python打卡day36
复习日
仔细回顾一下神经网络到目前的内容,没跟上进度的补一下进度
- 作业:对之前的信贷项目,利用神经网络训练下,尝试用到目前的知识点让代码更加规范和美观。
- 探索性作业(随意完成):尝试进入nn.Module中,查看他的方法
数据预处理
import pandas as pd #用于数据处理和分析,可处理表格数据。
import numpy as np #用于数值计算,提供了高效的数组操作。
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import warnings
warnings.filterwarnings("ignore")data = pd.read_csv('data.csv') #读取数据# 先筛选字符串变量
discrete_features = data.select_dtypes(include=['object']).columns.tolist()
# Home Ownership 标签编码
home_ownership_mapping = {'Own Home': 1,'Rent': 2,'Have Mortgage': 3,'Home Mortgage': 4
}
data['Home Ownership'] = data['Home Ownership'].map(home_ownership_mapping)# Years in current job 标签编码
years_in_job_mapping = {'< 1 year': 1,'1 year': 2,'2 years': 3,'3 years': 4,'4 years': 5,'5 years': 6,'6 years': 7,'7 years': 8,'8 years': 9,'9 years': 10,'10+ years': 11
}
data['Years in current job'] = data['Years in current job'].map(years_in_job_mapping)# Purpose 独热编码,记得需要将bool类型转换为数值
data = pd.get_dummies(data, columns=['Purpose'])
data2 = pd.read_csv("data.csv") # 重新读取数据,用来做列名对比
list_final = [] # 新建一个空列表,用于存放独热编码后新增的特征名
for i in data.columns:if i not in data2.columns:list_final.append(i) # 这里打印出来的就是独热编码后的特征名
for i in list_final:data[i] = data[i].astype(int) # 这里的i就是独热编码后的特征名# Term 0 - 1 映射
term_mapping = {'Short Term': 0,'Long Term': 1
}
data['Term'] = data['Term'].map(term_mapping)
data.rename(columns={'Term': 'Long Term'}, inplace=True) # 重命名列
continuous_features = data.select_dtypes(include=['int64', 'float64']).columns.tolist() #把筛选出来的列名转换成列表# 连续特征用中位数补全
for feature in continuous_features: mode_value = data[feature].mode()[0] #获取该列的众数。data[feature].fillna(mode_value, inplace=True) #用众数填充该列的缺失值,inplace=True表示直接在原数据上修改。X = data.drop(['Credit Default'], axis=1) # 特征,axis=1表示按列删除
y = data['Credit Default'] # 标签# 按照8:2划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 80%训练集,20%测试集# 归一化
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)数据转换为张量,反正是二分类,输出0-1的浮点数问题也不大,主要是后面BCEWithLogitsLoss要求预测值和标签数据类型必须一致,这里就全整成tensorFloat32省事了
import torch
import torch.nn as nn
import torch.optim as optim# 将数据转换为PyTorch张量
X_train = torch.FloatTensor(X_train)
y_train = torch.FloatTensor(y_train.to_numpy())
X_test = torch.FloatTensor(X_test)
y_test = torch.FloatTensor(y_test.to_numpy())网络定义及训练
class CreditRiskModel(nn.Module):def __init__(self, input_dim):super().__init__()# 输入层 → 隐藏层1self.fc1 = nn.Linear(input_dim, 32)self.relu1 = nn.ReLU()self.drop = nn.Dropout(0.2) # 随机丢弃20%神经元,防止过拟合# 隐藏层2self.fc2 = nn.Linear(32, 16)self.relu2 = nn.ReLU()# 输出层self.fc3 = nn.Linear(16, 1)def forward(self, x):out = self.fc1(x)out = self.relu1(out)out = self.drop(out)out = self.fc2(out)out = self.relu2(out)out = self.fc3(out)return out model = CreditRiskModel(input_dim=len(data.columns) - 1) # 特征数就是输入维度# 损失函数用BCEWithLogitsLoss,内置Sigmoid和数值稳定
criterion = nn.BCEWithLogitsLoss()
# Adam优化器
optimizer = optim.Adam(model.parameters(), lr=0.01)num_epochs = 400 # 训练的轮数# 用于存储每个 epoch 的损失值,用于后续绘制训练曲线
losses = []for epoch in range(num_epochs): # range是从0开始,所以epoch是从0开始# 前向传播outputs = model(X_train).squeeze() # 从 [6000, 1] → [6000],保证和标签的维度一致loss = criterion(outputs, y_train) # output是模型预测值,y_train是真实标签# 反向传播和优化optimizer.zero_grad() #梯度清零,因为PyTorch会累积梯度,所以每次迭代需要清零,梯度累计是那种小的bitchsize模拟大的bitchsizeloss.backward() # 反向传播计算梯度optimizer.step() # 更新参数# 记录损失值losses.append(loss.item()) # loss.item() 将单值张量转为 Python 的 float 或 int,才能添加到列表里面# 打印训练信息if (epoch + 1) % 20 == 0: # range是从0开始,所以epoch+1是从当前epoch开始,每20个epoch打印一次print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')loss可视化
import matplotlib.pyplot as plt
# 可视化损失曲线
plt.plot(range(num_epochs), losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss over Epochs')
plt.show()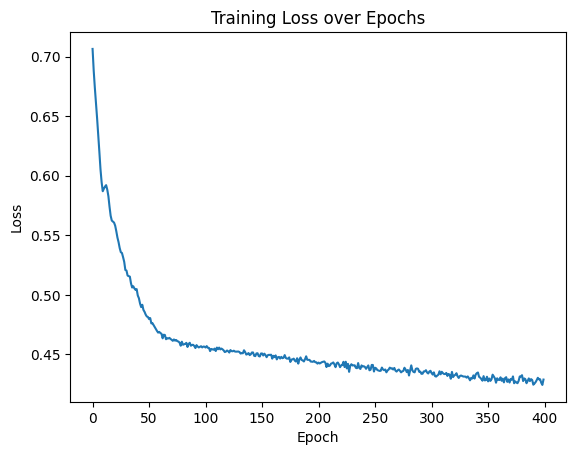
曲线有点小毛刺,但总归还是收敛了的
推理
# 评估模型
model.eval() # 设置模型为评估模式
with torch.no_grad(): # torch.no_grad()的作用是禁用梯度计算,可以提高模型推理速度outputs = model(X_test) # 对测试数据进行前向传播,获得预测结果_, predicted = torch.max(outputs, 1) # torch.max(outputs, 1)返回每行的最大值和对应的索引correct = (predicted == y_test).sum().item() # 计算预测正确的样本数accuracy = correct / y_test.size(0)print(f'测试集准确率: {accuracy * 100:.2f}%')# ----------------------------------------------
测试集准确率: 70.60%准确率不太高,可能训练的epoch还是少了点
收获心得:
1、终于搞懂数据转换成张量的时候要不要加上to_numpy()了,先看看数据类型,DataFrame或者Series就转换不过去,先搞成数组或者列表(很幽默啊,划分数据集后特征和标签的数据类型居然不一样)
print(type(X_train))
print(type(X_test))
print(type(y_train))
print(type(y_test))# ---------------------------------------
<class 'numpy.ndarray'>
<class 'numpy.ndarray'>
<class 'pandas.core.series.Series'>
<class 'pandas.core.series.Series'>2、构造神经网络的时候,输入层的输入维度没注意太多,因为处理前数据有16个特征,所以设置的16,一直报错,然后想起来独热编码之后导致了特征膨胀,变成了31个特征。这里的处理是将输入层的维度就设置成了31,但如果是大型数据集,特征更多了之后这样显然不太合适,还没想到处理办法
@浙大疏锦行