浙大公开课—基于深度学习的特征匹配与姿态估计
基于深度学习的特征匹配与姿态估计
Feature matching pipline
传统的特征匹配的流程。1. 输入图像 2. 局部特征提取 3.特征匹配

其中局部特征提取(Local Feature exture)中包含了两个核心的步骤。也就是特征点的检测和描述。
- Feature detection
- Feature description
我们建立的描述子是要进行匹配的,即要建立两个图像之间的对应关系。之后老师从两个角度解释了何为一个好的描述子。

- Distunctive得到的描述子具有好的辨识度。
- Invariant to image transformation对旋转缩放光线变化等具有稳定性才能便于匹配
Why Deep Learning
为什么要用深度学习去解决特征匹配的问题呢?
SIFT这种手工设计的描述子(handcrafted)尽管设计的十分巧妙可以适用绝大对数的场景但还是存在一些局限性。
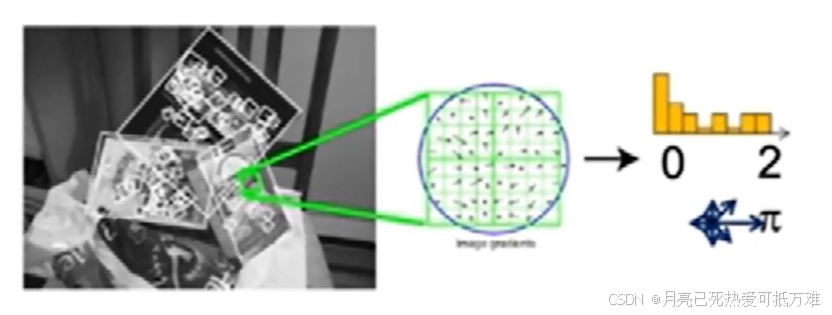
- 这种几何描述子更多的反应的是图像中的梯度变化这种几何信息,而没有使用语义信息,也就是缺少对整个图像的引用。
- 在图像中,纹理(texture)是指图像表面上局部灰度或颜色变化的空间分布模式和重复结构,在纹理特征出现由于光照变化或者运动模糊时候导致难以进行匹配。
现在最早的使用superpoint这种深度学习方法,和传统的SIFT方法的对比情况。如下所示

基于深度学习的方法在光线明显发生变化的情况下能够找到更多的匹配。
之后开始介绍这种基于深度学习的方法是如何进行实现的呢?
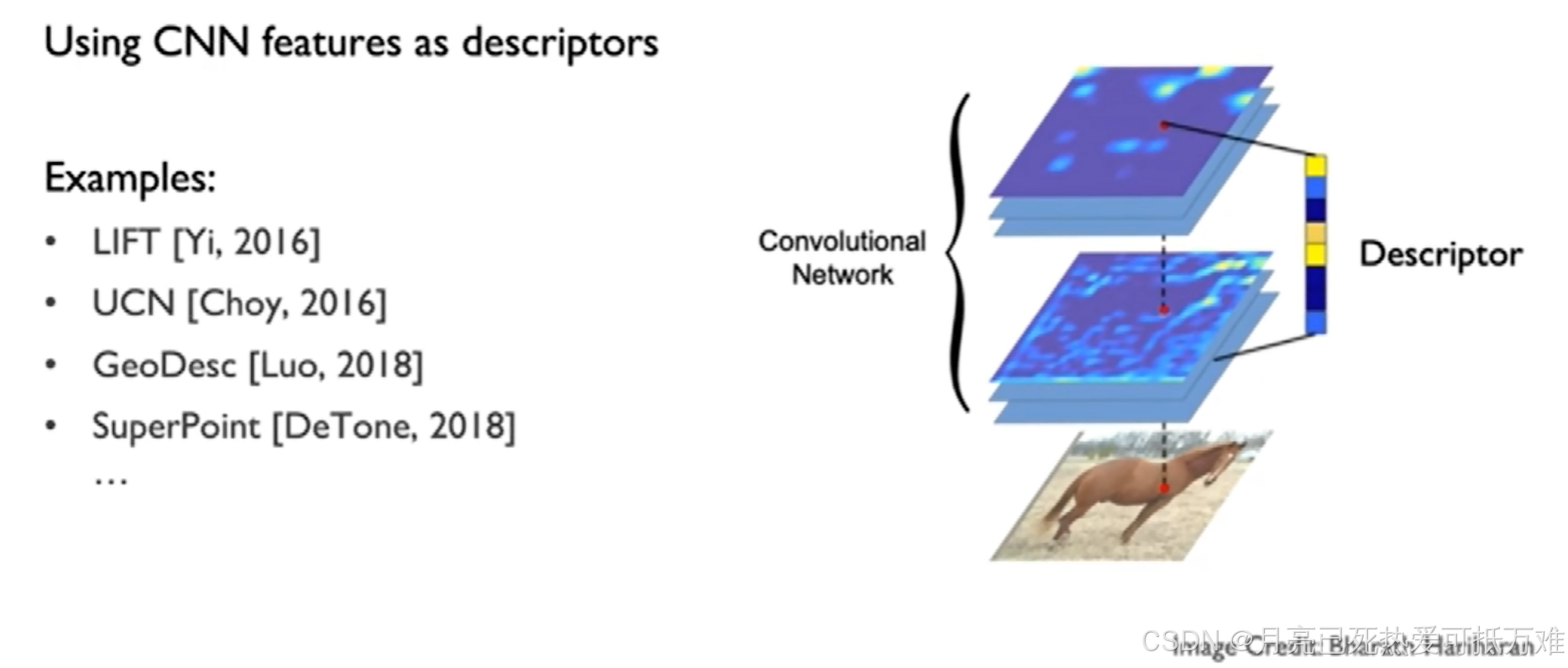
使用CNN网络对输入的图像进行特征的提取,在经过多层的卷积和下采样的操作之后。会得到多层的feature map。我们的特征图和原图像在空间上是能够进行对齐的。用提取的特征图上对应原图像上的特征点即可作为一个描述符进行使用。
通过类似对比损失的损失函数来训练detetor可以提取到好的合适的描述子。
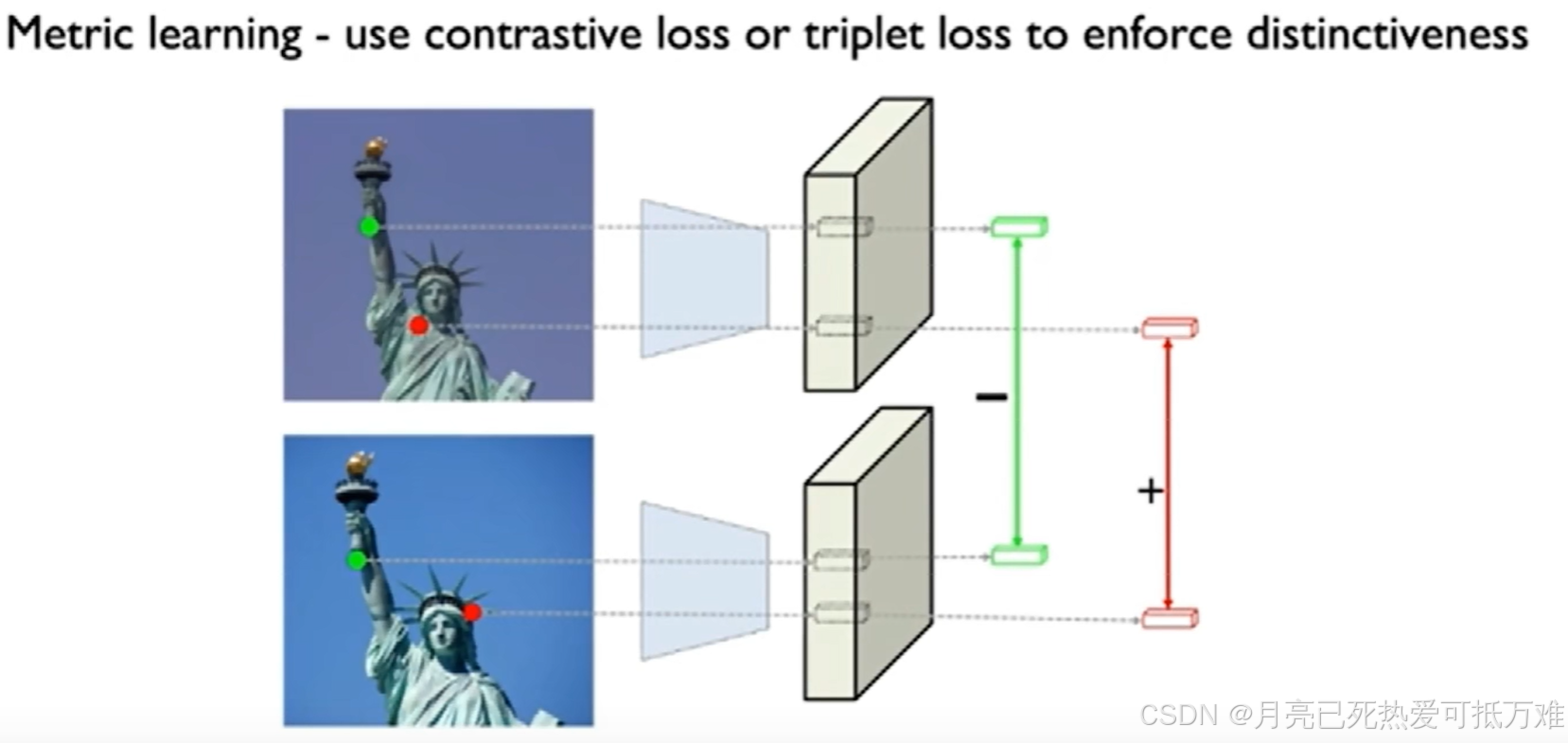
在相同的两个点上描述子的差距最小,在不同的描述子上的差距变大的一种自监督的方式。
这里我之前写做第一篇论文的时候也有疑惑,老师进行了解释。在训练数据的过程中这些点的对应关系是怎么来的呢?
训练过程的错误的数据可以来自随机初始化的点,而正确的数据集主要是来自Structure from motion数据集也就是经常见到的SfM这种数据集中 将其中三维点云的数据从多个角度投影到二维的平面上就可以得到多张正确的点匹配关系。
一个典型 SfM 数据集一般包括:
-
多视角图像(几十到几千张)
-
已知或需要重建的相机外参(有些提供 ground truth 相机位姿)
-
稀疏点云或密集点云(有时作为参考)
-
部分有 ground truth 三维模型(用于评估)
| 数据集 | 简介 | 大小(粗略) | 格式/用途 |
|---|---|---|---|
| ETH 3D / Strecha dataset | 少量高分辨率城市/建筑,提供标定相机位姿和稠密模型 | 小:几百 MB | 测试 SfM pipeline 精度 |
| COLMAP datasets | 作者提供的室内外小场景,几十张图 | 小:几百 MB | 验证算法、测试调参 |
| Tanks and Temples | 室内外复杂场景,高质量 mesh ground truth | 数 G | 测 dense reconstruction 精度 |
| DTU dataset | 有控制台架拍摄、多视角、多光照,带稠密点云 ground truth | 数 G | 多视图立体、稠密 SfM |
| Middlebury multi-view | 小场景,少量高分图像 | 数百 MB | 测 dense multi-view stereo |
| PhotoTourism (旧版 SFM dataset) | 如 Venice, Notre Dame 等 | 数百 MB–数 G | 点匹配+SfM |
| 1DSfM | 来自 Flickr 的真实图,几十个景点,每个有几百到几千张图 | 几 G | 大规模 SfM、鲁棒性测试 |
| MegaDepth | 大量来自互联网的旅游照片+SfM 点云+稠密深度 | ~80G | 训练 SfM / 深度预测 |
| ScanNet | RGB-D 视频,室内场景 | 数百 G | SfM+稠密重建+场景理解 |

这里存在的问题是在重建的过程中还是使用SIFT来进行匹配。也就是对应关系的产生还是利用的SIFT可能导致训练完成的效果也就是在sift的水平上。
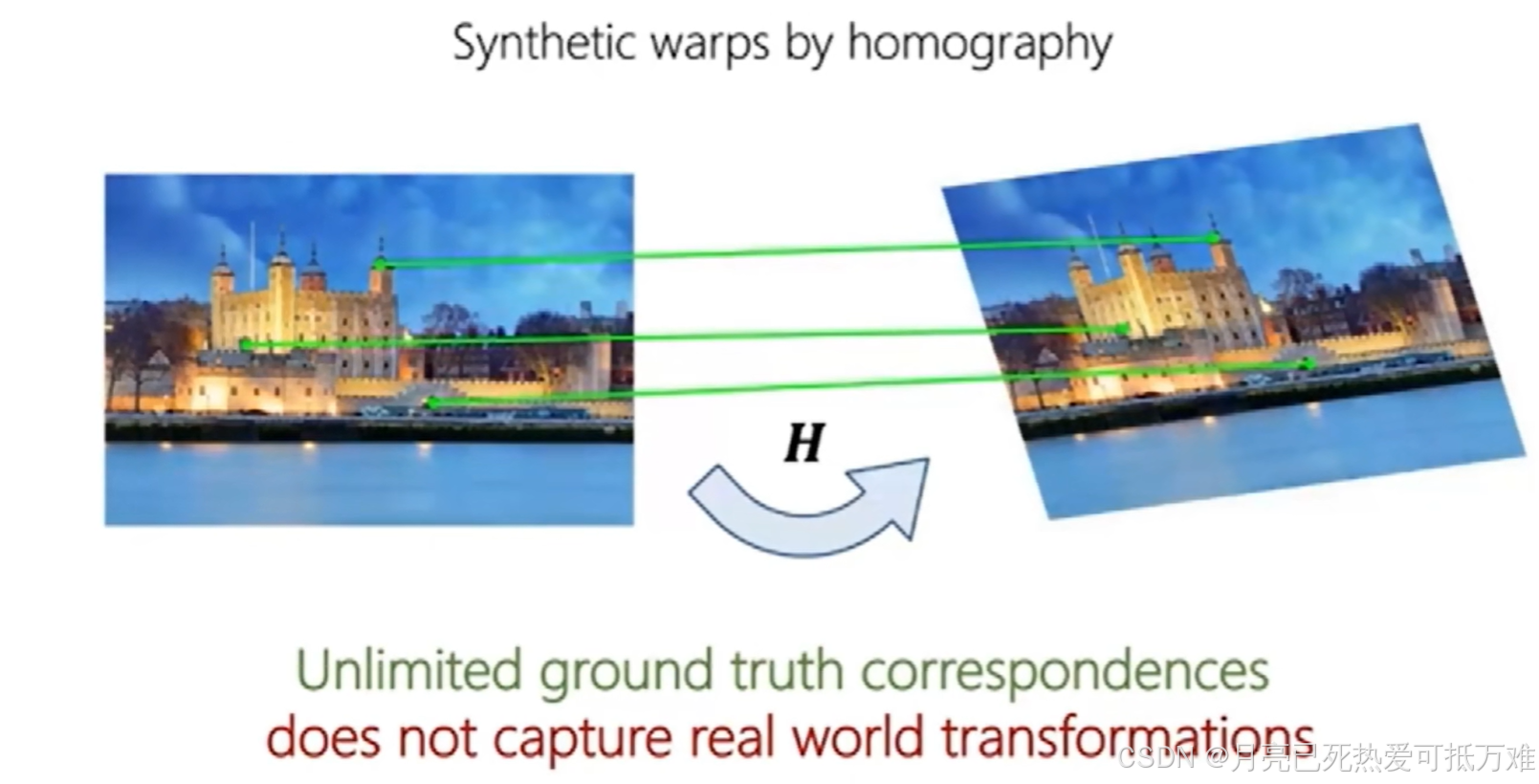
第二种方式就是在已知特征点的情况下进行二维的变化,比较局限难以反应三维的场景。
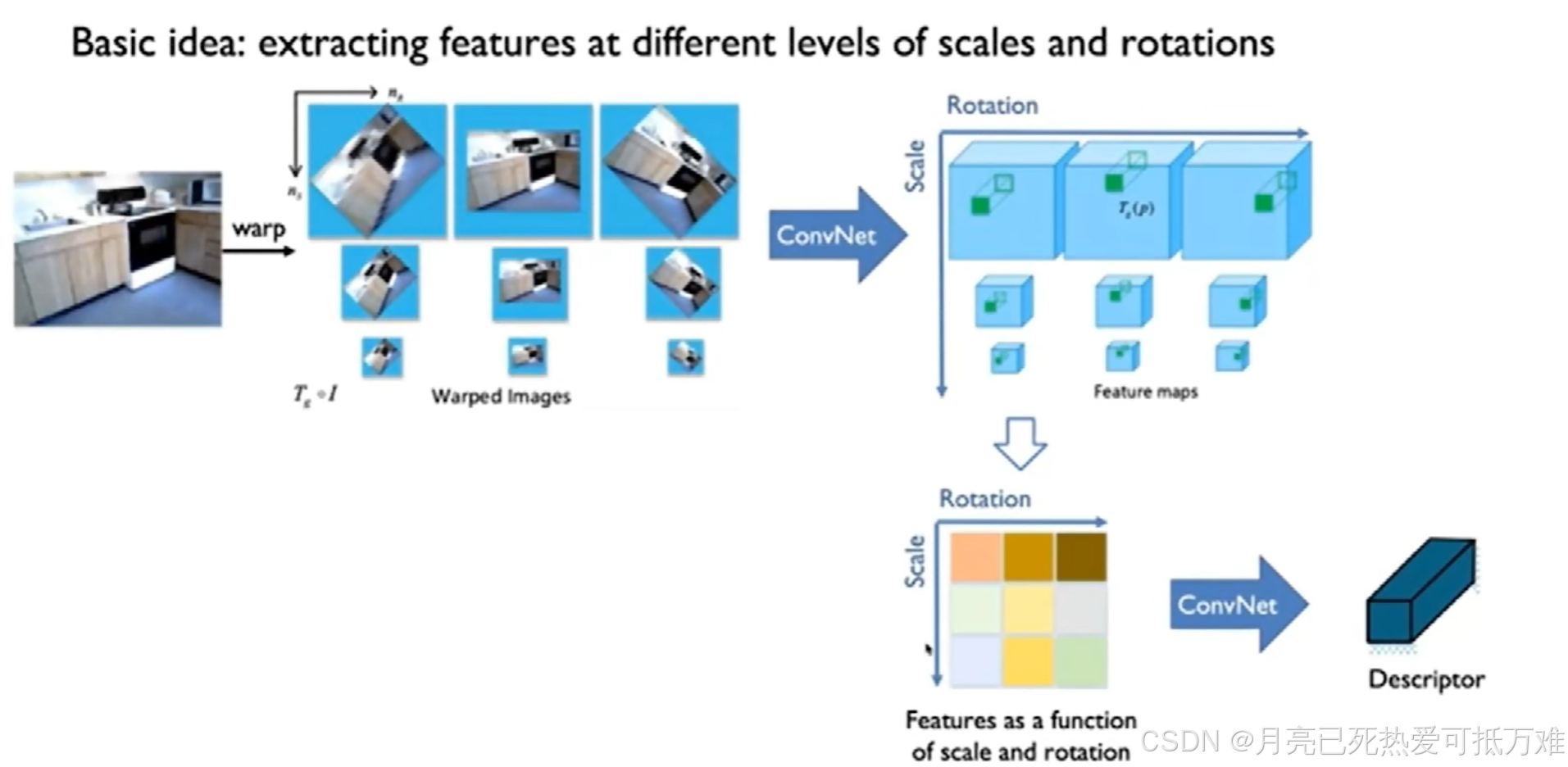
老师提出的方法:利用只包含pose的的数据集就可以进行监督。在更大的数据集上进行训练得到更好的效果。

之后通过一个例子说明了,通过学习的方式产生的描述子对光线的变化比较鲁棒但对于几何的变化上例如缩放和旋转等就比较难产生好的效果。
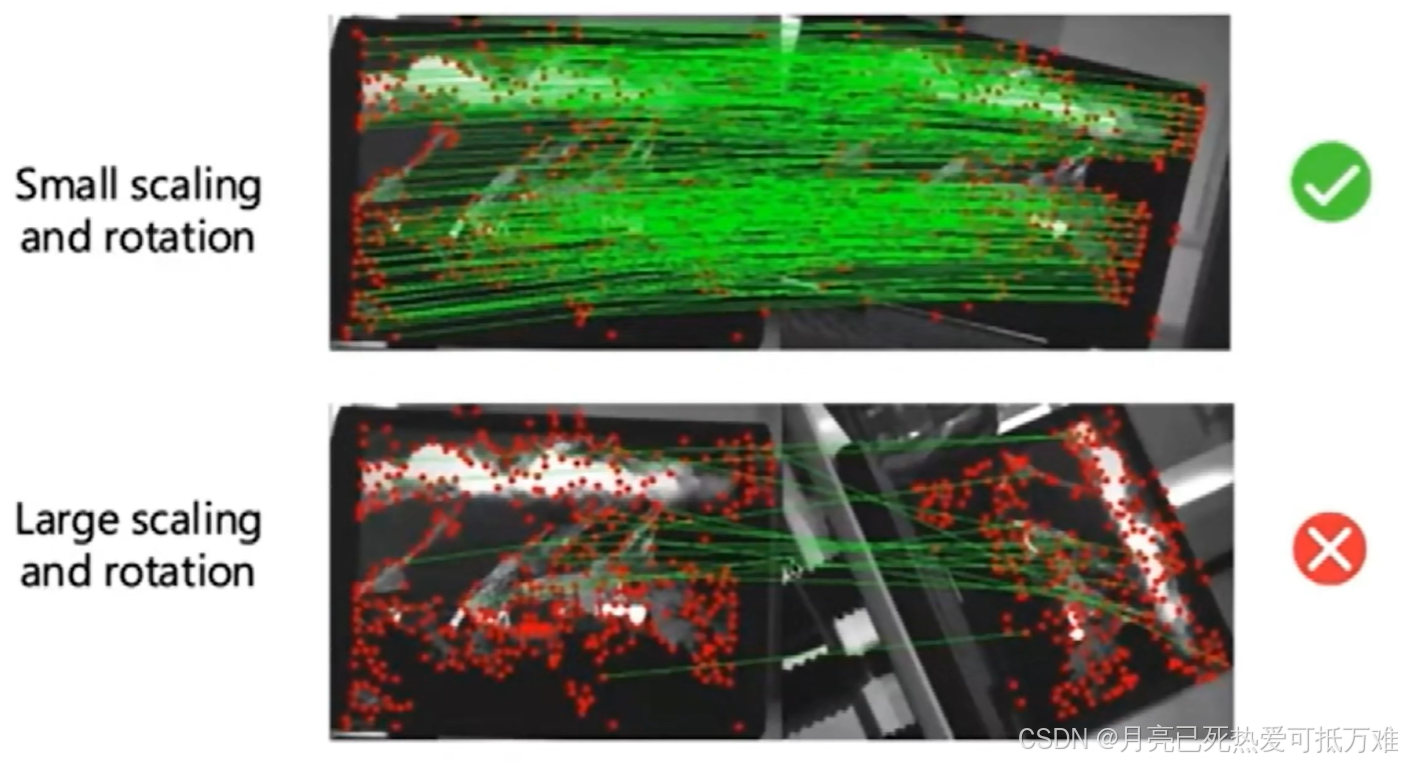
这种现象最终产生的原因是什么呢?之后给出了简要的说明。
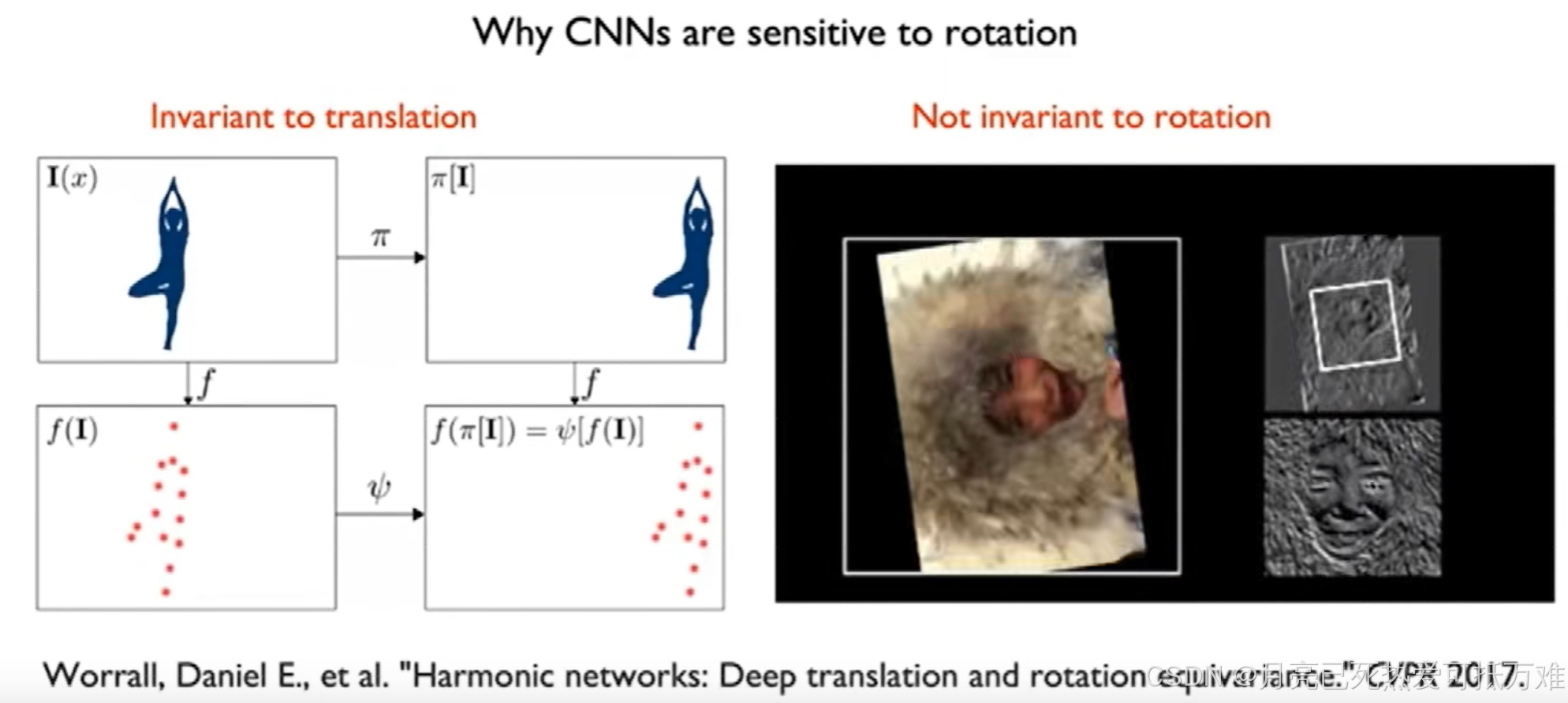
卷积操作对于平移来说具有不变性,但是对于旋转之后的特征就会发生难以预测的变化。


物体位姿估计介绍
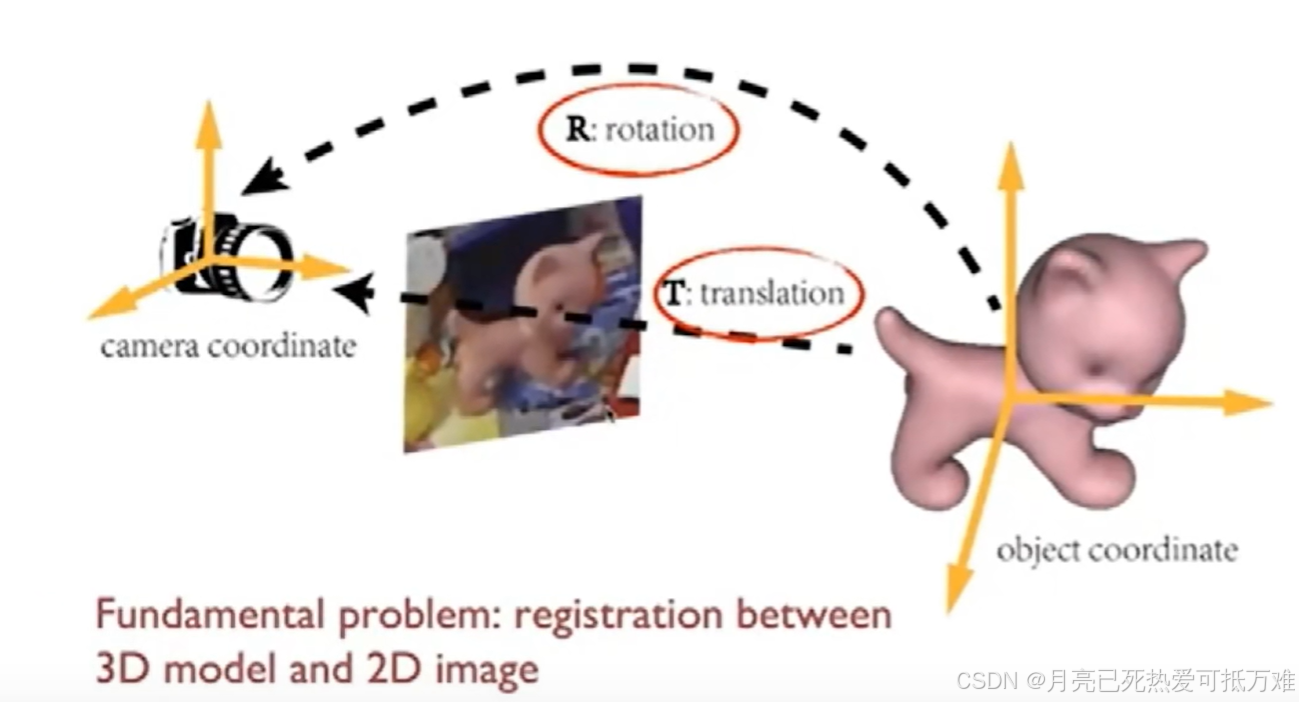
主要的一个应用是利用训练的一个映射网络实现三维上的点坐标到二维上的点坐标的一个应用。和之前点跟踪中的一个双射网络的思想是一样的,2d-3d-2d空间进行点的跟踪。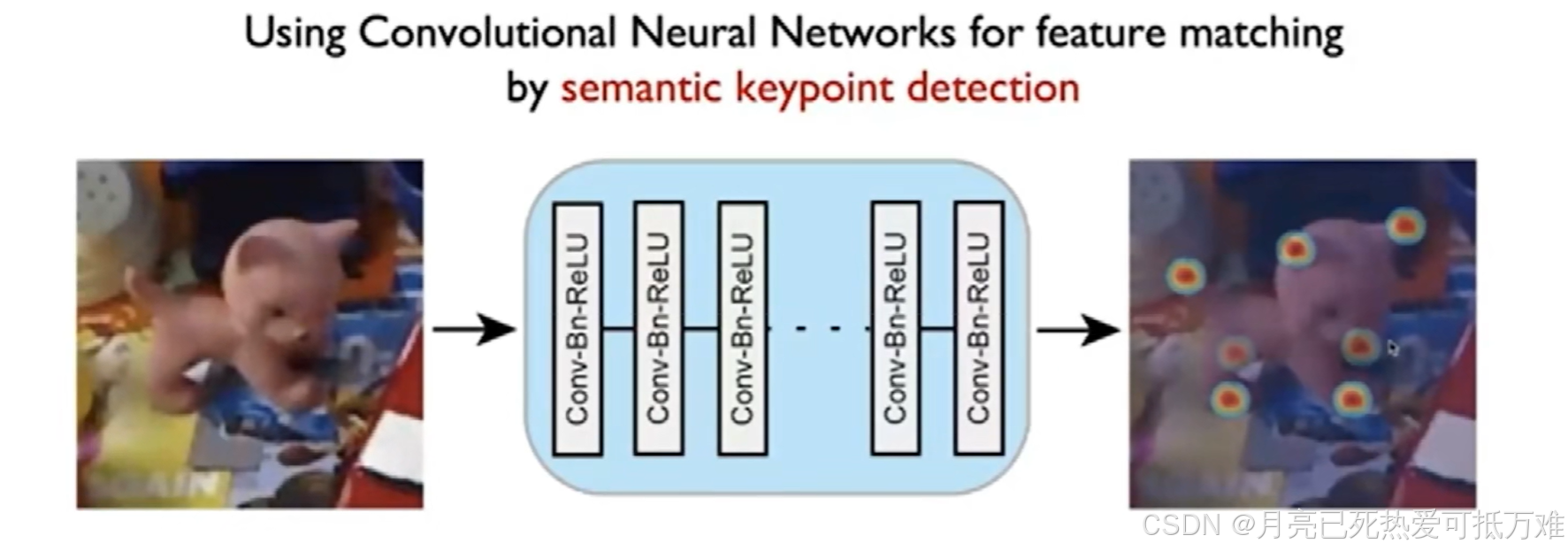


根据这种位姿估计的关系是可以实现目标之间的有效跟踪的。