【从0到1搞懂大模型】chatGPT 中的对齐优化(RLHF)讲解与实战(9)
GPT系列模型的演进
chatgpt系列模型演进的重要节点包含下面几个模型(当然,这两年模型发展太快了,4o这些推理模型我就先不写了)
(Transformer) → GPT-1 → GPT-2 → GPT-3 → InstructGPT/ChatGPT(GPT-3.5) → GPT-4
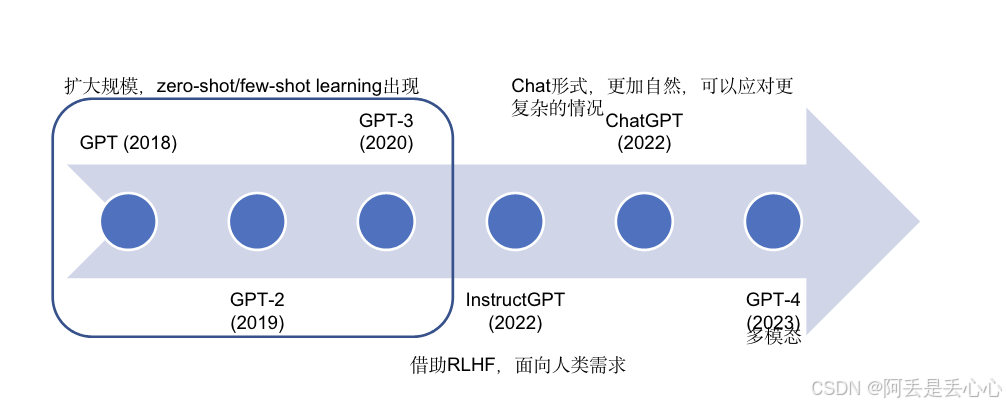
下面介绍一下各个模型之前的重点差异
(1)Transformer(2017)
- 定位:NLP基础架构革命,奠定GPT系列技术底座
- 核心创新:
- 多头自注意力机制:替代RNN/CNN,解决长距离依赖问题
- 位置编码:通过正弦函数或可学习向量表征序列位置
- 并行计算架构:突破序列处理的效率瓶颈
- 局限:未形成完整生成模型,需配合任务微调
(2)GPT-1(2018)
- 技术定位:首个基于Transformer的生成式预训练模型
- 核心改进:
- 单向掩码机制:仅允许左向注意力,实现自回归文本生成
- 两阶段训练:无监督预训练(BooksCorpus)+ 下游任务微调
- 参数规模:1.17亿
- 应用场景:文本续写、简单问答
(3)GPT-2(2019)
- 技术跃迁:验证"规模扩展+零样本学习"可行性
- 核心改进:
- 参数爆炸:15亿参数,较GPT-1增长12.8倍
- 零样本迁移:无需微调即可完成翻译、摘要等任务
- WebText数据集:800万网页数据提升多样性
- 局限:生成文本存在重复和不连贯现象
(4)GPT-3(2020)
- 技术突破:定义"大模型即服务"范式
- 核心创新:
- 超大规模参数:1750亿参数,开启千亿级模型时代
- 上下文学习:通过Prompt工程实现少样本/单样本学习
- 混合训练数据:融合Common Crawl、书籍、维基百科等
- 局限:存在事实性错误和伦理风险
(5)InstructGPT/ChatGPT(GPT-3.5, 2022)
- 技术定位:首个实现人类对齐的对话模型
- 核心改进:
- 三阶段对齐流程:SFT → RM → PPO
- RLHF技术:通过人类反馈强化学习优化输出安全性
- 指令微调:使用人工标注指令-答案对提升任务理解
- 参数规模:保持1750亿参数,但训练数据量扩展
(6)GPT-4(2023)
- 技术革命:多模态+超智能体架构
- 核心创新:
- 多模态处理:支持图像输入与文本生成联动
- 混合专家模型:推测采用MoE架构,参数达1.8万亿
- 动态推理优化:思维链(CoT)增强复杂问题解决能力
- 安全增强:毒性输出较GPT-3.5降低50%以上
- 工程突破:32K上下文窗口支持长文档处理
可以见的,从 GPT1 到 GPT3,最主要的技术进步就是参数量和预训练数据的扩大,这也验证可 Scale Law(规模法则)即模型性能随模型规模的增长而提高
而从 GPT3 到可以直接对话的 chatgpt,对齐优化则是最重要的突破,RLHF作为对齐阶段的里程碑技术,通过三阶段流程(SFT→RM→PPO)将模型输出与人类偏好深度绑定,标志着语言模型从“通用生成”到“可控服务”的范式转变。
下面 图片就演示了 RLHF,而本篇文章重点讲解一下 RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)
RLHF讲解与实战
整体流程介绍
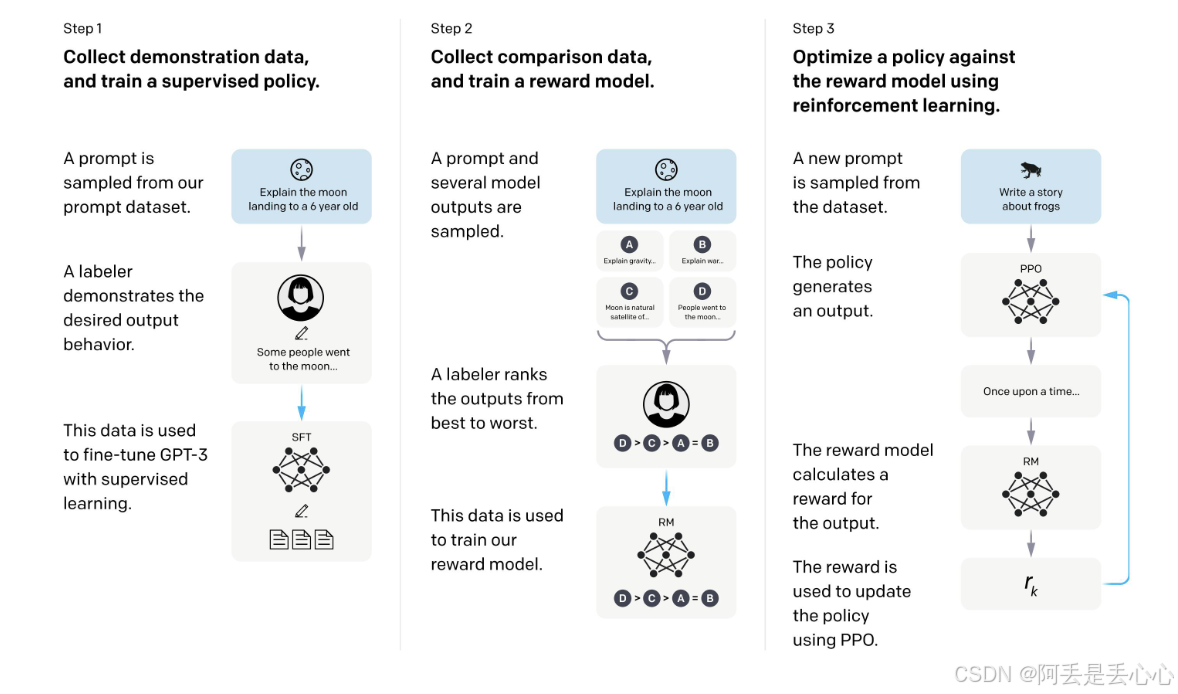
ChatGPT是怎么变聪明的?
想象一下,ChatGPT一开始就像个刚学说话的小孩,虽然懂一些知识,但回答得不太好。科学家们为了让它的回答更符合人类喜好,用了三步训练法,让它像打游戏升级一样,越练越强!
- 第1步:先教它“标准答案”(监督学习)
方法:从网上找一大堆问题和答案(比如“怎么煮咖啡?”),让ChatGPT学习正确的回答方式。
结果:它学会了基本的对话能力,但还不够聪明,回答可能很死板或者不讨喜。这时候的版本叫“弱弱的ChatGPT”。 - 第2步:教它“哪种回答更讨喜”(奖励模型)
方法:让“弱弱的ChatGPT”对同一个问题生成多个答案(比如回答“煮咖啡”时,有的详细,有的简短),然后请人类给这些答案打分(哪个更好?哪个更差?)。
训练奖励模型:用这些打分数据训练一个“评分AI”,让它学会人类的喜好,以后能自动给ChatGPT的回答打分。 - 第3步:让它“自己和自己比赛”(强化学习)
方法:让“弱弱的ChatGPT”继续回答问题,但这次用“评分AI”给它打分,然后告诉它:“这个回答得分高,下次多这样答;那个回答得分低,下次别这样了。”
升级版ChatGPT:经过反复调整,它的回答越来越符合人类喜好,变得更自然、更聪明。 - 循环升级:越练越强!
升级后的ChatGPT可以重新训练“评分AI”(因为它的回答更好了)。
更好的“评分AI”又能帮ChatGPT进一步优化回答……
这样循环训练,就像武侠小说里的高手左右手互搏,越练越厉害,最终成为惊艳世界的ChatGPT!
强化学习基础知识
强化学习(Reinforcement Learning, RL) 是一种通过试错学习实现目标的人工智能范式。其核心是智能体(Agent)在与环境(Environment)的交互中,通过最大化累积奖励(Reward)来学习最优策略(Policy)。
- 关键要素:
- 智能体(Agent):决策主体(如机器人、游戏角色)。
- 环境(Environment):智能体交互的物理或虚拟世界。
- 状态(State):环境的当前描述(如迷宫中的位置)。
- 动作(Action):智能体可执行的操作(如移动方向)。
- 奖励(Reward):环境对动作的即时反馈(如到达终点+100分,撞墙-10分)。
- 策略(Policy):状态到动作的映射规则(如“遇到障碍物时左转”)。
- 与其他机器学习的区别:
- 监督学习:依赖标注数据(输入-答案对),优化目标是预测误差最小化。
- 强化学习:无需标注数据,通过试错优化长期累积奖励,注重延迟反馈(如围棋中某一步可能在几十步后才决定胜负)
在训练ChatGPT时,OpenAI让一组人类评估者来评价模型的回答。这些评估者拿到了一组指导方针,告诉他们什么样的回答应该被高度评价,什么样的回答应该被低度评价。在评估者评价的过程中,通过不断的试错和学习,机器人试图找到一种策略,使得在与用户交谈过程中获取的总奖励最大。这就是通过基于人类反馈的强化学习调优ChatGPT的基本思想。
PPO讲解
PPO 是一种强化学习算法,专门用于让AI模型(比如ChatGPT)通过试错和反馈优化自己的策略(即参数)。它的核心思想是:
“小步调整参数,避免一次更新太大导致模型崩溃”(就像健身时循序渐进,而不是突然举100kg受伤)。
PPO的输入
- 输入:
当前模型(策略):比如“弱弱的ChatGPT”,参数为θ。
奖励模型(RM):能给ChatGPT的回答打分(比如1~10分)。
- 输出:
优化后的新模型:参数θ’,生成的回答更符合人类偏好。
PPO分步骤讲解
-
步骤1:生成回答并打分
从Prompt库抽样一个问题(比如“怎么煮咖啡?”)。
让当前ChatGPT生成多个答案(比如答案A、B、C)。
奖励模型RM给这些答案打分(比如A=7分,B=3分,C=5分) -
步骤2:计算“优势”(Advantage)
关键问题:当前回答比“平均水平”好多少?
公式:优势A = 当前回答得分 - 平均预期得分
如果A=7,平均预期=5 → 优势=+2(鼓励这类回答)。
如果B=3,平均预期=5 → 优势=-2(抑制这类回答)。 -
步骤3:计算“策略比率”(Policy Ratio)
关键问题:新参数θ’生成的回答,和旧参数θ生成的回答概率相差多少?
公式:比率 = Pθ’(回答) / Pθ(回答)
如果比率≈1:新旧策略对回答的选择概率相似。
如果比率>1:新策略更倾向于生成该回答。
如果比率<1:新策略更抑制该回答。 -
步骤4:PPO的核心目标函数
PPO通过以下公式调整参数θ’,同时限制更新幅度(避免突变):
**目标函数 = min(比率×优势, clip(比率, 1-ε, 1+ε)×优势)**
clip函数:强制比率在[1-ε, 1+ε]范围内(比如ε=0.2 → 比率限制在0.8~1.2)。
如果比率=1.5(更新太大)→ 被clip到1.2,防止参数剧烈变化。
如果比率=0.9(安全范围)→ 保持不变。
- 步骤5:梯度下降更新参数
最大化目标函数 → 让高优势回答的概率增加,低优势回答的概率降低。
但通过clip限制步长,保证训练稳定。
PPO 的整体公式就是
L(θ) = E[ min(ratio * Advantage, clip(ratio, 1-ε, 1+ε) * Advantage) ] - β * Entropy
- ratio = Pθ_new(a|s) / Pθ_old(a|s)
- Entropy 是熵奖励,鼓励生成多样性回答。
这个本身是一个相对复杂的算法,建议看看网上更专业的讲解奥
推荐一下李宏毅老师的课程:http://speech.ee.ntu.edu.tw/~tlkagk/courses_MLDS18.html
ppo代码示例
import torch
import torch.nn as nn
import torch.optim as optim
from torch.distributions import Categorical
import numpy as np
# 设置随机种子
torch.manual_seed(42)
np.random.seed(42)class LanguageModel(nn.Module):def __init__(self, vocab_size, embedding_dim=128, hidden_dim=256):super().__init__()self.embedding = nn.Embedding(vocab_size, embedding_dim)self.lstm = nn.LSTM(embedding_dim, hidden_dim, batch_first=True)self.fc = nn.Linear(hidden_dim, vocab_size) # 输出每个词的概率def forward(self, x):# x: [batch_size, seq_len]x = self.embedding(x) # [batch_size, seq_len, embedding_dim]lstm_out, _ = self.lstm(x) # [batch_size, seq_len, hidden_dim]logits = self.fc(lstm_out) # [batch_size, seq_len, vocab_size]return logitsdef generate(self, prompt, max_len=20):"""生成文本(类似ChatGPT的推理过程)"""with torch.no_grad():tokens = promptfor _ in range(max_len):logits = self.forward(tokens) # [batch_size, seq_len, vocab_size]next_token_logits = logits[:, -1, :] # 取最后一个词的logitsprobs = torch.softmax(next_token_logits, dim=-1)next_token = torch.multinomial(probs, 1) # 按概率采样tokens = torch.cat([tokens, next_token], dim=1)return tokensclass RewardModel(nn.Module):def __init__(self, vocab_size, embedding_dim=128, hidden_dim=256):super().__init__()self.embedding = nn.Embedding(vocab_size, embedding_dim)self.lstm = nn.LSTM(embedding_dim, hidden_dim, batch_first=True)self.fc = nn.Linear(hidden_dim, 1) # 输出单个奖励值def forward(self, x):# x: [batch_size, seq_len]x = self.embedding(x) # [batch_size, seq_len, embedding_dim]lstm_out, _ = self.lstm(x) # [batch_size, seq_len, hidden_dim]# 使用最后一个时间步的隐藏状态来预测奖励rewards = self.fc(lstm_out[:, -1, :]) # [batch_size, 1]return rewards.squeeze(-1) # [batch_size]def ppo_train(actor_model, # 语言模型(策略网络)reward_model, # 奖励模型optimizer, # 优化器(如Adam)prompts, # 输入的prompt(问题)num_epochs=10, # PPO训练轮数clip_epsilon=0.2, # PPO的clip参数(通常0.1~0.3)gamma=0.99, # 折扣因子batch_size=32 # 每批数据量
):actor_model.train() # 切换到训练模式reward_model.eval() # 奖励模型设置为评估模式for epoch in range(num_epochs):# 1. 生成回答(采样)with torch.no_grad():responses = actor_model.generate(prompts) # [batch_size, seq_len]# 计算旧策略的概率old_logits = actor_model(responses) # [batch_size, seq_len, vocab_size]old_log_probs = torch.log_softmax(old_logits, dim=-1)old_log_probs = old_log_probs.gather(-1, responses.unsqueeze(-1)).squeeze(-1) # [batch_size, seq_len]old_log_probs = old_log_probs.mean(dim=1) # 平均每个token的log_prob# 2. 计算奖励(用奖励模型)with torch.no_grad():rewards = reward_model(responses) # [batch_size]# 3. 计算优势(Advantage)# 这里简化计算:Advantage ≈ 归一化的Rewardadvantages = (rewards - rewards.mean()) / (rewards.std() + 1e-8)# 4. 计算新策略的概率new_logits = actor_model(responses) # [batch_size, seq_len, vocab_size]new_log_probs = torch.log_softmax(new_logits, dim=-1)new_log_probs = new_log_probs.gather(-1, responses.unsqueeze(-1)).squeeze(-1) # [batch_size, seq_len]new_log_probs = new_log_probs.mean(dim=1) # 平均每个token的log_prob# 5. 计算策略比率(Policy Ratio)ratios = torch.exp(new_log_probs - old_log_probs) # e^{log(π_new/π_old)}# 6. PPO 目标函数(Clipped Surrogate Objective)surr1 = ratios * advantagessurr2 = torch.clamp(ratios, 1 - clip_epsilon, 1 + clip_epsilon) * advantagespolicy_loss = -torch.min(surr1, surr2).mean() # 取min防止更新过大# 7. 计算熵正则化(鼓励探索)entropy = Categorical(logits=new_logits).entropy().mean()entropy_bonus = 0.01 * entropy # 调节系数# 8. 总损失 = Policy Loss - 熵奖励loss = policy_loss - entropy_bonus# 9. 反向传播 & 优化optimizer.zero_grad()loss.backward()optimizer.step()print(f"Epoch {epoch+1}, Loss: {loss.item():.4f}, Avg Reward: {rewards.mean().item():.4f}")# 设置参数
vocab_size = 10000 # 词汇表大小
embedding_dim = 128
hidden_dim = 256# 创建模型
actor_model = LanguageModel(vocab_size, embedding_dim, hidden_dim)
reward_model = RewardModel(vocab_size, embedding_dim, hidden_dim)# 优化器
optimizer = optim.Adam(actor_model.parameters(), lr=1e-5)# 创建示例输入数据
batch_size = 32
seq_len = 5
prompts = torch.randint(0, vocab_size, (batch_size, seq_len))# 开始PPO训练
ppo_train(actor_model, reward_model, optimizer, prompts, num_epochs=10)
简单RLHF实战
下面实现了一个完整的RLHF系统,包含了完整的RLHF三阶段流程
- 预训练阶段:训练基础语言模型
- 奖励模型训练:基于人类偏好数据训练奖励模型
- PPO强化学习:使用PPO算法优化策略
学习思路即可 目前效果确实一般
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
import numpy as np
import random
from collections import deque
import json
import os
from typing import List, Dict, Tuple, Optional
import logging# 设置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
logger.info(f"使用设备: {device}")class SimpleTokenizer:"""简单的分词器"""def __init__(self, vocab_size=5000):self.vocab_size = vocab_sizeself.vocab = {"<pad>": 0, "<unk>": 1, "<start>": 2, "<end>": 3}self.reverse_vocab = {0: "<pad>", 1: "<unk>", 2: "<start>", 3: "<end>"}def build_vocab(self, texts):"""构建词汇表"""word_freq = {}for text in texts:words = text.lower().split()for word in words:word_freq[word] = word_freq.get(word, 0) + 1# 按频率排序,取前vocab_size-4个词sorted_words = sorted(word_freq.items(), key=lambda x: x[1], reverse=True)for i, (word, _) in enumerate(sorted_words[:self.vocab_size-4]):idx = i + 4self.vocab[word] = idxself.reverse_vocab[idx] = word# 确保测试词在词汇表中test_words = ["今天", "天气", "人工", "智能", "学习", "健康", "工作"]for word in test_words:if word not in self.vocab:idx = len(self.vocab)self.vocab[word] = idxself.reverse_vocab[idx] = wordlogger.info(f"构建词汇表完成,词汇量: {len(self.vocab)}")logger.info(f"测试词是否在词汇表中: {[word in self.vocab for word in test_words]}")def encode(self, text, max_length=128):"""编码文本"""words = text.lower().split()tokens = [self.vocab.get(word, 1) for word in words] # 1是<unk># 添加开始和结束标记tokens = [2] + tokens + [3] # 2是<start>, 3是<end># 填充或截断if len(tokens) < max_length:tokens += [0] * (max_length - len(tokens)) # 0是<pad>else:tokens = tokens[:max_length]tokens[-1] = 3 # 确保以<end>结尾return tokensdef decode(self, tokens):"""解码令牌"""words = []for token in tokens:if token in [0, 2]: # 跳过<pad>和<start>continueif token == 3: # <end>breakwords.append(self.reverse_vocab.get(token, "<unk>"))return " ".join(words)class SimpleTransformer(nn.Module):"""简化的Transformer模型"""def __init__(self, vocab_size, d_model=256, nhead=8, num_layers=4, max_length=128):super().__init__()self.d_model = d_modelself.vocab_size = vocab_sizeself.max_length = max_length# 嵌入层self.embedding = nn.Embedding(vocab_size, d_model)self.pos_encoding = nn.Parameter(torch.randn(max_length, d_model))# Transformer层encoder_layer = nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead, dim_feedforward=d_model*4,dropout=0.1, batch_first=True)self.transformer = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)# 输出头self.lm_head = nn.Linear(d_model, vocab_size)# 初始化权重self._init_weights()def _init_weights(self):"""初始化权重"""for module in self.modules():if isinstance(module, nn.Linear):nn.init.normal_(module.weight, mean=0.0, std=0.02)if module.bias is not None:nn.init.zeros_(module.bias)elif isinstance(module, nn.Embedding):nn.init.normal_(module.weight, mean=0.0, std=0.02)def forward(self, input_ids, attention_mask=None):seq_length = input_ids.size(1)# 嵌入和位置编码embeddings = self.embedding(input_ids)# 确保位置编码维度匹配pos_enc = self.pos_encoding[:seq_length].unsqueeze(0).expand(embeddings.size(0), -1, -1)embeddings = embeddings + pos_enc# 注意力掩码if attention_mask is None:attention_mask = (input_ids != 0).float()# Transformermask = (attention_mask == 0)hidden_states = self.transformer(embeddings, src_key_padding_mask=mask)# 语言模型头logits = self.lm_head(hidden_states)return logitsclass RewardModel(nn.Module):"""奖励模型"""def __init__(self, vocab_size, d_model=256, nhead=8, num_layers=4, max_length=128):super().__init__()self.d_model = d_model# 嵌入层self.embedding = nn.Embedding(vocab_size, d_model)self.pos_encoding = nn.Parameter(torch.randn(max_length, d_model))# Transformer层encoder_layer = nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead, dim_feedforward=d_model*4,dropout=0.1, batch_first=True)self.transformer = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)# 奖励头self.reward_head = nn.Sequential(nn.Linear(d_model, d_model // 2),nn.ReLU(),nn.Linear(d_model // 2, 1))def forward(self, input_ids, attention_mask=None):seq_length = input_ids.size(1)# 嵌入和位置编码embeddings = self.embedding(input_ids)# 确保位置编码维度匹配pos_enc = self.pos_encoding[:seq_length].unsqueeze(0).expand(embeddings.size(0), -1, -1)embeddings = embeddings + pos_enc# 注意力掩码if attention_mask is None:attention_mask = (input_ids != 0).float()# Transformermask = (attention_mask == 0)hidden_states = self.transformer(embeddings, src_key_padding_mask=mask)# 使用最后一个非填充位置的隐藏状态batch_size = input_ids.size(0)# 计算每个序列的实际长度(非padding token的数量)seq_lengths = attention_mask.sum(dim=1).long()# 避免索引为0的情况,至少为1last_positions = torch.clamp(seq_lengths - 1, min=0)# 使用torch.arange确保索引类型正确batch_indices = torch.arange(batch_size, device=input_ids.device)last_hidden = hidden_states[batch_indices, last_positions]# 奖励分数reward = self.reward_head(last_hidden).squeeze(-1)return rewardclass PreferenceDataset(Dataset):"""偏好数据集"""def __init__(self, preferences, tokenizer, max_length=128):self.preferences = preferencesself.tokenizer = tokenizerself.max_length = max_lengthdef __len__(self):return len(self.preferences)def __getitem__(self, idx):pref = self.preferences[idx]prompt = pref["prompt"]chosen = pref["chosen"]rejected = pref["rejected"]# 编码prompt_tokens = self.tokenizer.encode(prompt, self.max_length)chosen_tokens = self.tokenizer.encode(prompt + " " + chosen, self.max_length)rejected_tokens = self.tokenizer.encode(prompt + " " + rejected, self.max_length)return {"prompt": torch.tensor(prompt_tokens, dtype=torch.long),"chosen": torch.tensor(chosen_tokens, dtype=torch.long),"rejected": torch.tensor(rejected_tokens, dtype=torch.long)}class PPOTrainer:"""PPO训练器"""def __init__(self, policy_model, reward_model, tokenizer, lr=1e-4):self.policy_model = policy_modelself.reward_model = reward_modelself.tokenizer = tokenizer# 创建参考模型(冻结的策略模型副本)self.ref_model = SimpleTransformer(vocab_size=policy_model.vocab_size,d_model=policy_model.d_model,max_length=policy_model.max_length).to(device)self.ref_model.load_state_dict(policy_model.state_dict())self.ref_model.eval()# 优化器self.optimizer = optim.Adam(policy_model.parameters(), lr=lr)# PPO参数self.clip_ratio = 0.2self.kl_coeff = 0.02self.value_coeff = 0.1self.entropy_coeff = 0.01def generate_response(self, prompt_tokens, max_new_tokens=50, temperature=0.8):"""生成响应"""self.policy_model.eval()with torch.no_grad():input_ids = prompt_tokens.clone()for _ in range(max_new_tokens):logits = self.policy_model(input_ids)next_token_logits = logits[:, -1, :] / temperatureprobs = F.softmax(next_token_logits, dim=-1)next_token = torch.multinomial(probs, 1)input_ids = torch.cat([input_ids, next_token], dim=-1)# 检查是否所有序列都生成了结束标记if (next_token == 3).all(): # <end>break# 防止序列过长if input_ids.size(1) >= self.policy_model.max_length:breakreturn input_idsdef compute_rewards(self, sequences):"""计算奖励"""self.reward_model.eval()with torch.no_grad():rewards = self.reward_model(sequences)return rewardsdef compute_log_probs(self, model, sequences, actions):"""计算动作的对数概率"""# 确保序列长度足够if sequences.size(1) <= 1:return torch.zeros(actions.size(), device=actions.device)logits = model(sequences[:, :-1]) # 不包括最后一个tokenlog_probs = F.log_softmax(logits, dim=-1)# 获取动作的对数概率action_log_probs = log_probs.gather(2, actions.unsqueeze(-1)).squeeze(-1)return action_log_probsdef ppo_step(self, prompts, responses, rewards, old_log_probs):"""PPO更新步骤"""self.policy_model.train()# 检查响应是否为空if responses.size(1) == 0:return {"policy_loss": 0.0,"kl_penalty": 0.0,"entropy": 0.0,"total_loss": 0.0}# 计算新的对数概率full_sequences = torch.cat([prompts, responses], dim=1)new_log_probs = self.compute_log_probs(self.policy_model, full_sequences, responses)# 计算参考模型的对数概率(用于KL散度)with torch.no_grad():ref_log_probs = self.compute_log_probs(self.ref_model, full_sequences, responses)# 计算比率ratio = torch.exp(new_log_probs - old_log_probs)# PPO裁剪损失advantages = rewards.unsqueeze(-1) - rewards.mean()clipped_ratio = torch.clamp(ratio, 1 - self.clip_ratio, 1 + self.clip_ratio)policy_loss = -torch.min(ratio * advantages, clipped_ratio * advantages).mean()# KL散度惩罚kl_penalty = self.kl_coeff * (new_log_probs - ref_log_probs).mean()# 熵奖励entropy = -(torch.exp(new_log_probs) * new_log_probs).sum(-1).mean()entropy_bonus = self.entropy_coeff * entropy# 总损失total_loss = policy_loss + kl_penalty - entropy_bonus# 反向传播self.optimizer.zero_grad()total_loss.backward()torch.nn.utils.clip_grad_norm_(self.policy_model.parameters(), 1.0)self.optimizer.step()return {"policy_loss": policy_loss.item(),"kl_penalty": kl_penalty.item(),"entropy": entropy.item(),"total_loss": total_loss.item()}class RLHFTrainer:"""完整的RLHF训练器"""def __init__(self, vocab_size=5000, d_model=256, max_length=128):self.vocab_size = vocab_sizeself.d_model = d_modelself.max_length = max_length# 初始化组件self.tokenizer = SimpleTokenizer(vocab_size)self.policy_model = SimpleTransformer(vocab_size, d_model, max_length=max_length).to(device)self.reward_model = RewardModel(vocab_size, d_model, max_length=max_length).to(device)logger.info("RLHF训练器初始化完成")def prepare_data(self):"""准备示例数据 - 增加更多样化的数据"""# 预训练数据 - 增加数据量和多样性pretrain_texts = ["今天天气很好,阳光明媚,适合出门散步","我喜欢学习新知识,这让我感到充实和快乐","人工智能很有趣,它正在改变我们的生活","编程是一门艺术,需要逻辑思维和创造力","音乐让人放松,能够舒缓心情和压力","读书使人进步,开拓视野增长见识","运动有益健康,保持身体活力和精神状态","美食令人愉悦,带来味觉和心灵的享受","旅行开阔视野,体验不同文化和风景","友谊珍贵无比,真挚的友情值得珍惜","工作需要专注,认真负责才能做好","家庭很重要,亲情是最温暖的港湾","创新推动发展,新思路带来新机遇","学习永无止境,持续进步才能成长","沟通很关键,理解彼此才能合作","时间很宝贵,珍惜当下把握机会","健康最重要,身体是革命的本钱","梦想值得追求,坚持努力终会实现","思考很重要,深度思考带来智慧","合作共赢好,团结协作力量大"] * 20 # 增加重复次数# 偏好数据 - 增加数据量preferences = [{"prompt": "今天天气","chosen": "今天天气很好,阳光明媚,适合出门游玩和散步","rejected": "今天天气不好,下雨了"},{"prompt": "学习的意义","chosen": "学习能够丰富知识,提升能力,让人变得更加智慧","rejected": "学习很累很困难"},{"prompt": "人工智能","chosen": "人工智能是未来科技发展的重要方向,将改变生活","rejected": "人工智能很难懂很复杂"},{"prompt": "工作态度","chosen": "认真负责的工作态度是成功的关键因素","rejected": "工作很辛苦很累"},{"prompt": "健康生活","chosen": "健康的生活方式包括运动、营养和良好作息","rejected": "健康生活很难坚持"},{"prompt": "友谊价值","chosen": "真挚的友谊珍贵无比,朋友间相互支持很重要","rejected": "朋友关系很复杂"}] * 10 # 增加重复次数return pretrain_texts, preferencesdef pretrain(self, texts, epochs=20, batch_size=8, lr=1e-3):"""预训练阶段 - 增加训练轮数"""logger.info("开始预训练...")# 构建词汇表self.tokenizer.build_vocab(texts)# 准备数据 - 使用与模型一致的最大长度encoded_texts = [self.tokenizer.encode(text, self.max_length) for text in texts]dataset = torch.utils.data.TensorDataset(torch.tensor(encoded_texts, dtype=torch.long))dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)# 优化器 - 调整学习率optimizer = optim.Adam(self.policy_model.parameters(), lr=lr, weight_decay=1e-5)criterion = nn.CrossEntropyLoss(ignore_index=0) # 忽略padding# 学习率调度器scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=epochs)self.policy_model.train()for epoch in range(epochs):total_loss = 0num_batches = 0for batch in dataloader:input_ids = batch[0].to(device)# 前向传播logits = self.policy_model(input_ids)# 计算损失(预测下一个token)shift_logits = logits[:, :-1, :].contiguous()shift_labels = input_ids[:, 1:].contiguous()loss = criterion(shift_logits.view(-1, self.vocab_size), shift_labels.view(-1))# 反向传播optimizer.zero_grad()loss.backward()torch.nn.utils.clip_grad_norm_(self.policy_model.parameters(), 1.0)optimizer.step()total_loss += loss.item()num_batches += 1scheduler.step()avg_loss = total_loss / num_batcheslogger.info(f"预训练 Epoch {epoch+1}/{epochs}, Loss: {avg_loss:.4f}, LR: {scheduler.get_last_lr()[0]:.6f}")logger.info("预训练完成")def train_reward_model(self, preferences, epochs=30, batch_size=4, lr=1e-4):"""训练奖励模型 - 增加训练轮数"""logger.info("开始训练奖励模型...")dataset = PreferenceDataset(preferences, self.tokenizer, self.max_length)dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)optimizer = optim.Adam(self.reward_model.parameters(), lr=lr, weight_decay=1e-5)self.reward_model.train()for epoch in range(epochs):total_loss = 0correct = 0total = 0for batch in dataloader:chosen_ids = batch["chosen"].to(device)rejected_ids = batch["rejected"].to(device)# 计算奖励分数chosen_rewards = self.reward_model(chosen_ids)rejected_rewards = self.reward_model(rejected_ids)# 排序损失(chosen应该比rejected得分更高)loss = -torch.log(torch.sigmoid(chosen_rewards - rejected_rewards)).mean()# 反向传播optimizer.zero_grad()loss.backward()torch.nn.utils.clip_grad_norm_(self.reward_model.parameters(), 1.0)optimizer.step()total_loss += loss.item()# 计算准确率correct += (chosen_rewards > rejected_rewards).sum().item()total += chosen_rewards.size(0)avg_loss = total_loss / len(dataloader)accuracy = correct / totallogger.info(f"奖励模型 Epoch {epoch+1}/{epochs}, Loss: {avg_loss:.4f}, Acc: {accuracy:.4f}")logger.info("奖励模型训练完成")def rl_training(self, prompts, epochs=15, batch_size=2):"""强化学习训练阶段 - 增加训练轮数"""logger.info("开始PPO强化学习训练...")ppo_trainer = PPOTrainer(self.policy_model, self.reward_model, self.tokenizer, lr=5e-5)# 编码提示encoded_prompts = [self.tokenizer.encode(prompt, self.max_length//2) for prompt in prompts]prompt_dataset = torch.utils.data.TensorDataset(torch.tensor(encoded_prompts, dtype=torch.long))prompt_dataloader = DataLoader(prompt_dataset, batch_size=batch_size, shuffle=True)for epoch in range(epochs):epoch_stats = {"policy_loss": 0, "kl_penalty": 0, "entropy": 0, "total_loss": 0}num_batches = 0for batch in prompt_dataloader:prompt_tokens = batch[0].to(device)# 生成响应with torch.no_grad():full_sequences = ppo_trainer.generate_response(prompt_tokens, max_new_tokens=20)# 确保响应序列不为空if full_sequences.size(1) <= prompt_tokens.size(1):continueresponses = full_sequences[:, prompt_tokens.size(1):]# 计算奖励rewards = ppo_trainer.compute_rewards(full_sequences)# 计算旧的对数概率old_log_probs = ppo_trainer.compute_log_probs(ppo_trainer.policy_model, full_sequences, responses)# PPO更新stats = ppo_trainer.ppo_step(prompt_tokens, responses, rewards, old_log_probs)for key in epoch_stats:epoch_stats[key] += stats[key]num_batches += 1# 记录平均统计if num_batches > 0:for key in epoch_stats:epoch_stats[key] /= num_batcheslogger.info(f"PPO Epoch {epoch+1}/{epochs}: {epoch_stats}")else:logger.info(f"PPO Epoch {epoch+1}/{epochs}: 没有有效的批次")logger.info("PPO训练完成")def generate_text(self, prompt, max_length=30, temperature=0.7, top_k=50):"""生成文本 - 改进解码策略"""self.policy_model.eval()# 确保提示词在词汇表中prompt_tokens = torch.tensor([self.tokenizer.encode(prompt, self.max_length//2)], dtype=torch.long).to(device)with torch.no_grad():input_ids = prompt_tokens.clone()generated_tokens = []for _ in range(max_length):# 获取模型预测logits = self.policy_model(input_ids)next_token_logits = logits[:, -1, :] / temperature# 应用top-k过滤if top_k > 0:indices_to_remove = next_token_logits < torch.topk(next_token_logits, top_k)[0][..., -1, None]next_token_logits[indices_to_remove] = -float('Inf')# 计算概率分布probs = F.softmax(next_token_logits, dim=-1)# 采样下一个tokennext_token = torch.multinomial(probs, 1)# 如果生成了结束标记,停止生成if next_token.item() == 3: # <end>break# 如果生成了未知标记,尝试重新采样if next_token.item() == 1: # <unk>continue# 添加新生成的tokeninput_ids = torch.cat([input_ids, next_token], dim=-1)generated_tokens.append(next_token.item())# 检查序列长度if input_ids.size(1) >= self.max_length:break# 如果没有生成任何token,返回原始提示if not generated_tokens:return prompt# 解码生成的文本generated_text = self.tokenizer.decode(generated_tokens)# 如果生成了空文本,返回原始提示if not generated_text.strip():return promptreturn prompt + " " + generated_textdef save_models(self, save_dir="./rlhf_models"):"""保存模型"""os.makedirs(save_dir, exist_ok=True)torch.save(self.policy_model.state_dict(), os.path.join(save_dir, "policy_model.pt"))torch.save(self.reward_model.state_dict(), os.path.join(save_dir, "reward_model.pt"))# 保存分词器with open(os.path.join(save_dir, "tokenizer.json"), "w", encoding="utf-8") as f:json.dump({"vocab": self.tokenizer.vocab,"reverse_vocab": self.tokenizer.reverse_vocab}, f, ensure_ascii=False, indent=2)logger.info(f"模型已保存到 {save_dir}")def load_models(self, save_dir="./rlhf_models"):"""加载模型"""self.policy_model.load_state_dict(torch.load(os.path.join(save_dir, "policy_model.pt"), map_location=device))self.reward_model.load_state_dict(torch.load(os.path.join(save_dir, "reward_model.pt"), map_location=device))# 加载分词器with open(os.path.join(save_dir, "tokenizer.json"), "r", encoding="utf-8") as f:tokenizer_data = json.load(f)self.tokenizer.vocab = tokenizer_data["vocab"]self.tokenizer.reverse_vocab = {int(k): v for k, v in tokenizer_data["reverse_vocab"].items()}logger.info(f"模型已从 {save_dir} 加载")def main():"""主函数 - 完整的RLHF训练流程"""logger.info("开始完整的RLHF训练流程")# 初始化训练器 - 调整参数trainer = RLHFTrainer(vocab_size=2000, d_model=128, max_length=64)# 准备数据pretrain_texts, preferences = trainer.prepare_data()# 阶段1:预训练trainer.pretrain(pretrain_texts, epochs=15, batch_size=4)# 阶段2:训练奖励模型trainer.train_reward_model(preferences, epochs=20, batch_size=2)# 阶段3:PPO强化学习prompts = ["今天天气", "学习的意义", "人工智能", "编程语言", "音乐的魅力", "健康生活", "工作态度"]trainer.rl_training(prompts, epochs=10, batch_size=2)# 测试生成logger.info("\n=== 生成测试 ===")test_prompts = ["今天天气", "人工智能", "学习", "健康", "工作"]for prompt in test_prompts:generated = trainer.generate_text(prompt, max_length=20)logger.info(f"提示: {prompt}")logger.info(f"生成: {generated}")logger.info("-" * 50)# 保存模型trainer.save_models()logger.info("RLHF训练流程完成!")if __name__ == "__main__":main()