Kafka数据怎么保障不丢失
在分布式消息系统中,数据不丢失是核心可靠性需求之一。Apache Kafka 通过生产者配置、副本机制、持久化策略、消费者偏移量管理等多层机制保障数据可靠性。以下从不同维度解析 Kafka 数据不丢失的核心策略,并附示意图辅助理解。
一、生产者端:确保消息可靠发送
生产者是数据流入 Kafka 的入口,通过配置参数和机制避免消息在发送过程中丢失。
1. 消息确认机制(acks 参数)
Kafka 生产者通过 acks 参数控制消息发送的确认级别,确保消息被 Broker 正确接收。
- acks=0:生产者发送消息后不等待任何确认,可能因网络故障丢失消息,可靠性最低。
- acks=1(默认):仅等待 Leader 副本确认消息写入本地日志,若 Leader 未同步副本就宕机,可能丢失消息。
- acks=all(或 acks=-1):等待所有 ISR(In-Sync Replicas) 副本确认消息写入,可靠性最高,但延迟较高。
示意图:acks=all 的消息确认流程
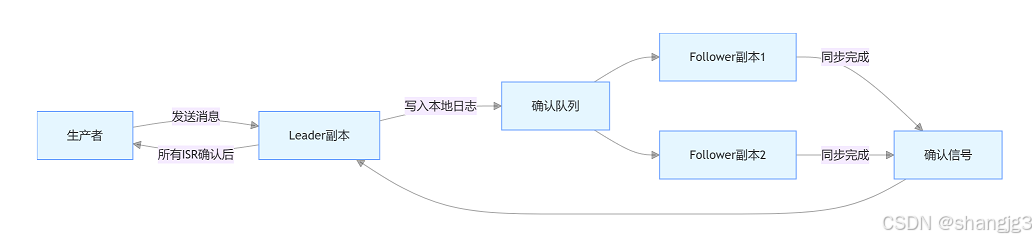
2. 重试机制(retries 参数)
当消息发送失败(如 Leader 切换、网络波动)时,生产者自动重试发送消息,避免因临时故障导致数据丢失。
- 需结合 retry.backoff.ms 控制重试间隔,避免频繁重试加剧网络负载。
- 注意:若未启用幂等性,重试可能导致消息重复(需下游去重)。
3. 幂等性与事务(Idempotence & Transactions)
- 幂等性:通过生产者 ID(PID)和序列号(Sequence Number)确保重复发送的消息仅被 Broker 处理一次,避免重试导致的重复数据。
- 开启方式:设置 enable.idempotence=true(默认开启)。
- 事务:确保跨分区、跨主题的消息发送具有原子性(全部成功或全部失败),适用于需要强一致性的场景(如订单系统)。
- 步骤:开启事务(transactional.id)→ 开始事务 → 发送消息 → 提交事务(或回滚)。
二、Broker 端:确保数据持久化与容错
Broker 通过副本机制和持久化策略保障数据不丢失,即使节点故障也能通过副本恢复数据。
1. 副本机制与 ISR 列表
- 分区多副本设计:每个分区包含 1 个 Leader 副本和多个 Follower 副本,数据先写入 Leader,再由 Follower 同步。
- ISR 动态维护:ISR 列表包含与 Leader 同步进度一致的 Follower 副本。当 Leader 宕机时,仅从 ISR 中选举新 Leader,确保新 Leader 拥有最新数据。
- 副本同步策略:
- 同步复制:消息需写入所有 ISR 副本才被确认(配合 acks=all),可靠性最高但性能较低。
- 异步复制:仅写入 Leader 即确认(acks=1),可能因 Follower 未同步导致数据丢失。
示意图:ISR 与副本同步流程
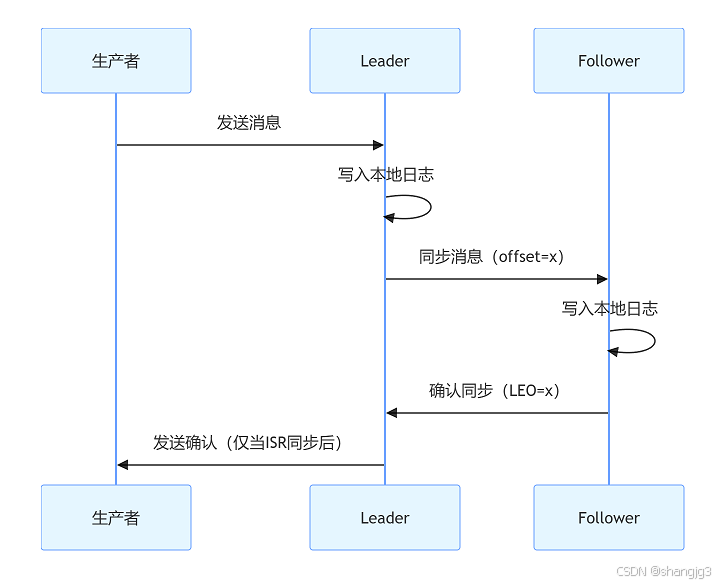
2. 日志持久化配置
- 磁盘刷盘策略:Kafka 通过 log.flush.interval.messages 和 log.flush.interval.ms 控制日志刷盘时机,确保内存数据定期持久化到磁盘。
- 若未及时刷盘,Broker 宕机可能导致内存中未刷盘的数据丢失(需结合业务容忍度配置)。
- 数据保留策略:通过 log.retention.hours 控制日志保留时间,避免数据被过早删除。
三、消费者端:确保消息不重复消费或漏消费
消费者通过偏移量(Offset)管理和再均衡机制保障数据消费的可靠性。
1. 偏移量提交策略
- 自动提交(默认):消费者定期自动提交偏移量(auto.commit.enable=true),若在消费过程中宕机,可能导致已提交但未处理的消息丢失。
- 手动提交:消费者处理完消息后手动提交偏移量(commitSync() 或 commitAsync()),确保“消费完成后再确认”。
// 手动提交示例(Kafka Consumer API)while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {processMessage(record); // 处理消息}
consumer.commitSync(); // 手动提交偏移量}
2. 分区再均衡(Rebalance)处理
当消费者组内成员变化(如新增/移除消费者)或分区数量变化时,会触发分区再均衡,可能导致消费混乱。
- 问题:若再均衡前未提交偏移量,可能导致分区分配给新消费者后重复消费;若提前提交,可能导致漏消费。
- 解决方案:
- 使用 ConsumerRebalanceListener 监听再均衡事件,在 onPartitionsRevoked 中手动提交偏移量或暂停消费。
consumer.subscribe(Arrays.asList("topic"), new ConsumerRebalanceListener() {@Overridepublic void onPartitionsRevoked(Collection<TopicPartition> partitions) {
consumer.commitSync(partitions); // 再均衡前提交偏移量}@Overridepublic void onPartitionsAssigned(Collection<TopicPartition> partitions) {// 重新分配分区后重置消费位置(可选)}});
3. 消费顺序性与重复消费处理
- 顺序性:单个分区内的消息按顺序消费,消费者按偏移量递增顺序拉取消息,确保处理顺序。
- 重复消费:若消费者未正确提交偏移量(如手动提交前宕机),可能导致重新消费已处理的消息,需下游业务实现幂等性(如通过唯一主键去重)。
四、高级保障机制
1. 跨数据中心复制(MirrorMaker 2)
通过 MirrorMaker 2 实现跨集群数据复制,将数据同步到异地数据中心,防止单集群故障导致数据永久丢失。
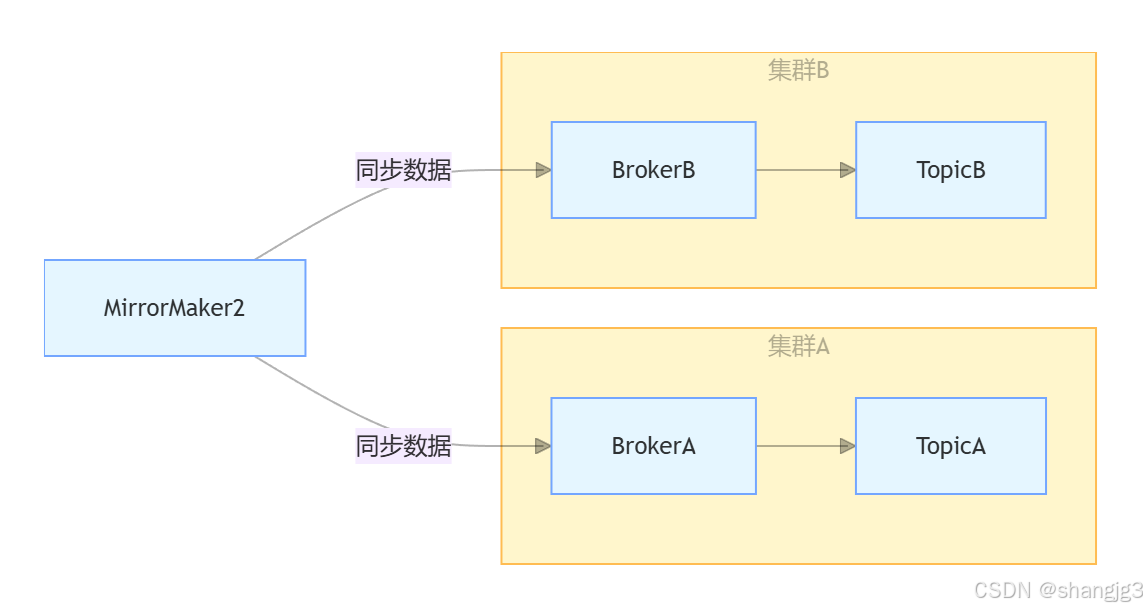
2. 监控与告警
- 监控指标:
- ISR 列表长度:若 Follower 长时间未同步,ISR 列表可能缩小,需排查网络或 Broker 性能问题。
- 分区 Leader 分布:确保 Leader 均匀分布,避免单节点负载过高。
- 工具:使用 Kafka Manager、Prometheus + Grafana 等监控平台,及时发现副本不同步、Broker 宕机等风险。
五、可靠性与性能的权衡
Kafka 的数据可靠性与性能呈负相关,需根据业务场景选择配置:
| 场景 | 推荐配置 | 特点 |
| 金融级强一致 | acks=all + 同步刷盘 + 手动提交偏移量 + 跨集群复制 | 可靠性最高,延迟高 |
| 高吞吐弱一致 | acks=1 + 异步刷盘 + 自动提交偏移量 | 性能高,允许轻微丢失 |
| 通用场景 | acks=all + 异步刷盘 + 手动提交偏移量 + 幂等性开启 | 平衡可靠性与性能 |
总结:数据不丢失的核心链路
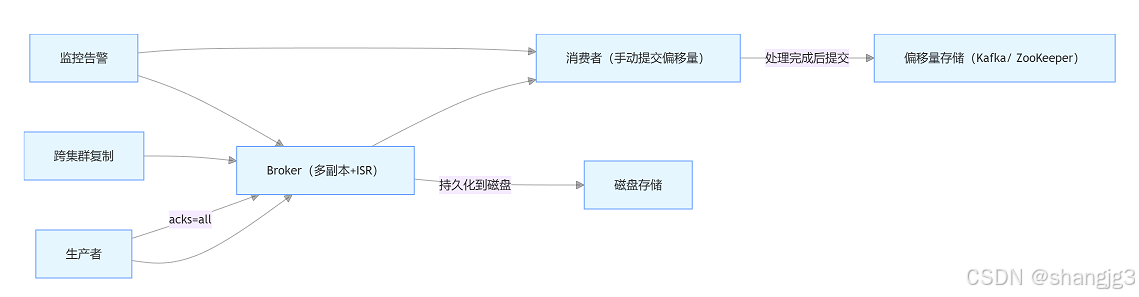
通过以上多层机制,Kafka 可在不同场景下保障数据不丢失。实际应用中需结合业务需求调整参数,并通过压测验证可靠性与性能的平衡。