【LUT技术专题】图像自适应3DLUT

3DLUT开山之作: Learning Image-adaptive 3D Lookup Tables for High Performance Photo Enhancement in Real-time(2020 TPAMI )
- 专题介绍
- 一、研究背景
- 二、图像自适应3DLUT方法
- 2.1 前置知识
- 2.2 整体流程
- 2.3 损失函数的设计
- 三、实验结果
- 四、局限
- 五、总结
本文将从头开始对3DLUT开山之作: Learning Image-adaptive 3D Lookup Tables for High Performance Photo Enhancement in Real-time,第一篇利用学习的方法来得出图像自适应3DLUT算法进行讲解,这篇主要的亮点在于作者利用CNN和3DLUT结合完成了图像自适应的3DLUT图像增强,在保持LUT轻量化的优势前提下,提升了泛化性和算法性能。参考资料如下:
[1]. 论文地址
[2]. 代码地址
专题介绍
Look-Up Table(查找表,LUT)是一种数据结构(也可以理解为字典),通过输入的key来查找到对应的value。其优势在于无需计算过程,不依赖于GPU、NPU等特殊硬件,本质就是一种内存换算力的思想。LUT在图像处理中是比较常见的操作,如Gamma映射,3D CLUT等。
近些年,LUT技术已被用于深度学习领域,由SR-LUT启发性地提出了模型训练+LUT推理的新范式。
本专题旨在跟进和解读LUT技术的发展趋势,为读者分享最全最新的LUT方法,欢迎一起探讨交流,对该专题感兴趣的读者可以订阅本专栏第一时间看到更新。
系列文章如下:
【1】SR-LUT
【2】Mu-LUT
【3】SP-LUT
【4】RC-LUT
【5】EC-LUT
【6】SPF-LUT
【7】Dn-LUT
【8】Tiny-LUT
一、研究背景
简单来说,当时已有的利用CNN实现的图像颜色增强算法,虽然在效果上比较显著,但是消耗大量计算和内存资源,尤其是在一些高分辨率的图像上。本文为了解决这个问题,首次结合3DLUT工具到AI ISP中,保持了LUT低资源消耗的优势,又提升了算法的性能。
回顾传统的3D LUT工具,通常是在ISP pipeline中或者图像编辑工具中作为一个手动调整或者是固化的算子来使用,一般不会随着图像进行自适应的增强,本文提出的方法则可以根据图像的不同输出不同的LUT。 总结就是综合了LUT和原有CNN的优势,然后达到了更好的效果,提升了实用性。
作者接着对比了一下相关工作,阐述本方案的优势之处,有以下三种,三种类型相关工作各有不足,本文的方法则是:
1)使用CNN来实现的image2image是在AI ISP中常见的一个方式,但这种基于CNN的网络在高分辨率下,资源消耗巨大。
2)预测一组预定义的增强算子或映射曲线,这个地方大家可以想象预测一条曲线(1DLUT)用来调整对比度,通过将亮度完成单点1对1的映射提升对比度,通常这类方法会输入一个图像的低分辨率图来进行估计这个曲线,从而完成对高分辨率图像的增强。但这种方法使用的算子过于简单,不能提供足够的增强能力,并且很难从数据中直接学习。
3)采用强化学习来对输入图像进行迭代增强,显然这会牺牲效率,强化学习需要大量约束来帮助模型学习,没有监督学习便于使用。
本文则是可以综合上述的优点,最后总结一下本文的贡献,主要有3点:
1)第一次通过学习3D LUT的方式,使用成对和非成对的数据集进行训练,并完成自动的图像增强
2)提出的模型在600k的参数两下,在Titan RTX GPU上只花费2ms的时间就能够处理4K图像,应用价值高。
3)基准数据集验证了在成对和非成对数据集上,模型在定量和定性的实验中都优于当时最先进的图像增强方法。
二、图像自适应3DLUT方法
2.1 前置知识
1)3DLUT:学习一个3个输入index索引一个3维向量的LUT表,如下图立方体所示,每个立方体上的点都有它对应的值,对应到实际应用,就是颜色的增强。

2)trilinear interpolation:立方体插值,通过一个浮点数的位置找到其周围8个顶点的距离进行加权,加权的值是小立方体的体积,插值的点是3D LUT上的点,这个插值方式在本专栏的SR-LUT有讲到过。如下图所示,是一次插值的过程。

用公式表示这个插值过程就是:
c ( x , y , z ) O = ( 1 − d x ) ( 1 − d y ) ( 1 − d z ) c ( i , j , k ) O + d x ( 1 − d y ) ( 1 − d z ) c ( i + 1 , j , k ) O + ( 1 − d x ) d y ( 1 − d z ) c ( i , j + 1 , k ) O + ( 1 − d x ) ( 1 − d y ) d z c ( i , j , k + 1 ) O + d x d y ( 1 − d z ) c ( i + 1 , j + 1 , k ) O + ( 1 − d x ) d y d z c ( i , j + 1 , k + 1 ) O + d x ( 1 − d y ) d z c ( i + 1 , j , k + 1 ) O + d x d y d z c ( i + 1 , j + 1 , k + 1 ) O , \begin{aligned} c_{(x, y, z)}^{O} & =\left(1-d_{x}\right)\left(1-d_{y}\right)\left(1-d_{z}\right) c_{(i, j, k)}^{O}+d_{x}\left(1-d_{y}\right)\left(1-d_{z}\right) c_{(i+1, j, k)}^{O} \\ & +\left(1-d_{x}\right) d_{y}\left(1-d_{z}\right) c_{(i, j+1, k)}^{O}+\left(1-d_{x}\right)\left(1-d_{y}\right) d_{z} c_{(i, j, k+1)}^{O} \\ & +d_{x} d_{y}\left(1-d_{z}\right) c_{(i+1, j+1, k)}^{O}+\left(1-d_{x}\right) d_{y} d_{z} c_{(i, j+1, k+1)}^{O} \\ & +d_{x}\left(1-d_{y}\right) d_{z} c_{(i+1, j, k+1)}^{O}+d_{x} d_{y} d_{z} c_{(i+1, j+1, k+1)}^{O}, \end{aligned} c(x,y,z)O=(1−dx)(1−dy)(1−dz)c(i,j,k)O+dx(1−dy)(1−dz)c(i+1,j,k)O+(1−dx)dy(1−dz)c(i,j+1,k)O+(1−dx)(1−dy)dzc(i,j,k+1)O+dxdy(1−dz)c(i+1,j+1,k)O+(1−dx)dydzc(i,j+1,k+1)O+dx(1−dy)dzc(i+1,j,k+1)O+dxdydzc(i+1,j+1,k+1)O,
其中 d x d_x dx、 d y d_y dy、 d z d_z dz分别是到最左下角点的距离,自然每个插值加权了一个立方体的体积。
2.2 整体流程
整体流程如下图所示。
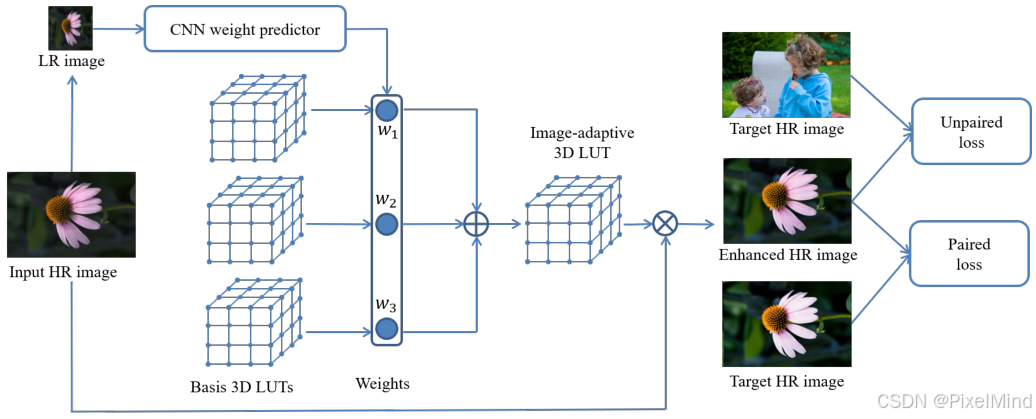
- 首先输入HR图像进行下采样得到LR图像,LR图像送入CNN weight predictor中预测得到 w 1 w_1 w1、 w 2 w_2 w2、 w 3 w_3 w3,此是用于加权Basis 3D LUTs的权重。
- 3D LUTs加权后得到一个Image-adaptive 3D LUT,显然这个3D LUT的生成过程是符合随着图像的变化而变化的这个特性的,这个LUT将作用于HR图像完成图像的增强,得到增强结果。
- 结果进行损失的计算,当然成对的图像使用论文设计的成对损失,否则使用非成对的损失进行模型优化。
作者接下来讲了为什么这么设计的原因,作者认为传统的3DLUT有两个局限性:
- 3D LUT手工设计,麻烦且昂贵。
- 1个3D LUT只能提供固定的变换,难以适应不同的场景,现有的一般都是预设一些LUT,然后让用户去选择,这不够灵活。
针对性的,为了解决第一个问题,采用数据驱动的方式,因为是数据集学习,所以也不存在所谓手工设计的情况。
针对第二个局限,模型只需要能够有对图像有针对性的调整即可,则引入了CNN来预测权重,那这里当然会存在一个分歧,如果作者设计成一个分类器,即强行选择某一个LUT(hard-voting strategy)。作者分析了这种方式存在明显的问题,首先,非常难以将某些场景归为特定的一些类从而让他们共享一个LUT,其次由于每个3DLUT都是独立作用于输入图像,因此需要大量的3D LUT来覆盖所有场景,最后分类器的训练独立于各个3D LUT使得他们之间的协作不是最优的,并且一旦分类错误会引入artifact。
2.3 损失函数的设计
1)内容相关的损失:
- 针对于成对数据,使用如下所示的MSE损失:
L m s e = 1 T ∑ t = 1 T ∥ q t − y t ∥ 2 \mathcal{L}_{m s e}=\frac{1}{T} \sum_{t=1}^{T}\left\|q_{t}-y_{t}\right\|^{2} Lmse=T1t=1∑T∥qt−yt∥2,这里的 q t q_t qt和 y t y_t yt是预测和实际的HQ, T T T是数据个数。 - 针对于非成对数据,则使用gan损失,如下所示,分别是生成器和判别器的损失,gan损失是他们的和。
L G = E x [ − D ( G ( x ) ) ] + λ 1 E x [ ∥ G ( x ) − x ∥ 2 ] , \mathcal{L}_{G}=\underset{x}{\mathbb{E}}[-D(G(x))]+\lambda_{1} \underset{x}{\mathbb{E}}\left[\|G(x)-x\|^{2}\right], LG=xE[−D(G(x))]+λ1xE[∥G(x)−x∥2], L D = E x [ D ( G ( x ) ) ] − E y [ D ( y ) ] + λ 2 E y ^ [ ( ∥ ∇ y ^ D ( y ^ ) ∥ 2 − 1 ) 2 ] , \mathcal{L}_{D}=\underset{x}{\mathbb{E}}[D(G(x))]-\underset{y}{\mathbb{E}}[D(y)]+\lambda_{2} \underset{\widehat{y}}{\mathbb{E}}\left[\left(\left\|\nabla_{\widehat{y}} D(\widehat{y})\right\|_{2}-1\right)^{2}\right], LD=xE[D(G(x))]−yE[D(y)]+λ2y E[(∥∇y D(y )∥2−1)2],则gan损失可以表达为: L g a n = L G + L D \mathcal{L}_{gan}=\mathcal{L}_{G}+\mathcal{L}_{D} Lgan=LG+LD
2)正则化项:作者使用了两个正则化损失,来确保结果的正常:
- 平滑损失:作者使用的TV损失搭配一个 w i w_i wi的权重正则来确保结果的平滑,只不过这个TV损失作用于LUT表上,如下所示。
R T V = ∑ c ∈ { r , g , b } ∑ i , j , k ( ∥ c ( i + 1 , j , k ) O − c ( i , j , k ) O ∥ 2 + ∥ c ( i , j + 1 , k ) O − c ( i , j , k ) O ∥ 2 + ∥ c ( i , j , k + 1 ) O − c ( i , j , k ) O ∥ 2 ) R_{TV} = \sum_{c \in \{r, g, b\}} \sum_{i, j, k} \left( \| c_{(i+1, j, k)}^O - c_{(i, j, k)}^O \|^2 + \| c_{(i, j+1, k)}^O - c_{(i, j, k)}^O \|^2 + \| c_{(i, j, k+1)}^O - c_{(i, j, k)}^O \|^2 \right) RTV=c∈{r,g,b}∑i,j,k∑(∥c(i+1,j,k)O−c(i,j,k)O∥2+∥c(i,j+1,k)O−c(i,j,k)O∥2+∥c(i,j,k+1)O−c(i,j,k)O∥2),可以看到这里是对于3DLUT的每个维度的梯度的平方做了一个加和,即不希望LUT每一个点的梯度不会太大,发生分层现象。最后平滑损失表示为:
R s = R T V + 1 n ∥ w n ∥ 2 \mathcal{R}_s = \mathcal{R}_{TV} + \frac{1}{n} \| w_n \|^2 Rs=RTV+n1∥wn∥2在TV损失的基础上添加了一个对 w w w的L2正则损失, w w w控制内容影响的权重而TV控制所使用到的LUT。 - 单调性损失:作者使用了如下所示的设计来确保LUT是单调的,不会发生分层现象。如下所示:
R m = ∑ c ∈ { r , g , b } ∑ i , j , k [ g ( c ( i , j , k ) O − c ( i + 1 , j , k ) O ) + g ( c ( i , j , k ) O − c ( i , j + 1 , k ) O ) + g ( c ( i , j , k ) O − c ( i , j , k + 1 ) O ) ] \mathcal{R}_m = \sum_{c \in \{r, g, b\}} \sum_{i, j, k} \left[ g \left( c_{(i, j, k)}^O - c_{(i+1, j, k)}^O \right) + g \left( c_{(i, j, k)}^O - c_{(i, j+1, k)}^O \right) + g \left( c_{(i, j, k)}^O - c_{(i, j, k+1)}^O \right) \right] Rm=c∈{r,g,b}∑i,j,k∑[g(c(i,j,k)O−c(i+1,j,k)O)+g(c(i,j,k)O−c(i,j+1,k)O)+g(c(i,j,k)O−c(i,j,k+1)O)]
这个公式中的 g g g代表标准ReLU,这个正则项是为了满足单调递增性的,当索引增大时,我们需要将其增大,因此当满足增大这个条件时,ReLU会使得损失为0,否则不为0。
三、实验结果
本篇文章的实验非常详细,首先讲一下消融实验。
1)预设的3D LUT数目,文中展示的是3个,作者做了实验。

这里的Delta E 是CIELAB色彩空间中定义的色差度量,显然定量的实验证明是LUT数目越多,效果越好,但作者为了权衡资源消耗和效果选择了3个,毕竟后续效果增长不多。
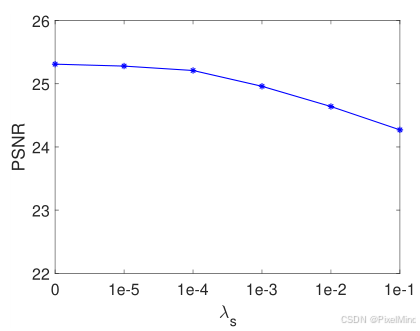
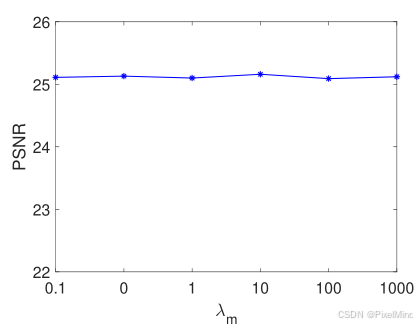
2)正则损失的权重大小:引入了 λ s \lambda_s λs和 λ m \lambda_m λm分别代表平滑损失和单调损失的大小,首先实验了他们的一个单调增长对于效果的影响, λ s \lambda_s λs越大,PSNR会显著下降,这是可以预料到的,因为平滑性限制了3D LUT的转换灵活性,而对于单调性来说,权重影响不大,因为他只是一个自然的约束,不会对其增强效果有太多抑制。
 .
.
然后作者做了一个定性的实验来看这些损失对于实际效果的影响,如下图所示。

对于完全不加约束的(a)来说,中间的天空出现了明显的分层现象,(b)做了平滑损失有一定的改善,但还是存在带状的一个分层,©有单调约束后对于带状的分层有了改善,但是仍然存在部分局部不平滑的问题,相比较来说(d)就更加好,不存在前面的问题,结合起来效果才会更好一些,作者在这里还做了对LUT切面的分析,整体会更有说服力,感兴趣的作者可以补充看一下,作者的实验做的非常的完整和详细。
最终作者通过以上实验给出了结论选择 λ s \lambda_s λs和 λ m \lambda_m λm分别为0.0001和10,在增强和模型稳定性之间取得一个平衡。
3)自适应LUT:这个主要就是看CNN给的weight是否有用,显然是有用的,作者做了定性的实验来说明这点。

针对自适应的LUT,固定LUT的效果有明显劣势。
消融实验讲完了,后续是作者的一些跟其他方法的效果对比实验。
1)成对数据:
- 定量实验:优势明显。
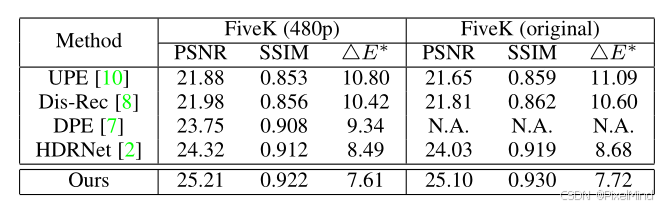
- 定性实验:同样优势明显。

跟较sota的HDRNet做了更细节的对比,效果上天空有优势,泛化性更好。

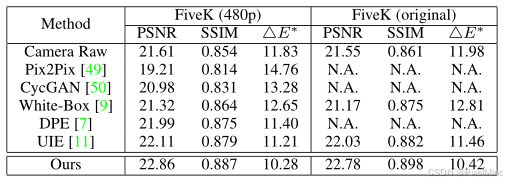
2)非成对数据:
-
定量实验:优势明显。
-
定性实验:效果上有优势。


3)User study:用户主观的判断,同样是优势。
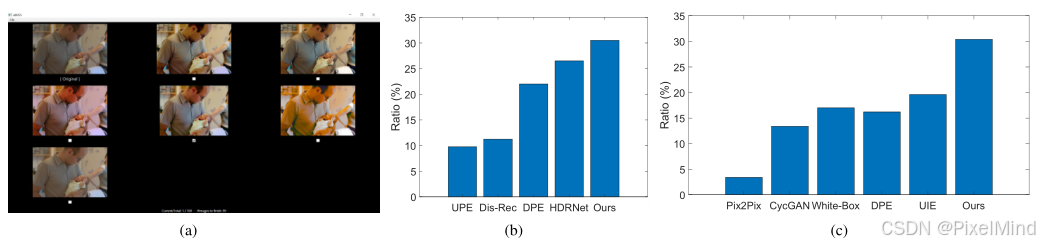
其中(a)是他们的测试界面,(b)和(c) 是成对和非成对类的结果对比,用户喜爱比是领先的。
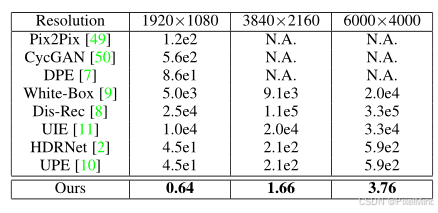
4)耗时比对:非常明显的优势,差了数量级。
四、局限
作者提了几个局限,从这里也可以看出这篇文章的内容非常的详细和完整,做了大量的实验。
1)局部对比度不够:因为是全局的LUT方法,所以在一些场景下存在问题,比如说:

在不加local tone mapping之前,3DLUT对于阴影部分的处理是不够好的。
2)可能会对噪声进行增强:由于增强可能会放大噪声,所以是需要在有噪声的环境下配合降噪使用。

图中放大的部分存在噪声被增强的情况。
五、总结
图像自适应的3DLUT算是开了一个新篇章,能够有效的根据图像来自适应的生成3DLUT对图像进行增强,并且引入的正则项可以有效的抑制模型的异常,整体来说是非常实用的一个技术,相信在很多实际的场景下已经得到了应用。
代码部分将会单起一篇进行解读。(未完待续)
感谢阅读,欢迎留言或私信,一起探讨和交流,如果对你有帮助的话,也希望可以给博主点一个关注,谢谢。