MIT 6.S081 Lab9 file system
文章目录
- large files
- 任务
- 提示
- 修改xv6
- Sysmbolic links
- 任务
- 提示
- 修改xv6
- 日志
large files
任务
In this assignment you’ll increase the maximum size of an xv6 file. Currently xv6 files are limited to 268 blocks, or 268*BSIZE bytes (BSIZE is 1024 in xv6). This limit comes from the fact that an xv6 inode contains 12 “direct” block numbers and one “singly-indirect” block number, which refers to a block that holds up to 256 more block numbers, for a total of 12+256=268 blocks.
在本作业中,您将增加xv6文件的最大大小。目前,xv6文件限制为268个块,或268*BSIZE字节(xv6中的BSIZE为1024)。这个限制来自这样一个事实,即xv6索引节点包含12个“直接”块号和一个“单间接”块号,即一个最多可容纳256个块号的块,总共12+256=268个块。
The mkfs program creates the xv6 file system disk image and determines how many total blocks the file system has; this size is controlled by FSSIZE in kernel/param.h. You’ll see that FSSIZE in the repository for this lab is set to 200,000 blocks. You should see the following output from mkfs/mkfs in the make output:
nmeta 70 (boot, super, log blocks 30 inode blocks 13, bitmap blocks 25) blocks 199930 total 200000
This line describes the file system that mkfs/mkfs built: it has 70 meta-data blocks (blocks used to describe the file system) and 199,930 data blocks, totaling 200,000 blocks.
If at any point during the lab you find yourself having to rebuild the file system from scratch, you can run make clean which forces make to rebuild fs.img.
mkfs程序创建xv6文件系统磁盘映像,并确定文件系统总共有多少块;该大小由kernel/param.h中的FSSIZE控制。您将看到该实验室存储库中的FSSIZE设置为200000个块。您应该在make输出中看到mkfs/mkfs的以下输出:
nmeta 70(引导、超级、日志块30索引节点块13、位图块25)块199930总共200000
此行描述了mkfs/mkfs构建的文件系统:它有70个元数据块(用于描述文件系统的块)和199930个数据块,总共200000个块。
如果在实验的任何时候,你发现自己必须从头开始重建文件系统,你可以运行make clean命令,强制make重建fs.img。
The format of an on-disk inode is defined by struct dinode in fs.h. You’re particularly interested in NDIRECT, NINDIRECT, MAXFILE, and the addrs[] element of struct dinode. Look at Figure 8.3 in the xv6 text for a diagram of the standard xv6 inode.
The code that finds a file’s data on disk is in bmap() in fs.c. Have a look at it and make sure you understand what it’s doing. bmap() is called both when reading and writing a file. When writing, bmap() allocates new blocks as needed to hold file content, as well as allocating an indirect block if needed to hold block addresses.
bmap() deals with two kinds of block numbers. The bn argument is a “logical block number” – a block number within the file, relative to the start of the file. The block numbers in ip->addrs[], and the argument to bread(), are disk block numbers. You can view bmap() as mapping a file’s logical block numbers into disk block numbers.
磁盘上inode的格式由fs.h中的结构dinode定义。你应该特别注意NDIRECT、NINDIRECT和MAXFILE以及结构dinode的addrs[]。请参阅xv6文本中的图8.3,了解标准xv6索引节点的示意图。
在磁盘上查找文件数据的代码位于fs.c中的bmap()中。请查看它,确保您了解它的功能。bmap()在读取和写入文件时都会被调用。写入时,bmap()会根据需要分配新块来保存文件内容,并在需要时分配间接块来保存块地址。
bmap()处理两种块编号。bn参数是一个“逻辑块号”,即文件中相对于文件开头的块号。ip->addrs[]中的块号和bread()的参数是磁盘块号。您可以将bmap()视为将文件的逻辑块号映射到磁盘块号。
Modify bmap() so that it implements a doubly-indirect block, in addition to direct blocks and a singly-indirect block. You’ll have to have only 11 direct blocks, rather than 12, to make room for your new doubly-indirect block; you’re not allowed to change the size of an on-disk inode. The first 11 elements of ip->addrs[] should be direct blocks; the 12th should be a singly-indirect block (just like the current one); the 13th should be your new doubly-indirect block. You are done with this exercise when bigfile writes 65803 blocks and usertests runs successfully:
修改bmap(),使其除了直接块和单间接块外,还实现了双间接块。你只需要11个直接块,而不是12个,就可以为你的新双间接块腾出空间;不允许更改磁盘上inode的大小。ip->addrs[]的前11个元素应该是直接块;第12个应该是一个单独的间接块(就像当前的块一样);13号应该是你的新双间接街区。当bigfile写入65803个块并且用户测试成功运行时,你就完成了此练习。
提示
- 确保你理解bmap()。写出ip->addrs[]、间接块、双间接块和它所指向的单间接块以及数据块之间的关系图。确保你理解为什么添加双间接块会使最大文件大小增加256*256个块(实际上是-1,因为你必须将直接块的数量减少一个)。
- 考虑一下如何用逻辑块号对双间接块及其指向的间接块进行索引。
- 如果更改NDIRECT的定义,则可能必须更改file.h中struct inode中addrs[]的声明。请确保struct inode和struct dinode在其addrs[]数组中具有相同数量的元素。
- 如果更改NDIRECT的定义,请确保创建一个新的fs.img,因为mkfs使用NDIRECT构建文件系统。
- 如果您的文件系统进入不良状态,可能是崩溃,请删除fs.img(从Unix中执行此操作,而不是xv6)。make将为您构建一个新的干净文件系统映像。
- 别忘了对每个
bread()的块进行brelease()。 - 您应该只根据需要分配间接块和双间接块,就像原始的
bmap()一样。 - 确保
itrunc释放文件的所有块,包括双间接块。
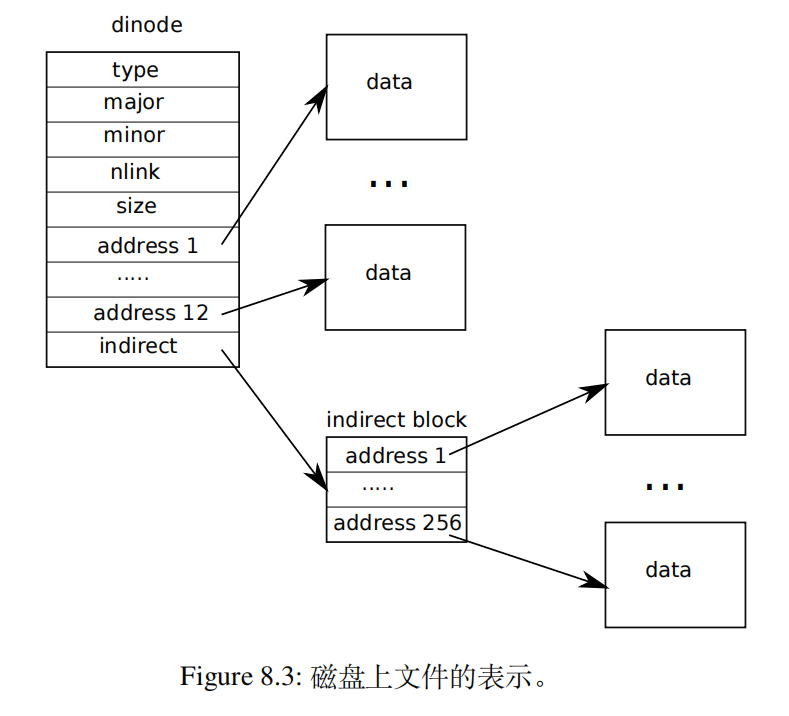
根据示意图,这里一个dinode一共有13个block,其中12个直接块,一个间接块,这里一个block的大小BSIZE是1024Bytes。前12KB(NDIRECT*BSIZE)大小的数据可以直接从inode中列出的块直接加载,而下一个256KB(NINDIRECT*BSIZE)字节只能从间接块中加载,这里需要设计二级间接块以满足实验要求。
- bmap根据需要分配块,ip->addrs[]或间接条目为0表示为分配任何块,如果bmap遇到0应该利用balloc分配新的块替换
- itrunc释放文件的块,并将索引节点的大小重置为0,首先释放直接块,然后释放间接块。
修改xv6
- 修改NDIRECT 宏定义,和inode结构体中的addrs
// kenerl/fs.h
// #define NDIRECT 12
#define NDIRECT 11
#define NINDIRECT (BSIZE / sizeof(uint))
// #define MAXFILE (NDIRECT + NINDIRECT)
#define MAXFILE (NDIRECT + NINDIRECT + NINDIRECT*NINDIRECT)
// On-disk inode structure
struct dinode {short type; // File typeshort major; // Major device number (T_DEVICE only)short minor; // Minor device number (T_DEVICE only)short nlink; // Number of links to inode in file systemuint size; // Size of file (bytes)uint addrs[NDIRECT+1+1]; // Data block addresses
};// kernel/file.h
// in-memory copy of an inode
struct inode {uint dev; // Device numberuint inum; // Inode numberint ref; // Reference countstruct sleeplock lock; // protects everything below hereint valid; // inode has been read from disk?short type; // copy of disk inodeshort major;short minor;short nlink;uint size;uint addrs[NDIRECT+1+1];
};
- 修改
bmap()函数
// kernel/fs.c
static uint
bmap(struct inode *ip, uint bn)
{uint addr, *a;struct buf *bp;if(bn < NDIRECT){if((addr = ip->addrs[bn]) == 0)ip->addrs[bn] = addr = balloc(ip->dev);return addr;}bn -= NDIRECT;if(bn < NINDIRECT){ // single indirect// Load indirect block, allocating if necessary.if((addr = ip->addrs[NDIRECT]) == 0)ip->addrs[NDIRECT] = addr = balloc(ip->dev);bp = bread(ip->dev, addr);a = (uint*)bp->data;if((addr = a[bn]) == 0){a[bn] = addr = balloc(ip->dev);log_write(bp);}brelse(bp);return addr;}bn -= NINDIRECT;if(bn < NINDIRECT*NINDIRECT){ // double indirect blockif ((addr = ip->addrs[NDIRECT + 1]) == 0){ip->addrs[NDIRECT + 1] = addr = balloc(ip->dev);}bp = bread(ip->dev, addr);a = (uint*)bp->data;if((addr = a[bn/NINDIRECT]) == 0){a[bn/NINDIRECT] = addr = balloc(ip->dev);log_write(bp);}brelse(bp);bn %= NINDIRECT;bp = bread(ip->dev, addr);a = (uint*)bp->data;if((addr = a[bn]) == 0){a[bn] = addr = balloc(ip->dev);log_write(bp);}brelse(bp);return addr;}panic("bmap: out of range");
}
- 修改
itrunc()函数
void
itrunc(struct inode *ip)
{int i, j;struct buf *bp;uint *a;for(i = 0; i < NDIRECT; i++){if(ip->addrs[i]){bfree(ip->dev, ip->addrs[i]);ip->addrs[i] = 0;}}if(ip->addrs[NDIRECT]){bp = bread(ip->dev, ip->addrs[NDIRECT]);a = (uint*)bp->data;for(j = 0; j < NINDIRECT; j++){if(a[j])bfree(ip->dev, a[j]);}brelse(bp);bfree(ip->dev, ip->addrs[NDIRECT]);ip->addrs[NDIRECT] = 0;}if(ip->addrs[NDIRECT + 1]){bp = bread(ip->dev, ip->addrs[NDIRECT + 1]);a = (uint*)bp->data;for(j = 0; j < NINDIRECT; j++){if(a[j]){struct buf *bp2 = bread(ip->dev, a[j]);uint *a2 = (uint*)bp2->data;for(i = 0; i < NINDIRECT; i++){if(a2[i])bfree(ip->dev, a2[i]);}brelse(bp2);bfree(ip->dev, a[j]);}}brelse(bp);bfree(ip->dev, ip->addrs[NDIRECT + 1]);ip->addrs[NDIRECT + 1] = 0;}ip->size = 0;iupdate(ip);
}
Sysmbolic links
任务
In this exercise you will add symbolic links to xv6. Symbolic links (or soft links) refer to a linked file by pathname; when a symbolic link is opened, the kernel follows the link to the referred file. Symbolic links resembles hard links, but hard links are restricted to pointing to file on the same disk, while symbolic links can cross disk devices. Although xv6 doesn’t support multiple devices, implementing this system call is a good exercise to understand how pathname lookup works.
在本练习中,您将向xv6添加符号链接。符号链接(或软链接)是指按路径名链接的文件;当打开符号链接时,内核会按照链接指向引用的文件。符号链接类似于硬链接,但硬链接仅限于指向同一磁盘上的文件,而符号链接可以跨磁盘设备。虽然xv6不支持多个设备,但实现此系统调用是理解路径名查找工作原理的一个很好的练习。
You will implement the symlink(char *target, char *path) system call, which creates a new symbolic link at path that refers to file named by target. For further information, see the man page symlink. To test, add symlinktest to the Makefile and run it. Your solution is complete when the tests produce the following output (including usertests succeeding).
您将实现symlink(char\*target,char\*path)系统调用,该调用在引用目标命名的文件的路径处创建一个新的符号链接。有关更多信息,请参阅手册页符号链接。要进行测试,请将symlinkstest添加到Makefile中并运行它。当测试产生以下输出时(包括用户测试成功),您的解决方案就完成了。
提示
- 首先,为symlink创建一个新的系统调用号,在user/usys.pl、user/user.h中添加一个条目,并在kernel/sysfile.c中实现一个空的sys_symlink。
- 在kernel/stat.h中添加一个新的文件类型(T_SYMLINK)来表示符号链接。
- 在kernel/fcntl.h中添加一个新标志(O_NOFOLLOW),该标志可用于开放系统调用。请注意,传递给open的标志是使用位OR运算符组合的,因此您的新标志不应与任何现有标志重叠。这将允许您在将user/symlinktest.c添加到Makefile后对其进行编译。
- 实现symlink(target,path)系统调用,在引用目标的路径处创建一个新的符号链接。请注意,系统调用成功不需要目标存在。您需要选择一个位置来存储符号链接的目标路径,例如,在索引节点的数据块中。符号链接应该返回一个表示成功(0)或失败(-1)的整数,类似于链接和取消链接。
- 修改开放系统调用以处理路径引用符号链接的情况。如果文件不存在,打开必须失败。当一个进程在要打开的标志中指定O_NOFOLLOW时,open应该打开符号链接(而不是遵循符号链接)。
- 如果链接文件也是符号链接,则必须递归地跟随它,直到到达非链接文件。如果链接形成循环,则必须返回错误代码。如果链接深度达到某个阈值(例如10),您可以通过返回错误代码来近似计算。
- 其他系统调用(例如,链接和取消链接)不得遵循符号链接;这些系统调用对符号链接本身进行操作。
- 您不必处理指向此实验目录的符号链接。
修改xv6
- 添加系统调用symlink,符号连接和普通文件一样需要占用inode块。
// user/usys.pl
entry("symlink");
// user/user.h
uint symlink(const char*, const char*);
// kernel/syscall.h
#define SYS_symlink 22;
// kernel/syscall.c
extern uint64 sys_symlink(void);
static uint64 (*syscalls[])(void) = {
// ..
[SYS_symlink] sys_symlink,
};
// kernel/stat.h
#define T_SYMLINK 4 // Symbolic link
// kernel/sysfile.c
uint64
sys_symlink(void)
{struct inode *ip;char target[MAXPATH], path[MAXPATH];if(argstr(0, target, MAXPATH) < 0 || argstr(1, path, MAXPATH) < 0)return -1;begin_op();ip = create(path, T_SYMLINK, 0, 0);if(ip == 0){end_op();return -1;}// use the first data block to store target path.if(writei(ip, 0, (uint64)target, 0, strlen(target)) < 0) {end_op();return -1;}iunlockput(ip);end_op();return 0;
}
- 修改sys_open系统调用
// kernel/fcntl.h
#define O_NOFOLLOW 0x800
// kernel/sysfile.c
uint64
sys_open(void)
{char path[MAXPATH];int fd, omode;struct file *f;struct inode *ip;int n;if((n = argstr(0, path, MAXPATH)) < 0 || argint(1, &omode) < 0)return -1;begin_op();if(omode & O_CREATE){ip = create(path, T_FILE, 0, 0);if(ip == 0){end_op();return -1;}} else {// if((ip = namei(path)) == 0){// end_op();// return -1;// }// ilock(ip);int symlink_depth = 0;while(1) { // recursively follow symlinksif((ip = namei(path)) == 0){end_op();return -1;}ilock(ip);if(ip->type == T_SYMLINK && (omode & O_NOFOLLOW) == 0) {if(++symlink_depth > 10) {// aovid loopiunlockput(ip);end_op();return -1;}if(readi(ip, 0, (uint64)path, 0, MAXPATH) < 0) {iunlockput(ip);end_op();return -1;}iunlockput(ip);} else {break;}}if(ip->type == T_DIR && omode != O_RDONLY){iunlockput(ip);end_op();return -1;}}if(ip->type == T_DEVICE && (ip->major < 0 || ip->major >= NDEV)){iunlockput(ip);end_op();return -1;}if((f = filealloc()) == 0 || (fd = fdalloc(f)) < 0){if(f)fileclose(f);iunlockput(ip);end_op();return -1;}if(ip->type == T_DEVICE){f->type = FD_DEVICE;f->major = ip->major;} else {f->type = FD_INODE;f->off = 0;}f->ip = ip;f->readable = !(omode & O_WRONLY);f->writable = (omode & O_WRONLY) || (omode & O_RDWR);if((omode & O_TRUNC) && ip->type == T_FILE){itrunc(ip);}iunlock(ip);end_op();return fd;
}
日志
参考Xv6-book中8.4-8.6节
