竞赛小算法总结(一):位运算,因数分解和“马拉车”算法含代码详解
写在前面的话:这里之所以把下面要讲的算法叫做小算法,并不是说它不重要,而是说它的可改变程度小,这也就导致了如果它出现在了竞赛中,你不会这些算法就很难破题,而一旦你学会了,一般都可以一战,因为改变度小,基本和你之前写的差不多(亲身体验)。
一 位运算
这里之所以要讲位运算,是因为蓝桥杯里面这是经常出现的考点,而且往往是题目的补充,有时我因为不懂位运算就下不了笔,而且位运算中也有非常多有意思的点。
位运算:位运算是对二进制数的每一位进行操作的运算 ,在计算机中,数据以二进制形式存储,位运算直接对这些二进制位进行处理,效率极高。
位运算介绍:
- 与(AND,符号:&) :两个位都为 1 时,结果为 1,否则为 0 。例如,5(二进制 101 )& 3(二进制 011 ),对应位运算为 101 & 011 = 001(结果为 1 ) 。
- 或(OR,符号:|) :两个位中有一个为 1 时,结果为 1,否则为 0 。例如,5 | 3 ,即 101 | 011 = 111(结果为 7 ) 。
- 异或(XOR,符号:^) :两个位不同时,结果为 1,否则为 0 。例如,5 ^ 3 ,即 101 ^ 011 = 110(结果为 6 ) 。其性质有:两个相同的数异或结果为 0;0 和任何数异或结果等于这个数本身 。
- 非(NOT,符号:~) :对每一位取反,0 变 1,1 变 0 。例如,~5(5 的二进制为 101 ),结果为(取决于位数,通常在补码表示下,结果为 - 6 ) 。
- 左移(Left Shift,符号:<<) :将二进制数向左移动指定位数,低位补 0 。例如,5 << 1 (101 左移 1 位 )结果为 1010(10 ) ,相当于乘以 2 。
- 右移(Right Shift,符号:>>) :将二进制数向右移动指定位数,对于有符号数,高位补符号位(算术右移);对于无符号数,高位补 0(逻辑右移) 。例如,5 >> 1 (101 右移 1 位 )结果为 10(2 ) ,相当于除以 2 。
这个中文对应的符号非常有必要记一下,有时它只给中文,你都不知道写什么。
下面是这些位运算的应用:
- 判断奇偶:使用 n & 1 ,结果为 1 则 n 为奇数,结果为 0 则 n 为偶数 。因为奇数的二进制最低位为 1,偶数的二进制最低位为 0 。
- 交换两个数:可以通过位运算实现,代码为 a ^= b; b ^= a; a ^= b; 。原理是利用异或运算的性质 。这个就很神奇,不需要临时变量就能交换。
- 取反加一:~n + 1 ,在补码表示下,相当于取负数 。
- 求绝对值:对于 32 位整数,可使用 (n ^ (n>> 31)) - (n >> 31) 计算绝对值 。
- 判断是否为 2 的幂:使用 (n & (n - 1)) == 0 来判断,若结果为真,则 n 是 2 的幂 。因为 2 的幂的二进制表示中只有一位是 1 ,减 1 后与原数按位与结果为 0 。(这个感觉很有用,可以把log(n)的时间复杂度降低)
- 统计二进制中 1 的个数:可以使用循环或查表法实现 。例如,不断让 n = n & (n - 1) ,每执行一次该操作,n 的二进制表示中最右侧的 1 就会被去掉,通过统计执行次数,就能得到 1 的个数 。
- 快速乘除:左移一位相当于乘以 2,右移一位相当于除以 2 。例如,a <<1 等同于 a * 2 ;a>> 1 等同于 a / 2 (这里的除法是整数除法 )。
位运算考点
- 基础运算规则考察:直接考查各种位运算符的运算规则,比如给定两个整数,要求计算它们经过某种位运算后的结果。例如,已知 a = 6(二进制 110 ),b = 3(二进制 011 ),求 a & b 、a | b 、a ^ b 的值 。
- 利用位运算性质解题:利用位运算的交换律、结合律、异或运算性质等解题。比如,“在一个整数数组中,除了一个数字只出现一次,其余数字都出现两次,找出这个只出现一次的数字”,就可以利用异或运算,两个相同的数异或为 0 ,0 和任何数异或为该数本身的性质来解决 ,异或运算有交换律。
- 位运算的应用场景考察:考察位运算在判断奇偶、交换数字、判断 2 的幂等场景中的应用。比如,判断一个数是否为 2 的幂,要求用位运算实现 。
- 位运算与算法结合:将位运算与其他算法结合,如在一些位运算相关的动态规划、贪心算法题目中,利用位运算进行状态表示或状态转移 。例如,在状态压缩动态规划中,用二进制数表示状态,通过位运算来操作和转移状态 。
二 因数分解
首先,我们要介绍算数基本定理,又称为正整数的唯一分解定理 ,是数论中非常重要的定理。其内容为:任何一个大于1的自然数N,都可以唯一分解成有限个质数的乘积。比如18=2*3*3;
那么我们接下来就要完成题目给我们一个数,我们把它质因数分解。
import java.util.*;public class Main {// 分解质因数的方法,返回包含所有质因数的ArrayListpublic static ArrayList<Integer> solve(int n) {ArrayList<Integer> arr = new ArrayList<>(); // 存储质因数的列表int i = 2; // 从最小的质数2开始试除// 当n大于1时,继续寻找质因数while (n > 1) {if (n % i == 0) { // 如果i是n的质因数n /= i; // 将n除以i,更新n的值arr.add(i); // 将i添加到质因数列表中} else { // 如果i不是n的质因数if (i == 2) { // 处理i=2的情况,直接加1变为3i++;} else { // 处理i为奇数的情况,每次加2(跳过偶数)i += 2;}}}return arr; // 返回包含所有质因数的列表}public static void main(String[] args) {Scanner sc = new Scanner(System.in); // 创建Scanner对象读取输入int n = sc.nextInt(); // 读取用户输入的整数ArrayList<Integer> arr = solve(n); // 调用solve方法进行质因数分解// 遍历质因数列表并输出每个质因数for (int i : arr) {System.out.println(i);}}
}这个确实很简单,但有时会作为题目的一部分出现。
三 “马拉车”算法
这个算法是这里最有含金量的。
算法简介
马拉车算法是一种高效求解字符串中最长回文子串的算法,其时间复杂度为 O(n),空间复杂度为 O(n)。传统方法(如中心扩展法)的时间复杂度为 O(n²),而马拉车算法通过预处理字符串和利用回文子串的对称性,大幅优化了效率。
其实之前我有发过力扣上这道题的中心拓展法的题解。
详情可见:双指针算法总结(二):同向双指针(滑动窗口),背向双指针(分离指针),包括算法原理,适用场景,力扣原题(环形列表,长度最小的子字符串,最长回文子串),思路分析和总结反思,含java代码-CSDN博客
但这并不能避免我在下面这道题的滑铁卢。
T597379 小漳爱探险! - 洛谷
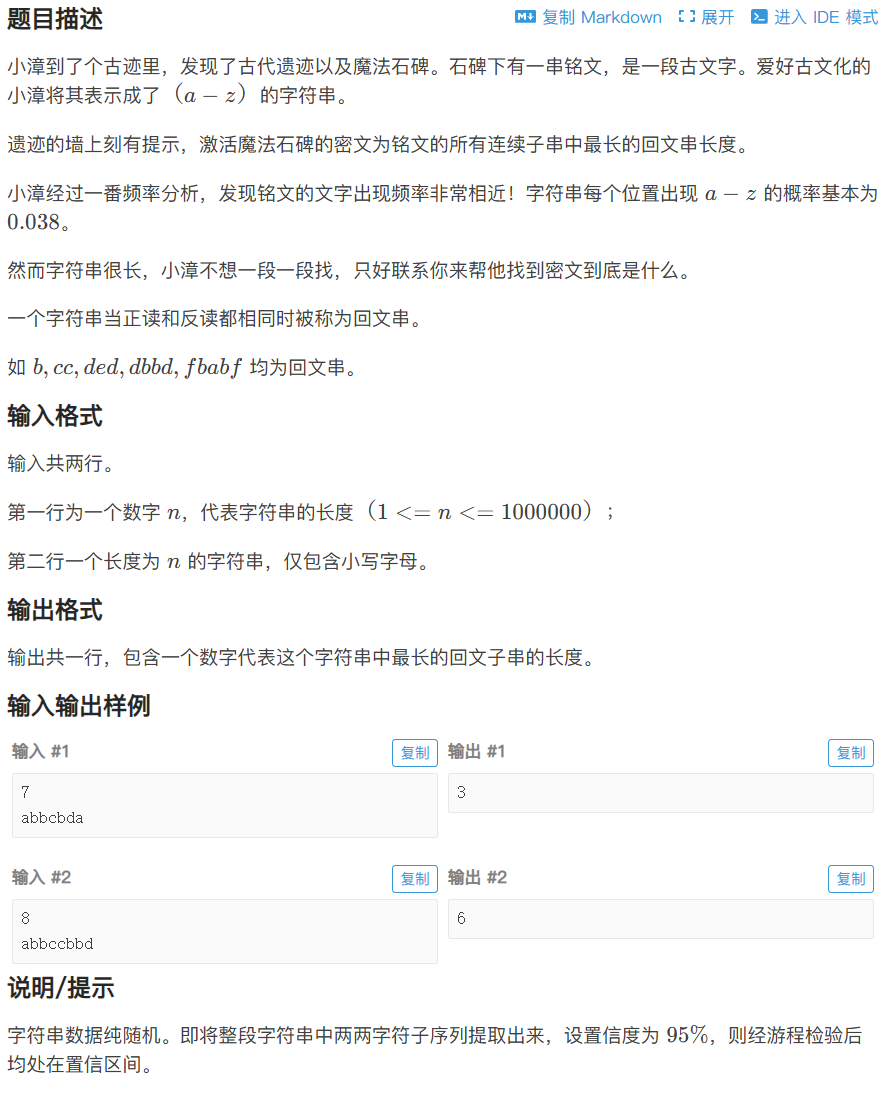
我们注意这里的n是10e6,这代表 时间复杂度为 O(n²)根本过不去,如果你和我当时一样不会马拉车算法就只能放弃了。
先展示一下我的超时解法来警醒各位。
import java.util.*;public class Main {static String a; // 存储输入的字符串public static void main(String arg[]) {Scanner sc = new Scanner(System.in);int n = sc.nextInt(); // 读取字符串长度a = sc.next(); // 读取输入的字符串// 创建一个数组,每个元素是一个ArrayList,用于存储每个字符的出现位置ArrayList<Integer> arr[] = new ArrayList[26];for (int i = 0; i < 26; i++) {arr[i] = new ArrayList<Integer>();}// 遍历字符串,将每个字符的位置存入对应的ArrayList中for (int i = 0; i < a.length(); i++) {char c = a.charAt(i);int k = (int) c % 26; // 将字符转换为0-25的索引(假设都是小写字母)arr[k].add(i); // 将字符c的位置i添加到对应的ArrayList中}int max = 1; // 初始化最长回文子串的长度为1(单个字符本身是回文)// 遍历每个字符的出现位置列表for (ArrayList<Integer> i : arr) {if (i.size() >= 2) { // 如果某个字符出现次数不少于2次// 遍历该字符的所有可能的位置对for (int t1 = 0; t1 < i.size(); t1++) {for (int t2 = t1 + 1; t2 < i.size(); t2++) {int left = i.get(t1); // 左边界位置int right = i.get(t2); // 右边界位置// 如果当前子串长度大于已知的最大长度,并且是回文if ((right - left + 1) > max && find(left, right)) {max = right - left + 1; // 更新最大长度}}}}}System.out.print(max); // 输出最长回文子串的长度}// 判断字符串从索引i到j的子串是否为回文public static boolean find(int i, int j) {while (i < j) {if (a.charAt(i) != a.charAt(j)) {return false; // 只要有不相等的字符,就不是回文}i++; // 左指针右移j--; // 右指针左移}return true; // 所有字符都相等,是回文}
}可以看出我当时已经尽力去优化它了,但还是超时。
下面我讲一下马拉车算法的原理
它其实就是中心拓展法的优化,就是当你已知一个对称中心和它的对称半径,那么你就可以对中心加半径范围之内的点进行直接判断,由于对称所以他的半径长度可能等于左边对称点的半径长度,但是由于对称半径的限制,所以当左边对称点的值大于限制这里就直接等于限制。
下面举例解释:

这是最关键的部分我们可以看到在上面的举例中它可以帮我们节省一些遍历和计算。
除了这个,还有预处理,就是为了避免aa,aba检测的不同,我们把它全部变成奇数,即@#a#a#^和@#a#b#a#^
下面是ai详细注释代码
import java.util.*;public class Main {/*** 预处理输入字符串,插入特殊字符将奇偶长度回文统一处理* @param a 原始字符串* @return 处理后的字符数组,格式为:^#s[0]#s[1]#...#s[n-1]#$*/public static char[] PreProcess(String a) {char arr[] = new char[a.length() * 2 + 3];arr[0] = '^'; // 左边界符,防止数组越界arr[2 * a.length() + 2] = '$'; // 右边界符,防止数组越界// 在每个字符两侧插入'#',将奇偶长度回文统一为奇数长度for (int i = 0; i < a.length(); i++) {arr[2 * i + 1] = '#';arr[2 * i + 2] = a.charAt(i);}arr[2 * a.length() + 1] = '#'; // 处理最后一个'#'return arr;}/*** 使用马拉车算法计算最长回文子串的长度* @param arr 预处理后的字符数组* @return 最长回文子串的长度*/public static int solve(char[] arr) {int maxLen = 0; // 最长回文子串的长度int maxCenter = 0; // 最长回文子串的中心位置int c = 0; // 当前最右回文的中心位置int rgt = 0; // 当前最右回文的右边界(rgt = c + p[c])int[] r = new int[arr.length]; // 记录每个位置的回文半径r[0] = 0; // 边界位置的回文半径为0// 遍历处理后的数组(跳过边界符)for (int i = 1; i < arr.length - 1; i++) {// 计算i关于c的对称点jint j = 2 * c - i;// 利用对称性初始化r[i]if (rgt > i) {// i在当前最右回文内,取对称点的半径或到右边界的距离的较小值r[i] = Math.min(rgt - i, r[j]);} else {// i超出当前最右回文,无法利用对称性,初始化为0r[i] = 0;}// 中心扩展:尝试扩展以i为中心的回文半径while (arr[i + r[i] + 1] == arr[i - r[i] - 1]) {r[i]++;}// 更新当前最右回文的中心和右边界if (i + r[i] > rgt) {c = i;rgt = i + r[i];}// 记录最大回文半径及其中心位置if (r[i] > maxLen) {maxLen = r[i];maxCenter = i;}}return maxLen; // 返回最长回文的半径}public static void main(String[] args) {Scanner sc = new Scanner(System.in);int n = sc.nextInt(); // 读取字符串长度(题目可能要求,但代码中未使用)String a = sc.next(); // 读取原始字符串char arr[] = PreProcess(a); // 预处理字符串int ans = solve(arr); // 计算最长回文长度System.out.print(ans); // 输出结果}
}总结,这里其实就利用对称性上半径也对称的特性,其实我们写题目是就是要分析它的特性来选择相应的算法。