DAY36打卡@浙大疏锦行
1.接35day作业补充
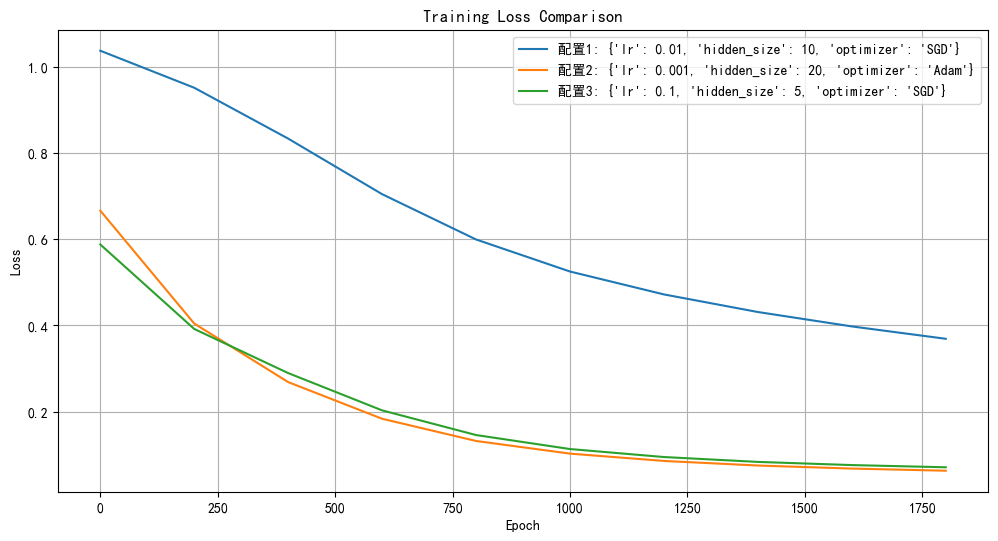 总体来看,配置 2 和配置 3 在准确率和损失值上表现较好,但配置 3 训练速度更快;配置 1 在各项指标上相对较弱。可以根据实际需求(如对训练时间和准确率的侧重)来选择最终使用的超参数配置。
总体来看,配置 2 和配置 3 在准确率和损失值上表现较好,但配置 3 训练速度更快;配置 1 在各项指标上相对较弱。可以根据实际需求(如对训练时间和准确率的侧重)来选择最终使用的超参数配置。
从训练损失对比图可以看出,三条曲线分别代表三种不同超参数配置下模型训练过程中损失值(Loss)随训练轮次(Epoch)的变化情况,且三条曲线的损失值都随着Epoch的增加呈下降趋势,说明三种配置下模型都在学习,逐渐降低预测值与真实值之间的差异。
1. 配置1(蓝色曲线) - 初始损失值较高,接近1.0 。这可能是因为初始参数设置下,模型预测结果与真实标签差异较大。 - 随着Epoch增加,损失值不断下降,但下降速度相对较慢。在整个训练过程中,其损失值始终高于配置2和配置3 。结合之前的超参数信息,配置1的学习率为0.01,隐藏层大小为10,优化器为SGD,可能由于学习率不是很合适,或者模型复杂度相对不足,导致收敛速度较慢且最终损失值较高。
2. 配置2(橙色曲线)- 初始损失值相对配置1低,在0.6左右。说明该配置下模型初始状态相对较好,预测结果更接近真实标签。 - 下降趋势较为明显,且下降速度较快,在训练后期损失值稳定在较低水平。配置2使用Adam优化器,学习率为0.001,隐藏层大小为20 ,Adam优化器的自适应学习率特性可能有助于模型更高效地更新参数,较大的隐藏层也能更好地捕捉数据特征,所以能较快收敛到较低损失值。
3. 配置3(绿色曲线)- 初始损失值也在0.6左右,和配置2相近。 - 下降速度较快,在训练前期就快速降低损失值,且在训练后期损失值与配置2相当,稳定在很低的水平。配置3的学习率为0.1,隐藏层大小为5,优化器为SGD,较高的学习率可能使模型在前期能快速调整参数,不过由于隐藏层神经元较少,模型复杂度有限,后期收敛优势没有配置2明显,但总体也取得了较好的效果。
总体而言,配置2和配置3在训练过程中的表现优于配置1 ,在选择超参数时,配置2和配置3是更优的选择。
2.
作业:
对之前的信贷项目,利用神经网络训练下,尝试用到目前的知识点让代码更加规范和美观。
import numpy as np
import pandas as pd
import torch #导入 PyTorch 的核心库
import torch.nn as nn #提供构建神经网络的基础组件
import torch.optim as optim #导入优化器模块,提供参数更新算法
from sklearn.datasets import load_iris #导入数据
from sklearn.model_selection import train_test_split #将数据集划分为训练集和测试集
from sklearn.preprocessing import MinMaxScaler, StandardScaler, OneHotEncoder, LabelEncoder #归一化、标准化、独热编码、标签编码
import time #记录运行时间
import matplotlib.pyplot as plt
from tqdm import tqdm #用于在循环中显示进度条,实时监控代码执行进度
from imblearn.over_sampling import SMOTE #处理数据不平衡的问题
#设置GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu" )
print(f"使用设备:{device}")# 加载信贷预测数据集
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统常用黑体字体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
data = pd.read_csv('D:\\Paperstudy\\Python学习60天打卡\\python60-days-challenge-master\\data.csv') #读取数据# 丢弃掉Id列
data = data.drop(['Id'], axis=1)# 区分连续特征与离散特征
continuous_features = data.select_dtypes(include=['float64', 'int64']).columns.tolist()
discrete_features = data.select_dtypes(exclude=['float64', 'int64']).columns.tolist()# 离散特征使用众数进行补全
for feature in discrete_features:if data[feature].isnull().sum() > 0:mode_value = data[feature].mode()[0]data[feature].fillna(mode_value, inplace=True)# 连续变量用中位数进行补全
for feature in continuous_features:if data[feature].isnull().sum() > 0:median_value = data[feature].median()data[feature].fillna(median_value, inplace=True)# 有顺序的离散变量进行标签编码
mappings = {"Years in current job": {"10+ years": 10,"2 years": 2,"3 years": 3,"< 1 year": 0,"5 years": 5,"1 year": 1,"4 years": 4,"6 years": 6,"7 years": 7,"8 years": 8,"9 years": 9},"Home Ownership": {"Home Mortgage": 0,"Rent": 1,"Own Home": 2,"Have Mortgage": 3},"Term": {"Short Term": 0,"Long Term": 1}
}# 使用映射字典进行转换
data["Years in current job"] = data["Years in current job"].map(mappings["Years in current job"])
data["Home Ownership"] = data["Home Ownership"].map(mappings["Home Ownership"])
data["Term"] = data["Term"].map(mappings["Term"])# 对没有顺序的离散变量进行独热编码
data = pd.get_dummies(data, columns=['Purpose'])
list_final = []
data2 = pd.read_csv('data.csv')
for i in data.columns:if i not in data2.columns:list_final.append(i)
for i in list_final:data[i] = data[i].astype(int) # 将bool型转换为数值型# 分离特征数据和标签数据
X = data.drop(['Credit Default'], axis=1) # 特征数据
y = data['Credit Default'] # 标签数据X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test) # 确保训练集和测试集是相同的缩放X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train.values).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test.values).to(device)# 实例化模型并移至GPU
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.fc1 = nn.Linear(30, 64)self.relu = nn.ReLU()self.fc2 = nn.Linear(64, 2)def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 实例化模型并移至GPU
model = MLP().to(device)# 分类问题使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()# 使用随机梯度下降优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练模型
num_epochs = 20000 # 训练的轮数# 用于存储每200个epoch的损失值、准确率和对应的epoch数
losses = []
accuracies = []
epochs = []start_time = time.time() # 记录开始时间# 创建tqdm进度条
with tqdm(total=num_epochs, desc="训练进度", unit="epoch") as pbar:# 训练模型for epoch in range(num_epochs):# 前向传播outputs = model(X_train) # 隐式调用forward函数loss = criterion(outputs, y_train)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()# 记录损失值、准确率并更新进度条if (epoch + 1) % 200 == 0:losses.append(loss.item())epochs.append(epoch + 1)# 在测试集上评估模型model.eval()with torch.no_grad():test_outputs = model(X_test)_, predicted = torch.max(test_outputs, 1)correct = (predicted == y_test).sum().item()accuracy = correct / y_test.size(0)accuracies.append(accuracy)# 更新进度条的描述信息pbar.set_postfix({'Loss': f'{loss.item():.4f}', 'Accuracy': f'{accuracy * 100:.2f}%'})# 每1000个epoch更新一次进度条if (epoch + 1) % 1000 == 0:pbar.update(1000) # 更新进度条# 确保进度条达到100%if pbar.n < num_epochs:pbar.update(num_epochs - pbar.n) # 计算剩余的进度并更新time_all = time.time() - start_time # 计算训练时间
print(f'Training time: {time_all:.2f} seconds')# 绘制损失和准确率曲线
fig, ax1 = plt.subplots(figsize=(10, 6))# 绘制损失曲线
color = 'tab:red'
ax1.set_xlabel('Epoch')
ax1.set_ylabel('Loss', color=color)
ax1.plot(epochs, losses, color=color)
ax1.tick_params(axis='y', labelcolor=color)# 创建第二个y轴用于绘制准确率曲线
ax2 = ax1.twinx()
color = 'tab:blue'
ax2.set_ylabel('Accuracy', color=color)
ax2.plot(epochs, accuracies, color=color)
ax2.tick_params(axis='y', labelcolor=color)plt.title('Training Loss and Accuracy over Epochs')
plt.grid(True)
plt.show()# 在测试集上评估模型,此时model内部已经是训练好的参数了
# 评估模型
model.eval() # 设置模型为评估模式
with torch.no_grad(): # torch.no_grad()的作用是禁用梯度计算,可以提高模型推理速度outputs = model(X_test) # 对测试数据进行前向传播,获得预测结果_, predicted = torch.max(outputs, 1) # torch.max(outputs, 1)返回每行的最大值和对应的索引correct = (predicted == y_test).sum().item() # 计算预测正确的样本数accuracy = correct / y_test.size(0)print(f'测试集准确率: {accuracy * 100:.2f}%')
3.
help(nn.Module)Help on class Module in module torch.nn.modules.module:class Module(builtins.object)| Base class for all neural network modules.| | Your models should also subclass this class.| | Modules can also contain other Modules, allowing to nest them in| a tree structure. You can assign the submodules as regular attributes::| | import torch.nn as nn| import torch.nn.functional as F| | class Model(nn.Module):| def __init__(self):| super(Model, self).__init__()| self.conv1 = nn.Conv2d(1, 20, 5)| self.conv2 = nn.Conv2d(20, 20, 5)| | def forward(self, x):| x = F.relu(self.conv1(x))| return F.relu(self.conv2(x))| | Submodules assigned in this way will be registered, and will have their| parameters converted too when you call :meth:`to`, etc.| | :ivar training: Boolean represents whether this module is in training or| evaluation mode.| :vartype training: bool| | Methods defined here:| | __call__ = _call_impl(self, *input, **kwargs)| | __delattr__(self, name)| Implement delattr(self, name).| | __dir__(self)| Default dir() implementation.| | __getattr__(self, name: str) -> Union[torch.Tensor, ForwardRef('Module')]| | __init__(self)| Initializes internal Module state, shared by both nn.Module and ScriptModule.| | __repr__(self)| Return repr(self).| | __setattr__(self, name: str, value: Union[torch.Tensor, ForwardRef('Module')]) -> None| Implement setattr(self, name, value).| | __setstate__(self, state)| | add_module(self, name: str, module: Union[ForwardRef('Module'), NoneType]) -> None| Adds a child module to the current module.| | The module can be accessed as an attribute using the given name.| | Args:| name (string): name of the child module. The child module can be| accessed from this module using the given name| module (Module): child module to be added to the module.| | apply(self: ~T, fn: Callable[[ForwardRef('Module')], NoneType]) -> ~T| Applies ``fn`` recursively to every submodule (as returned by ``.children()``)| as well as self. Typical use includes initializing the parameters of a model| (see also :ref:`nn-init-doc`).| | Args:| fn (:class:`Module` -> None): function to be applied to each submodule| | Returns:| Module: self| | Example::| | >>> @torch.no_grad()| >>> def init_weights(m):| >>> print(m)| >>> if type(m) == nn.Linear:| >>> m.weight.fill_(1.0)| >>> print(m.weight)| >>> net = nn.Sequential(nn.Linear(2, 2), nn.Linear(2, 2))| >>> net.apply(init_weights)| Linear(in_features=2, out_features=2, bias=True)| Parameter containing:| tensor([[ 1., 1.],| [ 1., 1.]])| Linear(in_features=2, out_features=2, bias=True)| Parameter containing:| tensor([[ 1., 1.],| [ 1., 1.]])| Sequential(| (0): Linear(in_features=2, out_features=2, bias=True)| (1): Linear(in_features=2, out_features=2, bias=True)| )| Sequential(| (0): Linear(in_features=2, out_features=2, bias=True)| (1): Linear(in_features=2, out_features=2, bias=True)| )| | bfloat16(self: ~T) -> ~T| Casts all floating point parameters and buffers to ``bfloat16`` datatype.| | Returns:| Module: self| | buffers(self, recurse: bool = True) -> Iterator[torch.Tensor]| Returns an iterator over module buffers.| | Args:| recurse (bool): if True, then yields buffers of this module| and all submodules. Otherwise, yields only buffers that| are direct members of this module.| | Yields:| torch.Tensor: module buffer| | Example::| | >>> for buf in model.buffers():| >>> print(type(buf), buf.size())| <class 'torch.Tensor'> (20L,)| <class 'torch.Tensor'> (20L, 1L, 5L, 5L)| | children(self) -> Iterator[ForwardRef('Module')]| Returns an iterator over immediate children modules.| | Yields:| Module: a child module| | cpu(self: ~T) -> ~T| Moves all model parameters and buffers to the CPU.| | Returns:| Module: self| | cuda(self: ~T, device: Union[int, torch.device, NoneType] = None) -> ~T| Moves all model parameters and buffers to the GPU.| | This also makes associated parameters and buffers different objects. So| it should be called before constructing optimizer if the module will| live on GPU while being optimized.| | Args:| device (int, optional): if specified, all parameters will be| copied to that device| | Returns:| Module: self| | double(self: ~T) -> ~T| Casts all floating point parameters and buffers to ``double`` datatype.| | Returns:| Module: self| | eval(self: ~T) -> ~T| Sets the module in evaluation mode.| | This has any effect only on certain modules. See documentations of| particular modules for details of their behaviors in training/evaluation| mode, if they are affected, e.g. :class:`Dropout`, :class:`BatchNorm`,| etc.| | This is equivalent with :meth:`self.train(False) <torch.nn.Module.train>`.| | Returns:| Module: self| | extra_repr(self) -> str| Set the extra representation of the module| | To print customized extra information, you should re-implement| this method in your own modules. Both single-line and multi-line| strings are acceptable.| | float(self: ~T) -> ~T| Casts all floating point parameters and buffers to float datatype.| | Returns:| Module: self| | forward = _forward_unimplemented(self, *input: Any) -> None| Defines the computation performed at every call.| | Should be overridden by all subclasses.| | .. note::| Although the recipe for forward pass needs to be defined within| this function, one should call the :class:`Module` instance afterwards| instead of this since the former takes care of running the| registered hooks while the latter silently ignores them.| | half(self: ~T) -> ~T| Casts all floating point parameters and buffers to ``half`` datatype.| | Returns:| Module: self| | load_state_dict(self, state_dict: 'OrderedDict[str, Tensor]', strict: bool = True)| Copies parameters and buffers from :attr:`state_dict` into| this module and its descendants. If :attr:`strict` is ``True``, then| the keys of :attr:`state_dict` must exactly match the keys returned| by this module's :meth:`~torch.nn.Module.state_dict` function.| | Args:| state_dict (dict): a dict containing parameters and| persistent buffers.| strict (bool, optional): whether to strictly enforce that the keys| in :attr:`state_dict` match the keys returned by this module's| :meth:`~torch.nn.Module.state_dict` function. Default: ``True``| | Returns:| ``NamedTuple`` with ``missing_keys`` and ``unexpected_keys`` fields:| * **missing_keys** is a list of str containing the missing keys| * **unexpected_keys** is a list of str containing the unexpected keys| | modules(self) -> Iterator[ForwardRef('Module')]| Returns an iterator over all modules in the network.| | Yields:| Module: a module in the network| | Note:| Duplicate modules are returned only once. In the following| example, ``l`` will be returned only once.| | Example::| | >>> l = nn.Linear(2, 2)| >>> net = nn.Sequential(l, l)| >>> for idx, m in enumerate(net.modules()):| print(idx, '->', m)| | 0 -> Sequential(| (0): Linear(in_features=2, out_features=2, bias=True)| (1): Linear(in_features=2, out_features=2, bias=True)| )| 1 -> Linear(in_features=2, out_features=2, bias=True)| | named_buffers(self, prefix: str = '', recurse: bool = True) -> Iterator[Tuple[str, torch.Tensor]]| Returns an iterator over module buffers, yielding both the| name of the buffer as well as the buffer itself.| | Args:| prefix (str): prefix to prepend to all buffer names.| recurse (bool): if True, then yields buffers of this module| and all submodules. Otherwise, yields only buffers that| are direct members of this module.| | Yields:| (string, torch.Tensor): Tuple containing the name and buffer| | Example::| | >>> for name, buf in self.named_buffers():| >>> if name in ['running_var']:| >>> print(buf.size())| | named_children(self) -> Iterator[Tuple[str, ForwardRef('Module')]]| Returns an iterator over immediate children modules, yielding both| the name of the module as well as the module itself.| | Yields:| (string, Module): Tuple containing a name and child module| | Example::| | >>> for name, module in model.named_children():| >>> if name in ['conv4', 'conv5']:| >>> print(module)| | named_modules(self, memo: Union[Set[ForwardRef('Module')], NoneType] = None, prefix: str = '')| Returns an iterator over all modules in the network, yielding| both the name of the module as well as the module itself.| | Yields:| (string, Module): Tuple of name and module| | Note:| Duplicate modules are returned only once. In the following| example, ``l`` will be returned only once.| | Example::| | >>> l = nn.Linear(2, 2)| >>> net = nn.Sequential(l, l)| >>> for idx, m in enumerate(net.named_modules()):| print(idx, '->', m)| | 0 -> ('', Sequential(| (0): Linear(in_features=2, out_features=2, bias=True)| (1): Linear(in_features=2, out_features=2, bias=True)| ))| 1 -> ('0', Linear(in_features=2, out_features=2, bias=True))| | named_parameters(self, prefix: str = '', recurse: bool = True) -> Iterator[Tuple[str, torch.nn.parameter.Parameter]]| Returns an iterator over module parameters, yielding both the| name of the parameter as well as the parameter itself.| | Args:| prefix (str): prefix to prepend to all parameter names.| recurse (bool): if True, then yields parameters of this module| and all submodules. Otherwise, yields only parameters that| are direct members of this module.| | Yields:| (string, Parameter): Tuple containing the name and parameter| | Example::| | >>> for name, param in self.named_parameters():| >>> if name in ['bias']:| >>> print(param.size())| | parameters(self, recurse: bool = True) -> Iterator[torch.nn.parameter.Parameter]| Returns an iterator over module parameters.| | This is typically passed to an optimizer.| | Args:| recurse (bool): if True, then yields parameters of this module| and all submodules. Otherwise, yields only parameters that| are direct members of this module.| | Yields:| Parameter: module parameter| | Example::| | >>> for param in model.parameters():| >>> print(type(param), param.size())| <class 'torch.Tensor'> (20L,)| <class 'torch.Tensor'> (20L, 1L, 5L, 5L)| | register_backward_hook(self, hook: Callable[[ForwardRef('Module'), Union[Tuple[torch.Tensor, ...], torch.Tensor], Union[Tuple[torch.Tensor, ...], torch.Tensor]], Union[NoneType, torch.Tensor]]) -> torch.utils.hooks.RemovableHandle| Registers a backward hook on the module.| | This function is deprecated in favor of :meth:`nn.Module.register_full_backward_hook` and| the behavior of this function will change in future versions.| | Returns:| :class:`torch.utils.hooks.RemovableHandle`:| a handle that can be used to remove the added hook by calling| ``handle.remove()``| | register_buffer(self, name: str, tensor: Union[torch.Tensor, NoneType], persistent: bool = True) -> None| Adds a buffer to the module.| | This is typically used to register a buffer that should not to be| considered a model parameter. For example, BatchNorm's ``running_mean``| is not a parameter, but is part of the module's state. Buffers, by| default, are persistent and will be saved alongside parameters. This| behavior can be changed by setting :attr:`persistent` to ``False``. The| only difference between a persistent buffer and a non-persistent buffer| is that the latter will not be a part of this module's| :attr:`state_dict`.| | Buffers can be accessed as attributes using given names.| | Args:| name (string): name of the buffer. The buffer can be accessed| from this module using the given name| tensor (Tensor): buffer to be registered.| persistent (bool): whether the buffer is part of this module's| :attr:`state_dict`.| | Example::| | >>> self.register_buffer('running_mean', torch.zeros(num_features))| | register_forward_hook(self, hook: Callable[..., NoneType]) -> torch.utils.hooks.RemovableHandle| Registers a forward hook on the module.| | The hook will be called every time after :func:`forward` has computed an output.| It should have the following signature::| | hook(module, input, output) -> None or modified output| | The input contains only the positional arguments given to the module.| Keyword arguments won't be passed to the hooks and only to the ``forward``.| The hook can modify the output. It can modify the input inplace but| it will not have effect on forward since this is called after| :func:`forward` is called.| | Returns:| :class:`torch.utils.hooks.RemovableHandle`:| a handle that can be used to remove the added hook by calling| ``handle.remove()``| | register_forward_pre_hook(self, hook: Callable[..., NoneType]) -> torch.utils.hooks.RemovableHandle| Registers a forward pre-hook on the module.| | The hook will be called every time before :func:`forward` is invoked.| It should have the following signature::| | hook(module, input) -> None or modified input| | The input contains only the positional arguments given to the module.| Keyword arguments won't be passed to the hooks and only to the ``forward``.| The hook can modify the input. User can either return a tuple or a| single modified value in the hook. We will wrap the value into a tuple| if a single value is returned(unless that value is already a tuple).| | Returns:| :class:`torch.utils.hooks.RemovableHandle`:| a handle that can be used to remove the added hook by calling| ``handle.remove()``| | register_full_backward_hook(self, hook: Callable[[ForwardRef('Module'), Union[Tuple[torch.Tensor, ...], torch.Tensor], Union[Tuple[torch.Tensor, ...], torch.Tensor]], Union[NoneType, torch.Tensor]]) -> torch.utils.hooks.RemovableHandle| Registers a backward hook on the module.| | The hook will be called every time the gradients with respect to module| inputs are computed. The hook should have the following signature::| | hook(module, grad_input, grad_output) -> tuple(Tensor) or None| | The :attr:`grad_input` and :attr:`grad_output` are tuples that contain the gradients| with respect to the inputs and outputs respectively. The hook should| not modify its arguments, but it can optionally return a new gradient with| respect to the input that will be used in place of :attr:`grad_input` in| subsequent computations. :attr:`grad_input` will only correspond to the inputs given| as positional arguments and all kwarg arguments are ignored. Entries| in :attr:`grad_input` and :attr:`grad_output` will be ``None`` for all non-Tensor| arguments.| | .. warning ::| Modifying inputs or outputs inplace is not allowed when using backward hooks and| will raise an error.| | Returns:| :class:`torch.utils.hooks.RemovableHandle`:| a handle that can be used to remove the added hook by calling| ``handle.remove()``| | register_parameter(self, name: str, param: Union[torch.nn.parameter.Parameter, NoneType]) -> None| Adds a parameter to the module.| | The parameter can be accessed as an attribute using given name.| | Args:| name (string): name of the parameter. The parameter can be accessed| from this module using the given name| param (Parameter): parameter to be added to the module.| | requires_grad_(self: ~T, requires_grad: bool = True) -> ~T| Change if autograd should record operations on parameters in this| module.| | This method sets the parameters' :attr:`requires_grad` attributes| in-place.| | This method is helpful for freezing part of the module for finetuning| or training parts of a model individually (e.g., GAN training).| | Args:| requires_grad (bool): whether autograd should record operations on| parameters in this module. Default: ``True``.| | Returns:| Module: self| | share_memory(self: ~T) -> ~T| | state_dict(self, destination=None, prefix='', keep_vars=False)| Returns a dictionary containing a whole state of the module.| | Both parameters and persistent buffers (e.g. running averages) are| included. Keys are corresponding parameter and buffer names.| | Returns:| dict:| a dictionary containing a whole state of the module| | Example::| | >>> module.state_dict().keys()| ['bias', 'weight']| | to(self, *args, **kwargs)| Moves and/or casts the parameters and buffers.| | This can be called as| | .. function:: to(device=None, dtype=None, non_blocking=False)| | .. function:: to(dtype, non_blocking=False)| | .. function:: to(tensor, non_blocking=False)| | .. function:: to(memory_format=torch.channels_last)| | Its signature is similar to :meth:`torch.Tensor.to`, but only accepts| floating point or complex :attr:`dtype`s. In addition, this method will| only cast the floating point or complex parameters and buffers to :attr:`dtype`| (if given). The integral parameters and buffers will be moved| :attr:`device`, if that is given, but with dtypes unchanged. When| :attr:`non_blocking` is set, it tries to convert/move asynchronously| with respect to the host if possible, e.g., moving CPU Tensors with| pinned memory to CUDA devices.| | See below for examples.| | .. note::| This method modifies the module in-place.| | Args:| device (:class:`torch.device`): the desired device of the parameters| and buffers in this module| dtype (:class:`torch.dtype`): the desired floating point or complex dtype of| the parameters and buffers in this module| tensor (torch.Tensor): Tensor whose dtype and device are the desired| dtype and device for all parameters and buffers in this module| memory_format (:class:`torch.memory_format`): the desired memory| format for 4D parameters and buffers in this module (keyword| only argument)| | Returns:| Module: self| | Examples::| | >>> linear = nn.Linear(2, 2)| >>> linear.weight| Parameter containing:| tensor([[ 0.1913, -0.3420],| [-0.5113, -0.2325]])| >>> linear.to(torch.double)| Linear(in_features=2, out_features=2, bias=True)| >>> linear.weight| Parameter containing:| tensor([[ 0.1913, -0.3420],| [-0.5113, -0.2325]], dtype=torch.float64)| >>> gpu1 = torch.device("cuda:1")| >>> linear.to(gpu1, dtype=torch.half, non_blocking=True)| Linear(in_features=2, out_features=2, bias=True)| >>> linear.weight| Parameter containing:| tensor([[ 0.1914, -0.3420],| [-0.5112, -0.2324]], dtype=torch.float16, device='cuda:1')| >>> cpu = torch.device("cpu")| >>> linear.to(cpu)| Linear(in_features=2, out_features=2, bias=True)| >>> linear.weight| Parameter containing:| tensor([[ 0.1914, -0.3420],| [-0.5112, -0.2324]], dtype=torch.float16)| | >>> linear = nn.Linear(2, 2, bias=None).to(torch.cdouble)| >>> linear.weight| Parameter containing:| tensor([[ 0.3741+0.j, 0.2382+0.j],| [ 0.5593+0.j, -0.4443+0.j]], dtype=torch.complex128)| >>> linear(torch.ones(3, 2, dtype=torch.cdouble))| tensor([[0.6122+0.j, 0.1150+0.j],| [0.6122+0.j, 0.1150+0.j],| [0.6122+0.j, 0.1150+0.j]], dtype=torch.complex128)| | train(self: ~T, mode: bool = True) -> ~T| Sets the module in training mode.| | This has any effect only on certain modules. See documentations of| particular modules for details of their behaviors in training/evaluation| mode, if they are affected, e.g. :class:`Dropout`, :class:`BatchNorm`,| etc.| | Args:| mode (bool): whether to set training mode (``True``) or evaluation| mode (``False``). Default: ``True``.| | Returns:| Module: self| | type(self: ~T, dst_type: Union[torch.dtype, str]) -> ~T| Casts all parameters and buffers to :attr:`dst_type`.| | Args:| dst_type (type or string): the desired type| | Returns:| Module: self| | xpu(self: ~T, device: Union[int, torch.device, NoneType] = None) -> ~T| Moves all model parameters and buffers to the XPU.| | This also makes associated parameters and buffers different objects. So| it should be called before constructing optimizer if the module will| live on XPU while being optimized.| | Arguments:| device (int, optional): if specified, all parameters will be| copied to that device| | Returns:| Module: self| | zero_grad(self, set_to_none: bool = False) -> None| Sets gradients of all model parameters to zero. See similar function| under :class:`torch.optim.Optimizer` for more context.| | Args:| set_to_none (bool): instead of setting to zero, set the grads to None.| See :meth:`torch.optim.Optimizer.zero_grad` for details.| | ----------------------------------------------------------------------| Data descriptors defined here:| | __dict__| dictionary for instance variables (if defined)| | __weakref__| list of weak references to the object (if defined)| | ----------------------------------------------------------------------| Data and other attributes defined here:| | T_destination = ~T_destination| | __annotations__ = {'__call__': typing.Callable[..., typing.Any], '_is_...| | dump_patches = False