Linux基础IO---缓冲区----文件系统----软硬链接
在 Linux 的 文件 I/O(输入 / 输出) 中,缓冲区(Buffer) 是用于暂存文件数据的内存区域,主要作用是减少磁盘 I/O 次数、提升读写效率。以下是文件 I/O 中缓冲区的核心内容:
一、文件 I/O 缓冲区的分类
根据缓冲区的位置和管理方式,可分为两类:
1. 内核缓冲区(Kernel Buffer)
- 位置:位于操作系统内核空间,由内核直接管理。
- 作用:
- 所有文件系统的读写操作(如通过
open/read/write系统调用)都会经过内核缓冲区。 - 读文件时,数据从磁盘先加载到内核缓冲区,再复制到用户空间;
- 写文件时,数据先存入内核缓冲区(称为 脏数据),再异步写入磁盘。
- 所有文件系统的读写操作(如通过
- 实现原理:
- 基于 页缓存(Page Cache):Linux 将内存划分为固定大小的页(通常 4KB),文件数据以页为单位缓存到内核内存中。
- 异步写入机制:内核通过后台进程(如
pdflush/kswapd)定期将脏数据写入磁盘,或在内存不足时触发写入。
2. 用户空间缓冲区(User Space Buffer)
- 位置:位于应用程序的用户空间(如通过
malloc分配的内存)。 - 作用:
- 由应用程序自行管理,用于暂存数据以减少系统调用次数。
- 典型场景:标准 I/O 库(如 C 语言的
fread/fwrite)通过用户空间缓冲区实现 全缓冲、行缓冲 或 无缓冲 的模式。
为什么要有缓冲区呢?
为了提高使用者效率->用空间换时间
- 内核缓冲区 利用页缓存和异步写入减少磁盘 I/O;
- 用户空间缓冲区 通过批量操作减少系统调用开销。
理解缓冲区的工作原理(如脏数据同步时机、fsync的作用)有助于在开发中平衡性能与数据可靠性,避免因缓冲区未刷新导致的数据丢失问题。
二、观察用户缓冲区(C语言)
观察下面这段代码的运行情况:
#include <stdio.h>
#include <unistd.h>
int main()
{//cprintf("hello printf\n");fputs("hello fputs\n", stdout);//systemwrite(1, "hello write\n", 12);fork();return 0;
}
执行结果:
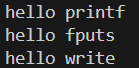
一切正常
但是当我们把结果重定向到log.txt中时:
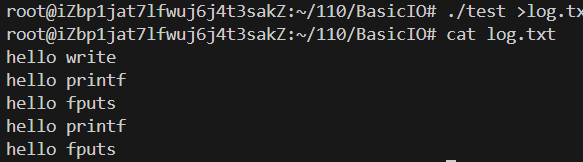
发现 write调用只打印一次,printf和fput分别调用两次,并且再write后打印出来
这是为什么呢?
首先,缓冲区的缓冲方式有3种:
1.无缓冲
2.行缓冲
3.全缓冲
我们第一次执行程序的时候就是行缓冲,因为每一次打印都带了"\n",所以在代码执行完后,对应的数据就立刻被刷新到显示器上。
那么为什么输入到文件里就不是行缓冲了呢?
在 Linux 中,标准 I/O 库(如 printf、fputs)的缓冲模式会根据 输出设备类型 自动调整
默认输出到终端时,启用行缓冲
输出到非终端,如文件、管道、套接字时,启用全缓冲
行缓冲(Line Buffered)
- 当输出到 终端(TTY) 时,默认启用行缓冲。
- 缓冲区在以下情况刷新:
- 遇到换行符
\n;- 缓冲区满(通常 1024 字节);
- 手动调用
fflush()。全缓冲(Fully Buffered)
- 当输出到 非终端设备(如文件、管道、套接字)时,默认启用全缓冲。
- 缓冲区仅在以下情况刷新:
- 缓冲区满(通常 4KB/8KB);
- 手动调用
fflush();- 程序正常退出(如
exit()或return)。无缓冲(Unbuffered)
- 标准错误输出
stderr始终为无缓冲,确保错误信息立即显示。、
所以在全缓冲的情况下,程序没有手动调用fflush,两句打印也不至于塞满缓冲区,所以缓冲区刷新就是在程序退出的时候。
那么为什么是write先刷新出来呢,就算是退出的时候刷新缓冲区难到不应该是先printf和fputs吗?
那是因为write的缓冲区和另外两个的缓冲区不一样。
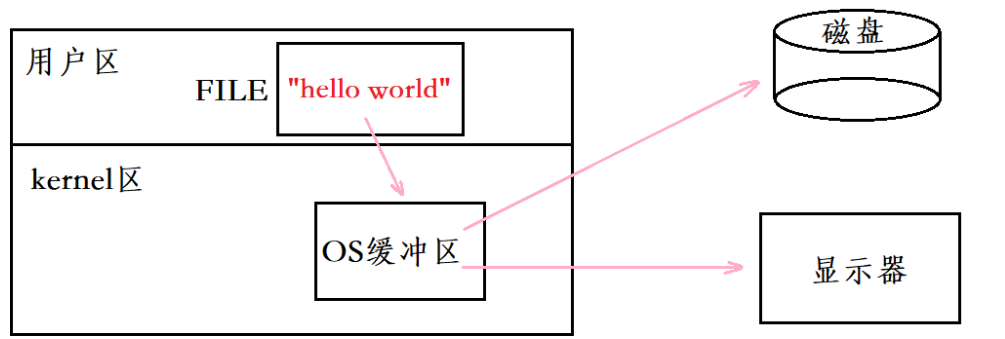
write直接操作内核缓冲区,数据立即进入内核管理的输出队列;- 标准 I/O 函数依赖用户空间缓冲,数据需满足特定条件才会刷新到内核。
用户缓冲区和内核缓冲区并不一样。
用户缓冲区是C语言自带的,C接口的内容先写到用户缓冲区里并未刷新到内核缓冲区里。
此时创建了子进程,子进程继承父进程的数据和代码,所以也同时也拥有父进程的缓冲区。
当父子进程退出时满足全缓冲的刷新条件了,就开始刷新缓冲区,由于刷新缓冲区也是修改数据,那么就会触发写时拷贝,于是父子进程各自就有一份缓冲区,刷新了两份内容到内核缓冲区,所以导致最后打印两次到文件里。
先刷新到内核缓冲区然后再输出到文件,肯定比直接就在内核缓冲区然后写入到文件漫,所以write比另外俩快。
理解文件系统
我们之前讨论的都是被进程所打开的文件,那么操作系统中被打开的文件一般是少数,其他更多的文件是没有被打开的存在磁盘中的文件,接下来我们就来谈谈磁盘文件。
inode
磁盘文件由两部分组成:内容+属性。
文件的内容就是其中存放的数据,文件的的属性就是文件的大小、最近修改时间、权限等等,也成为元信息。
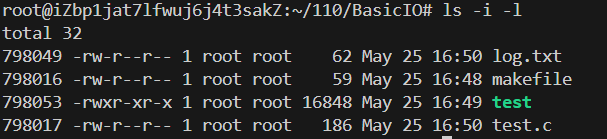
使用命令 ls -l 可以查看文件的元信息:

在 Linux 系统中,inode(索引节点) 是文件系统的核心数据结构,用于存储文件和目录的元信息(如权限、所有者、时间戳等),但不包含文件名和文件内容。
定义与作用
- inode 是 Index Node 的缩写,是 Linux 文件系统中存储文件元数据的数据结构。
- 每个文件和目录在文件系统中都有唯一的 inode 编号(inode number),用于标识和访问文件。
inode 包含以下关键信息:
- 文件类型(普通文件、目录、符号链接、设备文件等)。
- 权限信息(读 / 写 / 执行权限)。
- 所有者和所属组(文件的用户 ID 和组 ID)。
- 时间戳(创建时间、修改时间、访问时间)。
- 文件大小和使用的块数。
- 数据块指针(指向存储文件内容的数据块位置)。
- 文件链接数(硬链接数量)。
为什么inode不包含文件名?
分离元数据与目录结构
-
inode 专注存储文件元数据
inode 的核心功能是存储文件的元信息(如权限、所有者、数据块指针等),这些信息是文件内容相关的核心属性,与文件在目录中的位置无关。- 例如:一个文件被移动到不同目录时,文件名会变化,但 inode 及其元数据保持不变。
- 若 inode 存储文件名,当文件移动或重命名时,需要修改 inode 内容,这会增加磁盘 I/O 开销和实现复杂度。
-
目录作为 “文件名 - inode 映射表”
目录本质是一种特殊文件,其数据块中存储的是 文件名与 inode 编号的映射关系。- 例如:目录
/home/user中包含文件名file.txt,其对应 inode 编号为1234。当访问file.txt时,系统先通过目录找到 inode 编号,再通过 inode 读取文件内容。 - 这种分离设计使得文件名的修改(如重命名、移动)只需修改目录中的映射关系,而无需触及 inode,提升了灵活性和效率。
- 例如:目录
通过命令 ls -i -l查看文件的inode编号:
磁盘的概念
磁盘的概念:
磁盘是用电磁原理记录数据的存储介质,通常由涂有磁性物质的盘片和读写装置(驱动器)组成。
磁盘可以作为输出设备也可以作为输入设备。
磁盘的存储构成:
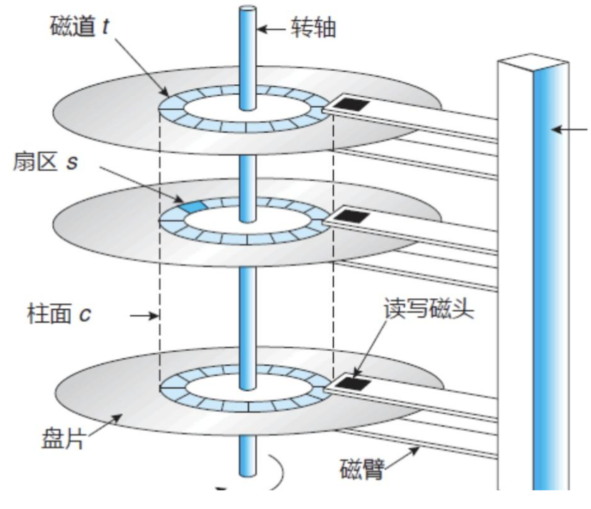
对其中重要的部分:盘片、柱面、磁道和扇区,进行讲解。
盘片:
每个盘片的上下两个面都有存储信息,一个磁盘通常是多个盘片堆叠在一起的。通常磁盘容量越大盘片越多。
工作原理
- 盘片通过马达驱动高速旋转(转速如 5400 RPM),磁头悬浮在盘片表面(距离约几纳米),通过改变磁性材料的极性来读写数据。
- 每个盘片的每个面对应一个独立的磁头,多个磁头通过磁头臂联动同步移动。
磁道:
- 磁道是盘片表面以盘片中心为圆心的同心圆环,是盘片格式化后的逻辑划分。
特点
- 磁道密度:单位长度内的磁道数量,外圈周长更长,但磁道密度(每英寸磁道数)与内圈相同。
- 用途:磁道是盘片上数据存储的一级逻辑单位,进一步划分为扇区。
扇区:
- 扇区是磁道上等角度划分的弧段,是机械硬盘最小的物理存储单元。
- 每个磁道被划分为若干扇区(如每个磁道有 512 个扇区),扇区之间以 间隙(Gap) 分隔,用于磁头识别扇区边界。
作用:
操作系统读写数据时,必须以扇区为单位(即使只需读写 1 字节,也需读取整个扇区)
柱面:
- 柱面是所有盘片上相同磁道号的磁道集合。例如,所有盘片的 0 磁道共同构成 “0 柱面”,所有盘片的 1 磁道构成 “1 柱面”,依此类推。
- 柱面是一个逻辑概念,用于简化磁头定位的计算(尤其是在分区时)
作用
- 在传统分区方式(如 MBR 分区)中,分区的边界通常按柱面划分,便于磁头在多个盘片的同一磁道上连续读写数据,减少寻道时间。
- 磁头定位逻辑:机械硬盘通过 “柱面号(磁道号)+ 磁头号(盘面号)+ 扇区号” 三维地址定位数据,其中:
- 柱面号:确定磁头臂移动的水平位置(对应磁道);
- 磁头号:确定读写哪个盘片的哪个面;
- 扇区号:确定在磁道上的具体存储位置。
磁盘的寻址方式
对磁盘进行读写操作是,一般通过以下方式找到数据:
1.确定数据在哪个盘面。
2.确定数据在那个柱面。
3.确定数据再哪个扇区。
磁盘分区与格式化
磁盘的逻辑结构是线性的存储结构。就像被卷起来的磁带,把磁带拉长后就是一个线性的结构,圆形的磁盘其实逻辑结构也是线性的
磁盘分区、
一个扇区的大小通常是512字节。我们以512G的磁盘举例,该磁盘就可以分为10亿多个 扇区。
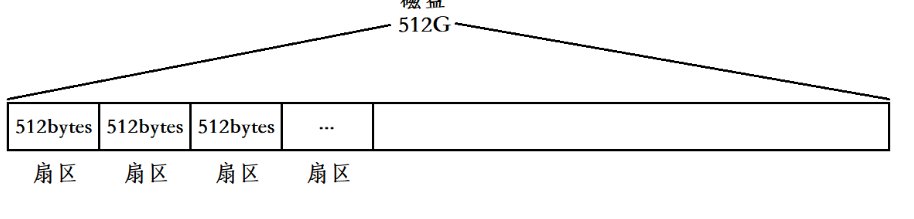
磁盘分区:
在Windows操作系统下磁盘的分区就是把一块磁盘分为为C盘和D盘等等,一旦划分成数个分区,不同的目录与文件就可以存储进不同的分区,分区越多,就可以将文件的性质区分得越细,按照更为细分的性质,存储在不同的地方以管理文件。
操作系统怎么分别不同的分区的?
通过一个分区的结构体:
struct partion
{int start;int end;
}start和end分别指向分区的开头和结尾。将所有分区放在数组里 struct partion part[],得到这样一个分区表,这样方便操作系统访问。
每个分区也有更详细的划分
EXT2文件系统的存储方案
EXT2(Second Extended File System)是 Linux 系统早期广泛使用的文件系统,其设计目标是高效、可靠地管理磁盘存储。EXT2 的存储方案基于块存储和索引节点(inode) 机制,将磁盘空间划分为多个逻辑单元进行管理
EXT2 文件系统的整体结构
EXT2 将磁盘划分为多个块组(Block Group),每个块组是文件系统的基本管理单元,包含独立的元数据和数据存储区域。
块组的核心组成部分:
-
引导块(Boot Block)
- 位于磁盘起始位置(第 0 块),存储引导程序(如 GRUB),用于系统启动。
- 仅第一个块组包含引导块,其他块组的引导块保留未用。
-
超级块(Super Block)
- 存储文件系统的全局元数据,例如:
- 块大小、inode 总数、块组数量、文件系统状态(是否挂载、是否干净)等。
- 每个块组都有超级块的副本,以提高可靠性(如第一个块组的超级块损坏时,可从其他块组恢复)。
- 存储文件系统的全局元数据,例如:
-
inode 位图(inode Bitmap)
- 每个比特位对应一个 inode,表示该 inode 是否已被占用(1 表示已用,0 表示空闲)。
-
块位图(Block Bitmap)
- 每个比特位对应一个数据块,表示该块是否已被占用(1 表示已用,0 表示空闲)。
-
inode 表(inode Table)
- 存储所有 inode 的集合,每个 inode 对应一个文件或目录的元数据(如权限、所有者、修改时间、数据块指针等)。
-
数据块(Data Blocks)
- 实际存储文件内容和目录数据的区域,按块大小(如 1KB、2KB、4KB)分配。
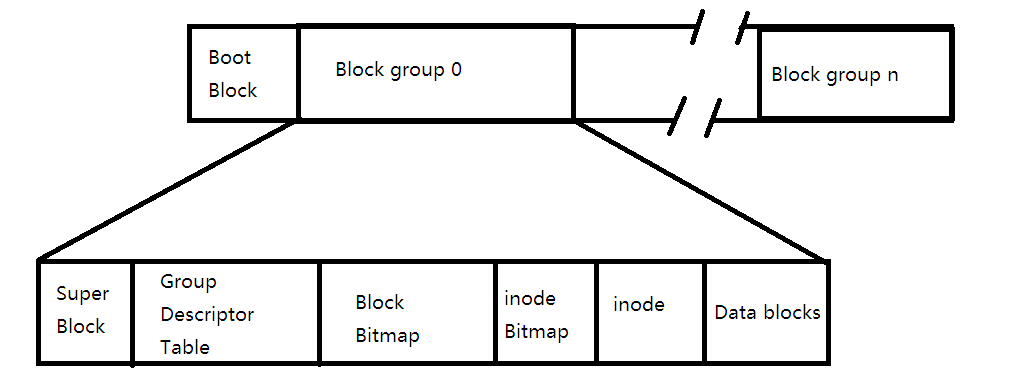
group descriptor table
描述的是整个分组的使用情况——比如我们block bitmap的起始地址, 使用了多少空间、inode bitmap的起始地址, 使用了多少空间。 inode table的起始地址、data block的数量, 空间块数量等等。 以及我们在分配inode的时候或者分配block的时候, 我们的inode或者data block的编号下一个要从哪里开始分配。这个也就解决了我们想要拿到块编号和inode编号来定位bitmap中比特位的问题。
这里之所以没有使用bitmap来直接计算block和inode的使用情况是因为计算的过程效率不如直接使用统计效率高。 所以这里直接使用了Group Descriptor Table。
注意:Boot Block启动块的大小是固定的,由格式化的时候确定的,并且不可以更改。
磁盘分区并格式化后,每个分区的inode个数就确定了。
操作系统的对磁盘的管理方式——分而治之
对于512G的磁盘分区后一个区256G,再把打分区分成小分区比如10G,管理好小分区就能管理好大分区,管理好大分区就能管理好整个磁盘,这就是分治的思想。
如何创建一个文件?
1、首先遍历inode位图,找到空闲的inode。
2、在inode表中找到对应位图inode,将文件元信息填入inode结构中。
3.将该文件的文件名和inode号建立映射,然后将文件名和inode指针添加到目录的数据块中。
如何理解对文件写入信息?
通过文件的inode编号找到对应的inode结构。
通过inode结构找到存储该文件内容的数据块,并将数据写入数据块。
若不存在数据块或申请的数据块已被写满,则通过遍历块位图的方式找到一个空闲的块号,并在数据区当中找到对应的空闲块,再将数据写入数据块,最后还需要建立数据块和inode结构的对应关系。
一个文件使用的数据块和inode结构的对应关系,是通过一个数组进行维护的,该数组一般可以存储15个元素,其中前12个元素分别对应该文件使用的12个数据块,剩余的三个元素分别是一级索引、二级索引和三级索引,当该文件使用数据块的个数超过12个时,可以用这三个索引进行数据块扩充。
如何删除一个文件?
1、将该文件的inode在inode位图中对应的位置置为无效。
2、将该文件申请过的数据块在块位图当中置为无效
该操作并不会直接把数据全部置0,只是告诉操作系统这块磁盘“空出来了”,所以在其他文件写入内容前,其实都是可以恢复删除的文件的。
为什么删除文件很快,拷贝文件却很慢?
删除的原理刚才讲过了,其实根本不需要真的去删除数据,所以很快,拷贝是实打实的要先创建文件,然后对文件写入,inode申请数据块申请都不能少最后还要写入所以慢。
如何理解目录
Linux下一切皆文件,所以目录也是文件,只不过目录里的数据是存储在该目录下的文件名其对应的inode映射关系。
如何查看目录的inode呢?
其实很简单,去上级目录查找就行了,一直往上到根目录,从根目录递归返回所有目录的inode。
软硬链接
软链接:
什么是软连接?
其实软链接很想Windows系统下的快捷方式。
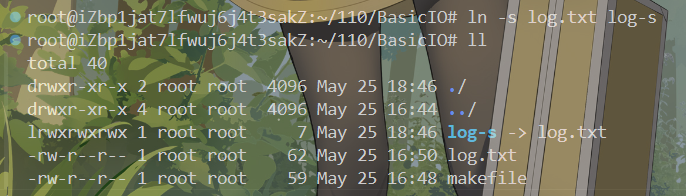 通过命令ln -s 目标文件 创建文件 的格式可以创建软链接
通过命令ln -s 目标文件 创建文件 的格式可以创建软链接

查看文件inode发现软链接的inode和被链接的文件不同,说明软链接时直接创建了一个新的文件,并且软链接文件的大小比原文件小得多。
软链接文件内容和被链接文件完全一样:

硬链接
用命令 ln 目标文件 创建文件 的格式创建硬链接:

可以看见硬链接创建的文件inode和被链接文件一模一样,并且文件大小也一样。
同时注意:两个文件的硬链接数都变成了2

既然硬链接文件没有自己的inode代表他就不是一个独立的文件,硬链接文件其实是被链接文件的别名,该文件有几个硬链接硬链接数就是几。
现在我们删除原文件log.txt.
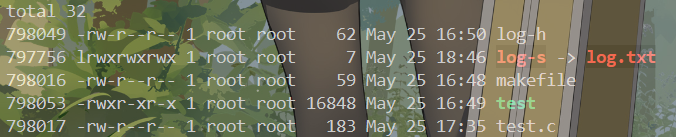
我们发现硬链接数变成了1,分别尝试查看软硬链接的内容:
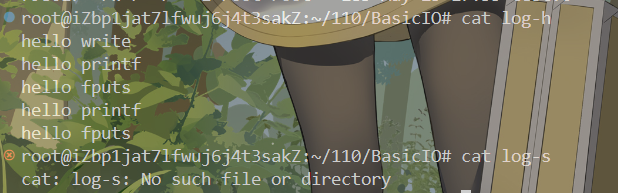
发现硬链接任然能够正常查看,但是软链接报错说找不到文件。
为什么硬链接创建的文件还能正常打开?
软链接打不开好理解,快捷方式指向的文件名都没了,没有文件名就找不到文件名对应的inode,所以就打不开。
那么硬链接呢?
其实硬链接的本质是在目录的数据块里增加一个文件名和inode的映射。
什么意思呢,一个inode可以有多个文件名和其创建映射,这些多出来的映射就是硬链接,我们删除一个文件,该inode就少一个映射,当链接inode的文件名全部删除也就是映射为0的时候文就被彻底删除了。对于文件来说,无论文件名怎么变,inode是创建文件的时候就固定好的。
对于软链接:
软链接作为快捷方式,拥有自己的inode,那么他的数据块里存的是什么内容呢?
软链接的数据块内存储的是他所链接的文件的路径。所以删掉软链接并不会影响被链接文件,删除被链接文件就会发生找不到文件的错误。
对于硬链接:

为什么文件夹的硬链接数是2?
这是因为每个目录文件下都有一个“.”目录文件

这个.就是当前目录本身的硬链接,我们可以查看inode确认:
![]()
![]()
我们继续观察还可以看到目录里还有一个".."文件夹,这个文件夹是上级目录
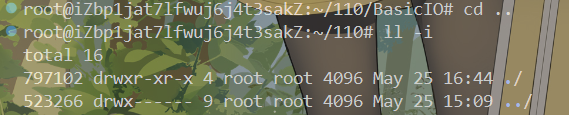
通过cd .. 操作进入上级目录可以发现上级目录的inode和..文件的inode相同,他的硬链接数是4
那么是哪里来的4个呢?
首先目录本身不说了,其次是自己目录下的.文件,还有两个硬链接是什么呢,就是其目录下的目录里的..文件。
也就是说一个目录的硬链接数-2(自己和.文件)剩下的数就是该目录下保存的目录数量!
注意:Linux不允许用户创建目录的硬链接,那我问你,这个 . 和..文件不就是目录的硬链接吗?
我只能回答系统可以任性...
那么为什么不让用户创建目录的硬链接呢?
- 无限递归遍历:当系统遍历目录时(如执行
ls、find命令),循环链接会使程序陷入死循环,无法终止,甚至耗尽系统资源。 - 元数据混乱:目录的硬链接会增加其 “硬链接计数”(
inode中的i_nlink字段),但内核难以正确维护循环链接中的目录层次关系,可能导致文件系统元数据损坏