【MPC控制】番外篇:MPC 与 机器学习/深度学习 —— 双雄会的相似与不同
【MPC控制】番外篇:MPC 与 机器学习/深度学习 —— 双雄会的相似与不同
各位控制领域的探索者们,大家好!欢迎来到我们【MPC控制 - 从ACC到自动驾驶】专栏的特别“番外篇”。在前五天的学习中,我们深入了解了模型预测控制(MPC)在自适应巡航(ACC)系统中的应用。细心的朋友可能会在学习过程中产生一个疑问:MPC这种基于模型进行预测和优化的方式,听起来和现在大火的机器学习(ML)/深度学习(DL)解决问题的方法,似乎有异曲同工之妙?它们都是在处理复杂系统,都在试图做出“智能”的决策。
你不是一个人在这么想!确实,MPC和ML/DL在某些高层目标上(比如实现智能控制)是相似的,但它们的底层逻辑、实现路径和适用场景却大相径庭。今天,我们就来一场“双雄会”,从多个维度深入对比一下MPC和ML/DL这两大技术流派的相似与不同,希望能帮助大家更清晰地认识它们各自的特点和价值。
主角登场:MPC 与 ML/DL 简述
在正式对比之前,我们先简单回顾一下两位主角的核心思想。
模型预测控制 (MPC) - 深思熟虑的规划大师
我们在专栏正篇中已经详细学习过MPC了。它的核心思想可以概括为:
- 基于模型 (Model-Based): 依赖一个明确的被控对象(如车辆)的数学模型。
- 预测未来 (Prediction): 利用模型预测系统在未来一段时间(预测时域 N p N_p Np)内的行为。
- 滚动优化 (Receding Horizon Optimization): 在每个控制周期,求解一个带约束的优化问题,以最小化某个性能指标(代价函数 J J J),从而找到未来一段时间(控制时域 N c N_c Nc)的最优控制序列。
- 反馈校正 (Feedback): 只执行最优控制序列的第一个动作,然后在下一时刻根据新的系统状态测量值,重复整个预测和优化过程。
MPC就像一位深思熟虑的工程师,手握蓝图(模型),精确计算每一步的得失,并严格遵守安全规范(约束)。

机器学习/深度学习 (ML/DL) - 经验丰富的学习巨匠
机器学习,特别是深度学习(通常指使用深层神经网络的机器学习),则是另一种范式:
- 数据驱动 (Data-Driven): 主要依赖大量数据来学习模型或策略。
- 模式识别与函数逼近 (Pattern Recognition & Function Approximation): 擅长从数据中发现复杂的模式、规律,并能以极高的精度逼近任意复杂的函数。
- 学习范式多样:
- 监督学习 (Supervised Learning): 从“带标签”的数据(输入-输出对)中学习映射关系。例如,根据历史驾驶数据学习一个驾驶策略。
- 无监督学习 (Unsupervised Learning): 从“无标签”的数据中发现结构和模式。
- 强化学习 (Reinforcement Learning, RL): 智能体(Agent)通过与环境的交互(试错)来学习一个最优策略,以最大化累积奖励(Reward)。这在控制领域应用非常广泛,比如AlphaGo下棋,或者训练机器人走路。
ML/DL就像一位经验极其丰富的老师傅,通过观察成千上万的案例(数据),逐渐掌握了解决问题的“手感”和“直觉”,但可能不一定能清晰地解释出每一步背后的精确数学原理。
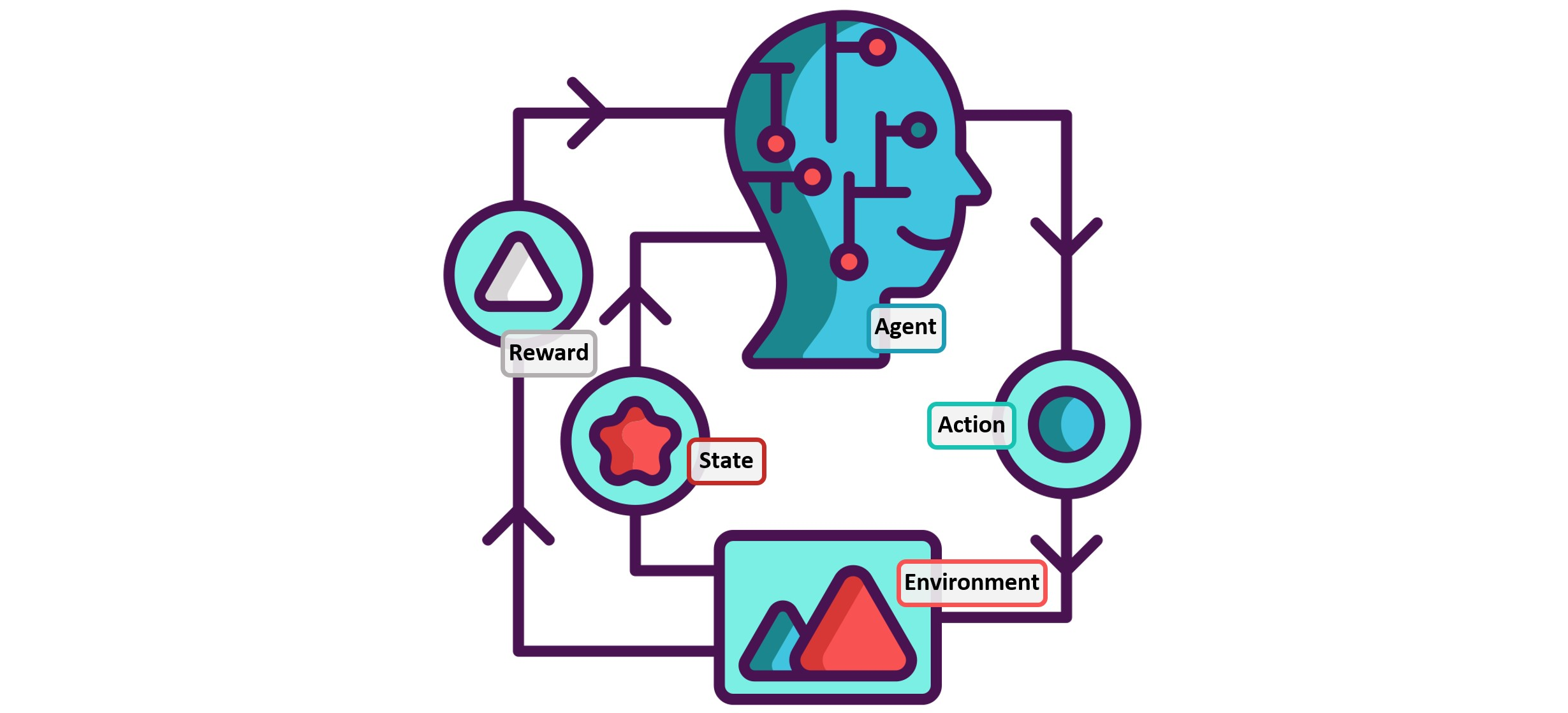
深度对比:MPC vs. ML/DL 在控制领域的“七十二变”
了解了基本概念后,我们从以下几个关键维度进行对比:
| 特性维度 | 模型预测控制 (MPC) | 机器学习/深度学习 (ML/DL) in Control |
|---|---|---|
| 1. 核心范式 | 基于模型 (Model-Based) | 数据驱动 (Data-Driven) |
| 2. 模型来源 | 通常基于物理定律、第一性原理推导,或系统辨识得到显式数学模型 (如状态空间方程) | 从数据中隐式学习得到,模型结构(如神经网络)通常是预设的,参数是学习的 |
| 3. 数据需求 | 对精确模型依赖高;数据主要用于模型辨识、验证和参数校准 | 依赖大量高质量数据进行训练;数据量和多样性直接影响性能 |
| 4. 可解释性 | 强 (White Box/Grey Box),决策过程和原因相对透明,基于优化目标和约束 | 弱 (Black Box/Grey Box),尤其是深度神经网络,其决策逻辑难以直观解释 |
| 5. 约束处理 | 核心优势之一,可以显式、严格地处理状态和输入的约束 (硬约束/软约束) | 较难直接处理硬约束,通常通过在损失函数中加惩罚项、修改网络结构或结合其他方法间接处理 |
| 6. 最优性与稳定性 | 在一定条件下(如线性系统、凸优化问题)可保证局部或全局最优;稳定性分析理论相对成熟 | 最优性通常是经验性的(如在训练集上表现好);泛化到未见数据的稳定性和最优性保证较难 |
| 7. 计算成本 | 在线计算成本高: 每个控制周期都需要求解优化问题;离线成本低: 模型建立和参数整定 | 在线计算成本低(推理快): 一旦训练完成,前向传播通常很快;离线训练成本高: 可能需要大量计算资源和时间 |
| 8. 适应性与泛化 | 对模型准确性敏感,模型失配会影响性能;适应新工况通常需要重新调整模型或参数 | 泛化能力强(如果数据多样且充足),能处理训练数据中未精确出现的相似情况;但对训练分布外的场景可能表现差(Out-of-Distribution) |
| 9. 开发周期与难度 | 模型建立可能耗时且需要领域知识;优化求解器选择和参数整定有挑战 | 数据收集和标注成本高;网络结构设计、超参数调整、训练技巧复杂,需要大量经验 |
| 10. 安全关键应用 | 由于可解释性强、约束处理能力强、稳定性分析相对成熟,在安全关键领域应用更受信任 | 在安全关键应用中需谨慎,通常需要额外的验证与确认 (V&V) 机制,或与其他更可信的控制器结合 |
| 11. “学习”方式 | 主要通过在线滚动优化适应当前状态和预测;参数和模型通常是离线确定的(自适应MPC除外) | 主要通过离线训练从数据中学习;在线学习(如持续强化学习)也在发展,但面临挑战 |
1. 核心驱动力:模型 vs. 数据
这是两者最根本的区别。
-
MPC: “给我一个准确的系统模型,我能告诉你怎么控制它达到最优。” 它的“智能”来源于对系统行为规律的深刻理解(通过模型)和对未来可能性的系统性探索(通过预测和优化)。
x ( k + 1 ) = f ( x ( k ) , u ( k ) ) \mathbf{x}(k+1) = f(\mathbf{x}(k), u(k)) x(k+1)=f(x(k),u(k))
这个 f f f对MPC来说是已知的、明确的。 -
ML/DL: “给我足够多的‘好行为’或‘环境反馈’数据,我能学会如何做出类似的‘好行为’。” 它的“智能”来源于从海量经验中提取出的模式和关联。
u ( k ) = π θ ( x ( k ) ) u(k) = \pi_{\theta}(\mathbf{x}(k)) u(k)=πθ(x(k))
这个策略 π θ \pi_{\theta} πθ(例如一个神经网络) 中的参数 θ \theta θ是通过数据学习得到的,我们可能并不完全清楚 π θ \pi_{\theta} πθ内部的具体运作机理。
2. 可解释性:透明的工程师 vs. 神秘的艺术家
- MPC: 当MPC做出一个控制决策时,我们可以追溯其原因:是因为要最小化某个代价函数?还是因为某个约束快要被触碰了?它的决策逻辑是清晰的,这对于调试和验证非常重要。
- ML/DL: 尤其是深度神经网络,其内部的运作方式往往像一个“黑箱”。虽然它可能给出了一个很好的控制指令,但我们很难解释“为什么”是这个指令。这在需要高可靠性和高安全性的应用中(如自动驾驶)是一个巨大的挑战。目前,可解释性人工智能(XAI)是研究的热点。
3. 约束处理能力:戴着镣铐跳舞的艺术
- MPC: 这是MPC的“杀手锏”。无论是车辆的加速度不能超过2m/s²,还是与前车的距离不能小于10米,这些都可以作为明确的数学约束条件加入到优化问题中。MPC的解天然就是满足这些约束的。
min U J ( X , U ) s.t. x m i n ≤ x ( k ) ≤ x m a x , u m i n ≤ u ( k ) ≤ u m a x \min_{U} J(X,U) \quad \text{s.t.} \quad \mathbf{x}_{min} \le \mathbf{x}(k) \le \mathbf{x}_{max}, \quad u_{min} \le u(k) \le u_{max} minUJ(X,U)s.t.xmin≤x(k)≤xmax,umin≤u(k)≤umax - ML/DL: 直接在神经网络中编码硬约束非常困难。通常的做法是:
- 在损失函数中加入惩罚项,引导网络学习避免违反约束。
- 通过修改网络输出层(如使用
tanh激活函数将输出限制在[-1,1])来间接实现。 - 在强化学习中,如果Agent做出了违反约束的动作,给予一个大的负奖励。
但这些方法都不能保证约束在所有情况下都被严格满足。
4. 对“未知”的处理:依赖模型外推 vs. 依赖数据泛化
- MPC: 如果系统模型在某个未曾遇到的工况下依然准确,MPC理论上可以基于模型外推出合理的控制。但如果实际系统行为超出了模型的描述范围(模型失配),MPC的性能可能会急剧下降。
- ML/DL: 如果训练数据覆盖了足够多样的情况,训练好的模型通常具有一定的泛化能力,能够处理与训练数据相似但又不完全相同的新情况。但如果遇到的情况与训练数据的分布差异过大(Out-of-Distribution),ML模型的表现可能会非常糟糕,甚至给出完全错误的决策。
5. “学习”与“适应”的机制
- MPC: 其核心的“适应性”来自于在线的滚动优化。在每个时刻,它都会根据最新的系统状态重新进行预测和优化。这使得它能够动态地响应扰动和变化。更高级的自适应MPC (Adaptive MPC) 还会在线更新模型参数。
- ML/DL: 其核心的“学习”通常发生在离线的训练阶段。一旦模型训练完成并部署,其参数就固定了(除非采用在线学习或持续学习的策略,但这在复杂控制中仍有挑战)。它的“适应性”更多体现在对训练数据覆盖范围内的不同情况的泛化处理。强化学习是一个例外,它本身就是一个不断与环境交互和学习的过程。
相似之处:为何我们会觉得它们“像”?
尽管有诸多不同,但MPC和ML/DL在某些方面确实展现出相似的“气质”:
- 处理复杂性: 两者都能用于控制具有非线性、多变量、时变特性的复杂系统。MPC通过复杂的优化计算,ML/DL通过复杂的网络结构和学习算法。
- “智能”决策: 它们都能根据当前状态和目标,做出超越简单规则的“智能”决策。MPC的智能源于优化,ML/DL的智能源于学习到的模式。
- 序列决策: MPC通过预测和优化未来控制序列,强化学习也关注一系列动作如何导致最终的累积奖励最大化。
- 在自动驾驶中的共同身影: 在自动驾驶领域,感知层(如图像识别、目标检测)几乎是深度学习的天下;决策规划层则经常看到MPC、RL以及各种混合方法的身影。
强强联合:MPC 与 ML/DL 的“联姻”
既然MPC和ML/DL各有千秋,那么能不能让它们“取长补短、强强联合”呢?答案是肯定的!这正是当前控制领域研究的热点方向之一。
1. ML/DL 助力 MPC (让MPC更强大)
- 学习系统模型 (System Identification): 当难以建立精确的物理模型时,可以用ML/DL方法(如神经网络、高斯过程)从数据中学习一个近似的系统动力学模型 f ^ ( x , u ) \hat{f}(\mathbf{x}, u) f^(x,u),供MPC使用。
- 例如:用神经网络学习车辆的非线性轮胎模型或复杂的空气动力学模型。
- 学习代价函数或约束: 有时,性能指标很难用明确的数学公式表达(比如“驾驶舒适度”)。可以尝试用ML从人类驾驶员的演示数据中学习一个代价函数 J ^ ( x , u ) \hat{J}(\mathbf{x}, u) J^(x,u)。
- 加速MPC求解 (Approximating MPC Policy): MPC的在线优化计算量大,限制了其在快速系统中的应用。可以用一个深度神经网络去“模仿”MPC控制器的行为,即学习从状态 x \mathbf{x} x到最优控制 u ∗ u^* u∗的映射 u ∗ ≈ π N N ( x ) u^* \approx \pi_{NN}(\mathbf{x}) u∗≈πNN(x)。这个训练好的网络在在线使用时,只需要一次前向传播,速度极快。这被称为“显式MPC”或“近似MPC”。
- 学习扰动模型: 预测MPC中未建模的扰动,提高预测精度。
2. MPC 辅助 ML/DL (让ML/DL更可靠)
- 强化学习中的安全探索 (Safe Exploration in RL): 强化学习的“试错”过程在真实物理系统(如车辆)上可能是危险的。可以用MPC作为“安全监督员”,在RL Agent探索时,如果其动作可能导致危险(如违反约束),MPC可以介入并修正动作,保证安全。
- 模型 기반 강화 학습 (Model-Based RL): 先用ML方法学习一个环境模型,然后基于这个学习到的模型进行规划或策略优化(类似于MPC的思想)。
- 指导策略学习: 用MPC生成高质量的控制轨迹作为“专家数据”,来引导或初始化RL策略网络的训练。
- 残差学习: 让ML/DL学习主控制器(如MPC)的残差部分,即对主控制器输出的修正量,以补偿模型不确定性或未建模动态。
如何选择:MPC 还是 ML/DL?亦或两者皆是?
那么,在面对一个具体的控制问题时,我们应该如何选择呢?这取决于问题的特性和可用的资源:
- 当你有一个相对准确、易于建立的物理模型,并且系统有明确的、需要严格遵守的约束时: MPC通常是首选。它能提供较好的可解释性和性能保证。
- 当系统极其复杂,难以建立精确的物理模型,但你有大量相关的运行数据时: ML/DL(尤其是RL或模仿学习)可能是一个有前景的尝试方向。特别是在涉及复杂感知(如视觉输入)的任务中,DL几乎是标配。
- 当你既需要模型的精确指导和约束的严格保证,又想利用数据来弥补模型的不足或加速计算时: 考虑MPC与ML/DL的混合方法。
- 对于安全关键系统: MPC或经过严格验证的传统控制方法通常是基础。如果使用ML/DL,必须有非常完善的验证、确认和安全监控机制。
在ACC的场景中:
- 传统的ACC: 车辆纵向动力学模型相对成熟,约束明确,MPC表现优异。
- 更高级的ACC(如考虑舒适性、个性化、复杂交通交互): 可能会用到ML来学习驾驶员偏好(调整MPC权重或代价函数),或者用DL进行传感器融合以提供更精确的环境感知。
- 端到端自动驾驶(从感知直接到控制): 深度强化学习是一个热门研究方向,但面临巨大的安全和可解释性挑战。
结语:没有银弹,只有合适的工具
MPC和ML/DL都是解决复杂控制问题的强大工具,它们各有其独特的优势和局限性。它们不是相互替代的关系,更像是工具箱里两把不同但都非常锋利的“瑞士军刀”。
理解它们的本质区别和潜在的协同效应,能帮助我们作为工程师和研究者,在面对未来的挑战时,做出更明智的技术选型,设计出更智能、更安全、更高效的控制系统。
希望这篇番外能帮助你拨开“相似”的迷雾,看清MPC与ML/DL各自的“真容”。控制的探索永无止境,让我们带着对不同工具的深刻理解,继续前行!
这篇番外篇就到这里了。希望它能解答你关于MPC和ML/DL相似性的疑问,并为你提供一个新的视角来看待这两个强大的技术领域。如果你有任何想法或问题,欢迎在评论区交流!