Tool-Star新突破!RL赋能LLM多工具协同推理,性能全面超越基线方法
Tool-Star新突破!RL赋能LLM多工具协同推理,性能全面超越基线方法
在大语言模型(LLM)推理能力快速发展的背景下,如何让模型高效调用多种外部工具进行协同推理成为新挑战。本文提出的Tool-Star框架,通过创新的数据合成与强化学习策略,显著提升了模型在复杂推理任务中的表现,为多工具集成推理开辟了新路径。
论文标题
Tool-Star: Empowering LLM-Brained Multi-Tool Reasoner via Reinforcement Learning
来源
arXiv:2505.16410v1 [cs.CL] + https://arxiv.org/abs/2505.16410
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁
文章核心
研究背景
近年来,大规模强化学习(RL)推动大语言模型(LLMs)在思维链(CoT)推理中展现出深度思考、自我反思等涌现行为,显著提升复杂任务解决能力。工具集成推理(TIR)通过引导 LLMs 与外部工具交互,将纯语言推理拓展至信息检索、精确计算等更广泛场景。
现有 TIR 研究主要聚焦单工具场景,或通过监督微调(SFT)、提示工程等方式实现工具调用,但难以让模型自主发现高效推理模式。而真实推理任务常需模型同时具备计算与动态信息获取能力,亟需多工具(如搜索引擎、代码解释器)的深度反馈整合,这一领域的系统性研究缺失成为 TIR 实际应用的关键瓶颈。
研究问题
1. 工具使用合理性与效率:如何在平衡工具调用成本的同时,实现高效的工具增强推理。
2. 多工具协同推理:如何让模型在推理过程中有效整合多种工具的功能。
3. 工具使用数据稀缺:高质量多工具使用数据匮乏,限制了模型训练效果。
主要贡献
1. 提出两阶段训练框架:通过冷启动微调(Cold-Start Fine-tuning)引导模型探索工具调用反馈中的推理模式,结合分层奖励设计的多工具自批评强化学习算法(Multi-Tool Self-Critic RL),促进工具间有效协作,这与传统单工具RL方法有本质区别。
2. 设计通用数据合成流水线:结合工具集成提示与基于提示的采样,自动生成大规模工具使用轨迹,并通过质量归一化和难度感知分类筛选样本,解决数据稀缺问题,相比传统数据收集方法更高效。
3. 集成六类工具并优化推理:训练阶段引入搜索引擎、网页浏览器代理和代码解释器三类核心工具,推理阶段添加代码调试器、工具使用回溯器和推理链优化器三类工具,提升推理可靠性,丰富了工具集成模式。
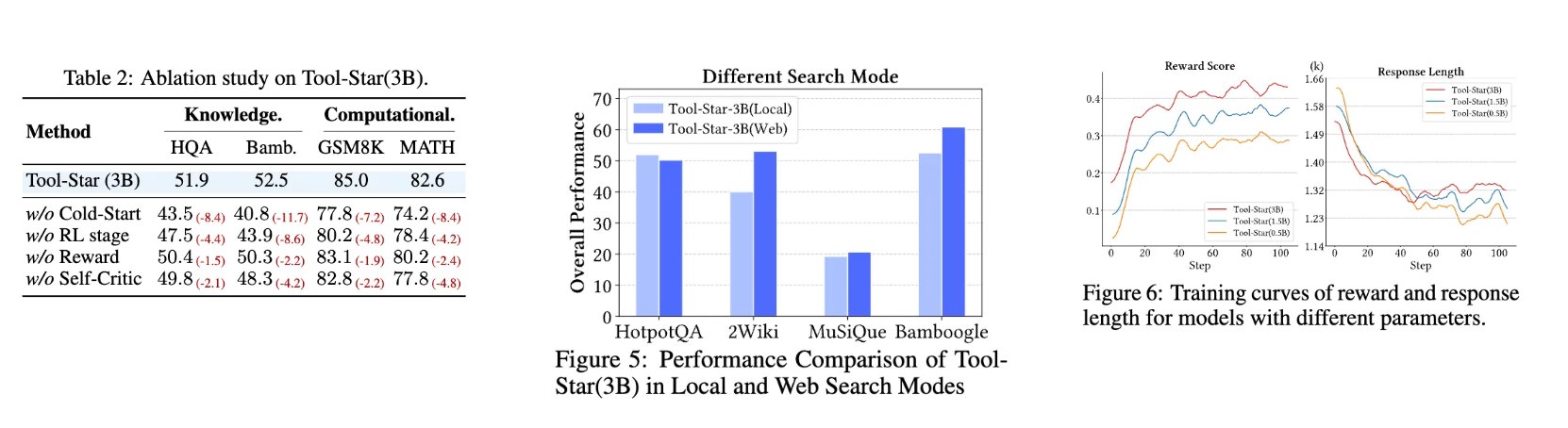
4. 性能全面超越基线:在10余个挑战性推理基准上,Tool-Star的工具使用准确率和推理性能均显著优于Search-o1、ToRL等基线方法,验证了方法的有效性。
方法论精要
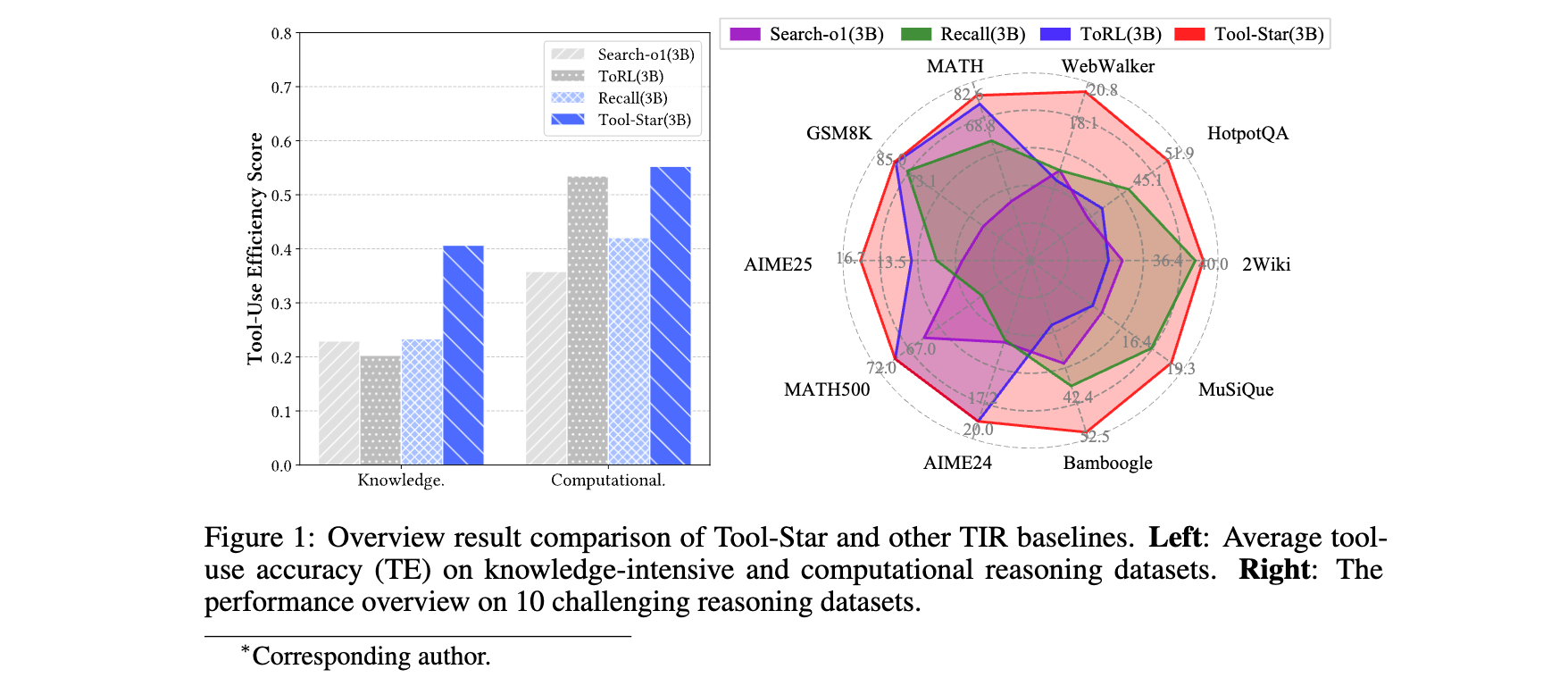
工具集成推理数据合成流水线
为解决多工具推理数据稀缺问题,Tool-Star 设计了三层数据处理架构:
- 数据采集与采样:从 NuminaMath、HotpotQA 等公开数据集提取 90K 文本数据与 1K 现有 TIR 数据,结合TIR 提示采样(引导 LLM 生成工具调用轨迹)和提示采样(在纯文本推理中插入逻辑验证 / 答案反思提示),生成初始工具使用轨迹。
- 质量归一化:通过工具调用频率控制(阈值 β=5)、重复调用过滤、格式标准化(统一<search>/<python>等标签),剔除不合理样本。
- 难度分级:基于纯语言推理(DR)与工具集成推理(TIR)的正确性,将数据划分为 “简单 - 困难” 四级:DR 正确样本用于冷启动微调,TIR 困难样本保留至 RL 阶段,形成 curriculum learning 数据链。
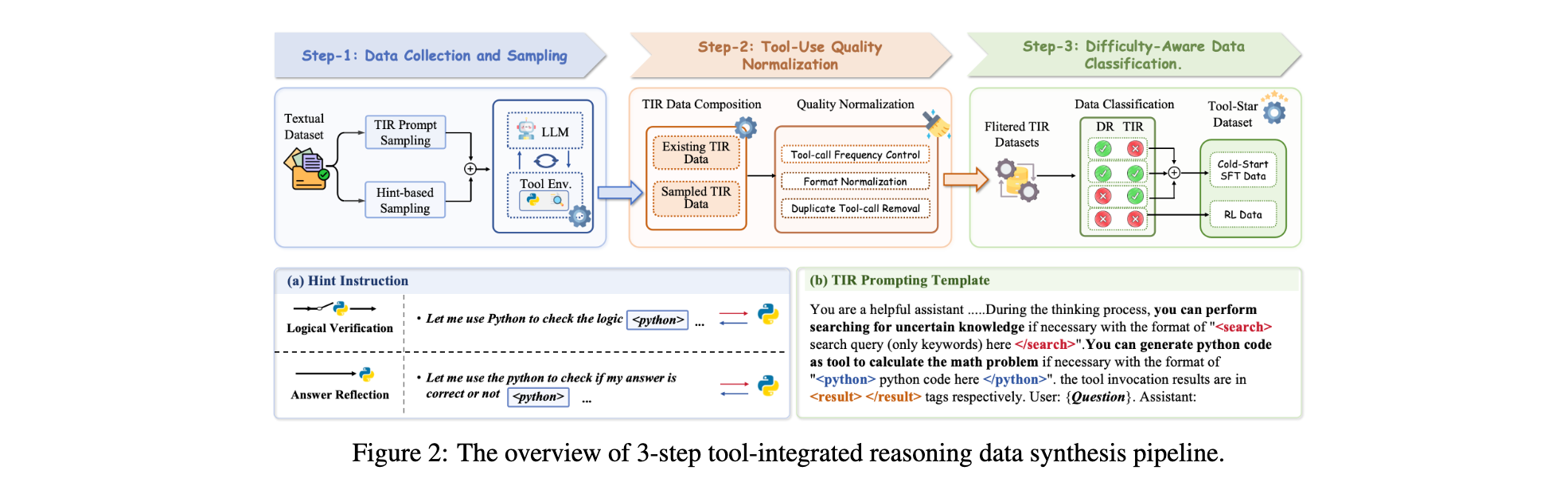
两阶段多工具协同训练框架
(1)冷启动监督微调(Cold-Start SFT)
目标:赋予模型基础工具调用能力,学习 “何时调用工具” 的基础策略。
数据:融合 DR 正确样本 D t e x t s u b D_{text}^{sub} Dtextsub与 TIR 优势样本 D t o o l s u b D_{tool}^{sub} Dtoolsub,共 54K 样本。
训练细节:使用 Qwen2.5-3B-Instruct 作为骨干模型,学习率 7e-6,批量大小 128,训练 3 轮,采用 DeepSpeed ZeRO-3 与 FlashAttention2 加速。
(2)多工具自批评强化学习(Multi-Tool Self-Critic RL)
该阶段通过 “vanilla RL 训练 + 自批评微调” 的迭代机制优化多工具策略:
- 步骤 1:基于 GRPO 的vanilla RL 训练
- 记忆化滚动机制:缓存工具调用请求与结果(如重复搜索相同 query 时直接读取缓存),减少 30% 冗余调用。
- 分层奖励设计:
- 基础奖励:答案正确性(Acc.)+ 格式合规性(Format);
- 协同奖励:当同时出现和调用时,额外奖励 r M = 0.1 r_M=0.1 rM=0.1。
- 算法实现:采用 Group Relative Policy Optimization(GRPO)算法,学习率 8e-5,每样本 8 次滚动,KL 散度系数设为 0 以稳定训练。
- 步骤 2:自批评奖励微调(Self-Critic Reward Finetuning)
- 奖励感知数据生成:从 RL 训练集随机采样 D t o o l S D_{tool}^{S} DtoolS,通过模型自采样生成 N 个候选响应,用分层奖励函数自动标注奖励分数(r≥1 为正例,r<1 为负例),构建偏好数据集 D t o o l c r i t i c D_{tool}^{critic} Dtoolcritic。
- DPO 目标优化:通过 Direct Preference Optimization(DPO)损失函数,让模型学习 “高奖励响应” 的生成模式。
- 迭代机制:每 50 步 RL 训练后插入自批评微调,通过 “策略优化 - 奖励理解” 的双向迭代,提升模型对多工具协同策略的掌握。
工具矩阵设计与推理优化
(1)训练阶段工具(3 核心工具)
- 搜索引擎:支持本地 / 网页搜索(如 Bing API),获取知识型信息;
- 网页浏览器代理:解析 URL 内容,提取关键信息并摘要;
- 代码解释器:在沙盒环境执行 Python 代码,返回计算结果或错误信息。
(2)推理阶段工具(3 优化工具)
- 代码调试器:基于编译错误自动修正 LLM 生成的代码(如语法错误修复);
- 工具回溯器:定位失败调用前的推理步骤,支持推理链回滚重生成;
- 推理链精炼器:压缩超长推理链,剔除冗余步骤(如重复计算)。
实验验证体系
(1)数据集与基线
- 计算推理:AIME24/25、MATH500、GSM8K 等,侧重数学问题求解;
- 知识推理:WebWalker、HotpotQA、2WikiMultihopQA 等,侧重信息检索与整合。
- 对比基线:
- 单工具方法:ToRL(代码辅助)、Search-o1(搜索辅助);
- 多工具方法:Multi-Tool Prompting;
- 主流模型:Qwen2.5-3B、Llama3.2-3B。
(2)评估指标
- 推理准确性:计算任务用 LLM 评判(Qwen2.5-72B-Instruct),知识任务用 F1 分数;
- 工具效率:Tool-use Efficiency T E T_E TE= 正确回答数 / 总样本数,衡量工具调用有效性。
实验洞察
性能优势
计算推理:在 MATH500 上准确率 72.0%,较 ToRL 提升 1.4%;AIME24 准确率 20.0%,超越 Search-o1(16.7%)。
知识推理:WebWalker 任务 F1 值 20.8%,HotpotQA 达 51.9%,分别领先基线 31.2% 和 27.6%。
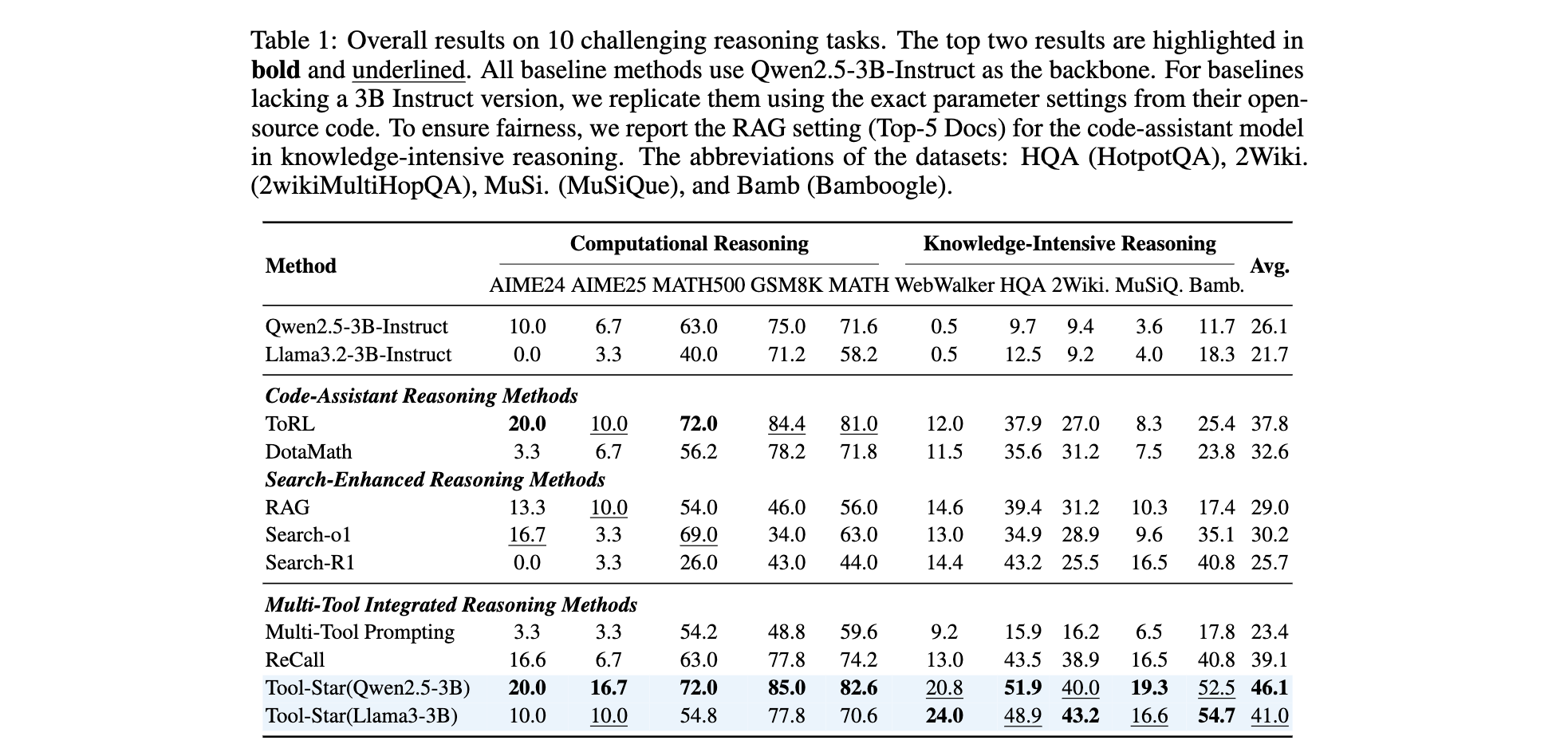
效率突破
工具使用效率( T E T_E TE)达 0.35,在 GSM8K 任务中每正确回答仅需 2.7 次工具调用,较 ToRL 减少 1.3 次。
推理时间优化:通过内存缓存重复工具请求,响应速度提升 40%。
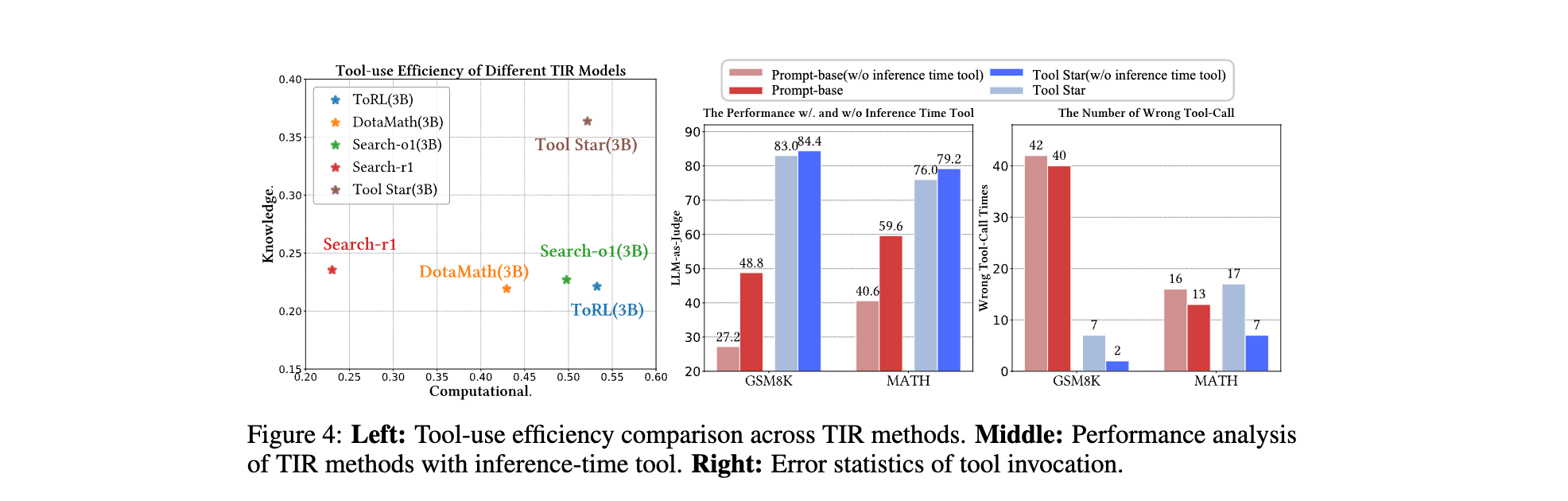
Quantitative Analysis
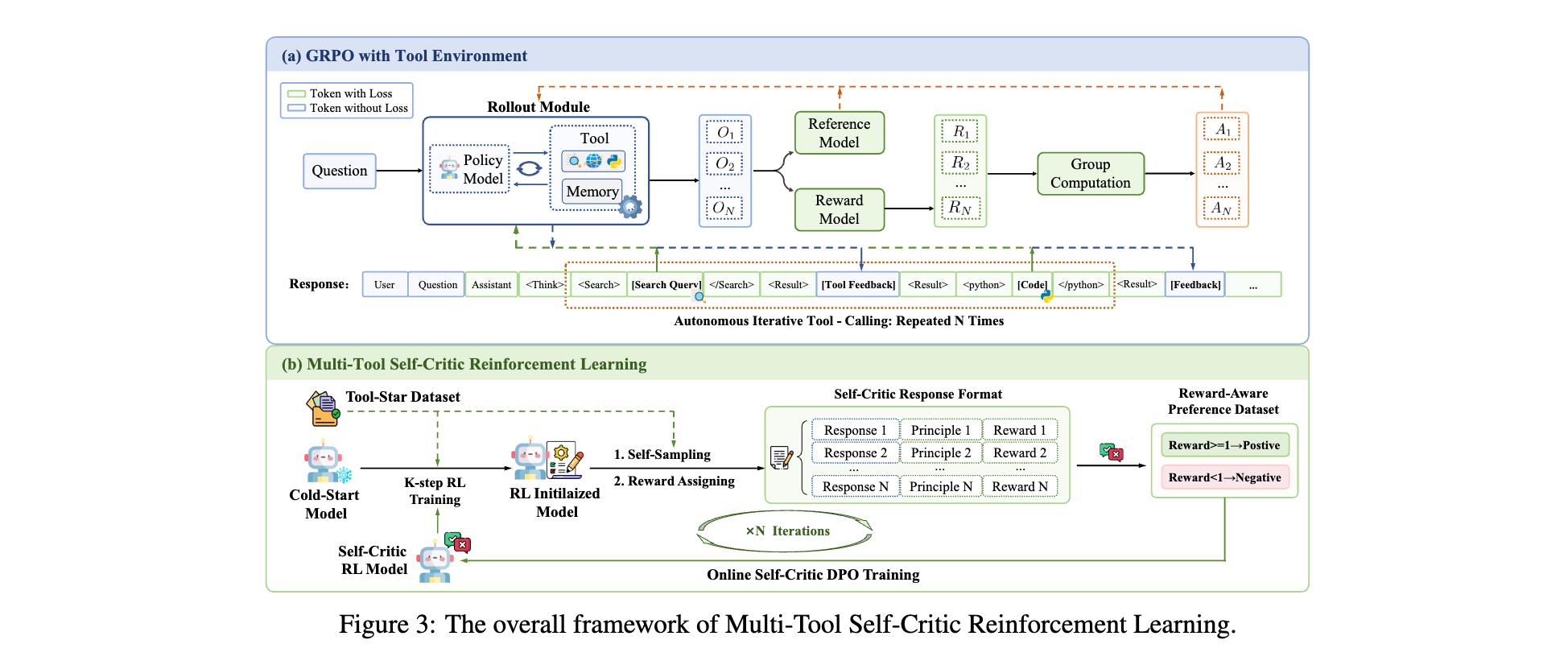
- 冷启动阶段缺失导致 HQA 任务准确率下降 8.4%,RL 阶段缺失使 MATH 准确率下降 4.2%,证明两阶段设计的必要性。
- 分层奖励缺失导致多工具协同率降低 15%,自批评估缺失使模型对奖励理解偏差增加 22%。
- 在搜索模式上,网页搜索在 2WikiMultihopQA 中 F1 值 40.0%,较本地搜索提升 48.1%,Bing API 在 MuSiQue 任务中 F1 值较本地 E5 检索提升 16.9%。
- 参数规模与训练上,0.5B 模型 RL 初期奖励达 0.8,3B 模型第 10 步奖励从 1.23 升至 1.40,响应长稳定在 800 tokens。