day17 常见聚类算法
目录
准备操作
聚类评估指标介绍
1.轮廓系数(Sihouette Score)
2.CH指数(Calinski-Harabasz Index)
3.DB指数(Davies-Bounldin Index)
KMeans聚类
算法原理
确定簇数的方法:肘部法
KMeans算法的优缺点
DBSCAN聚类
核心概念
算法原理
层次聚类
作业:对心脏病数据集进行聚类。
KMeans算法
DBSCAN算法
层次聚类
知识点
- 聚类的指标
- 聚类常见算法:kmeans聚类、dbscan聚类、层次聚类
- 三种算法对应的流程
准备操作
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans, DBSCAN, AgglomerativeClustering
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
import matplotlib.pyplot as plt
import seaborn as sns# 标准化数据(聚类前通常需要标准化)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# X_scaled聚类评估指标介绍
以下是三种常用的聚类效果评估指标,分别用于衡量聚类的质量和簇的分离与紧凑程度。
1.轮廓系数(Sihouette Score)
定义:轮廓系数衡量每个样本与其所属簇的紧密程度以及与最近其他簇的分离程度
取值范围:[-1, 1]
· 轮廓系数越接近1,表示样本与其所属簇内其他样本很近,与其他簇很远,聚类效果越好。
· 轮廓系数越接近-1,表示样本与其所属簇内样本较远,与其簇较近,聚类效果越差(可能被错误分类)
· 轮廓系数接近0,表示样本在簇边界附近,聚类效果无明显好坏。
使用建议:选择轮廓系数最高的 k 值作为最佳簇数量
2.CH指数(Calinski-Harabasz Index)
定义:CH指数是簇间分散度与簇内分散度之比,用于评估簇的分离度和紧凑度
取值范围:[0,+∞)
· CH指数越大,表示簇间分离度越高,簇内紧凑度越高,聚类效果越好。
· 没有固定的上限,值越大越好。
使用建议:选择CH指数最高的 k 值最为最佳簇数量
3.DB指数(Davies-Bounldin Index)
定义:DB 指数衡量簇间距离与簇内分散度的比值,用于评估簇的分离度和紧凑度。
取值范围:[0,+∞)
· DB 指数越小,表示簇间分离度越高,簇内紧凑度越高,聚类效果越好。
· 没有固定的上限,值越小越好。
使用建议:选择 DB 指数最低的 k 值作为最佳簇数量
KMeans聚类
算法原理
KMeans 是一种基于距离的聚类算法,需要预先指定聚类个数,即 k 。其核心步骤如下:
1. 随机选择 k 个样本点作为初始质心(簇中心)。
2. 计算每个样本点到各个质心的距离,将样本点分配到距离最近的质心所在的簇。
3. 更新每个簇的质心为该簇内所有样本点的均值。
4. 重复步骤 2 和 3,直到质心不再变化或达到最大迭代次数为止。
确定簇数的方法:肘部法
- 肘部法(Elbow Method)是一种常用的确定 k 值的方法。
- 原理:通过计算不同 k 值下的簇内平方和(Within-Cluster Sum of Squares, WCSS),绘制 k 与 WCSS 的关系图。
- 选择标准:在图中找到“肘部”点,即 WCSS 下降速率明显减缓的 k 值,通常认为是最佳簇数。这是因为增加 k 值带来的收益(WCSS 减少)在该点后变得不显著。
KMeans算法的优缺点
优点:
- 简单高效:算法实现简单,计算速度快,适合处理大规模数据集。
- 适用性强:对球形或紧凑的簇效果较好,适用于特征空间中簇分布较为均匀的数据。
- 易于解释:聚类结果直观,簇中心具有明确的物理意义。
缺点:
- 需预先指定 k 值:对簇数量 k 的选择敏感,不合适的 k 会导致聚类效果较差。
- 对初始质心敏感:初始质心的随机选择可能导致结果不稳定或陷入局部最优(可通过 KMeans++ 初始化方法缓解)。
- 对噪声和异常值敏感:异常值可能会显著影响质心的位置,导致聚类结果失真。
- 不适合非球形簇:对非线性可分或形状复杂的簇效果较差,无法处理簇密度不均的情况。
# 评估不同 k 值下的指标
k_range = range(2, 11) # 测试 k 从 2 到 10
inertia_values = [] # 存储每个 k 值对应的惯性值
silhouette_scores = [] # 存储每个 k 值对应的轮廓系数
ch_scores = [] # 存储每个 k 值对应的 CH 指数
db_scores = [] # 存储每个 k 值对应的 DB 指数for k in k_range:kmeans = KMeans(n_clusters=k, random_state=42) kmeans_labels = kmeans.fit_predict(X_scaled) inertia_values.append(kmeans.inertia_) # 惯性(肘部法则)silhouette = silhouette_score(X_scaled, kmeans_labels) # 轮廓系数silhouette_scores.append(silhouette)ch = calinski_harabasz_score(X_scaled, kmeans_labels) # CH 指数ch_scores.append(ch)db = davies_bouldin_score(X_scaled, kmeans_labels) # DB 指数db_scores.append(db)print(f"k={k}, 惯性: {kmeans.inertia_:.2f}, 轮廓系数: {silhouette:.3f}, CH 指数: {ch:.2f}, DB 指数: {db:.3f}")# 绘制评估指标图
plt.figure(figsize=(15, 10))# 肘部法则图(Inertia)
plt.subplot(2, 2, 1)
plt.plot(k_range, inertia_values, marker='o')
plt.title('肘部法则确定最优聚类数 k(惯性,越小越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('惯性')
plt.grid(True) # 轮廓系数图
plt.subplot(2, 2, 2)
plt.plot(k_range, silhouette_scores, marker='o', color='orange')
plt.title('轮廓系数确定最优聚类数 k(越大越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('轮廓系数')
plt.grid(True)# CH 指数图
plt.subplot(2, 2, 3)
plt.plot(k_range, ch_scores, marker='o', color='green')
plt.title('Calinski-Harabasz 指数确定最优聚类数 k(越大越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('CH 指数')
plt.grid(True)# DB 指数图
plt.subplot(2, 2, 4)
plt.plot(k_range, db_scores, marker='o', color='red')
plt.title('Davies-Bouldin 指数确定最优聚类数 k(越小越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('DB 指数')
plt.grid(True)plt.tight_layout()
plt.show()k=2, 惯性: 218529.50, 轮廓系数: 0.320, CH 指数: 479.34, DB 指数: 3.222
k=3, 惯性: 207982.87, 轮廓系数: 0.209, CH 指数: 441.88, DB 指数: 2.906
k=4, 惯性: 200477.28, 轮廓系数: 0.220, CH 指数: 399.12, DB 指数: 2.441
k=5, 惯性: 192940.36, 轮廓系数: 0.224, CH 指数: 384.19, DB 指数: 2.042
k=6, 惯性: 185411.81, 轮廓系数: 0.227, CH 指数: 380.64, DB 指数: 1.733
k=7, 惯性: 178444.49, 轮廓系数: 0.130, CH 指数: 378.31, DB 指数: 1.633
k=8, 惯性: 174920.27, 轮廓系数: 0.143, CH 指数: 352.31, DB 指数: 1.817
k=9, 惯性: 167383.96, 轮廓系数: 0.150, CH 指数: 364.27, DB 指数: 1.636
k=10, 惯性: 159824.84, 轮廓系数: 0.156, CH 指数: 378.43, DB 指数: 1.502
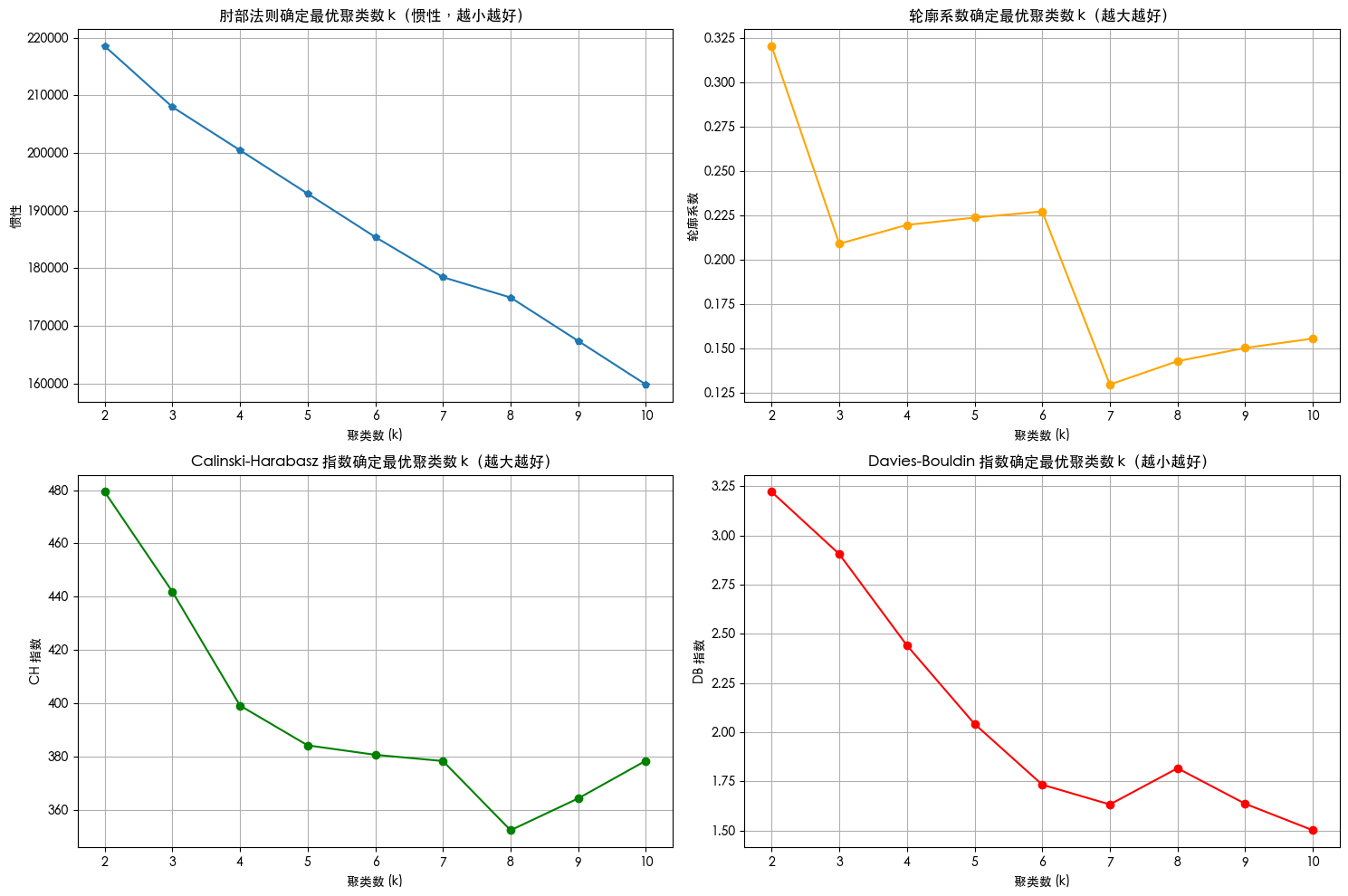
1. 肘部法则图: 找下降速率变慢的拐点,这里都差不多
2. 轮廓系数图:找局部最高点,这里选6不能选7
3. CH指数图: 找局部最高点,这里选7之前的都还行
4. DB指数图:找局部最低点,这里选6 7 9 10都行
综上,选择6比较合适。
--- 为什么选择局部最优的点,因为比如簇间差异,分得越细越好,但是k太细了没价值,所以要取舍。
--- 比如k可以选3和5,推荐选择5,能包含更多信息。
# 提示用户选择 k 值
selected_k = 6# 使用选择的 k 值进行 KMeans 聚类
kmeans = KMeans(n_clusters=selected_k, random_state=42)
kmeans_labels = kmeans.fit_predict(X_scaled)
X['KMeans_Cluster'] = kmeans_labels # 将聚类标签添加到原始数据中# 使用 PCA 降维到 2D 进行可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled) # KMeans 聚类结果可视化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=kmeans_labels, palette='viridis')
plt.title(f'KMeans Clustering with k={selected_k} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()# 打印 KMeans 聚类标签的前几行
print(f"KMeans Cluster labels (k={selected_k}) added to X:")
print(X[['KMeans_Cluster']].value_counts())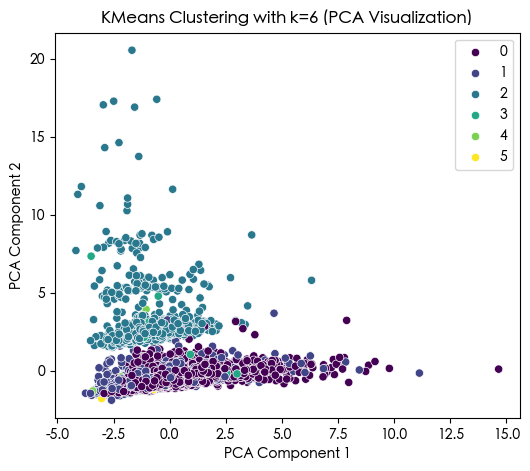
KMeans Cluster labels (k=6) added to X:
KMeans_Cluster
0 5205
1 1220
2 903
3 128
4 34
5 10
Name: count, dtype: int64
DBSCAN聚类
核心概念
1、ε邻域:表示以某点为中心,半径为 ε 的圆形范围。邻域内的所有点到该中心点的距离(欧氏距离或其他距离)都不会超过 ε (ε邻域的另一定义:指距离该点不超过 ε 的所有点的集合)
2、MinPts:它是一个给定的数值,表示一个点被认为是核心点所需的最小邻居数量(包括该点本身)。
3、核心点:如果一个点的 ε 邻域内至少有MinPts个点(包括它自身),则该点是核心点。核心点周围有足够的密度,能够扩展形成一个聚类。
4、边界点:如果一个点的ε邻域内有少于MinPts个点,但它位于某个核心点的邻域内,那么这个点就是边界点。边界点虽然在核心点的邻域内,但它自身不满足成为核心点的条件(即它的邻域内的点数不足以形成密度聚类)。
5、噪声点:如果一个点既不是核心点,也不在任何核心点的邻域内,那么它被认为是噪声点,通常不属于任何聚类。噪声点是稀疏区域的点,DBSCAN会将这些点从聚类结果中剔除。
6、聚类扩展:DBSCAN的聚类是从核心点开始扩展的。一旦找到一个核心点,它会将该核心点的邻域内的所有点(包括边界点)添加到同一个聚类中。如果一个边界点的邻域内没有足够的点(小于MinPts),则该点不能成为新的核心点,但它可以作为已有核心点的边界点进行扩展。
7、聚类的形成:
DBSCAN通过核心点扩展聚类,聚类可以包含多个核心点及其邻域内的边界点。
如果两个核心点的ε邻域有重叠,它们的聚类就会合并成一个更大的聚类。
如果核心点之间没有重叠,它们就会形成不同的聚类。
算法原理
DBSCAN是一种基于密度的聚类算法,核心步骤如下:
(一)定义参数
epsilon:一个点被认为是邻居的最大距离。即半径范围内的点。
MinPts:一个点被认为是核心点的最小邻居数。
(二)DBSCAN迭代步骤
1、选择一个未访问过的点:
从数据集中选取一个未被访问过的点P。
2、计算ε邻域内的点数,判断P是否为核心点:
计算点P在ε范围内的所有邻居。如果邻域内的点数大于或等于MinPts,则P是一个核心点。
3、若P为核心点:
如果P是核心点,则将P及其所有邻域内的点加入一个簇中。
对簇中的每个点进行扩展,检查其邻域。如果邻域内的点数大于MinPts,且该点尚未被处理过,则将其添加到簇中,并进一步检查其邻域。
4、若不是核心点,则处理边界点和噪声点:
如果一个点没有足够的邻居(即少于MinPts个点在ε邻域内),且不在任何核心点的邻域内,则该点被标记为噪声点。
否则,该点会被归类为边界点,属于某个核心点的簇,但它本身不是一个核心点。
5、重复以上迭代步骤,直到所有点都被访问过
对数据集中的所有点进行检查,直到所有点都被分配到簇中或被标记为噪声点。
DBSCAN算法的优缺点:
优点:
- 能发现任意形状的簇:DBSCAN能够识别形状不规则的簇(如弯曲的、环形的簇等),不像K-means那样只能发现圆形或球形的簇。适用于复杂的数据结构,特别是当簇的形状是非凸时。
- 不需要预设簇数:不同于K-means需要指定簇的数量,DBSCAN不需要预先设定簇的数量(k)。它根据数据的密度自动决定簇的数量,这对于不确定簇数的数据集非常有用。
- 能够识别噪声:DBSCAN能够自动识别噪声点(标记为 -1),并将这些点从聚类中分离出来。这对处理含有噪声或异常值的数据集特别有用。
- 处理大规模数据集时表现较好:在处理具有密集区域的较大数据集时,DBSCAN的表现较好,因为它只处理密度较高的区域,减少了计算量。
- 适应性强:对不同密度的簇也有较好的适应性,通过调整 eps 和 min_samples 参数,可以适应不同密度的数据。
缺点:
- 对参数敏感:DBSCAN对参数 eps(邻域半径)和 min_samples(最小样本数)非常敏感。选择不合适的参数值会导致聚类效果不好,例如将簇错误地合并或分裂,或将太多的点标记为噪声。在不同的数据集上,选择合适的参数往往需要实验和调优。
- 计算复杂度较高:DBSCAN在高维空间中的计算复杂度较高,因为它需要计算每对数据点之间的距离。特别是当数据量很大时,这个计算过程可能变得非常慢。
- 不适用于高维数据:在高维空间中,数据点之间的距离趋于相似(“维度灾难”),DBSCAN的效果可能会受到影响。高维空间中的密度定义变得模糊,因此可能导致聚类效果不理想。
- 无法处理极端不均匀的分布:如果数据集的分布极不均匀(例如某些簇非常密集而其他簇非常稀疏),DBSCAN可能无法很好地聚类,导致簇的质量下降。
# 评估不同 eps 和 min_samples 下的指标
# eps这个参数表示邻域的半径,min_samples表示一个点被认为是核心点所需的最小样本数。
# min_samples这个参数表示一个核心点所需的最小样本数。eps_range = np.arange(0.3, 0.8, 0.1) # 测试 eps 从 0.3 到 0.7
min_samples_range = range(3, 8) # 测试 min_samples 从 3 到 7
results = []for eps in eps_range:for min_samples in min_samples_range:dbscan = DBSCAN(eps=eps, min_samples=min_samples)dbscan_labels = dbscan.fit_predict(X_scaled)# 计算簇的数量(排除噪声点 -1)n_clusters = len(np.unique(dbscan_labels)) - (1 if -1 in dbscan_labels else 0) # 计算噪声点数量n_noise = list(dbscan_labels).count(-1)# 只有当簇数量大于 1 且有有效簇时才计算评估指标if n_clusters > 1:# 排除噪声点后计算评估指标mask = dbscan_labels != -1if mask.sum() > 0: # 确保有非噪声点silhouette = silhouette_score(X_scaled[mask], dbscan_labels[mask])ch = calinski_harabasz_score(X_scaled[mask], dbscan_labels[mask])db = davies_bouldin_score(X_scaled[mask], dbscan_labels[mask])results.append({'eps': eps,'min_samples': min_samples,'n_clusters': n_clusters,'n_noise': n_noise,'silhouette': silhouette,'ch_score': ch,'db_score': db})print(f"eps={eps:.1f}, min_samples={min_samples}, 簇数: {n_clusters}, 噪声点: {n_noise}, "f"轮廓系数: {silhouette:.3f}, CH 指数: {ch:.2f}, DB 指数: {db:.3f}")else:print(f"eps={eps:.1f}, min_samples={min_samples}, 簇数: {n_clusters}, 噪声点: {n_noise}, 无法计算评估指标")# 将结果转为 DataFrame 以便可视化和选择参数
results_df = pd.DataFrame(results)eps=0.3, min_samples=3, 簇数: 0, 噪声点: 7500, 无法计算评估指标
eps=0.3, min_samples=4, 簇数: 0, 噪声点: 7500, 无法计算评估指标
eps=0.3, min_samples=5, 簇数: 0, 噪声点: 7500, 无法计算评估指标
eps=0.3, min_samples=6, 簇数: 0, 噪声点: 7500, 无法计算评估指标
eps=0.3, min_samples=7, 簇数: 0, 噪声点: 7500, 无法计算评估指标
eps=0.4, min_samples=3, 簇数: 1, 噪声点: 7497, 无法计算评估指标
eps=0.4, min_samples=4, 簇数: 0, 噪声点: 7500, 无法计算评估指标
eps=0.4, min_samples=5, 簇数: 0, 噪声点: 7500, 无法计算评估指标
eps=0.4, min_samples=6, 簇数: 0, 噪声点: 7500, 无法计算评估指标
eps=0.4, min_samples=7, 簇数: 0, 噪声点: 7500, 无法计算评估指标
eps=0.5, min_samples=3, 簇数: 21, 噪声点: 7425, 轮廓系数: 0.619, CH 指数: 591.52, DB 指数: 0.486
eps=0.5, min_samples=4, 簇数: 5, 噪声点: 7476, 轮廓系数: 0.663, CH 指数: 673.01, DB 指数: 0.504
eps=0.5, min_samples=5, 簇数: 1, 噪声点: 7495, 无法计算评估指标
eps=0.5, min_samples=6, 簇数: 0, 噪声点: 7500, 无法计算评估指标
eps=0.5, min_samples=7, 簇数: 0, 噪声点: 7500, 无法计算评估指标
eps=0.6, min_samples=3, 簇数: 64, 噪声点: 7235, 轮廓系数: 0.462, CH 指数: 511.60, DB 指数: 0.776
eps=0.6, min_samples=4, 簇数: 22, 噪声点: 7377, 轮廓系数: 0.590, CH 指数: 1116.10, DB 指数: 0.624
eps=0.6, min_samples=5, 簇数: 7, 噪声点: 7447, 轮廓系数: 0.813, CH 指数: 1498.48, DB 指数: 0.251
eps=0.6, min_samples=6, 簇数: 6, 噪声点: 7452, 轮廓系数: 0.811, CH 指数: 1341.46, DB 指数: 0.253
eps=0.6, min_samples=7, 簇数: 2, 噪声点: 7486, 轮廓系数: 0.953, CH 指数: 2997.39, DB 指数: 0.061
eps=0.7, min_samples=3, 簇数: 104, 噪声点: 6820, 轮廓系数: 0.225, CH 指数: 153.23, DB 指数: 0.941
eps=0.7, min_samples=4, 簇数: 55, 噪声点: 7078, 轮廓系数: 0.261, CH 指数: 264.64, DB 指数: 0.908
eps=0.7, min_samples=5, 簇数: 26, 噪声点: 7259, 轮廓系数: 0.351, CH 指数: 548.11, DB 指数: 0.820
eps=0.7, min_samples=6, 簇数: 11, 噪声点: 7372, 轮廓系数: 0.411, CH 指数: 1161.50, DB 指数: 0.655
eps=0.7, min_samples=7, 簇数: 8, 噪声点: 7409, 轮廓系数: 0.416, CH 指数: 849.91, DB 指数: 1.041
| eps | min_samples | n_clusters | n_noise | silhouette | ch_score | db_score | |
|---|---|---|---|---|---|---|---|
| 0 | 0.5 | 3 | 21 | 7420 | 0.493932 | 89.643271 | 0.612520 |
| 1 | 0.5 | 4 | 5 | 7473 | 0.463183 | 83.112261 | 0.748730 |
| 2 | 0.6 | 3 | 56 | 7214 | 0.267180 | 58.953185 | 0.952780 |
| 3 | 0.6 | 4 | 21 | 7356 | 0.306341 | 72.516588 | 0.987645 |
| 4 | 0.6 | 5 | 7 | 7433 | 0.346922 | 42.556437 | 0.988006 |
| 5 | 0.6 | 6 | 6 | 7452 | 0.414377 | 48.321691 | 0.842974 |
| 6 | 0.6 | 7 | 2 | 7486 | 0.757909 | 109.895595 | 0.317504 |
| 7 | 0.7 | 3 | 90 | 6800 | 0.028382 | 22.652187 | 0.917994 |
| 8 | 0.7 | 4 | 39 | 7047 | -0.026360 | 20.195762 | 0.954573 |
| 9 | 0.7 | 5 | 15 | 7214 | -0.013375 | 26.353848 | 1.010414 |
| 10 | 0.7 | 6 | 5 | 7313 | 0.015271 | 25.901056 | 1.101364 |
| 11 | 0.7 | 7 | 5 | 7337 | 0.034993 | 26.038924 | 1.337139 |
# 绘制评估指标图,增加点论文中的工作量
plt.figure(figsize=(15, 10))
# 轮廓系数图
plt.subplot(2, 2, 1)
for min_samples in min_samples_range:subset = results_df[results_df['min_samples'] == min_samples] # plt.plot(subset['eps'], subset['silhouette'], marker='o', label=f'min_samples={min_samples}')
plt.title('轮廓系数确定最优参数(越大越好)')
plt.xlabel('eps')
plt.ylabel('轮廓系数')
plt.legend()
plt.grid(True)# CH 指数图
plt.subplot(2, 2, 2)
for min_samples in min_samples_range:subset = results_df[results_df['min_samples'] == min_samples]plt.plot(subset['eps'], subset['ch_score'], marker='o', label=f'min_samples={min_samples}')
plt.title('Calinski-Harabasz 指数确定最优参数(越大越好)')
plt.xlabel('eps')
plt.ylabel('CH 指数')
plt.legend()
plt.grid(True)# DB 指数图
plt.subplot(2, 2, 3)
for min_samples in min_samples_range:subset = results_df[results_df['min_samples'] == min_samples]plt.plot(subset['eps'], subset['db_score'], marker='o', label=f'min_samples={min_samples}')
plt.title('Davies-Bouldin 指数确定最优参数(越小越好)')
plt.xlabel('eps')
plt.ylabel('DB 指数')
plt.legend()
plt.grid(True)# 簇数量图
plt.subplot(2, 2, 4)
for min_samples in min_samples_range:subset = results_df[results_df['min_samples'] == min_samples]plt.plot(subset['eps'], subset['n_clusters'], marker='o', label=f'min_samples={min_samples}')
plt.title('簇数量变化')
plt.xlabel('eps')
plt.ylabel('簇数量')
plt.legend()
plt.grid(True)plt.tight_layout()
plt.show()

# 选择 eps 和 min_samples 值(根据图表选择最佳参数)
selected_eps = 0.6 # 根据图表调整
selected_min_samples = 6 # 根据图表调整# 使用选择的参数进行 DBSCAN 聚类
dbscan = DBSCAN(eps=selected_eps, min_samples=selected_min_samples)
dbscan_labels = dbscan.fit_predict(X_scaled)
X['DBSCAN_Cluster'] = dbscan_labels# 使用 PCA 降维到 2D 进行可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)# DBSCAN 聚类结果可视化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=dbscan_labels, palette='viridis')
plt.title(f'DBSCAN Clustering with eps={selected_eps}, min_samples={selected_min_samples} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()# 打印 DBSCAN 聚类标签的分布
print(f"DBSCAN Cluster labels (eps={selected_eps}, min_samples={selected_min_samples}) added to X:")
print(X[['DBSCAN_Cluster']].value_counts()) 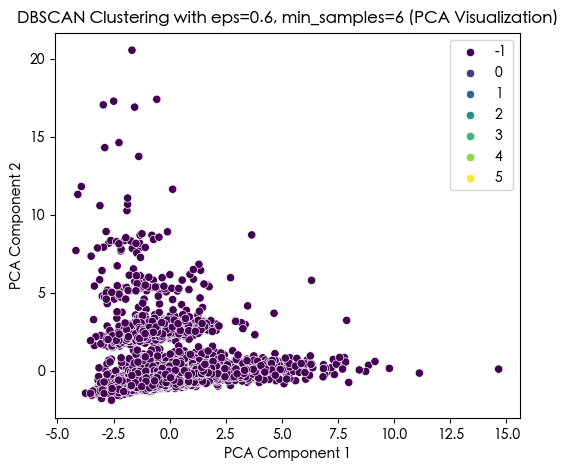
DBSCAN Cluster labels (eps=0.6, min_samples=6) added to X:
DBSCAN_Cluster
-1 7452
0 12
2 9
3 8
4 7
1 6
5 6
Name: count, dtype: int64
从结果来看 这个聚类是失败的 因为没有少数簇的数目太少,也可能是dbscan这个算法不太合适
层次聚类
Agglomerative Clustering 是一种自底向上的层次聚类方法,初始时每个样本是一个簇,然后逐步合并最相似的簇,直到达到指定的簇数量或满足停止条件。由于它需要指定簇数量(类似于 KMeans),我将通过测试不同的簇数量 n_clusters 来评估聚类效果,并使用轮廓系数(Silhouette Score)、CH 指数(Calinski-Harabasz Index)和 DB 指数(Davies-Bouldin Index)作为评估指标。
# 评估不同 n_clusters 下的指标
n_clusters_range = range(2, 11) # 测试簇数量从 2 到 10
silhouette_scores = []
ch_scores = []
db_scores = []for n_clusters in n_clusters_range:agglo = AgglomerativeClustering(n_clusters=n_clusters, linkage='ward') # 使用 Ward 准则合并簇agglo_labels = agglo.fit_predict(X_scaled)# 计算评估指标silhouette = silhouette_score(X_scaled, agglo_labels)ch = calinski_harabasz_score(X_scaled, agglo_labels)db = davies_bouldin_score(X_scaled, agglo_labels)silhouette_scores.append(silhouette)ch_scores.append(ch)db_scores.append(db)print(f"n_clusters={n_clusters}, 轮廓系数: {silhouette:.3f}, CH 指数: {ch:.2f}, DB 指数: {db:.3f}")# 绘制评估指标图
plt.figure(figsize=(15, 5))# 轮廓系数图
plt.subplot(1, 3, 1)
plt.plot(n_clusters_range, silhouette_scores, marker='o')
plt.title('轮廓系数确定最优簇数(越大越好)')
plt.xlabel('簇数量 (n_clusters)')
plt.ylabel('轮廓系数')
plt.grid(True)# CH 指数图
plt.subplot(1, 3, 2)
plt.plot(n_clusters_range, ch_scores, marker='o')
plt.title('Calinski-Harabasz 指数确定最优簇数(越大越好)')
plt.xlabel('簇数量 (n_clusters)')
plt.ylabel('CH 指数')
plt.grid(True)# DB 指数图
plt.subplot(1, 3, 3)
plt.plot(n_clusters_range, db_scores, marker='o')
plt.title('Davies-Bouldin 指数确定最优簇数(越小越好)')
plt.xlabel('簇数量 (n_clusters)')
plt.ylabel('DB 指数')
plt.grid(True)plt.tight_layout()
plt.show()n_clusters=2, 轮廓系数: 0.256, CH 指数: 579.09, DB 指数: 3.037
n_clusters=3, 轮廓系数: 0.210, CH 指数: 508.05, DB 指数: 2.699
n_clusters=4, 轮廓系数: 0.222, CH 指数: 456.16, DB 指数: 2.423
n_clusters=5, 轮廓系数: 0.244, CH 指数: 430.89, DB 指数: 2.291
n_clusters=6, 轮廓系数: 0.252, CH 指数: 417.20, DB 指数: 2.011
n_clusters=7, 轮廓系数: 0.263, CH 指数: 412.97, DB 指数: 1.798
n_clusters=8, 轮廓系数: 0.265, CH 指数: 414.19, DB 指数: 1.538
n_clusters=9, 轮廓系数: 0.269, CH 指数: 419.75, DB 指数: 1.372
n_clusters=10, 轮廓系数: 0.277, CH 指数: 428.73, DB 指数: 1.342
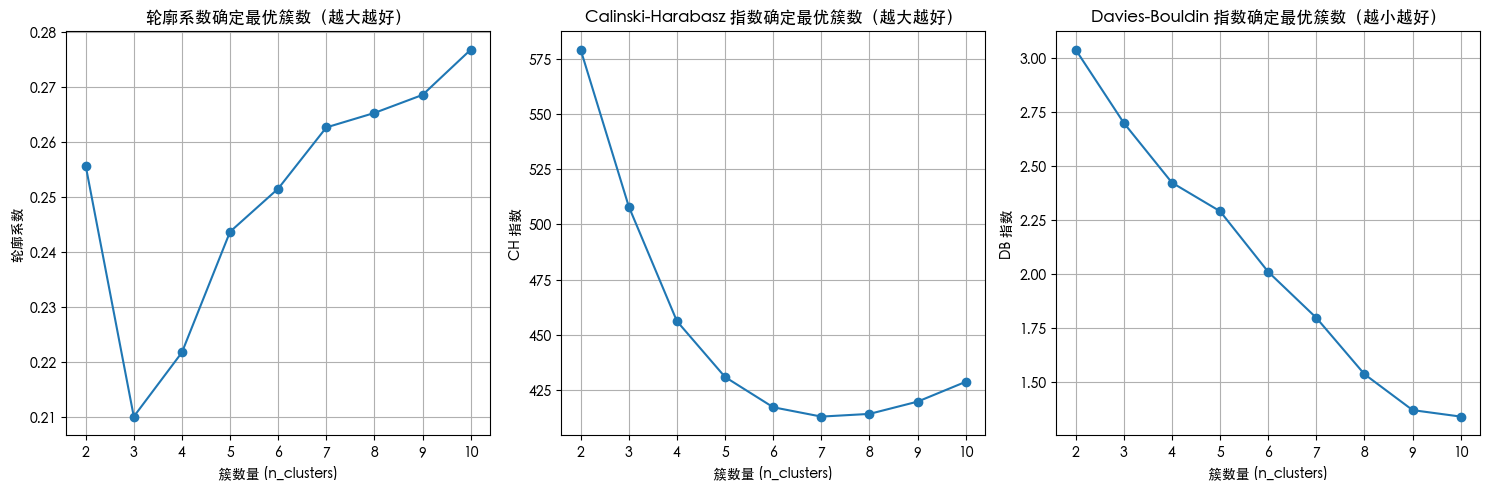
# 提示用户选择 n_clusters 值(这里可以根据图表选择最佳簇数)
selected_n_clusters = 10 # 示例值,根据图表调整# 使用选择的簇数进行 Agglomerative Clustering 聚类
agglo = AgglomerativeClustering(n_clusters=selected_n_clusters, linkage='ward')
agglo_labels = agglo.fit_predict(X_scaled)
X['Agglo_Cluster'] = agglo_labels# 使用 PCA 降维到 2D 进行可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)# Agglomerative Clustering 聚类结果可视化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=agglo_labels, palette='viridis')
plt.title(f'Agglomerative Clustering with n_clusters={selected_n_clusters} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()# 打印 Agglomerative Clustering 聚类标签的分布
print(f"Agglomerative Cluster labels (n_clusters={selected_n_clusters}) added to X:")
print(X[['Agglo_Cluster']].value_counts())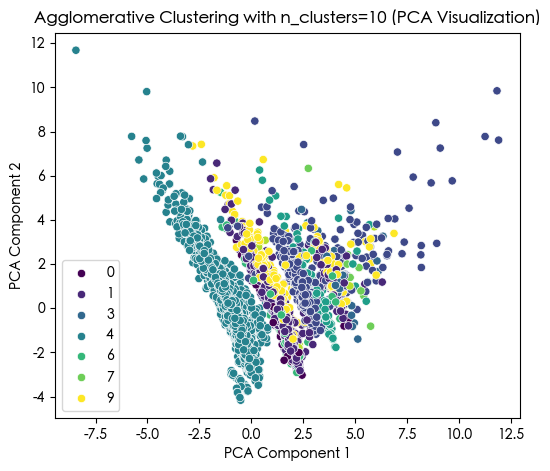
Agglomerative Cluster labels (n_clusters=10) added to X:
Agglo_Cluster
4 5230
1 778
2 771
9 409
5 127
6 96
0 37
3 34
7 10
8 8
Name: count, dtype: int64
# 层次聚类的树状图可视化
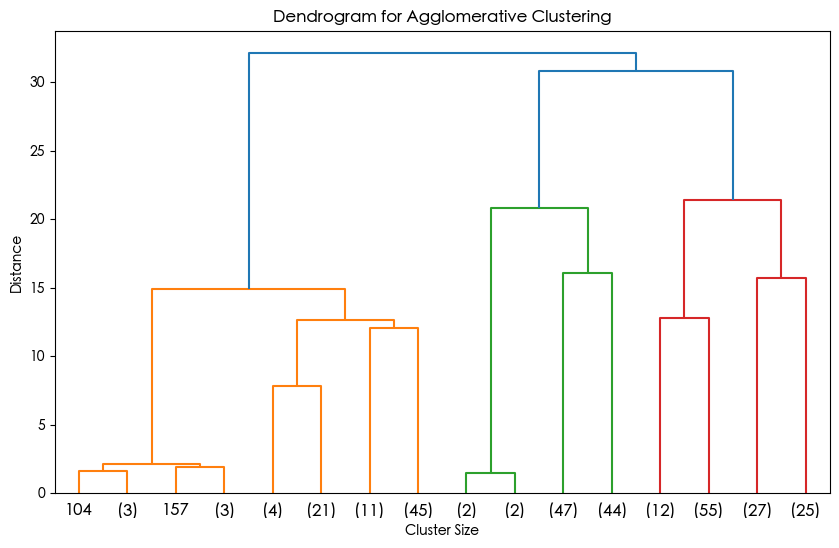
from scipy.cluster import hierarchy
import matplotlib.pyplot as plt# 假设 X_scaled 是标准化后的数据
# 计算层次聚类的链接矩阵
Z = hierarchy.linkage(X_scaled, method='ward') # 'ward' 是常用的合并准则# 绘制树状图
plt.figure(figsize=(10, 6))
hierarchy.dendrogram(Z, truncate_mode='level', p=3) # p 控制显示的层次深度
# hierarchy.dendrogram(Z, truncate_mode='level') # 不用p这个参数,可以显示全部的深度
plt.title('Dendrogram for Agglomerative Clustering')
plt.xlabel('Cluster Size')
plt.ylabel('Distance')
plt.show()
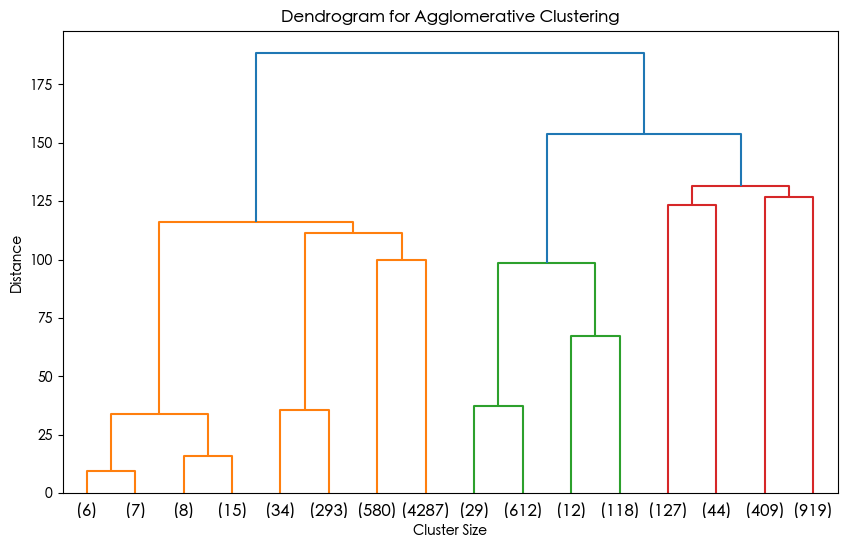
1. 横坐标代表每个簇对应样本的数据,这些样本数目加一起是整个数据集的样本数目。这是从上到下进行截断,p=3显示最后3层,不用p这个参数会显示全部。
2. 纵轴代表距离 ,反映了在聚类过程中,不同样本或簇合并时的距离度量值。距离越大,意味着两个样本或簇之间的差异越大;距离越小,则差异越小。
作业:对心脏病数据集进行聚类。
代码与上类似。
KMeans算法
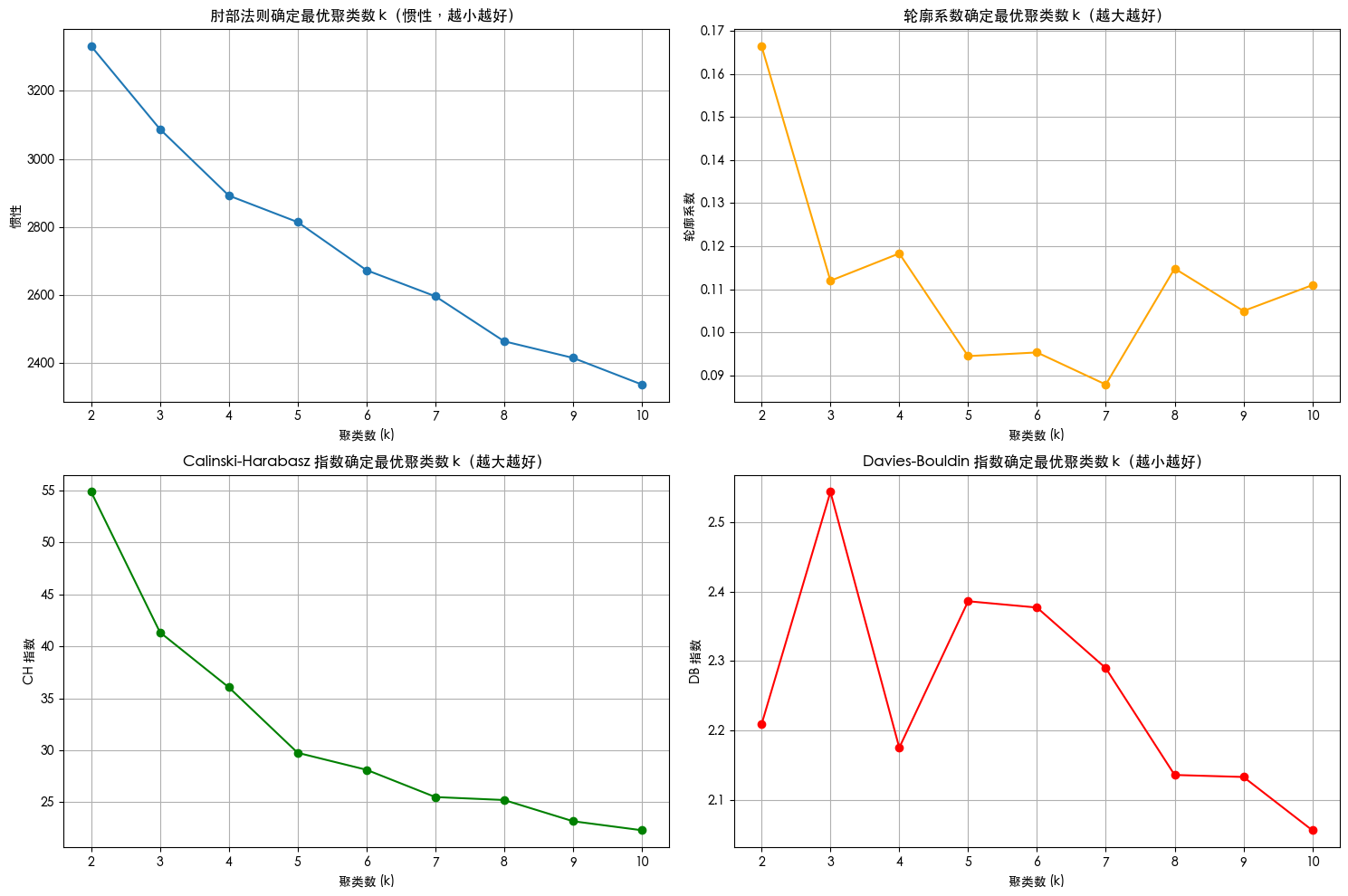
k=2, 惯性: 3331.64, 轮廓系数: 0.166, CH 指数: 54.87, DB 指数: 2.209
k=3, 惯性: 3087.69, 轮廓系数: 0.112, CH 指数: 41.36, DB 指数: 2.544
k=4, 惯性: 2892.52, 轮廓系数: 0.118, CH 指数: 36.06, DB 指数: 2.175
k=5, 惯性: 2814.65, 轮廓系数: 0.094, CH 指数: 29.76, DB 指数: 2.386
k=6, 惯性: 2673.22, 轮廓系数: 0.095, CH 指数: 28.13, DB 指数: 2.377
k=7, 惯性: 2596.68, 轮廓系数: 0.088, CH 指数: 25.50, DB 指数: 2.290
k=8, 惯性: 2464.39, 轮廓系数: 0.115, CH 指数: 25.22, DB 指数: 2.136
k=9, 惯性: 2415.63, 轮廓系数: 0.105, CH 指数: 23.18, DB 指数: 2.133
k=10, 惯性: 2337.41, 轮廓系数: 0.111, CH 指数: 22.31, DB 指数: 2.056
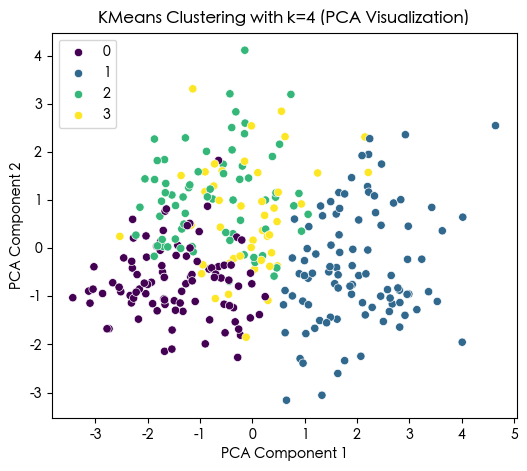
KMeans Cluster labels (k=4) added to X:
KMeans_Cluster
1 95
0 94
2 69
3 45
Name: count, dtype: int64
DBSCAN算法
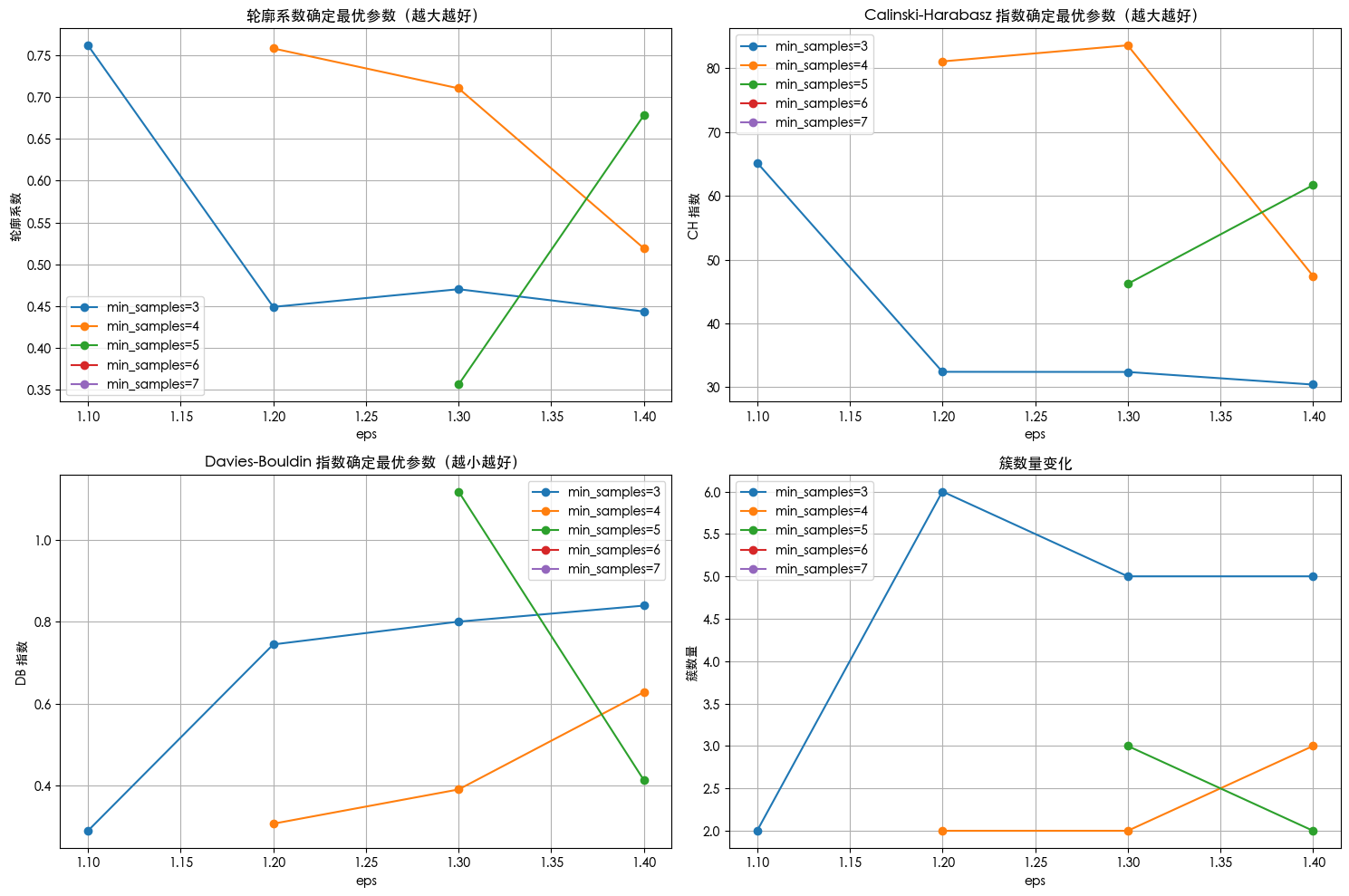
eps=1.0, min_samples=3, 簇数: 1, 噪声点: 299, 无法计算评估指标
eps=1.0, min_samples=4, 簇数: 1, 噪声点: 299, 无法计算评估指标
eps=1.0, min_samples=5, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=1.0, min_samples=6, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=1.0, min_samples=7, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=1.1, min_samples=3, 簇数: 2, 噪声点: 293, 轮廓系数: 0.762, CH 指数: 65.20, DB 指数: 0.289
eps=1.1, min_samples=4, 簇数: 1, 噪声点: 298, 无法计算评估指标
eps=1.1, min_samples=5, 簇数: 1, 噪声点: 298, 无法计算评估指标
eps=1.1, min_samples=6, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=1.1, min_samples=7, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=1.2, min_samples=3, 簇数: 6, 噪声点: 276, 轮廓系数: 0.449, CH 指数: 32.43, DB 指数: 0.745
eps=1.2, min_samples=4, 簇数: 2, 噪声点: 291, 轮廓系数: 0.758, CH 指数: 81.07, DB 指数: 0.306
eps=1.2, min_samples=5, 簇数: 1, 噪声点: 297, 无法计算评估指标
eps=1.2, min_samples=6, 簇数: 1, 噪声点: 297, 无法计算评估指标
eps=1.2, min_samples=7, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=1.3, min_samples=3, 簇数: 5, 噪声点: 272, 轮廓系数: 0.470, CH 指数: 32.40, DB 指数: 0.800
eps=1.3, min_samples=4, 簇数: 2, 噪声点: 285, 轮廓系数: 0.710, CH 指数: 83.59, DB 指数: 0.390
eps=1.3, min_samples=5, 簇数: 3, 噪声点: 288, 轮廓系数: 0.356, CH 指数: 46.21, DB 指数: 1.119
eps=1.3, min_samples=6, 簇数: 1, 噪声点: 297, 无法计算评估指标
eps=1.3, min_samples=7, 簇数: 0, 噪声点: 303, 无法计算评估指标
eps=1.4, min_samples=3, 簇数: 5, 噪声点: 269, 轮廓系数: 0.444, CH 指数: 30.43, DB 指数: 0.840
eps=1.4, min_samples=4, 簇数: 3, 噪声点: 277, 轮廓系数: 0.519, CH 指数: 47.44, DB 指数: 0.628
eps=1.4, min_samples=5, 簇数: 2, 噪声点: 282, 轮廓系数: 0.678, CH 指数: 61.68, DB 指数: 0.413
eps=1.4, min_samples=6, 簇数: 1, 噪声点: 287, 无法计算评估指标
eps=1.4, min_samples=7, 簇数: 1, 噪声点: 288, 无法计算评估指标
| eps | min_samples | n_clusters | n_noise | silhouette | ch_score | db_score | |
|---|---|---|---|---|---|---|---|
| 0 | 1.1 | 3 | 2 | 293 | 0.761552 | 65.199077 | 0.288790 |
| 1 | 1.2 | 3 | 6 | 276 | 0.449204 | 32.426429 | 0.744683 |
| 2 | 1.2 | 4 | 2 | 291 | 0.757832 | 81.066008 | 0.306087 |
| 3 | 1.3 | 3 | 5 | 272 | 0.470332 | 32.404153 | 0.800453 |
| 4 | 1.3 | 4 | 2 | 285 | 0.710207 | 83.589483 | 0.389856 |
| 5 | 1.3 | 5 | 3 | 288 | 0.356453 | 46.209802 | 1.118833 |
| 6 | 1.4 | 3 | 5 | 269 | 0.443695 | 30.425917 | 0.839624 |
| 7 | 1.4 | 4 | 3 | 277 | 0.519161 | 47.442337 | 0.628003 |
| 8 | 1.4 | 5 | 2 | 282 | 0.677947 | 61.683418 | 0.412640 |
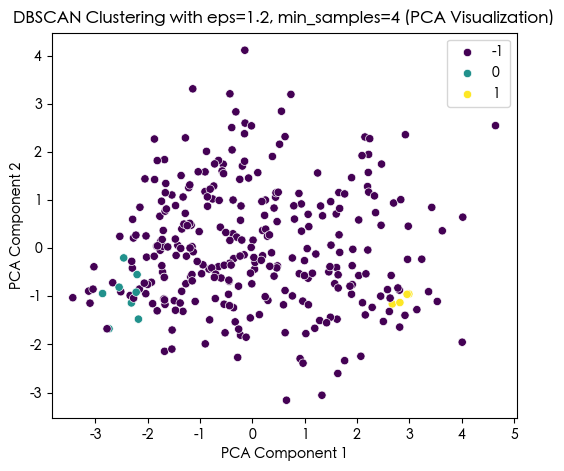
DBSCAN Cluster labels (eps=1.2, min_samples=4) added to X:
DBSCAN_Cluster
-1 291
0 8
1 4
Name: count, dtype: int64
层次聚类
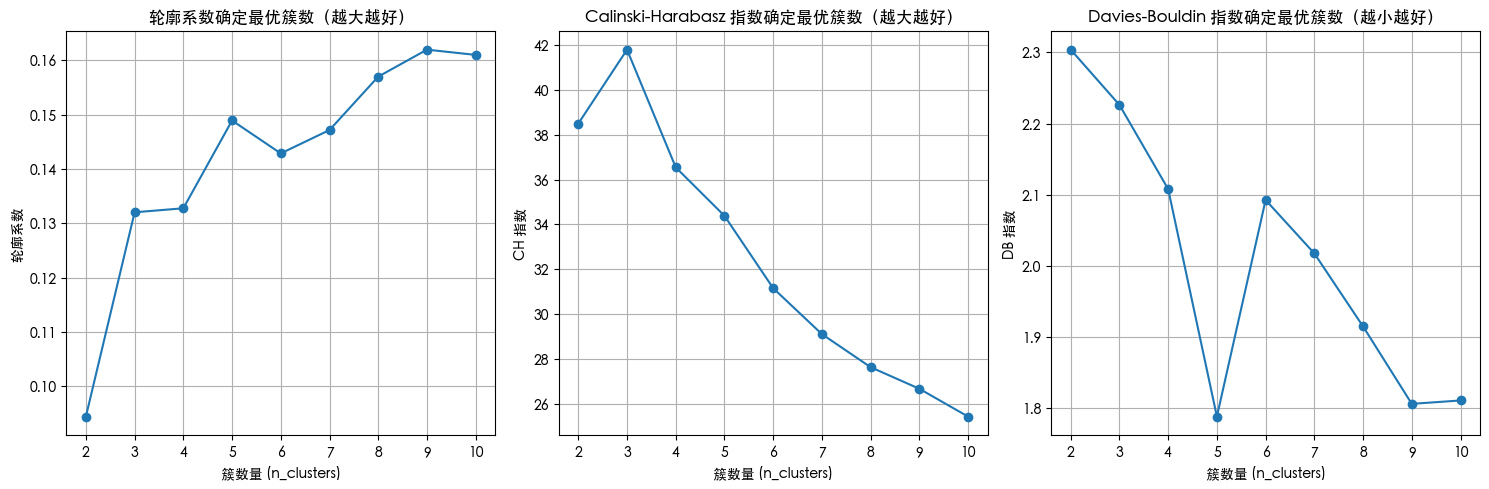
n_clusters=2, 轮廓系数: 0.094, CH 指数: 38.49, DB 指数: 2.304
n_clusters=3, 轮廓系数: 0.132, CH 指数: 41.78, DB 指数: 2.226
n_clusters=4, 轮廓系数: 0.133, CH 指数: 36.54, DB 指数: 2.108
n_clusters=5, 轮廓系数: 0.149, CH 指数: 34.38, DB 指数: 1.788
n_clusters=6, 轮廓系数: 0.143, CH 指数: 31.16, DB 指数: 2.093
n_clusters=7, 轮廓系数: 0.147, CH 指数: 29.12, DB 指数: 2.018
n_clusters=8, 轮廓系数: 0.157, CH 指数: 27.65, DB 指数: 1.915
n_clusters=9, 轮廓系数: 0.162, CH 指数: 26.69, DB 指数: 1.806
n_clusters=10, 轮廓系数: 0.161, CH 指数: 25.45, DB 指数: 1.811
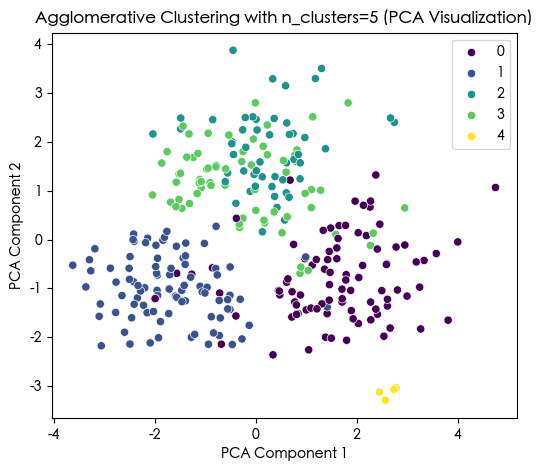
Agglomerative Cluster labels (n_clusters=5) added to X:
Agglo_Cluster
0 91
1 89
3 67
2 52
4 4
Name: count, dtype: int64
@浙大疏锦行