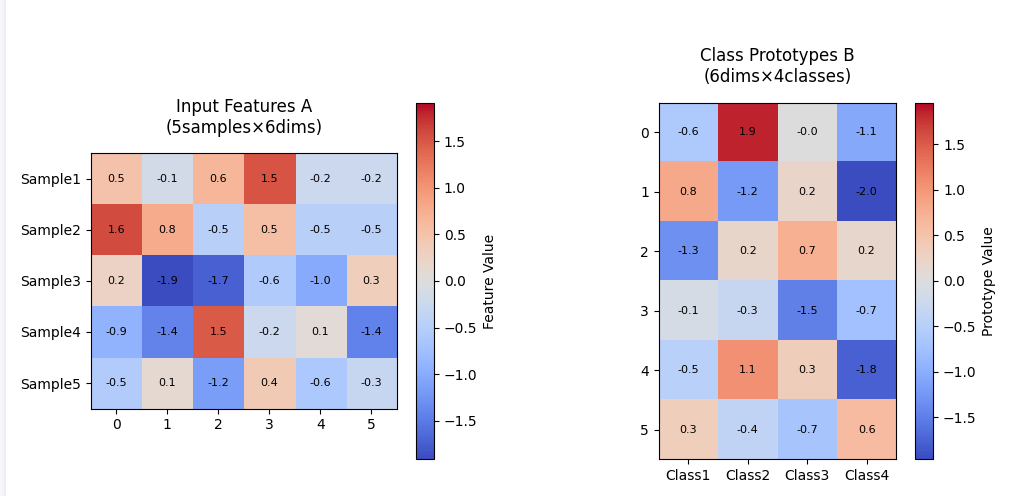
1.2.1 输入特征矩阵 A(上左图)
-
数据结构
-
行(S1-S5):5个样本的特征向量
-
列(F1-F6):6维特征空间
-
示例值范围:-1.5 ~ +1.5(随机生成)
-
-
关键说明
-
颜色映射:
🔵 蓝色 → 负值特征(如F2列S3样本的-1.0)
🔴 红色 → 正值特征(如F5列S1样本的+1.3)
⚪ 白色 → 接近零的值(如F3列S2样本的0.1) -
物理意义:展示原始数据经过神经网络提取后的特征分布
-
1.2.2. 类别原型矩阵 B(上右图)
-
核心概念
-
列向量(C1-C4):每个类别对应的"典型特征模板"
-
行方向:与输入特征维度完全对齐(F1-F6)
-
-
学习机制
-
训练过程中,B矩阵通过梯度下降自动更新
-
例如C3列的F4特征值为+1.2 → 表示该类在F4维度有强正相关性
-
可视化价值:直接观察模型学到的类别判别特征
-
1.2.3. 相似度矩阵 X = A·B(下图)
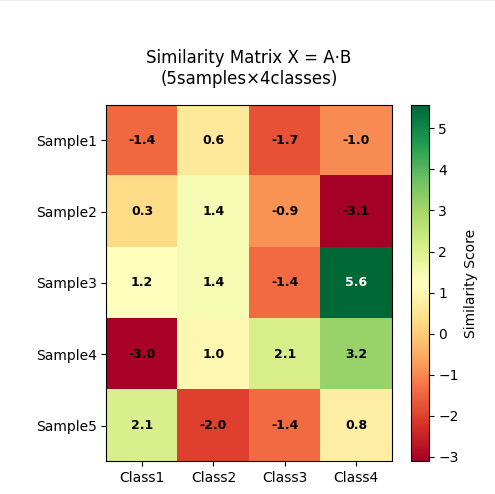
-
计算原理
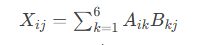
-
每个元素表示样本与类别的匹配得分
-
-
决策解读
-
颜色编码:
🟢 深绿 → 高相似度(如S4行C3列的2.8分)
🟡 黄色 → 中等相似度(如S2行C1列的0.5分)
🔴 红色 → 低相似度(如S5行C4列的-1.2分) -
分类规则:每行取最大值所在列(如S1应归为C2类)
-
1.2.4 几何解释
想象在一个3D特征空间中:
- 每个样本是空间中的一个点
- 每个类别原型是从原点出发的一个向量
- 内积
衡量样本向量与类别向量的"对齐程度"
类别A原型 ↗| θ| ←── 夹角越小,相似度越高|
样本点 ----+在机器学习中,当对特征向量A和B进行L2归一化处理后,它们的相似度度量即等价于余弦相似度:sim(A,B)=cosθ,其中θ表示两个向量之间的夹角。深度神经网络的核心目标在于学习能够有效表征样本本质特征的特征向量空间,而分类层中的权重向量则可视为各类别的原型表征(prototype representation)。通过设计适当的损失函数,模型能够优化网络参数,使得在特征空间中:1)样本特征向量与其对应类别原型的相似度最大化;2)与其它类别原型的相似度最小化。这种优化过程实质上是在构建一个具有良好判别性的特征空间几何结构,其中类内样本紧凑聚集在其类别原型周围,而不同类别的原型则保持足够的分离度。
这种可视化结果见下图
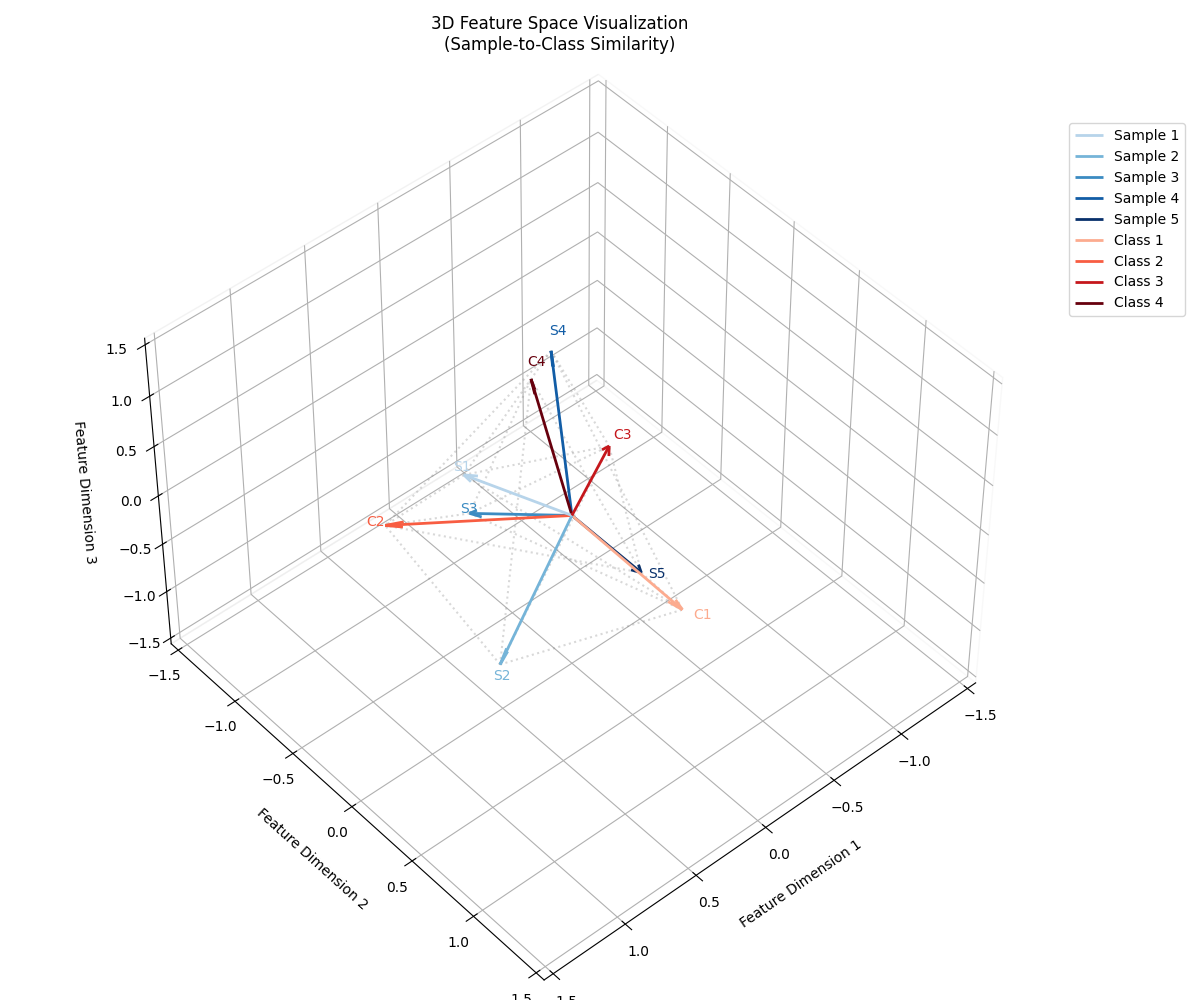
-
可视化要素
-
箭头起点:坐标原点 (0,0,0)
-
箭头方向:样本在3D特征空间的投影(取前3维)
-
-
归一化处理
S2向量=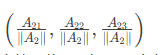
所有向量长度统一为1,便于观察角度关系
几何解释
两向量夹角θ的余弦值即为相似度: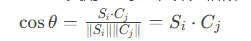
-
-
强匹配:虚线短且夹角小 → 高置信度分类
-
弱匹配:虚线长且夹角大 → 可能分类错误
-
对抗情况:夹角>90° → 负相关(需梯度修正)
-
-
训练目标
通过损失函数迫使:-
同类样本-原型夹角 → 0°
-
异类样本-原型夹角 → 180°
-
1.3 分类的本质目标
对于分类任务,我们希望:
- 正样本相似度最大:对于第
i个样本(真实类别为y_i),X[i,yi] 应该是 X[i,:] 中的最大值。 - 负样本相似度非最大:不强制要求其他类别的相似度很小,只要它们不超过正样本的相似度即可。
数学表达:
![]()
这一目标将指导我们设计损失函数(如交叉熵损失),通过优化各中间矩阵来实现分类。
2. 从损失函数设计需求到交叉熵
2.1 损失函数的设计原则
一个好的分类损失函数应该满足:
- 区分正确与错误:分类正确时损失小,错误时损失大
- 反映错误程度:预测置信度越低,损失越大
- 提供合适梯度:在不同错误程度下提供不同强度的梯度信号
2.2 候选函数分析
假设某个样本属于类别0,模型预测它属于类别0的概率为p,我们需要一个关于p的损失函数。
候选函数比较:
| 函数 | 表达式 | p=0.1时损失 | p=0.01时损失 | 梯度表达式 | 梯度特性 |
|---|---|---|---|---|---|
| 1-p | 1−p | 0.9 | 0.99 | −1 | 恒定梯度 |
| exp(-p) | e−p | 0.905 | 0.990 | −e−p | 衰减梯度 |
| -log(p) | −lnp | 2.30 | 4.61 | −1/p | 自适应梯度 |
-log(p)的优势:
- 当p → 0时,损失 → ∞,提供强烈的纠正信号
- 当p → 1时,损失 → 0,符合预期
- 梯度为-1/p,预测越错梯度越大
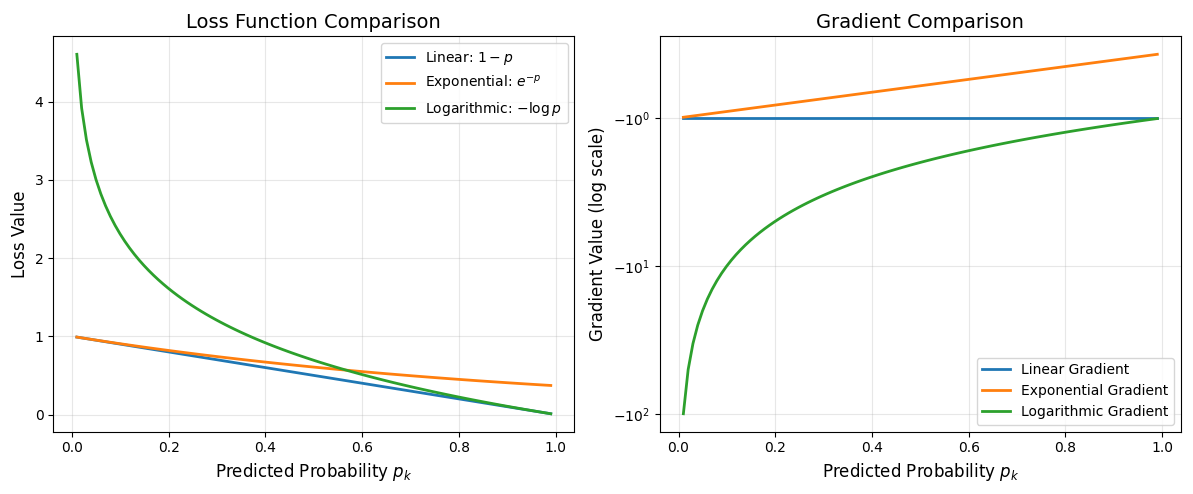
2.3 Softmax交叉熵损失函数
在全连接层的输出中,我们得到了一个相似度矩阵 X其中 表示第 i个样本与第 j个类别的相似度,然而,相似度的值范围可能很大(尤其是未归一化时),直接用于损失计算会导致数值不稳定。因此,我们需要将相似度转换为概率分布。
Softmax函数的作用正是将相似度映射为概率分布:

Softmax通过指数函数放大相似度差异,再归一化,使得最大相似度对应的概率接近1,其余接近0。这种特性非常适合分类任务。
交叉熵用于衡量模型预测概率分布 P 与真实标签分布 Y 的差异,原始的交叉熵损失定义如下
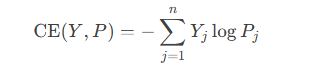
对于Softmax交叉熵损失:
其中: -是logits(未归一化的模型输出) -
是真实类别(one-hot编码) -
是softmax概率
梯度推导:
第一项梯度:
第二项梯度:
合并梯度:
矩阵形式:
其中, -
是one-hot标签向量
梯度解释:
|(真实类别) |
| 预测概率
越接近1,梯度越小 | |
(其他类别) |
越大,梯度越大 |
在反向传播中:
2.4 对交叉熵损失的深度解释
2.4.1 梯度下降法
从最速下降法的角度看,真实类别方向, 因为
,所以
,梯度始终为负值,负梯度方向:
,意味着需要增大
,:
,
为学习率。 - 当预测概率
较小时(如0.2),梯度
→ 大幅增加
,当
时,梯度
→ 停止更新。
对 (
)的梯度,
,
,则起到减小错误类别的logit值的作用。
是logits向量
中对应真实类别的分量:
-:模型最后一层的原始输出(未归一化)
-
-
为什么需要增大
| 数学机制 | 实际影响 | 理论保证 |
|----------------------------|--------------|-------------------|
|| 增大分子 | 单调递增函数 |
|| 提高
| 概率归一化 |
|| 降低损失 | 极大似然估计 |
举个例子:
假设:
- 当前logits:(3分类)
- 真实类别
- 计算得softmax:
梯度计算:
更新过程():
X_new = [2.0 - 0.1*(-0.35),
1.0 - 0.1*0.24,
0.5 - 0.1*0.11]
= [2.035, 0.976, 0.489]可见:
- (第一个元素)确实增大,(因为它的真实类别是第0类)
- 其他减小
由此softmax起到了预期的作用。
2.4.2 几何解释:
回顾交叉熵的原始定义为:
梯度为:
-
正样本梯度:Pk−1(负值,推动增加 Xy)
-
负样本梯度:Pk(正值,推动减少 Xk)
广义的交叉熵的矩阵计算示意图如下,第一列表示真实的标签值Y,它是一个分布,即当前样本属于各个类别的概率(与硬分类不同,它在许多场景中是有用的),第二列P是当前样本经过神经网络和全连接层后预测的类别的概率(softmax结果),第3列为Y*log(Pju)的计算值。
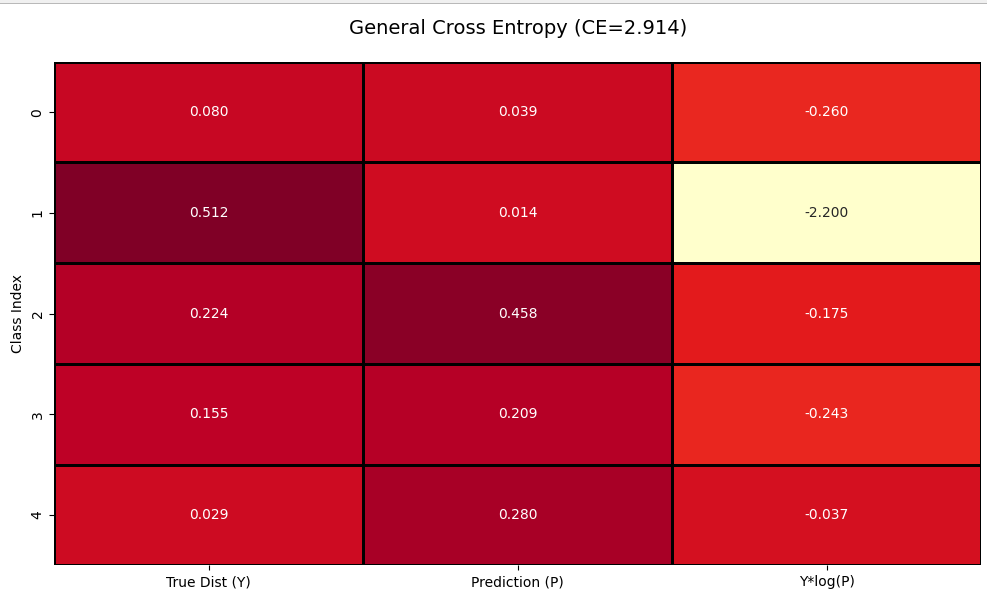
在上面的定义中,真实标签分布 Y 不是非0即1的,这样对于每个预测标签都需要算损失。
它的一个经典应用就是平滑标签的交叉熵损失,在非监督学习领域,由于标签存在噪声,往往使用平滑的标签,效果图如下:
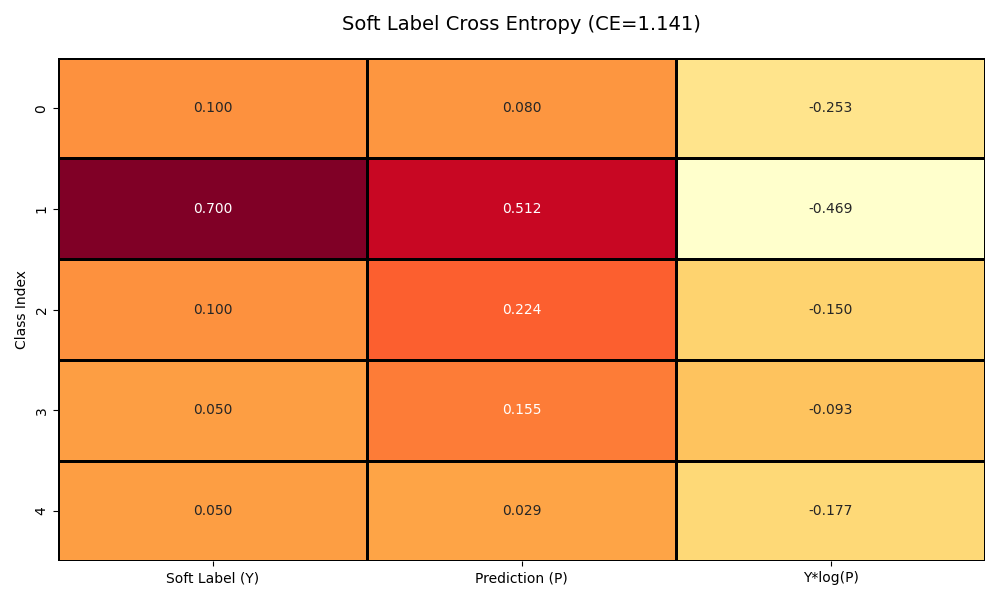
而在一般情况下,我们往往使用的是硬标签损失,而对于硬标签(one-hot编码),真实分布 Y 仅在真实类别位置为1,其余为0。由于 Y是one-hot向量,实际计算简化为:

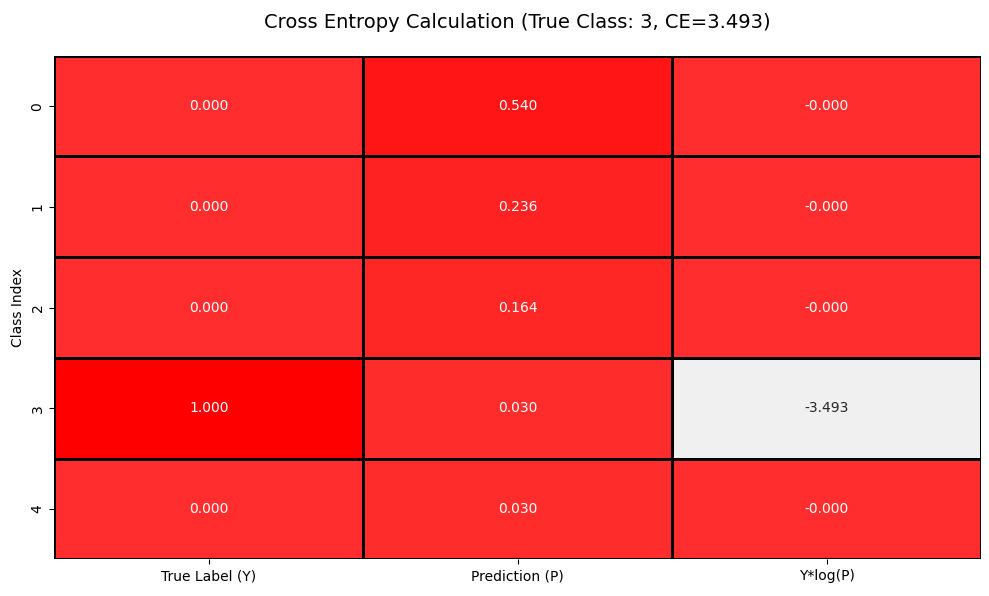
可以观察到它的计算发生了简化。
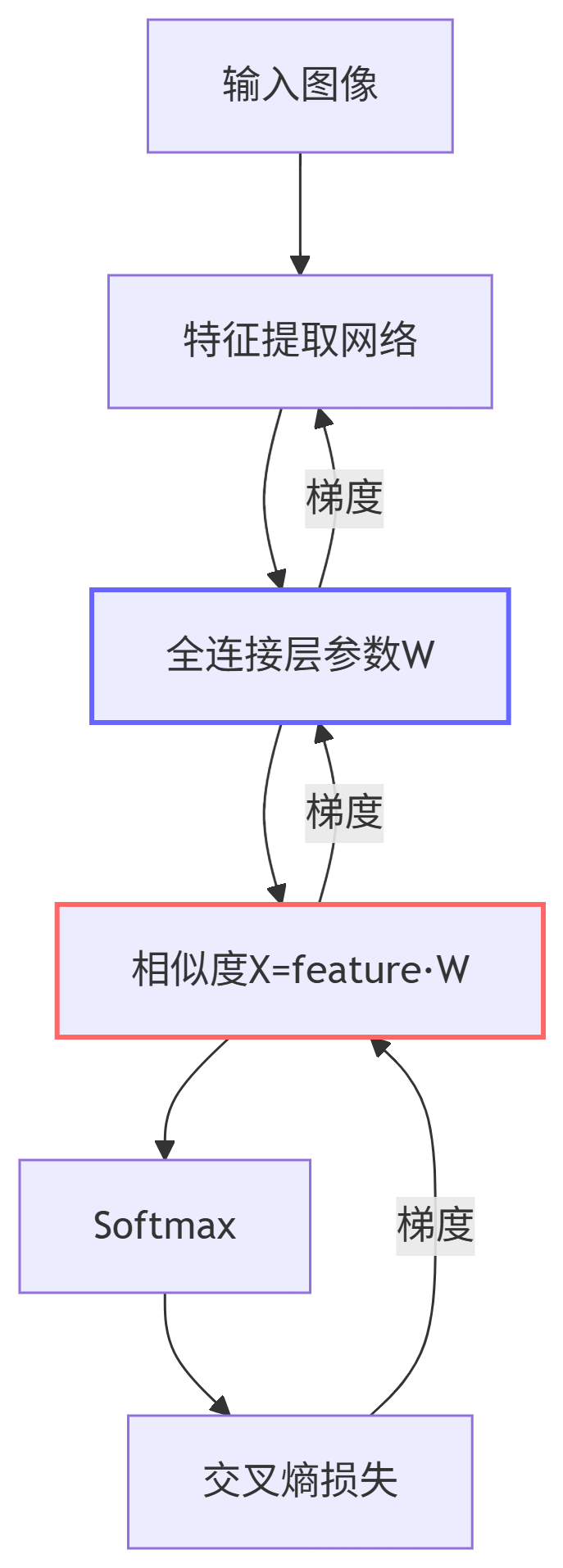
我们总结下交叉熵计算流程:
-
输出数据经过神经网络得到每个样本的特征向量Feature
-
特征向量与全连接层进行矩阵乘法得到相似度矩阵 X(样本与类别的相似度)。
-
Softmax将 X 转换为概率分布 P。
-
交叉熵衡量 P 与真实分布 Y 的差异。
2.4.3 概率空间几何解释
在概率单纯形中:
- 梯度指向真实类别顶点方向
- 更新使预测分布向真实分布
移动
- 当时达到全局最优(梯度为0)
2.4.4 海森矩阵与凸性分析
二阶导数:
海森矩阵的性质:
1. 半正定性:
2. 说明损失函数是凸的
3. 保证梯度下降能收敛到全局最优
2.4.5 信息几何视角
从KL散度角度看:
梯度更新最小化真实分布与预测分布
之间的KL散度。
2.4.6 梯度行为的深入分析
2.4.6.1 学习动态
| 情况 | 梯度行为 | 学习效果 |
|-----------------------------|----------------------|-------------------------|
| | 大梯度 (
) | 快速增强正确类别 |
| | 小梯度 (
) | 微调 |
| (错误类别) | 正梯度 | 强烈抑制 |
2.4.3.2 梯度饱和问题
当时:
- 梯度
- 可能导致学习停滞
- 解释为什么需要适当的权重初始化
2.4.3.3 与Margin的联系
梯度更新隐式地最大化:
即推动正确类别的logit比其他类别大至少一个margin。
2.4.3.4. 实际训练中的意义
1. **类间竞争**:softmax的梯度自动保持
2. **自适应学习**:梯度与预测误差成比例
3. **概率校准**:推动预测概率反映真实置信度
2.5 简单例子
全连接层输出的相似度矩阵 X∈Rb×n 需要通过Softmax转换为概率分布。我们通过具体例子说明:
例子1:假设batch中有1个样本,输出3个类别的相似度:
Softmax计算过程:
对于真实类别为"猫"(类别0)的情况:
交叉熵计算:
对比错误预测时的表现:
则预测结果与真实结果相差越大CE的损失值越高。
3. 交叉熵的数值稳定性
交叉熵损失函数在深度学习中广泛应用,但在实际计算过程中容易出现数值不稳定问题。本章将详细分析这些问题的成因、表现形式以及解决方案。
3.1 数值不稳定的根本原因
3.1.1 理论分析
交叉熵损失函数的数学表达式为
L = -∑(i=1 to N) y_i * log(p_i)其中:
y_i是真实标签的one-hot编码p_i是模型预测的概率分布
数值不稳定主要源于以下几个方面:
- 对数函数的特性:当
p_i接近0时,log(p_i)趋向于负无穷 - 指数函数的溢出:在softmax计算中,
exp(x)当x很大时会溢出 - 浮点数精度限制:计算机表示浮点数的精度有限
3.1.2 Softmax函数的数值问题
Softmax函数定义为
softmax(x_i) = exp(x_i) / ∑(j=1 to K) exp(x_j)当输入值很大时,指数函数会导致数值溢出;当输入值很小或负数绝对值很大时,会导致下溢。
3.2 数值不稳定常见的PyTorch报错原因
3.2.1 数值溢出错误
import torch
import torch.nn as nn# 模拟极端情况下的logits
logits = torch.tensor([[100.0, 200.0, 150.0]], requires_grad=True)
targets = torch.tensor([1])criterion = nn.CrossEntropyLoss()
loss = criterion(logits, targets)典型报错信息:
RuntimeError: result type Float can't be cast to the desired output type Long
# 或者
RuntimeError: CUDA error: an illegal memory access was encountered
# 或者出现 NaN 值
tensor(nan, grad_fn=<NllLossBackward>)3.2.2 梯度爆炸/消失
# 梯度爆炸示例
logits = torch.tensor([[1e10, 1e5, 1e8]], requires_grad=True)
targets = torch.tensor([0])criterion = nn.CrossEntropyLoss()
loss = criterion(logits, targets)
loss.backward()print(f"梯度值: {logits.grad}")
# 输出可能是: tensor([[nan, nan, nan]])3.2.3 类别标签未定义错误
# 错误的标签索引
logits = torch.randn(2, 3) # 3个类别
targets = torch.tensor([1, 5]) # 标签5超出了类别范围[0,2]criterion = nn.CrossEntropyLoss()
loss = criterion(logits, targets)3.2.4 维度不匹配错误
# 维度不匹配
logits = torch.randn(4, 10) # batch_size=4, num_classes=10
targets = torch.randn(4, 10) # 错误:应该是类别索引,不是概率分布criterion = nn.CrossEntropyLoss()
loss = criterion(logits, targets)3.3 数值不稳定的解决方案
数值不稳定往往表现为梯度异常或损失值异常
3.3.1 使用数值稳定的实现
PyTorch的nn.CrossEntropyLoss内部已经实现了数值稳定的版本,它直接从logits计算,避免了显式的softmax计算:
import torch
import torch.nn as nn
import torch.nn.functional as F# 推荐的稳定做法
def stable_cross_entropy_example():"""演示数值稳定的交叉熵计算"""logits = torch.tensor([[100.0, 200.0, 150.0],[50.0, 75.0, 25.0]])targets = torch.tensor([1, 0])# 方法1: 使用nn.CrossEntropyLoss (推荐)criterion = nn.CrossEntropyLoss()loss1 = criterion(logits, targets)# 方法2: 使用F.cross_entropy (等价)loss2 = F.cross_entropy(logits, targets)# 方法3: 手动实现稳定版本log_softmax = F.log_softmax(logits, dim=1)loss3 = F.nll_loss(log_softmax, targets)print(f"nn.CrossEntropyLoss: {loss1.item():.6f}")print(f"F.cross_entropy: {loss2.item():.6f}")print(f"手动稳定实现: {loss3.item():.6f}")stable_cross_entropy_example()3.3.2 避免不稳定的做法
# ❌ 不稳定的做法
def unstable_implementation(logits, targets):"""不推荐的不稳定实现"""softmax_probs = F.softmax(logits, dim=1)log_probs = torch.log(softmax_probs) # 这里可能出现log(0)return F.nll_loss(log_probs, targets)# ✅ 稳定的做法
def stable_implementation(logits, targets):"""推荐的稳定实现"""return F.cross_entropy(logits, targets)3.3.4 梯度裁剪
def training_with_gradient_clipping():"""带梯度裁剪的训练示例"""# 模拟模型和数据model = nn.Linear(10, 3)optimizer = torch.optim.Adam(model.parameters(), lr=0.01)criterion = nn.CrossEntropyLoss()# 模拟一个batch的数据inputs = torch.randn(32, 10)targets = torch.randint(0, 3, (32,))# 前向传播outputs = model(inputs)loss = criterion(outputs, targets)# 反向传播optimizer.zero_grad()loss.backward()# 梯度裁剪torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)# 参数更新optimizer.step()print(f"损失值: {loss.item():.6f}")# 检查梯度for name, param in model.named_parameters():if param.grad is not None:grad_norm = torch.norm(param.grad).item()print(f"{name} 梯度范数: {grad_norm:.6f}")training_with_gradient_clipping()4. 对比学习中的交叉熵公式变体
注意,本节不在于揭示各不同损失函数的统一性,而是帮助读者用联系的观点看待这些不同问题,这对于编程和写论文是由帮助的。
4.1 重新审视分类:从原型对比到样本对比
4.1.1 分类任务的对比本质
在深入对比学习之前,让我们重新审视传统分类任务。回顾第1章中全连接层的几何直觉,我们发现分类本质上也可以看出一种特殊对比过程:
传统分类:样本 vs 类别原型
X = A · B^T
其中:A是输入样本特征,B是类别原型特征当我们计算 softmax 交叉熵时:
P(class_i|x) = exp(x · w_i) / Σ_j exp(x · w_j)这个过程实际上是:
- 计算样本x与每个类别原型
的相似度
- 通过softmax将相似度转换为概率分布
- 最大化样本与正确类别原型的相似度
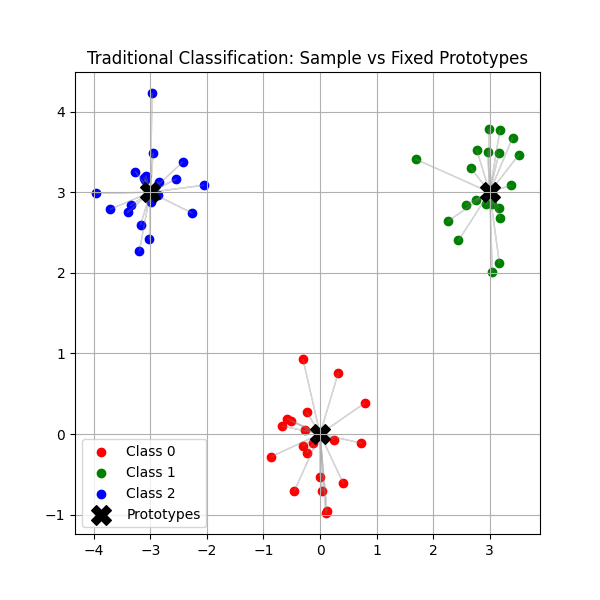
我们发现,传统分类过程也可以看出是样本与固定原型的对比,这个类别原型实际是隐藏在全连接层中,它在训练的过程中也会发生移动。每个类别样本的值不会与其它样本之间对比,而是与类别原型进行对比。
4.1.2 从固定原型到动态样本
对比学习将这个思想进一步扩展:
传统分类:样本 vs 固定类别原型
对比学习:样本 vs 动态样本集合在对比学习中:
- 正样本:与查询样本语义相似的样本
- 负样本:与查询样本语义不同的样本
- 目标:拉近正样本,推远负样本
本质上,我们是在学习一个动态的"原型空间",其中每个样本都可能成为某种语义的原型。
4.1.3 交叉熵的自然延伸
既然传统分类已经使用交叉熵来处理"样本vs原型"的对比,那么"样本vs样本"的对比自然也可以采用交叉熵的形式进行理解。
4.2 InfoNCE
4.2.1 从分类交叉熵到InfoNCE
在传统分类中:
在InfoNCE中,我们有查询样本q和候选样本集合{k_0, k_1, ..., k_N},其中k_0是正样本:
对比分析:
- 分类交叉熵:x与权重向量
- InfoNCE:q与动态样本向量
的内积
- 共同点:都是通过内积计算相似度,通过softmax归一化,通过负对数似然优化
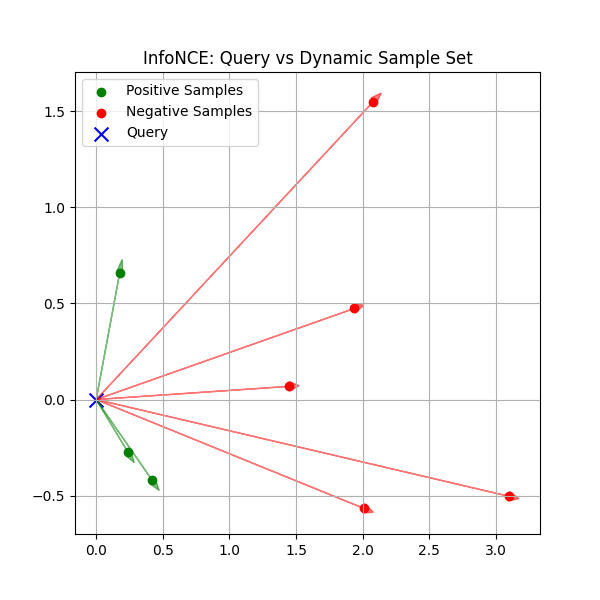
如上图所示,在InfoNce中,是不存在类别原型的,而是样本之间直接的对比,这里面既包括正样本的对比也包括负样本的对比。
4.2.2 温度参数τ的交叉熵理解
温度参数τ在分类任务中也经常使用,称为temperature scaling:
分类中的温度缩放:P(y|x) = softmax(logits/τ)
InfoNCE中的温度:P(pos|q) = softmax(similarities/τ)τ的作用机制:
τ < 1(低温度):
- softmax分布变得尖锐
- 模型更加"自信",倾向于给最相似的候选更高概率
- 梯度主要来自最相似的负样本
- 类似于hard attention机制
τ > 1(高温度):
- softmax分布变得平滑
- 模型更加"谦逊",概率分布更均匀
- 所有负样本都对梯度有贡献
- 类似于soft attention机制
τ = 1(标准温度):
- 保持原始的softmax特性
- 在尖锐性和平滑性之间平衡
4.2.3 为什么使用 InfoNCE 进行大规模数据训练?
在实际的大规模视觉或语言任务中,类别数量可能非常庞大(例如数万甚至上百万类),传统的分类交叉熵方法面临严重的效率与性能瓶颈。InfoNCE(Noise Contrastive Estimation 的一种信息论扩展)在此类场景下具有显著优势,主要原因如下:
1. 类别爆炸问题
- 在传统分类任务中,softmax 输出层的大小与类别数成正比。
- 当类别数达到十万、百万级别时,全类别 softmax 计算变得不可行:
- 参数量巨大,模型内存和计算开销剧增;
- 梯度更新效率低下,训练速度慢;
- 长尾分布问题加剧,大量类别样本稀少,难以有效学习。
而 InfoNCE 并不依赖于显式类别标签,而是通过对比学习构建监督信号,避免了对类别数量的直接依赖。
2. 负样本代替类别原型
- InfoNCE 不需要为每个类别维护一个“类别原型”向量;
- 取而代之的是,在每次训练迭代中,将其他样本作为负样本,动态地进行对比;
- 正样本通常来自数据增强或语义匹配策略(如同一图像的不同视角、同一句子的不同表达等);
- 这种方式更灵活,尤其适用于无明确类别划分的任务(如自监督学习)。
3. 负样本过多但可采样处理
- 虽然 InfoNCE 使用大量负样本,但可以通过以下技术缓解其影响:
- 负样本采样(Negative Sampling):从所有样本中随机选取一部分作为负样本;
- 动量编码器(Momentum Encoder):用于生成高质量负样本嵌入(如 MoCo 中的方法);
- 队列机制(Queue):缓存历史负样本,提升负样本多样性(如 MoCo v2);
- 去噪技巧(De-noising):过滤掉潜在的伪负样本,提高训练稳定性。
这些技术使得 InfoNCE 在面对超大规模数据时仍能保持高效稳定的学习过程。
4. 端到端优化相似性度量
- InfoNCE 直接优化查询样本与正样本之间的相似性,同时拉开与负样本的距离;
- 更适合学习可用于检索、匹配等下游任务的表示;
- 对比损失(Contrastive Loss)、三元组损失(Triplet Loss)等早期方法往往需要特定的数据构造(如成对/成组数据),而 InfoNCE 利用批量内的样本即可构建对比目标,更加简洁高效。
5. 适用于自监督与弱监督学习
- 在缺乏类别标签的情况下,InfoNCE 提供了一种有效的学习表示的方式;
- 例如:在视觉自监督学习中,通过对同一图像进行不同变换得到两个视图,互为正样本,其余为负样本;
- InfoNCE 构建的对比目标可以引导模型学习到语义一致的表示,即使没有人工标注的类别标签。
4.3 监督对比学习:多正样本的交叉熵扩展
4.3.1 从单一正确答案到多个正确答案
传统分类假设每个样本只属于一个类别,但现实中一个样本可能与多个样本相似。监督对比学习处理这种情况:
# 传统分类:一个样本对应一个类别
labels = [0, 1, 2, 0, 1] # 每个样本一个标签# 监督对比:一个锚点对应多个正样本
positive_pairs = {0: [0, 3], # 样本0与样本0,3相似1: [1, 4], # 样本1与样本1,4相似2: [2], # 样本2只与自己相似
}4.3.2 多标签交叉熵的自然扩展
监督对比学习的损失函数:
L_sup = -1/|P(i)| Σ_{p∈P(i)} log(exp(z_i·z_p/τ) / Σ_{a∈A(i)} exp(z_i·z_a/τ))这可以理解为多个二分类交叉熵的平均:
def supervised_contrastive_loss(features, labels, temperature=0.1):batch_size = features.shape[0]similarities = torch.mm(features, features.t()) / temperature# 构建正样本masklabels = labels.view(-1, 1)mask = torch.eq(labels, labels.t()).float() # 相同标签为1mask = mask - torch.eye(batch_size) # 移除对角线# 对每个正样本计算交叉熵,然后平均loss = 0for i in range(batch_size):if mask[i].sum() > 0: # 如果有正样本pos_similarities = similarities[i] * mask[i]# 这里每个正样本都相当于一个独立的交叉熵计算loss += -torch.log(torch.sum(torch.exp(pos_similarities)) / torch.sum(torch.exp(similarities[i])))return loss / batch_size- 每个正样本对应一个"虚拟类别"
- 对每个虚拟类别计算交叉熵
- 最终损失是所有虚拟类别交叉熵的平均
4.4 Circle Loss:重新参数化的交叉熵
4.4.1 从欧氏距离到余弦相似度
Circle Loss最初设计用于度量学习,处理样本间的距离关系。但我们可以通过交叉熵的视角来理解它。
Circle Loss的原始形式:
4.4.2 隐藏的二分类交叉熵结构
通过重新组织,我们可以将Circle Loss写成二分类交叉熵的形式:
若
则:
这正是二分类交叉熵的标准形式!
def circle_loss_as_crossentropy(pos_scores, neg_scores, gamma=1.0):# 计算正类和负类的综合logitpos_logit = torch.logsumexp(-gamma * pos_scores, dim=0)neg_logit = torch.logsumexp(gamma * neg_scores, dim=0)# 二分类交叉熵:log(1 + exp(neg_logit - pos_logit))return F.softplus(neg_logit - pos_logit)理解要点:
- Circle Loss将多个正负样本分别聚合成两个综合得分
- 然后在这两个得分之间进行二分类
- 本质上是"正样本集合 vs 负样本集合"的交叉熵对比
4.4.3 动态权重的交叉熵解释
Circle Loss的动态权重:
从交叉熵角度理解:
- 困难正样本(相似度低)获得更大权重,相当于增加其在损失中的重要性
- 困难负样本(相似度高)获得更大权重,相当于增加其在损失中的重要性
- 这类似于Focal Loss中根据预测置信度调整权重的思想
4.5 Triplet Loss
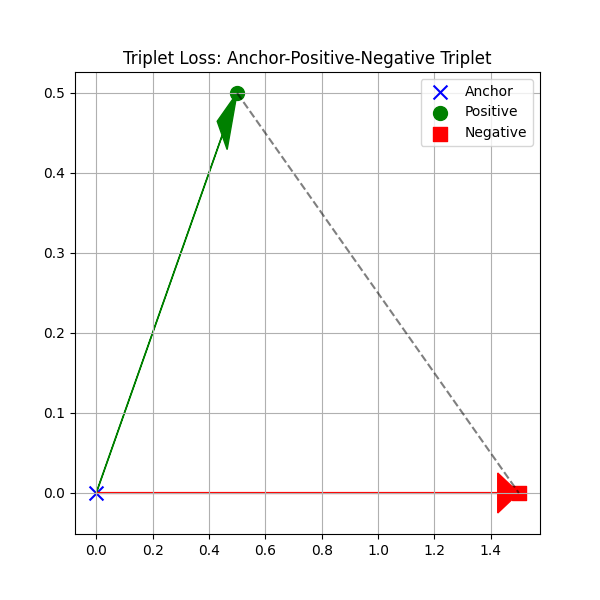
传统的Triplet Loss使用硬边界:
这个损失函数是不可导的(在边界处),实际应用中常使用软化版本:
另 (similarity for positive pair),
(similarity for negative pair)
则
这也是二元交叉熵的形式: - 用作正类 logit -
用作负类 logit - 公式与标准 BCE 匹配:
当扩展到多个负样本时:
从交叉熵角度,这等价于:
def multi_triplet_as_crossentropy(anchor, positive, negatives):pos_sim = torch.dot(anchor, positive)neg_sims = torch.mm(anchor.unsqueeze(0), negatives.t()).squeeze()# 对每个负样本进行二分类losses = []for neg_sim in neg_sims:# 二分类:正样本 vs 当前负样本logit = pos_sim - neg_simloss = F.binary_cross_entropy_with_logits(logit.unsqueeze(0), torch.ones(1) # 正样本应该获胜)losses.append(loss)return torch.stack(losses).mean()4.6 小结
通过本章的分析,我们深入理解了对比学习中各种损失函数:
- 分类是特殊的对比:样本与固定类别原型的对比
- 对比学习是泛化的分类:样本与动态样本集合的对比
- 交叉熵是通用的框架:无论是原型对比还是样本对比,都可以用交叉熵来建模
统一的理解框架
传统分类:max P(correct_class | sample)
对比学习:max P(positive_sample | query)共同本质:通过交叉熵优化概率分布的匹配结语
。编写中可能不严谨和错漏的地方,欢迎讨论指正。