大模型应用开发之RAG
Intro:RAG框架
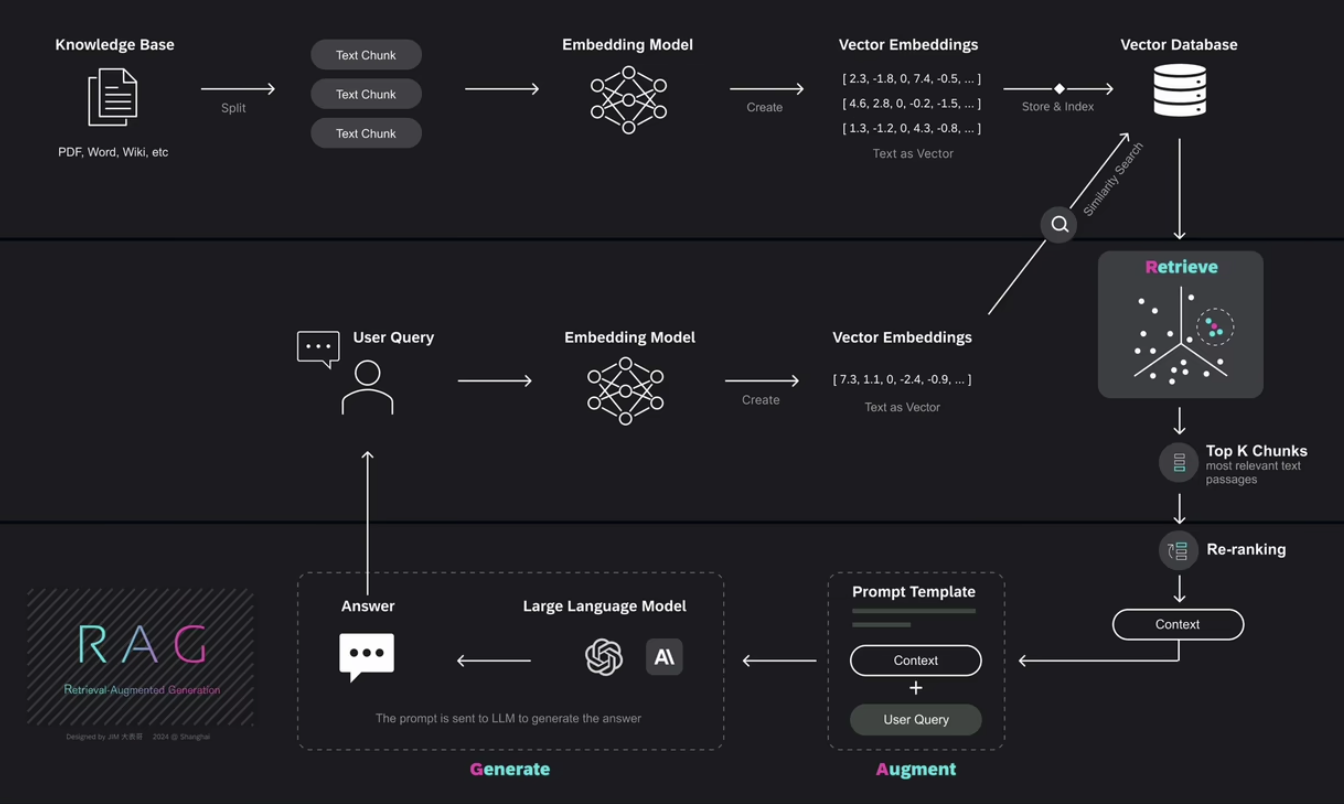
一、RAG概述
1、 LLM 的缺陷
- 幻觉:LLM 可能生成无事实依据、不与现实世界一致,甚至完全虚构的内容。
- 知识更新滞后:LLM知识的有效性取决于训练数据的时间,因此存在知识更新滞后的问题。
- 回答缺乏透明度:LLM 生成的回答通常缺乏引用来源,导致用户难以判断答案的真实性,降低了模型的可信度。
2、Definition
为了缓解上述问题,RAG通过检索外部知识库中的相关信息,并将这些信息作为上下文输入到语言模型中,即在 LLM 生成答案时检索外部数据,从而增强生成能力
- 减少幻觉问题,提供事实依据。
- 通过外部知识库实现实时更新,无需重新训练模型。
- 生成结果带有检索来源,提升在专业领域的表现。
3、组件
- 向量数据库(Vector DB): 存储和检索嵌入向量,例如 FAISS、Pinecone、Weaviate。
- 嵌入模型(Embedding Model): 将文本转换为向量,如 OpenAI Embeddings、BERT.
- 检索模型(Retriever): 搜索相关信息,可使用BM25、Dense Retrieval (DPR)等方法
- LLM(Large Language Model): GPT-4等,负责生成最终答案。
- 融合策略(Fusion Strategy): 结合检索信息 + LLM 结果,提高生成的可信度。
4、常见应用领域
- 企业知识问答
- 法律/医疗领域问答
- 金融风控
- 搜索增强对话
二、RAG实现
1、数据处理
1)数据清洗cleaning
- 去重(Deduplication):去除重复文档或内容,提高存储效率,减少无效检索。
- 噪声过滤(Noise Filtering):删除 无关内容、广告、低质量文本 ,避免干扰 LLM 生成。
- 格式标准化(Normalization):统一文本编码、标点符号、日期格式,保证数据一致性。
2)数据分片chunking
- 基于规则的chunking
- 固定长度分片:按固定字符数或 固定单词数切分,如每 512 词分为一个 Chunk(简单易实现,适合结构化文本(如 Wikipedia)-但可能导致句子或段落被拆散,影响语义完整性)。
- 基于段落的 Chunking:以自然语言的逻辑单元(如句子、段落)进行分片,保持上下文完整性(可以减少语义破坏,适用于法律、医学文档但Chunk 长度不均匀,可能影响索引效率)
- 滑动窗口分片:相邻 Chunk 之间有部分重叠,如窗口大小 256 词,滑动步长 128 词。(可以保证跨段落上下文信息,减少查询时的信息丢失但会增加存储和计算开销)。
- 基于模型的chunking
- Transformer 句子分割:使用 Transformer 模型(如 BERT、RoBERTa)检测句子边界 ,以高语义相关性进行分片。例如 BERT 的 NSP 预训练任务(适用于复杂文档,如法律、医学文本,避免破坏逻辑结构)。
- 基于依存关系的 Chunking:使用依存句法分析(Dependency Parsing)识别主谓宾结构,以语法结构为基础拆分 Chunk(适用于技术文档 ,如 API 说明书、论文摘要)
- 基于LLM 的 Chunking:让 LLM 自适应判断 Chunk 切分点 ,根据上下文哪些部分应该作为独立片段(适用于非结构化文本 如用户评论、社交媒体内容)
- Small2Big Chunking
核心思想:先生成较小的 Chunk,再根据语义相似度合并成较大的 Chunk,最终形成更合理的文档分片结构。结合了固定长度切分与语义分析,避免了传统 Chunking 方法的弊端(过小 Chunk 可能丢失上下文信息,导致 LLM 生成错误答案;过大 Chunk 可能增加检索噪声,影响搜索精准度)。
- 初步切分小片段 (Small Chunks):使用固定长度切分,或者采用 自然段落切分,保持文本语义完整性。
- 计算 Chunk 之间的语义相似度:使用 BERT/SBERT 向量嵌入将 Chunk 表示为向量;计算相邻 Chunk 之间的 余弦相似度S_{i,i+1};设定相似度阈值 \tau,如果 S_{i,i+1} > \tau\,则合并 Chunk。
- 相似度高的 Chunk 进行合并,形成更大、更有信息密度的片段;逐步执行,直到不再满足合并条件。
- 存入向量数据库 采用 FAISS/Pinecone 存储优化后的 Chunk。
3)数据嵌入embedding
Embedding 是检索效率的核心。RAG 的工作方式是先检索相关文档,再根据这些文档生成答案。而检索的关键就是通过 Embedding 把查询(Query)和文档转化为向量,然后比较它们的相似度,找到最匹配的文档。
- 嵌入模型选择
- OpenAI—text-embedding-ada-002:输出 1536 维的向量,适合通用任务,支持多种语言
- SBERT(Sentence-BERT):BERT 的变体,专为句子级 Embedding 设计,适合语义匹配和问答任务
- BAAI(bge-base-zh):在中文任务上表现优异,适合中文 RAG 应用
- DistilBERT:BERT 的轻量级版本,计算效率高,适合资源受限环境
- 自定义微调模型:通过微调现有模型(如 BERT、RoBERTa)以适应特定专业领域(如法律、医疗)或特定任务的 RAG 应用
- 优化query
- Query Rewriting(查询重写):用语言模型(LLM)把用户的查询改得更自然、更容易检索
- HyDE(假想文档嵌入):通过生成“假想文档”或“假想答案”,用这个假想答案的向量去匹配真实的文档来提升检索效果
- 优化文档 Embedding
- 生成摘要:对于长文档(像论文),系统会生成一个简短的摘要,把摘要的 Embedding 存起来,跟全文的 Embedding 一起用
- 假想问题:系统为每个文档生成一些它可能回答的问题,然后存下这些问题的 Embedding
2、检索Retrieval
1)检索流程
RAG 检索流程通常包括两个阶段:
- 召回(Retrieval): 基于关键词(如 BM25)或语义(Embedding ANN)快速检索出候选文档
- 重排序(Rerank): 对初步召回的文档进行更为精细的语义相关度计算,得到精确的排序结果。重排序算法负责第二阶段的任务,进一步提高检索精确性和召回效果。
2)召回
召回是指从大规模知识库中准确找到与用户查询相关内容的过程。这是RAG系统的第一步,也是最关键的步骤,因为后续生成的质量很大程度上依赖于召回内容的相关性和准确性
- 关键词检索:基于精确的词汇匹配进行检索,典型代表是BM25算法
- 语义检索:利用向量空间模型表示文本语义,通过向量相似度进行检索,包括:
- 余弦相似度算法
- FAISS
- HNSW
- 混合检索:结合关键词检索和语义检索的优势,采用多阶段检索策略:
- 并行召回
- 串行召回
3)重排序
Rerank一般流程:
- 输人:候选文档集合{D1,…,Dn}和查询文本 Q;
- 精细打分:利用 Cross-Encoder 模型分别计算每对(Q,Di)的相关度评分,常见的Cross-Encoder 模型有:
- 基于 BERT 的 Cross-Encoder
- 领域特定 Finetuned Cross-Encoder
- 重排序:按照分数高低重新排序,取前k个文档作为最终结果。
提升 Rerank 算法效果的常见方法包括:
- 领域微调(Finetune):使用相关领域数据微调 Cross-Encoder 模型;
- 知识蒸馏(Knowledge Distillation):训练轻量级模型,降低延迟;
- 难负例(Hard Negative)训练:增强模型识别能力。
3、生成Generation
生成策略用于指导生成模型(如 GPT )根据检索结果生成精准且连贯的答案。
1)生成策略流程
- 检索阶段获取与查询相关的文档或片段;
- 将检索内容以适当方式融人 Prompt 中;
- 使用生成模型(如 GPT-4)基于 Prompt 生成最终答案
2)几种生成策略
- Prompt-based 生成策略:该策略将检索到的文档直接放入 Prompt 中进行生成,此方法简单高效,易于实现,但受限于模型最大上下文长度,且可能产生幻觉(Hallucination)问题
Prompt =[Instruction]+[Retrieved Docs]+[Query]
- 融合生成策略(Fusion-in-Decoder):该策略通过在 Decoder 阶段同时结合多个检索文档的信息,增强生成答案的精准度,能有效减少幻觉问题,但推理速度较慢,实现成本相对较高。
- RAG-Sequence:逐步选择合适文档生成答案,每一步动态选择上下文。
- RAG-Token:每生成一个词(Token)都动态选择不同文档的信息以支持当前生成的内容。
- 选代生成策略(Iterative Generation):允许模型在多轮迭代中逐步优化答案,常用于需要极高准确性的场景。
- 根据初步答案再次检索相关文档;
- 重新生成答案,迭代直至达到期望质量;
- 自一致性生成策略(Self-Consistency):使用多次生成并融合多个候选答案以提高整体质量,能有效提高结果稳定性,但计算成本较高。
- 对同一检索结果多次调用生成模型,得到多个答案;
- 采用多数投票或评分融合机制选择最优答案;
3)生成策略优化
- Prompt 工程优化:合理设计 Prompt 结构,提升生成质量;
- 领域特定模型微调(Finetune):在专业领域内优化生成效果;
- Temperature 和 Top-k 调整:调低 temperature 参数以提高生成稳定性和一致性。
4、增强Augment
1)预训练数据增强
预训练阶段的数据增强以提升模型泛化能力为主,常用技巧包括:
- 随机掩蔽(Random Masking):随机掩盖句子或文档中的词汇,让模型预测被掩盖的内容,增强6模型语言理解能力。
- 随机替换同义词(Synonym Replacement):使用 WordNet 或词典随机替换句子中的词汇,提升面模型对同义表达的泛化能力。
- 上下文乱序(Sentence Permutation):在段落级别随机打乱句子顺序,增强模型对整体语义的理许。
- 回译(Back Translation):利用多语言模型,将文本翻译成另一种语言再回译回来,以生成语义等价但表达不同的文本,提升语义泛化能力。
2)微调数据增强
微调阶段的增强技术更加关注领域内的精准表达和特定任务适配,常见方法如下:
- 领域术语增强(Domain-specific Term Replacement):在特定领域(如医学、法律)内,用同领域的同义术语进行替换,强化模型对领域术语的理解。
- 句子拼接与切分(Sentence Concatenation and Splitting): 将多个句子拼接或长句切分为短句增加训练样本多样性,提高模型对复杂上下文的处理能力。
- 对比学习增强(Contrastive Learning Augmentation):通过构造正负样本对(如问答对),采用对比学习提高模型检索阶段的精确度和生成阶段的连贯性。
- 知识注人(Knowledge Injection):从知识图谱或百科知识库抽取相关知识,嵌入到训练数据中以提升模型对知识的捕获和利用能力。
3)推理数据增强
推理阶段的数据增强侧重于实时提高生成质量与鲁棒性,常用技巧包括:
- Prompt 增强(Prompt Augmentation):使用多样化的 Prompt 结构或模板,显著提高生成模型对问题的理解能力与稳定性。
- 上下文扩展与补充(Context Expansion):在原始检索文档基础上,额外增加相关背景文档或扩展信息,降低生成幻觉(hallucination)风险。
- 多次推理融合(Multi-sampling Generation):针对同一问题进行多次生成(不同 temperature 或top-k),通过投票或打分机制选择最优答案,显著提升答案质量和稳定性(Self-consistency 方法)。
- 迭代自问白答(Iterative SelfAsk):利用生成结果多次检索和迭代生成,增强生成内容的深度与准确性。
三、RAG评估
1、评估方法
1)检索评估
- 评估召回质量,即评估系统能否召回正确且相关的文档
- 检索评估关注检索阶段的准确性和召回率,要关注的是 context relevance 指标,及检索到的 chunks 与 query 的相似度。
- 常用方法包括:MRR,Recall@k,NDCG, Hit rate 等
2)生成评估
- 评估最终生成答案的质量,包括准确性、流畅性与一致性。
- 一种衡量生成模型给出的答案能否忠实地反映检索到的上下文内容避免产生幻觉或无根据的答案,确保生成的答案是可信的和基于事实的。
- 另一种关注模型所生成的答案是否直接有效地回答了用户问题,体现了答案的准确性和有效性。
2、评估框架
- LangChain Evaluation:内置标准化评估流程,支持检索评估、生成评估及自动指标计算。
- LlamaIndex Eval Framework:专注于 RAG 场景,提供综合的检索与生成质量评估。
- Haystack Eval Framework:集成了检索与问答场景的评估能力,适用于工业级 RAG 系统。
- RAGAS (Retrieval-Augmented Generation Assessment): 专门用于 RAG 场景的评估框架可同时评估检索与生成质量。