【深度学习】2. 从梯度推导到优化策略:反向传播与 SGD, Mini SGD
反向传播算法详解
1. 前向传播与输出层误差定义
假设我们考虑一个典型的前馈神经网络,其最后一层为 softmax 分类器,损失函数为交叉熵。
前向传播过程
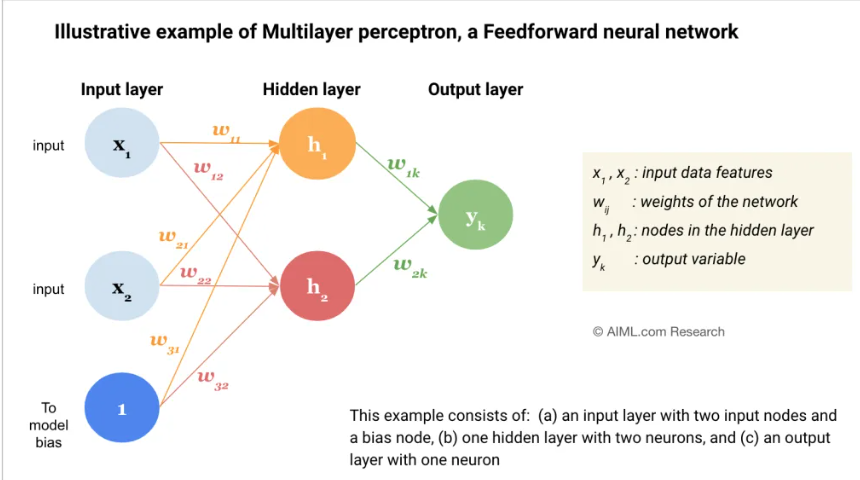
对于某一隐藏层神经元 j j j:
-
输入: x i x_i xi
-
权重: w j i w_{ji} wji
-
线性组合:
net j = ∑ i w j i x i = w j ⊤ x \text{net}_j = \sum_i w_{ji} x_i = \mathbf{w}_j^\top \mathbf{x} netj=i∑wjixi=wj⊤x -
激活输出:
y j = f ( net j ) y_j = f(\text{net}_j) yj=f(netj)
最终输出层采用 softmax 函数,输出概率:
z k = e net k ∑ k ′ e net k ′ z_k = \frac{e^{\text{net}_k}}{\sum_{k'} e^{\text{net}_{k'}}} zk=∑k′enetk′enetk
训练误差(Training Error)
在训练神经网络时,损失函数(training error)用于衡量预测输出 z \mathbf{z} z 与目标标签 t \mathbf{t} t 之间的距离。常见的损失函数包括以下三种形式:
1. 欧几里得距离(Euclidean distance)
这是最基本的损失函数形式,适用于回归任务或输出不是概率分布时:
J ( t , z ) = 1 2 ∑ k = 1 C ( t k − z k ) 2 = 1 2 ∥ t − z ∥ 2 J(t, z) = \frac{1}{2} \sum_{k=1}^{C} (t_k - z_k)^2 = \frac{1}{2} \| \mathbf{t} - \mathbf{z} \|^2 J(t,z)=21k=1∑C(tk−zk)2=21∥t−z∥2
其中:
- C C C 是输出类别数
- t \mathbf{t} t 是目标向量
- z \mathbf{z} z 是模型输出
它表示的是平方误差损失,数值意义上等价于 L2 范数。
2. 交叉熵(Cross Entropy)
当 t \mathbf{t} t 和 z \mathbf{z} z 都是概率分布(如 one-hot 和 softmax 输出)时,更推荐使用交叉熵损失:
J ( t , z ) = − ∑ k = 1 C t k log z k J(t, z) = - \sum_{k=1}^{C} t_k \log z_k J(t,z)=−k=1∑Ctklogzk
该形式特别适合用于多分类问题,且与 softmax 联合使用可得到简洁的梯度表达式。
3. 对称交叉熵(Symmetric Cross Entropy)
标准交叉熵是非对称的,即 J ( t , z ) ≠ J ( z , t ) J(t, z) \ne J(z, t) J(t,z)=J(z,t)。为了在某些任务中保持对称性,可以使用如下形式:
J ( t , z ) = − ∑ k = 1 C ( t k log z k + z k log t k ) J(t, z) = - \sum_{k=1}^{C} (t_k \log z_k + z_k \log t_k) J(t,z)=−k=1∑C(tklogzk+zklogtk)
这种形式在一些模糊标签、不确定性建模或鲁棒学习中更常见,但需要确保 t k > 0 t_k > 0 tk>0 且 z k > 0 z_k > 0 zk>0,否则 log 项会出现数值问题。
小结
| 损失函数类型 | 应用场景 |
|---|---|
| 欧几里得距离 | 回归或非概率输出 |
| 交叉熵 | 分类任务,概率分布输出(softmax) |
| 对称交叉熵 | 非对称性敏感的分类问题 |
交叉熵损失(Cross Entropy Loss)
在分类任务中,当目标分布 t \mathbf{t} t 和模型输出 z \mathbf{z} z 都是概率分布时,交叉熵是一种常用的损失函数,用于衡量两个分布之间的“差异”或“信息损失”。
定义:
给定两个概率分布 t = { t 1 , … , t C } \mathbf{t} = \{t_1, \dots, t_C\} t={t1,…,tC} 和 z = { z 1 , … , z C } \mathbf{z} = \{z_1, \dots, z_C\} z={z1,…,zC},交叉熵定义为:
CrossEntropy ( t , z ) = − ∑ i t i log z i \text{CrossEntropy}(t, z) = -\sum_i t_i \log z_i CrossEntropy(t,z)=−i∑tilogzi
推导展开:
交叉熵可以拆解为熵(Entropy)和 KL 散度(Kullback-Leibler Divergence)之和:
CrossEntropy ( t , z ) = − ∑ i t i log z i = − ∑ i t i log t i + ∑ i t i log t i z i = Entropy ( t ) + D KL ( t ∥ z ) \begin{aligned} \text{CrossEntropy}(t, z) &= -\sum_i t_i \log z_i \\ &= -\sum_i t_i \log t_i + \sum_i t_i \log \frac{t_i}{z_i} \\ &= \text{Entropy}(t) + D_{\text{KL}}(t \| z) \end{aligned} CrossEntropy(t,z)=−i∑tilogzi=−i∑tilogti+i∑tilogziti=Entropy(t)+DKL(t∥z)
其中:
- Entropy ( t ) = − ∑ i t i log t i \text{Entropy}(t) = -\sum_i t_i \log t_i Entropy(t)=−∑itilogti
- D KL ( t ∥ z ) = ∑ i t i log t i z i D_{\text{KL}}(t \| z) = \sum_i t_i \log \frac{t_i}{z_i} DKL(t∥z)=∑itilogziti
解释说明:
-
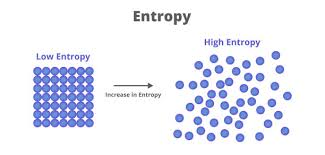
Entropy(熵) 是衡量分布不确定性的度量,值越高表示分布越“混乱”。
-
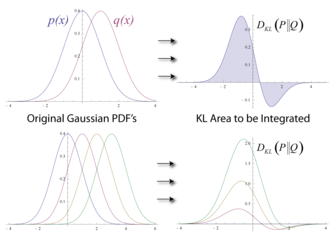
KL 散度 衡量两个分布之间的差异,是一个非对称的距离度量(即 D KL ( t ∥ z ) ≠ D KL ( z ∥ t ) D_{\text{KL}}(t \| z) \ne D_{\text{KL}}(z \| t) DKL(t∥z)=DKL(z∥t))。
面积越大 → 两分布差异越大 → KL 越大
图示直观理解:
总结:
| 名称 | 数学形式 | 说明 |
|---|---|---|
| 交叉熵 | − ∑ i t i log z i -\sum_i t_i \log z_i −∑itilogzi | 衡量预测分布 z z z 与真实分布 t t t 的差异 |
| 熵 | − ∑ i t i log t i -\sum_i t_i \log t_i −∑itilogti | 测量目标分布自身的不确定性 |
| KL 散度 | ∑ i t i log t i z i \sum_i t_i \log \frac{t_i}{z_i} ∑itilogziti | 模型 z z z 逼近目标 t t t 时的信息损失 |
因此,交叉熵 = 熵 + KL 散度,是一个包含两部分含义的损失函数。
2. Softmax
在多类分类中,输出层之前的softmax函数是为每个类分配条件概率
softmax ( z i ) = e z i ∑ j = 1 C e z j \text{softmax}(z_i) = \frac{e^{z_i}}{\sum_{j=1}^C e^{z_j}} softmax(zi)=∑j=1Cezjezi
3. 隐藏层权重更新与链式法则
我们首先来看从隐藏层到输出层的权重 w k j w_{kj} wkj(第 j j j 个隐藏神经元到第 k k k 个输出神经元)。
使用链式法则:
∂ J ∂ w k j = ∂ J ∂ net k ⋅ ∂ net k ∂ w k j = ∂ J ∂ net k ⋅ y j \frac{\partial J}{\partial w_{kj}} = \frac{\partial J}{\partial \text{net}_k} \cdot \frac{\partial \text{net}_k}{\partial w_{kj}} = \frac{\partial J}{\partial \text{net}_k} \cdot y_j ∂wkj∂J=∂netk∂J⋅∂wkj∂netk=∂netk∂J⋅yj
其中:
-
net k \text{net}_k netk 是输出神经元 k k k 的加权输入:
net k = ∑ j = 1 n H y j w k j + w k 0 \text{net}_k = \sum_{j=1}^{n_H} y_j w_{kj} + w_{k0} netk=j=1∑nHyjwkj+wk0 -
y j y_j yj 是隐藏层神经元 j j j 的激活输出
-
J J J 是整体损失函数,使用欧几里得损失:
J ( w ) = 1 2 ∥ t − z ∥ 2 J(\mathbf{w}) = \frac{1}{2} \|\mathbf{t} - \mathbf{z}\|^2 J(w)=21∥t−z∥2
即误差对每条连接的权重 w k j w_{kj} wkj 的导数,取决于该输出神经元的误差信号 ∂ J ∂ net k \frac{\partial J}{\partial \text{net}_k} ∂netk∂J 乘以隐藏层输入 y j y_j yj。
现在我们推导从输入层到隐藏层的权重 w j i w_{ji} wji(输入 x i x_i xi 到隐藏神经元 y j y_j yj)。
应用多级链式法则:
∂ J ∂ w j i = ∂ J ∂ y j ⋅ ∂ y j ∂ net j ⋅ ∂ net j ∂ w j i \frac{\partial J}{\partial w_{ji}} = \frac{\partial J}{\partial y_j} \cdot \frac{\partial y_j}{\partial \text{net}_j} \cdot \frac{\partial \text{net}_j}{\partial w_{ji}} ∂wji∂J=∂yj∂J⋅∂netj∂yj⋅∂wji∂netj
-
先求 ∂ net j ∂ w j i = x i \frac{\partial \text{net}_j}{\partial w_{ji}} = x_i ∂wji∂netj=xi
-
激活函数导数: ∂ y j ∂ net j = f ′ ( net j ) \frac{\partial y_j}{\partial \text{net}_j} = f'(\text{net}_j) ∂netj∂yj=f′(netj)
-
关键: ∂ J ∂ y j \frac{\partial J}{\partial y_j} ∂yj∂J 不能直接求出,但可以通过反向传播累加自输出层所有神经元:
∂ J ∂ y j = ∑ k = 1 C ∂ J ∂ z k ⋅ ∂ z k ∂ y j \frac{\partial J}{\partial y_j} = \sum_{k=1}^C \frac{\partial J}{\partial z_k} \cdot \frac{\partial z_k}{\partial y_j} ∂yj∂J=k=1∑C∂zk∂J⋅∂yj∂zk
- 其中 ∂ z k ∂ y j = f ′ ( net k ) ⋅ w k j \frac{\partial z_k}{\partial y_j} = f'(\text{net}_k) \cdot w_{kj} ∂yj∂zk=f′(netk)⋅wkj
- 若 z k z_k zk 是 softmax 输出, ∂ J ∂ net k = z k − t k \frac{\partial J}{\partial \text{net}_k} = z_k - t_k ∂netk∂J=zk−tk
所以完整形式为:
∂ J ∂ w j i = ( ∑ k ( z k − t k ) w k j ) ⋅ f ′ ( net j ) ⋅ x i \frac{\partial J}{\partial w_{ji}} = \left( \sum_k (z_k - t_k) w_{kj} \right) \cdot f'(\text{net}_j) \cdot x_i ∂wji∂J=(k∑(zk−tk)wkj)⋅f′(netj)⋅xi
总结
| 权重类型 | 梯度表达式 |
|---|---|
| 输出层 w k j w_{kj} wkj | ∂ J ∂ w k j = δ k ⋅ y j \frac{\partial J}{\partial w_{kj}} = \delta_k \cdot y_j ∂wkj∂J=δk⋅yj,其中 δ k = ∂ J ∂ net k \delta_k = \frac{\partial J}{\partial \text{net}_k} δk=∂netk∂J |
| 输入层 w j i w_{ji} wji | ∂ J ∂ w j i = δ j ⋅ x i \frac{\partial J}{\partial w_{ji}} = \delta_j \cdot x_i ∂wji∂J=δj⋅xi,其中 δ j \delta_j δj 由输出层误差反向传递计算得出 |
整个反向传播过程建立在链式法则之上,通过分层计算误差信号,并逐层传播与更新权重。
4. 梯度消失与爆炸问题
在深层神经网络中,误差信号需从输出层通过多层链式导数逐步反向传播至输入层。在此过程中,梯度可能出现以下数值不稳定现象:
梯度消失(vanishing gradients)
若激活函数的导数在大部分区域非常小(如 sigmoid 的最大导数仅为 0.25),那么反向传播时:
δ ( l ) = f ′ ( net ( l ) ) ⋅ ∑ k w k j ( l + 1 ) δ k ( l + 1 ) \delta^{(l)} = f'(\text{net}^{(l)}) \cdot \sum_k w_{kj}^{(l+1)} \delta_k^{(l+1)} δ(l)=f′(net(l))⋅k∑wkj(l+1)δk(l+1)
将不断被乘以小于 1 的数,导致越靠近输入层,梯度越趋近于 0,使得参数更新缓慢,甚至停滞。
梯度爆炸(exploding gradients)
相反,如果激活函数导数较大,或权重初始化不当(如值较大),则会导致链式乘积中项持续放大,最终使梯度数值迅速增大,导致训练不稳定甚至发散。
5. 应对策略与激活函数的选择
为了缓解梯度消失与爆炸问题,实践中可采用以下策略:
- 选用非饱和激活函数(如 ReLU、Leaky ReLU)以避免小梯度区间
- 使用归一化技巧(如 BatchNorm)以稳定各层输入分布
- 采用合适的权重初始化方式(如 Xavier 或 He 初始化)
- 在网络设计中控制层数与梯度路径长度
此外,近年来 Residual Connection(残差连接)和 Layer Normalization 等技术也在深层网络中得到广泛应用,用于缓解梯度问题。
综上所述,反向传播通过链式法则传播误差信号,是神经网络训练的核心机制。而要实现高效稳定的反向传播,需综合考虑激活函数选型、损失函数结构、权重初始化、归一化技术与模型深度等因素。
6. 随机梯度下降(SGD)与 Mini-batch 梯度下降
神经网络的训练本质上是通过优化某个损失函数 J ( θ ) J(\theta) J(θ) 来寻找最佳参数 θ \theta θ,最常用的方法是基于梯度的优化方式。
梯度下降(Gradient Descent)
标准的批量梯度下降(Batch Gradient Descent)在每一次更新中使用整个训练集:
θ ← θ − η ⋅ ∇ θ J ( θ ) \theta \leftarrow \theta - \eta \cdot \nabla_\theta J(\theta) θ←θ−η⋅∇θJ(θ)
- 优点:梯度方向准确
- 缺点:每次迭代计算成本高,不适合大数据集
随机梯度下降(SGD)
随机梯度下降在每次迭代中仅使用一个样本来估计梯度:
θ ← θ − η ⋅ ∇ θ J ( θ ; x ( i ) , y ( i ) ) \theta \leftarrow \theta - \eta \cdot \nabla_\theta J(\theta; x^{(i)}, y^{(i)}) θ←θ−η⋅∇θJ(θ;x(i),y(i))
- 优点:更新频繁、可以快速跳出局部极小值
- 缺点:单样本噪声大,收敛不稳定
权值更新可能会减少所呈现的单个模式上的误差,但会增加整个训练集上的误差。
小批量梯度下降(Mini-batch SGD)
Mini-batch 是在全批量和完全随机之间的折中策略。每次迭代使用一个包含 m m m 个样本的批次(mini-batch)计算梯度:
θ ← θ − η ⋅ 1 m ∑ i = 1 m ∇ θ J ( θ ; x ( i ) , y ( i ) ) \theta \leftarrow \theta - \eta \cdot \frac{1}{m} \sum_{i=1}^{m} \nabla_\theta J(\theta; x^{(i)}, y^{(i)}) θ←θ−η⋅m1i=1∑m∇θJ(θ;x(i),y(i))
- 一般选用 m = 32 , 64 , 128 m = 32, 64, 128 m=32,64,128 等较小值
- 兼具效率与稳定性,适用于现代硬件并行处理
训练流程
- 将训练集打乱并分成若干 mini-batches
- 对每个 mini-batch:
- 前向传播计算输出
- 反向传播计算梯度
- 更新权重参数
- 多轮迭代直到收敛
小结
| 方法 | 每次更新使用样本数 | 优点 | 缺点 |
|---|---|---|---|
| Batch | 全部训练样本 | 梯度稳定 | 内存消耗大、速度慢 |
| SGD | 单一样本 | 快速跳出局部最优 | 更新方向不稳定 |
| Mini-batch | 少量样本(如 64) | 训练速度与稳定性兼顾 | 最广泛使用的策略 |
使用 Mini-batch SGD 是现代深度学习训练的默认做法,通常配合动量、Adam 等优化器提升效果。
SGD 方法分析(SGD Analysis)
我们对两种常见的 SGD 训练方式进行优缺点对比分析:
单样本 SGD(One-example based SGD)
- 每次仅用一个样本估计梯度,因此噪声较大,更新方向波动明显
- 每次迭代开销小,比批量学习更快,尤其在数据存在冗余时效果更优
- 由于随机性高,噪声反而有助于跳出局部最小值
- 缺点是收敛路径不稳定,权重更新可能震荡,不一定收敛到稳定最优点
小批量 SGD(Mini-batch based SGD)
- 收敛性理论良好:梯度估计更平稳,易于分析收敛速度和稳定性
- 可结合批量加速技术(如 momentum、Adam、Nesterov)进行训练优化
- 由于噪声较小,更适合用于理论分析与调试模型行为
小结比较
| 项目 | 单样本 SGD | 小批量 SGD |
|---|---|---|
| 计算速度 | 每步快 | 中等 |
| 噪声/波动 | 大,有助于跳出局部最小值 | 小,梯度估计更稳定 |
| 收敛路径 | 易震荡,不一定收敛 | 更平稳,理论收敛性强 |
| 可结合技术 | 较少 | 支持大部分优化算法(如 Adam) |
| 理论分析难度 | 高 | 易于分析与调试 |
SGD 的噪声既是缺点也是优点,关键在于如何结合合适的 batch size 和优化器,以实现训练稳定性与收敛效率的平衡。