leetcode hot100刷题日记——34.将有序数组转换为二叉搜索树
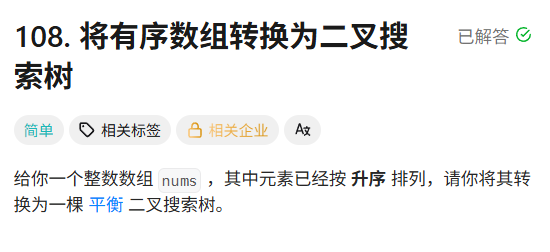
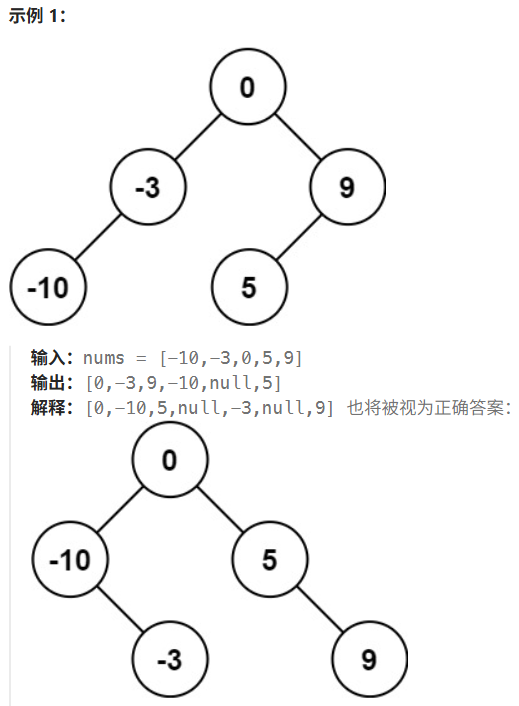
First Blood:什么是平衡二叉搜索树?
二叉搜索树(BST)的性质
左小右大:每个节点的左子树中所有节点的值都小于该节点的值,右子树中所有节点的值都大于该节点的值。
子树也是BST:左子树和右子树也必须是二叉搜索树。
中序遍历有序:对二叉搜索树进行中序遍历,可以得到一个按从小到大顺序排列的有序序列。
平衡二叉搜索树(Balanced BST)的性质
平衡性:平衡二叉搜索树在满足二叉搜索树所有性质的基础上,要求每个节点的左右子树的高度差的绝对值不超过1。
高效操作:由于树的高度平衡,插入、删除和查找等操作的时间复杂度稳定在 O(log n) 级别。
递归思路:
数组中间的点是根节点。数组左边到中间的左子区间可以构成平衡二叉树的左子树。数组中间到右边的右子区间可以构成平衡二叉树的右子树。
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {public:TreeNode* dfs(vector<int>& nums,int left,int right){if(left==right){return nullptr;}int m=left+(right-left)/2;return new TreeNode(nums[m],dfs(nums,left,m),dfs(nums,m+1,right));}TreeNode* sortedArrayToBST(vector<int>& nums) {return dfs(nums,0,nums.size());}
};
为什么right是从nums.size()开始而不是nums.size()-1呢?
A:首先,right一开始可以是nums.size()-1,但也要:
class Solution {
public:TreeNode* dfs(vector<int>& nums, int left, int right) {if(left > right) { // 注意终止条件变了return nullptr;}int m = left + (right - left) / 2;return new TreeNode(nums[m], dfs(nums, left, m-1), // 注意这里变了dfs(nums, m+1, right));}TreeNode* sortedArrayToBST(vector<int>& nums) {return dfs(nums, 0, nums.size()-1); // 这里就用 size()-1}
};
举例说明:nums = [1, 2, 3]
dfs([1,2,3], 0, 3) // 处理 [0,3),即索引 0,1,2
├─ m = 1,选择 nums[1] = 2
├─ 左子树:dfs([1,2,3], 0, 1) // 处理 [0,1),即索引 0
│ ├─ m = 0,选择 nums[0] = 1
│ ├─ 左子树:dfs([1,2,3], 0, 0) // [0,0) 空区间,left==right
│ └─ 右子树:dfs([1,2,3], 1, 1) // [1,1) 空区间,left==right
└─ 右子树:dfs([1,2,3], 2, 3) // 处理 [2,3),即索引 2├─ m = 2,选择 nums[2] = 3├─ 左子树:dfs([1,2,3], 2, 2) // [2,2) 空区间,left==right └─ 右子树:dfs([1,2,3], 3, 3) // [3,3) 空区间,left==right
dfs([1,2,3], 0, 2) // 处理 [0,2],即索引 0,1,2
├─ m = 1,选择 nums[1] = 2
├─ 左子树:dfs([1,2,3], 0, 0) // 处理 [0,0],即索引 0
│ ├─ m = 0,选择 nums[0] = 1
│ ├─ 左子树:dfs([1,2,3], 0, -1) // [0,-1] 空区间,left>right
│ └─ 右子树:dfs([1,2,3], 1, 0) // [1,0] 空区间,left>right
└─ 右子树:dfs([1,2,3], 2, 2) // 处理 [2,2],即索引 2├─ m = 2,选择 nums[2] = 3├─ 左子树:dfs([1,2,3], 2, 1) // [2,1] 空区间,left>right└─ 右子树:dfs([1,2,3], 3, 2) // [3,2] 空区间,left>right

时间复杂度分析:
主要操作分析:
1.每个节点只被访问一次:每次递归调用都会创建一个新节点
2.每次递归的工作量:
计算中点:O(1)
创建节点:O(1)
递归调用:分解为两个子问题
递推关系:
T(n) = 2 * T(n/2) + O(1)
其中:
T(n) 表示处理n个元素的时间
2 * T(n/2) 表示处理左右两个子树
O(1) 表示当前层的操作时间
递推求解:
T(n) = 2 * T(n/2) + 1
T(n/2) = 2 * T(n/4) + 1
T(n/4) = 2 * T(n/8) + 1
...
展开:
T(n) = 2 * (2 * T(n/4) + 1) + 1 = 4 * T(n/4) + 2 + 1
T(n) = 4 * (2 * T(n/8) + 1) + 3 = 8 * T(n/8) + 4 + 3
...
T(n) = 2^k * T(n/2^k) + (2^k - 1)
当 n/2^k = 1 时,即 k = log₂(n):
T(n) = n * T(1) + (n - 1) = n * 1 + n - 1 = 2n - 1 = O(n)
所以时间复杂度为O(n)
空间复杂度:O(log n)
递归深度:
每次递归将问题规模减半
递归深度 = log₂(n)
每层递归占用常数空间
调用栈空间:O(log n)