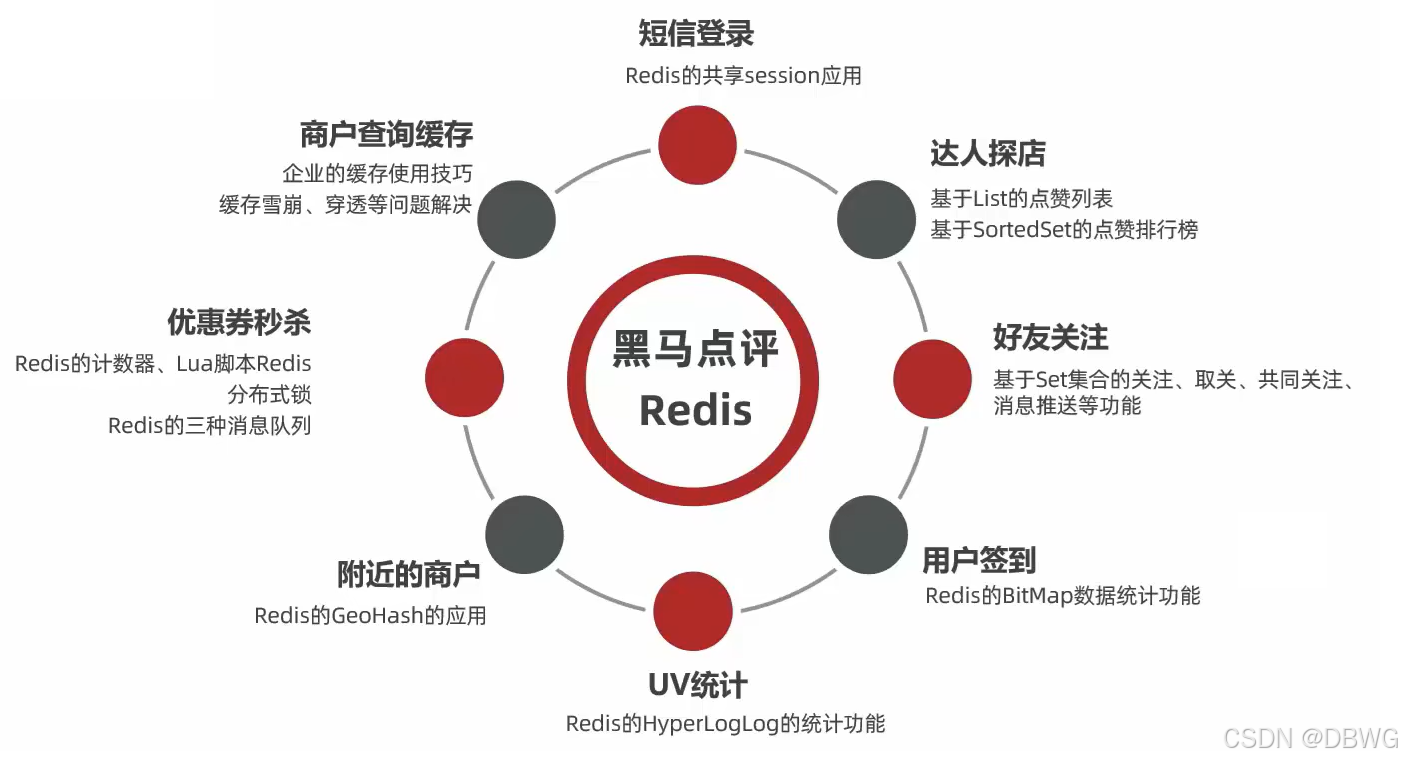
【黑马点评】redis实战
参考: 【黑马程序员Redis入门到实战教程,深度透析redis底层原理+redis分布式锁+企业解决方案+黑马点评实战项目】
本文是原理和使用分析。
redis入门参考 https://blog.csdn.net/JK01WYX/article/details/147500712?spm=1001.2014.3001.5501
文章目录
- Redis的Java客户端
- redis 实战
- 短信登录【过期】
- 达人探店【List; ZSet】
- 好友关注【Set 集合运算】
- 用户签到【BitMap】
- UV统计 【基数统计】
- HyperLogLog
- 附近的商户 【地理定位】
- GEO hash
- 优惠券秒杀 【Lua】
- 商户查询缓存 (如4.缓存三剑客)
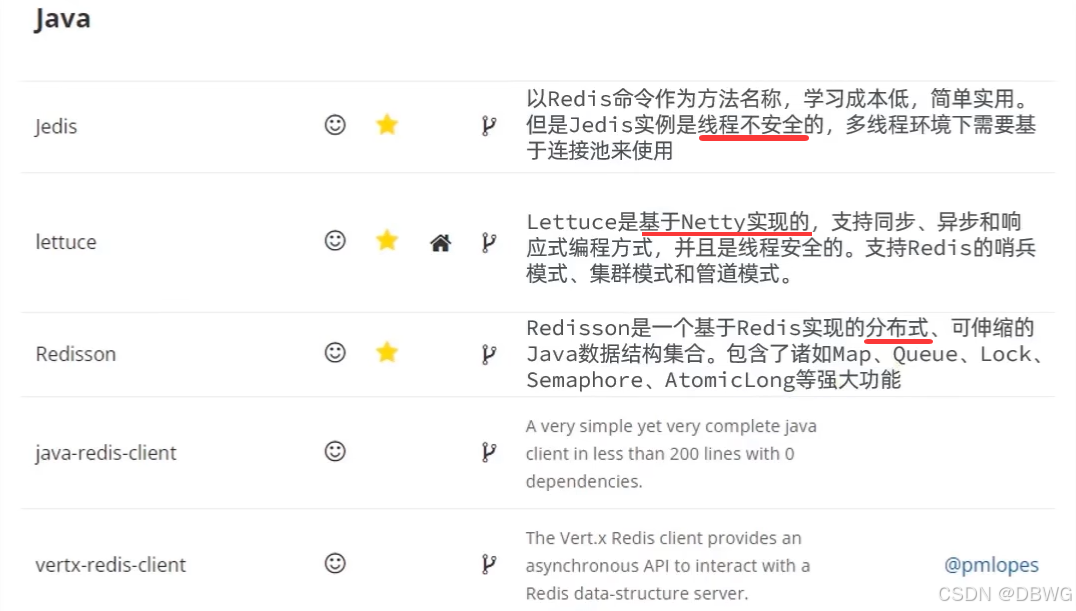
Redis的Java客户端
其实就是一些可编程redis的java库,来自 黑马程序员-点评项目
redis 实战
短信登录【过期】
【高性能存储验证码,自动过期无需手动清理。】
使用 SET key value EX 60 设置验证码 + 60 秒过期;
限流防刷:用户手机号短时间多次请求,可设置请求次数的限制,如 INCR+EXPIRE。 (防止短信服务费用暴涨)
# 验证码:
SET sms:login:13800000000 123456 EX 60# 限流防刷:
INCR req:sms:13800000000
EXPIRE req:sms:13800000000 60
达人探店【List; ZSet】
使用场景:点赞列表、点赞排行榜。
【高效支持排序、分页、范围查询;“轻量级业务中台”】
List 存储最近点赞记录,适合展示列表;
- 使用
LPUSH将最新点赞记录插入头部; - 可用
LRANGE实现分页;可用LTRIM保留最近 N 条记录,限制列表长度。(trim 修剪;RPUSH 是右插入)
SortedSet(zset) 存储排行榜,score 为点赞数或权重;
# 某店铺被用户点赞
LPUSH like:shop:1001 user:uid123
LTRIM like:shop:1001 0 99 # 只保留最新的 100 条记录# 用户点赞;查询点赞 top 10;删除某个店铺的排行榜数据
ZINCRBY like:rank 1 shop:1001
ZREVRANGE like:rank 0 9 WITHSCORES
ZREM like:rank shop:1001
在“达人探店”这个场景下,Redis 不再只是缓存数据库,而是被当作一个高性能、具备特定业务逻辑的数据处理引擎来使用,甚至可以理解为一种“轻量级业务中台”。
像抖音这种 千万主播并发直播、实时打赏榜单不断更新 的极端高并发场景,其核心优化策略之一就是:
只缓存热门主播的打赏榜单”,其他不进 Redis!
好友关注【Set 集合运算】
【集合运算高效、操作简单。】
这个场景和“达人探店”一样,也是非常经典的 Redis 轻社交系统实现案例
使用 Set 存储关注集合,如 SADD user:123:follow 456;
SINTER 求共同关注,SUNION SDIFF 求关注推荐;
# 1. 用户关注某人(写入)
SADD user:123:follow 456 # 用户123关注用户456
SADD user:456:fans 123 # 用户456的粉丝列表中加上123# 2. 查询某人关注列表 / 粉丝列表
SMEMBERS user:123:follow # 查用户123关注了谁
SMEMBERS user:456:fans # 查用户456的粉丝是谁# 3. 共同关注【交集】
SINTER user:123:follow user:456:follow
# 查 123 和 456 都关注了哪些人# 4. 推荐关注【并集,差集】
SUNION user:456:follow user:789:follow
SDIFF result user:123:follow
# 合并朋友的关注列表,再减去自己已经关注的
-- “推荐关注” 用 lua 实现 (Lua 是一种轻量级的脚本语言,设计初衷是为了嵌入到应用程序中提供灵活的扩展功能)
local union = redis.call("SUNION", KEYS[1], KEYS[2])
local result = {}
for _, uid in ipairs(union) doif redis.call("SISMEMBER", KEYS[3], uid) == 0 then -- SISMEMBER KEYS[3] uid 检查 uid 是否存在于第三个集合(KEYS[3])中。table.insert(result, uid)end
end
return result-- redis中这样调用:
redis-cli EVAL "脚本内容" 3 users:new users:premium users:blocked
-- 3 表示脚本接收 3 个键名参数,后续参数依次对应 KEYS[1], KEYS[2], KEYS[3]。
可是redis在内存中,能存得下吗?
1亿 用户 × 500 个关注 × 16 字节的每个关注关系大小 ≈ 800 GB
实际做法:冷热数据分层+限量策略 —— 热数据放 Redis + 冷数据放 DB + 设关注上限
当前关注者和被关注者插入redis,为热点数据,随后设置TTL或者LRU策略逐渐淘汰即可。
像冷门博主,也未必需要拉入缓存。
持久化这边,一次可以读取set的所有内容来存,SADD也支持一次插入多个成员,进行批量恢复。
用户签到【BitMap】
【节省空间,每月只需一个整数即可表示 31 天 —— int 32位。】
(BitMap 是位图,这里不详细讲解了。)
使用 BitMap 表示某天是否签到:如 SETBIT user:sign:202505 23 1 表示5月第24天签到;
使用 BITCOUNT 统计本月签到次数;
# 查询某日是否签到
GETBIT user:sign:123:202505 23
# 本月累计签到次数
BITCOUNT user:sign:123:202505
# bitmap会自动扩容,但不支持回收空间
> SETBIT mybitmap 10000000 1
(integer) 1
> STRLEN test_bitmap
(integer) 1250001Redis 会自动将字符串扩展至能容纳 第 10000000 位 的大小,也就是:
- 10000000 bits ≈ 1,250,000 字节(约 1.25MB);
Redis 会分配内存,后面的位默认为 0。
UV统计 【基数统计】
独立访客数(Unique Visitor)
(基数统计:统计一个集合中不重复元素,这被称为基数。)
【极大压缩空间,误差可接受(约 0.81%)】
Redis 的 HyperLogLog 是一种 基于概率算法的基数统计结构,用于统计不重复元素的个数。
在极小内存(固定12KB)下,完成大规模数据去重计数,标准误差为 ±0.81%。
如果你要统计大规模用户中的“唯一个体数量”,但不关心具体是谁、能接受少量误差,那么 Redis 的 HyperLogLog 是内存效率最优、运算最快的选择。
某网站想统计:
2025年5月24日,一共有多少 不同用户访问了首页:
使用 HyperLogLog:
计数当日新用户 PFADD uv:20250524 user_id;
统计当日 uv PFCOUNT uv:202505
# 统计某月累计 UV:多日的key合并
PFMERGE uv:202505 uv:20250501 uv:20250502 ... uv:20250531
PFCOUNT uv:202505
HyperLogLog
Log 表示对数,HyperLogLog 意思是超对数计算,是 LogLog 算法的改进版
HyperLogLog 是一种概率性数据结构,可以在极小的内存开销(~12KB)下,统计数千万甚至上亿数据的去重个数(基数),误差大约在 0.81% 左右。
PF:Probabilistic Filter 概率性过滤器
# 添加元素
PFADD key element [element ...]
# 获取基数估计值
PFCOUNT key
# 合并多个 HyperLogLog
PFMERGE destkey sourcekey1 sourcekey2 ...
- HyperLogLog 只能估计“有多少个”,不能知道是谁
- PFADD 和 PFCOUNT 都是 O(1) 操作
- 一旦加进去就不能删,也不能撤销
数据结构:
参考 https://cloud.tencent.com/developer/article/2333100
https://blog.csdn.net/ldw201510803006/article/details/126093455
头部:
struct hllhdr {char magic[4]; // 表示数据结构的标识符,这里始终为 HYLLuint8_t encoding; // 编码方式 稠密HLL_DENSE/稀疏HLL_SPARSEuint8_t notused[3]; // 拓展uint8_t card[8]; // 缓存基数uint8_t registers[];// 存数据
};
数据部分分了 2 14 2^{14} 214 个桶(16384),每个桶内部是 6bit
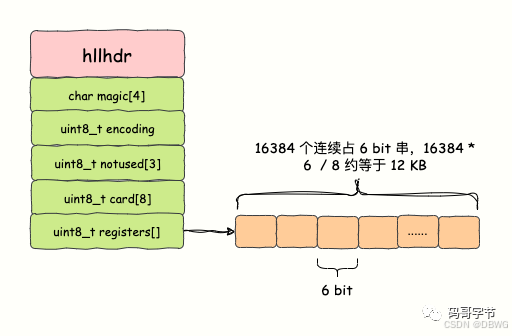
在计数比较小的时候,存储空间采用系数矩阵,占用空间很小。
在计数很大,稀疏矩阵占用的空间超过了阈值才会转变成稠密矩阵,占用 12KB 空间。
工作原理:
如果你在一批哈希值中见过最长的连续前导零是 k 位,那大致可以推断有约 2^k 个不同元素。
(如哈希值: 0001001001000… 有3个前导0)
关键直觉:出现长前导零的概率很小
一个随机二进制串以 k 个连续 0 开头的概率是: 1 2 k + 1 \frac{1}{2^{k+1}} 2k+11 (k个0后下一位得是1)
所以比如有 10个前导0,那可能就有 2 11 2^{11} 211 (2048)个数了!
实际还做优化:
分桶分别估计,最后合并;
再利用调和平均 n ∑ 1 x i \frac{n}{\sum \frac{1}{x_i}} ∑xi1n
调和平均: 假如开车,去程60km/h,回程120,平均速度不能是直接除以二为 90,因为在 60 km/h 上花费了更多时间,调和平均: 2 1 60 + 1 120 = 80 k m / h \frac{2}{\frac{1}{60} + \frac{1}{120}} = 80 km/h 601+12012=80km/h
这里 因为桶的估计值是指数级的,直接平均会被大值影响,用调和平均更稳健
附近的商户 【地理定位】
使用场景:地图定位,查找附近店铺。
【内置地理位置查询,性能远高于传统数据库。】
Redis 自 3.2 起内置了 Geo 系列命令,允许你使用类似地图的方式去管理位置数据,执行 高性能的地理查询,如:
- 添加商户地理坐标(经纬度);
- 查找指定位置附近的所有商户;
- 查询两个地点的距离;
- 获取商户位置坐标等。
底层原理是 Geohash + SortedSet(有序集合)
Redis 的 Geo 模块可以高性能地支持“查找附近商户/服务”功能,在中小体量 LBS 场景下,效果远超传统数据库方案,尤其适合:本地生活、外卖、出行、配送、社交等应用。
使用 GEOADD 添加商户地理位置;
使用 GEORADIUS 或 GEOSEARCH 查找周边商户;
# GEOADD key 经度 纬度 名称
GEOADD shop:geo 113.935 22.540 "星巴克-南山店"
GEOADD shop:geo 113.931 22.538 "喜茶-深圳大学城"
GEOADD shop:geo 113.937 22.542 "麦当劳-南山科技园"# 查询附近商户(按半径):
GEORADIUS shop:geo 113.933 22.539 1 km WITHDIST
# 新版
GEOSEARCH shop:geo FROMLONLAT 113.933 22.539 BYRADIUS 1 km WITHDIST# 查询距离
GEODIST shop:geo "星巴克-南山店" "喜茶-深圳大学城" km# 获取经纬度:
GEOPOS shop:geo "麦当劳-南山科技园"
GEO hash
初始范围: 经度范围:[-180, 180],纬度范围:[-90, 90]
GeoHash 使用 经度和纬度交替处理,从较大的范围开始进行二分,每次划分交替处理经度和纬度:
- 判断当前值是否大于中点,如果是,记为 1;否则为 0
- 每次划分后,更新当前的最大/最小边界
最后得到一个 52 位 unsigned 64-bit 整数,位置越接近,其编码的前缀越长(更相同)
解码时只需反向地通过比特串去不断还原出区域范围,并最终得到经纬度的中心点。
优惠券秒杀 【Lua】
使用场景:限时限量秒杀抢券。
【高并发下防止超卖、抢重复券、库存一致性问题。】
Lua 脚本:原子操作(防止超卖、重复抢)
Redis 单线程,Lua 脚本可以保证整个脚本逻辑的原子性;一条 EVAL 命令在执行期间不会被其他命令打断;非常适合处理 “库存扣减 + 抢购记录写入” 这类必须一致的操作
使用 Lua 脚本 保证库存扣减 + 用户记录的原子操作;
使用 SETNX 或 Redisson 实现分布式锁;
利用 Stream / List / PubSub 三种消息队列异步处理下单;
一、 Lua 脚本:扣减库存并记录用户
-- KEYS[1] = 库存Key
-- KEYS[2] = 用户记录Key
-- ARGV[1] = 用户ID-- 判断用户是否已抢过
if redis.call("SISMEMBER", KEYS[2], ARGV[1]) == 1 thenreturn 0
end-- 判断库存是否充足
if tonumber(redis.call("GET", KEYS[1])) <= 0 thenreturn 0
end-- 扣减库存
redis.call("DECR", KEYS[1])-- 添加用户记录
redis.call("SADD", KEYS[2], ARGV[1])return 1
//java代码调用
String script = "脚本如上...";
redisTemplate.execute(new DefaultRedisScript<>(script, Long.class), Arrays.asList("seckill:stock:coupon123", "seckill:user:coupon123"),userId);二、分布式锁:防止重复下单(业务层)
SET lock:user:123 1 NX EX 3
三、异步处理下单:削峰填谷
抢券成功后,不直接下单,异步发送消息让下游慢慢处理。
| 方式 | Redis结构 | 说明 |
|---|---|---|
| Stream | Redis Stream | 高级消息队列,支持ACK、消费组 |
| List | LPUSH / BRPOP | 简单队列,适合轻量业务 |
| PubSub | 发布订阅 | 不可持久化,不建议用于秒杀 |
商户查询缓存 (如4.缓存三剑客)
使用场景:访问热门商户详情信息。
访问热门商户(如某网红餐厅)详情时,如果每次都查数据库:会造成数据库压力暴增;大量并发请求甚至可能压垮 DB;
而 Redis 提供毫秒级响应、高 QPS,非常适合读多写少的场景。
【极大提高系统吞吐量和稳定性。】
使用缓存 + TTL 缓解数据库压力;
解决缓存穿透(如:空值缓存)、缓存击穿(如:互斥锁)、缓存雪崩(如:设置随机 TTL);
缓存穿透:
场景:用户频繁请求一个不存在的商户ID,比如 id=-1、id=999999 【查询不存在的数据,击穿缓存+打爆DB】
解决方案:在redis缓存空值,下次请求直接命中空值,避免访问 DB。
// 数据库返回 null,缓存一个占位符,如 ""
redis.set("shop:123456", "", 2分钟TTL);
缓存击穿:
场景:商户 10001 是热点,一旦缓存过期,瞬间成百上千个请求打到数据库。
解决方案:
-
互斥锁(推荐)。只有一个线程能访问 DB,其他等待。
一个拿到后缓存,其他请求读缓存即可。 -
逻辑过期:数据不真正过期,后台线程异步刷新
缓存雪崩:
场景:你设置了 1 小时 TTL,整点全部缓存过期,所有请求打到数据库。
解决方案:设置随机 TTL,让不同 Key 的过期时间错开,避免同一时间一起失效。
redis.set("shop:10001", json, 60分钟 + 随机5分钟)