一周学会Pandas2之Python数据处理与分析-数据重塑与透视-melt() - 融化 / 逆透视 (宽 -> 长)
锋哥原创的Pandas2 Python数据处理与分析 视频教程:
2025版 Pandas2 Python数据处理与分析 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili

melt() 是 pandas 中用于数据重塑的核心方法之一,它可以将 宽格式数据 转换为 长格式数据,特别适合处理具有多个观测值列的数据集。与 stack()/unstack() 不同,melt() 提供了更直观的方式来整理数据,尤其适用于数据预处理和清洗阶段。
基本概念:宽格式 vs 长格式
在深入 melt() 之前,先理解两种数据格式:
-
宽格式:每个变量有单独的列
ID Math Science English
0 1 90 85 92
1 2 78 88 95-
长格式:变量名和值分别存储在单独的列中
ID Subject Score
0 1 Math 90
1 1 Science 85
2 1 English 92
3 2 Math 78
4 2 Science 88
5 2 English 95基本语法
pd.melt(frame, id_vars=None, value_vars=None, var_name=None, value_name='value', col_level=None, ignore_index=True)参数说明
| 参数 | 说明 |
|---|---|
| frame | 要处理的 DataFrame |
| id_vars | 保持不变的列(标识变量) |
| value_vars | 要融合的列(观测值变量) |
| var_name | 新创建的变量名列的名称 |
| value_name | 新创建的值列的名称 |
| col_level | 用于多级列索引的层级 |
| ignore_index | 是否忽略原始索引(默认为 True) |
示例
import pandas as pd
# 创建示例数据
df = pd.DataFrame({'Student': ['Alice', 'Bob'],'Math': [90, 78],'Science': [85, 88],'English': [92, 95]
})
print("原始数据(宽格式):")
print(df)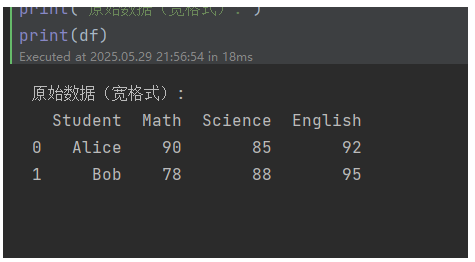
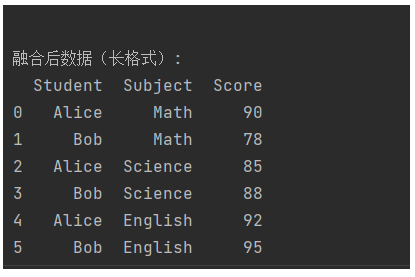
使用 melt() 转换:
melted_df = pd.melt(df,id_vars=['Student'], # 保留学生列value_vars=['Math', 'Science', 'English'], # 融合的科目列var_name='Subject', # 新列名:存储科目名称value_name='Score' # 新列名:存储分数
)
print("\n融合后数据(长格式):")
print(melted_df)