kaggle房价预测-0.12619-排名:757
代码在此处:DL-House_Prices | Kaggle
目录
数据获取和分析
数据下载和读取
数据合并
探索性数据分析
数据预处理
数据清洗
缺失值的填充
连续特征标准化
特征编码
特征选择
皮尔逊相关
互信息
Lasso
RFE
降维分析
PCA
T-SNE
模型选择训练以及评估
SVR+15折+RMSLE
RF+15折+RMSLE
XGboost+15折+RMSLE
词嵌入+XGboost
预测房价
心得
数据获取和分析
数据下载和读取

首先导入不同的模块,包括hashlib用于生成哈希值,用来验证文件完整性;os:提供操作系统相关的功能,如文件路径操作;tarfile处理tar格式压缩的文件;zipfile处理zip格式压缩文件;requests用来发起网络请求。然后定义一个空字典用来存储后续的数据,以及一个基础数据下载网站的URL。

定义下载数据集函数,接受name就是我们定义在DATA_HUB中需要下载的文件名以及下载的路径。assert是该函数要允许需要满足的条件,获取数据对应的url和文件的哈希值用于验证数据的完整性。会自动创建目录,将数据集缓存在本地目录中,并返回下载文件的名称。

定义了两个下载相关函数,分别是download_extract可以自动下载压缩文件并解压,方便快速获取数据;download_all可以一键下载DATA_HUB中所有文件,用于一开始批量准备环境。

后续代码是自己完成的,所以不需要d2l了,首先导入相关包,使用魔法命令用于更好的显示图片,numpy数组,pandas,torch用于张量的计算还有神经网络。

接下来就可以读取数据,并查看数据的形状了,训练集有1460个样本,测试集有1459个样本,有80个特征,训练集多的是房价SalePrice。
数据合并

除去Id,保留特征,把训练集的标签也分离出来,因为后续训练集和测试集需要一起做特征编码。

使用concat方法,按照0轴合并

局部数据展示,合并之后有2919个样本,79个特征。
探索性数据分析
从局部数据的展示可以看出,比如Alley特征是有缺失值的NaN,因此我们有必要,先处理缺失值。


这段代码用于统计合并数据的缺失值的个数。

可以发现合并数据的样本一共2919个,上述图中前三个特征的缺失值的占比都在90%以上,因此后续应该删除,第四个占80%、第五个占60%,后续也应该考虑删除。

最初,我并没有在意房价的范围,是当我计算损失函数的时候,发现,如果不改变房价的分布,或者说做一些标准化,那么损失的值将会很大,因此这是很关键的步骤。经过我的反思,在处理分类任务的时候,要关注类别的占比,处理回归任务也是同样的,要对标签的分布进行分析。因此,我绘制了原始标签的分布直方图和经过对数转换之后的分布直方图如下。

原始房价呈现左偏态分布,说明很多房价较低,高价房比较少,经过对数变换之后缩小了数据的偏态,使得标签更接近正态分布,有利于后续模型构建和评估。

接下来是统计数值型特征的个数,一共有36个,并展示了前9个特征的分布情况,发现都不是正态分布。

为了进一步确定36个特征的分布,使用Shapiro-Wilk检验,用于检验正态分布,发现所有特征均不是正态分布。

可以提示我们后续建模,或许更倾向于非线性模型。
上述是对数值型特征的分析,接下来是对字符串型的特征的分析。

一共有43个字符型的特征,对于的每个特征的类别的个数统计如下:


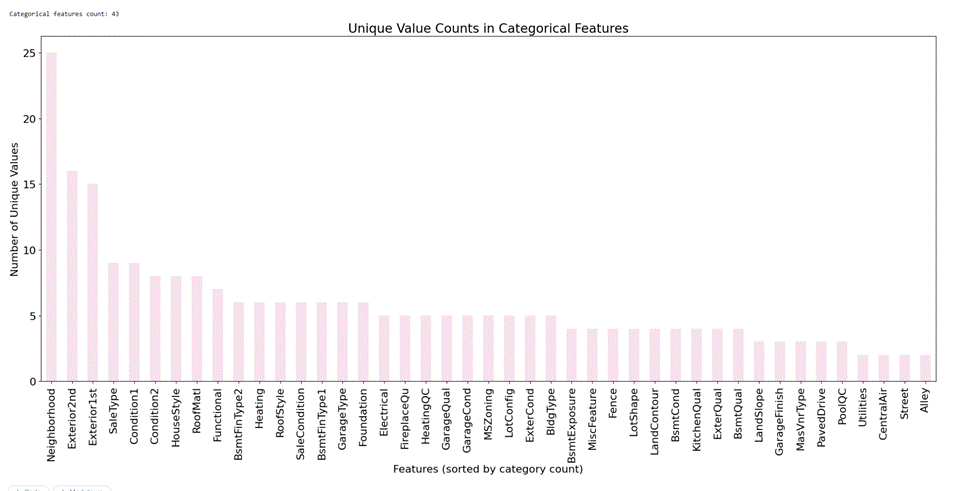
知道每个类别特征的类别个数,便于后续进行特征编码的时候,使用不同的方法,特征值类型很多的可能要考虑one-hot编码,特征只有两个的就可以是0、1编码,如果是有序特征就可以使0,1,2,3…等等。
下面对数值型的特征查看他们与标签皮尔逊相关性,相关性越高就说明,该特征可以对于预测标签房价比较重要。


可以看到前4个特征的相关性都比较高,那么可视化这个4个特征。


发现他们确实和标签有正相关的关系。

紧接着查看数值型特征和特征之间的相关性,如果相关性比较高,那么可能就是冗余的特征,可以考虑删除。

可以发现大多数的颜色都比较浅,只有少数几个相关性高,可能是冗余特征。

发现了4对冗余特征,的相关性在0.8以上,后续考虑删除一半,保留一半。
保留['YearBuilt','TotalBsmtSF','GrLivArea','GarageArea']
删除[' GarageYrBlt','1stFlrSF','TotRmsAbvGrd','GarageCars']
这是我自己后续不断的尝试不同的特征,得出的结果。
随后查看建筑年份和房价的关系


发现除了1880-1900年有一个极增极降之外,其余年份,都比较正常,随着年份的增加,房价也在增加。

以及房价和房子整理的面积和质量也有一个正相关的关系。
经过上述的分析,大致了解了数据的全貌,包括,对冗余特征的删除,含有缺失值特征的处理,以及后续建模的方法考虑非线性模型。接下来就进入数据预处理
数据预处理
数据清洗


删除缺失率大于60%的特征,共有5个。

删除上述分析得到的皮尔逊相关系数在0.8以上的4个特征。

现在数据的特征有70个。
缺失值的填充



我定义了一个比较麻烦的缺失值填充函数,是因为数据中不仅有连续的数据,还要离散的字符串数据,所以不能简单粗暴的使用均值或者中位数填充,并且测试数据和训练数据应该合在一起处理,确保离散数据的完整性。处理合并之后的数据中的缺失值,数值型特征用中位数填充比平均值更抗异常值,能让数据更稳定。字符串特征,也就是有分类的特征,分类变量按不同类别处理,对于有序分类特征,首先降缺失值用虚构的值填充,填充完后用,众数填充剩余的空值,能保留等级关系。二值分类特征,只有两个取值,先映射为0,1之后,同样用众数填充,没有排序关系的变量也用众数。最后如果还有缺失,用前后填充补充,确保没有空缺。
缺失值填充之后的部分数据展示。
连续特征标准化
同样因为数据特征的原因,对于分类类型的特征不需要标准化,但是数值型特征需要标准化,因为要消除不同特征之间的量纲,比如房屋面积和房屋类型的个数的特征的值就会差距很大。而且必须在分类特征编码之前标准化,因为,分类特征编码之后,所有的特征值都变成了数值型,所以就不好区分分类特征和数值型特征了。训练集和测试集也需要分开,不然标准化的时候会造成数据泄露。


展示部分训练集标准化之后的数据。

接下来又要合并数据,因为特征编码的时候需要训练集测试集一起,避免露掉一些类别值。
特征编码


上述是我定义的特征编码的类,用于自动化特征编码器,根据特征类型自动选择编码方式:有序分类特征:使用OrdinalEncoder、二值分类特征:手动映射为0或1、名义分类特征:使用OneHotEncoder。ordinal_features是有序特征字典 {特征名: [类别列表,从低到高]};binary_features是二值特征字典 {特征名: {'类别1':0, '类别2':1}}。

下面是编码后的结果,字符串型的特征就变成了数值了,这样机器就可以学习了,特征也从70维变到了204维。但是比书上的少,书上的300多维。后续我还会进行特征选择。


继续分开训练集和测试集,只用训练集来选择特征和建模。
特征选择
我尝试了很多方法,但是最后只选用了RFE特征递归消除,因为RFE选出来的特征的效果最好。
皮尔逊相关
在探索性分析部分我们已经分析处理几个与房价有线性相关的特征,现在设定0.6的阈值把特征选出来,作为我们重点特征。

互信息
在数据的特征中,除了考虑线性特征,同样要考虑非线性特征。因此我们使用SelectKBest结合互信息衡量连续特征与连续目标变量之间关系。互信息是一种衡量两个变量在统计上依赖关系的指标,值越高表示变量之间的关系越强。我选择使用 mutual_info_regression 作为评分函数,是因为它能捕捉特征与目标之间的非线性依赖关系。通过选择得分较高的特征,我们能够保留对目标影响最大的特征,从而简化模型、减少过拟合,同时提升预测能力。

处理互信息与皮尔逊相关找到的特征,取并集之后发现,皮尔逊相关特征被包含在互信息找到的特征中。

Lasso
Lossa回归是一种带有L1正则化的线性回归方法,L1惩罚促使很多系数变为零,从而实现特征的自动选择。系数非零的特征可能是对模型贡献较大的特征。


找到了75个特征。

将前面的(“皮尔逊相关”|“互信息”)&“Lasso”经过这样运算,最终得到了91个特征。可以用这91个特征尝试建模,如果还是觉得特征比较多,可以继续使用RFE筛选特征。
RFE
接下来利用RFE递归特征消除,结合XGboost回归模型逐步筛选出重要特征。它能够递归地评估每个特征的重要性,逐步除去对目标影响较小的特征,从而筛选出最具代表性的特征集,这样可以提升模型的效率和准确性。XGBoost的非线性建模能力也确保了筛选过程对复杂关系的适应性。最终得到了45个特征。
如果只是将原始的特征编码之后的数据有204维,用REF则最终剩下的102维度,后续的PCA降维都是基于102维特征进行,在后续讨论中我会说明,为什么不使用45个特征。


下面是原始特征RFE之后的结果

降维分析
PCA

PCA主成分分析是一种线性降维技术,找出数据中最大方差的方向(主成分),用较少的维度保留最多的原始信息。通过散点图,将每个样本点在降维空间中展示,颜色代表对应的标签值房价。

通过降维图,我发现数据在PC1和PC2的方向上都有两个明显聚类的趋势,并且随着PC1的增加,颜色向黄色趋近,也就是PC1和房价有一个正相关的趋势。
T-SNE

t-SNE通过模拟高维空间中点之间的概率分布,将数据点映射到低维空间,保持局部邻近关系。

t-SNE能捕捉非线性关系,通过观测t-SNE结果的局部簇和颜色的变化,可以判断该数据的特征存在潜在的非线性关系或簇结构。我发现确实有局部的聚类关系,并且整个散点都比较分散。
模型选择训练以及评估
根据上述数据的分析,特征中非线性的信息更多,因此选择模型尽量选择的非线性模型。
SVR+15折+RMSLE
SVR是SVM的回归版本,用于寻找一个最大程度地在某个容差范围内的预测函数,能有效处理高维稀疏数据。我使用的核函数是RBF高斯径向基,可以捕捉非线性关系。


首先对目标变量y进行对数变换,帮助模型更好的拟合偏态分布。
核函数是高斯径向基rbf,更好的捕捉非线性关系,设置惩罚系数为0.01、控制容忍噪声的范围是0.01、核函数的系数是scale能够自动缩放、以及允许无限训练迭代。然后创建空的字典,用于存储目标函数的值和评估指标的值以及特征重要性。设计交叉验证的循环,最好输出可视化的结果。RMSLE(Root Mean Squared Logarithmic Error,均方对数误差的平方根),测量预测值与实际值之间的差异,在值范围较大时更稳健;MAPE(Mean Absolute Percentage Error,平均绝对百分比误差):以百分比形式衡量平均预测误差。直观显示模型平均偏离实际值的百分比,更容易理解和解释。
最终结果是RMSLE为0.1313 ± 0.0534、MAPE为9.42% ± 4.14。
RF+15折+RMSLE
RF集成多个决策树,通过平均回归得到最终预测,有比较高的稳健性,能处理大量不同类型的数据,且不容易过拟合。


定义随机森林RF的模型,使用RandomForestRegressor进行回归,设置的森林的数量为1000、最大深度为12、内部分裂所需要的最小样本为5、叶子节点的最小样本为2、每次分裂时随机挑选特征最大的数据增加模型的多样性、设置15折交叉验证,和上述一样存储指标和特征重要性,进行交叉验证循环,最后输出结果。RMSLE为00.1400 ± 0.0228、MAPE为9.57% ± 1.24。
XGboost+15折+RMSLE
XGboost是一种基于梯度提升树的高效实现,此处用的是回归模型,具有高性能、快速训练的优势,也可以添加正则化约束。


构建XGBRegressor,设置树的总数为20000、学习率为0.01、最大深度是3、随机采样的比例是0.7、随机采样的特征比例也是0.7、L2的正则化参数为0.01、L1的正则化参数为0.01、随机种子为42、目标函数是平方误差、评估指标是均方根误差。学习率越小,意味着树的总量就会越多,树的深度越深,模型就会越复杂,所以需要正则化来约束。最终的结果就是RMSLE为0.1123 ± 0.0282、MAPE为7.95% ± 1.62,优于其他两个模型。
词嵌入+XGboost
这部分是尝试,没有过多的去调参。在数据预处理阶段,分类变量的特征编码,需要知道每个特征的值,因此我想如果直接将分类变量用词向量来表示,就不用那么复杂了。


上述代码就是在特征编码部分与其他不同,首先是建立TextVectorization层,定义词汇表大小和输出格式;其次使用adapt()在训练文本上统计词频,将文本转成整数序列(最大长度10);
通过对序列的均值处理,得到数值特征。
也可以把预训练的词向量GloVe,用于我们的词嵌入,不过在这里需要下载glove.6B/glove.6B.100d.txt。
但是这样的方法得到的结果也不错,但是没有原始特征编码的损失值低。

通过上述三种模型的比较,最终XGboost的效果最好。
| 模型\评估指标 | SVR | RF | XGboost |
| RMSLE | 0.1313 ± 0.0534 | 0.1400 ± 0.0228 | 0.1123 ± 0.0282 |
| MAPE | 9.42% ± 4.14 | 9.57% ± 1.24 | 7.95% ± 1.62 |
预测房价

通过上述训练好XGboost模型,预测测试集,并添加ID列。提交预测结果数据如下:


目前排名为757名。
心得
从结果来看,我是既高兴又不满足于此,高兴的是,我通过调整学习率、正则化约束、迭代次数等超参数,性能有一定的提升,可是就是突破不了,一直都困在0.12。或许应该换一个模型、换一些特征、也许用神经网络更好,只是我还没有尝试更多。
从整个过程来看,我很兴奋。从数据预处理开始,训练集和测试集的样本量都比较合适1460条和1459条,特征有79个,且标签是房价,那么确定任务就是回归任务了。开始对数据进行分析,我先在网上找了一些比较好看的颜色,用于我后续可视化的展示。首先是数据缺失值的查看,如果有缺失值,那么就要填充,但是有的特征缺失值占比达到了60%、90%以上的,我都决定删除,如果填充也没有意义,也许还会干扰模型更好的学习数据;然后我查看了房价的分布,呈现左偏态分布,因此对房价分布进行了调整,使得成为正态分布;随后,我通过统计特征的类型和个数,我把数据的特征分为了两类,一类是连续的数值型特征、一类是字符串的分类特征,模型只能学习数值,所以就必须对分类特征进行处理,我所知道的是有序化、向量化、二值化。因此对于第二类分类特征又可以拆分为:分类变量个数为2、有序、无序的特征,就可以用上述的方法进行编码。对于第一数值型特征需要做的就是标准化(训练集和测试集需要分开标准化),以此消除特征之间量纲的差异,第二类就不用标准化,因为是分类变量。经过标准化和特征编码之后,特征维度就从79变为了204。对于数值型特征,还能分析与房价的相关性,以及特征特征之间的相关性以此确定冗余特征。
上面是我自己编写的特征编码,还有一种方式,就是利TextVectorization词向量编码分类变量,但是效果和之前的结果差一点,但是相比于我自己写特征编码却要简单很多。
完整特征编码之后,有204个特征,显然有点多。我就使用了一系列的方法试图减少一些不重要的特征,包括:皮尔逊相关系数、互信息、Lasso、RFE等等。在这里就保留了很多不同的特征组合,相互取交集或并集运算。将筛选出的特征,再做降维分析,包括PCA和t-SNE,以查看数据的分布,发现使用了一系列特征赛选的方法组合的特征,反而PCA的样本点很聚集,没有什么可以分析的趋势、t-SNE不聚集,说明丢失了一些非线性的关系。若是简单的用RFE来进行剔除,PCA就表现出了PC1和房价的正相关趋势,以及t-SNE也有局部的聚集,保留了非线性的信息。因此在最后,我只选用了204个特征经过RFE之后留下的102个特征进行建模。
接下来进行构建模型,由于我前面没有将训练集数据单独划分出训练集和验证集,所以这里用K折交叉验证来划分。K的值从10→14→15→16→18→20,我不停的尝试,最好的是15折。模型我选择的都是非线性的模型包括:RF、SVR(核函数是RFB)、XGboost、MLP,通过评估函数RMSLE,在验证集上的表现来选择最终的模型。最好的模型就是Xgboost,RMSLE最低的时候等于0.1137。确定模型之后,我就对XGboost进行了无尽的调参,我就是一个一个的调,把一个超参数调到最优,保持不动,再去调整另一个超参数。下面是可以调整的超参数和我的经验,学习率(一般设置得比较小,要改的话改0的个数就好了)、最大深度(3-5)、正则化约束(先来两个极值,看模型是需要更复杂的模型,还是简单的模型,再折中的设置,这个是调整之后模型性能变化最大的)、交叉验证折数(根据样本数量来决定,虽然一般是5或者10,我们的样本相对较多,10折之后每一折也有140多个样本,15折有90多个样本也可以)、迭代次数(尽量多)。
最后,我希望自己能尽可能的去尝试更多的方法,或许沉淀几天,就又能进步了。