分布式缓存:BASE理论实践指南
文章目录
- 缓存全景图
- Pre
- 一、传统 CAP 的突破与 Brewer 的修正
- 二、分区感知与处理
- 三、BASE 理论与实践
- 四、数据一致性应对方案概览
- 五、分布式事务:2PC/3PC 与共识算法
- 六、主从复制与业务层消息总线
- 七、多区域多活案例

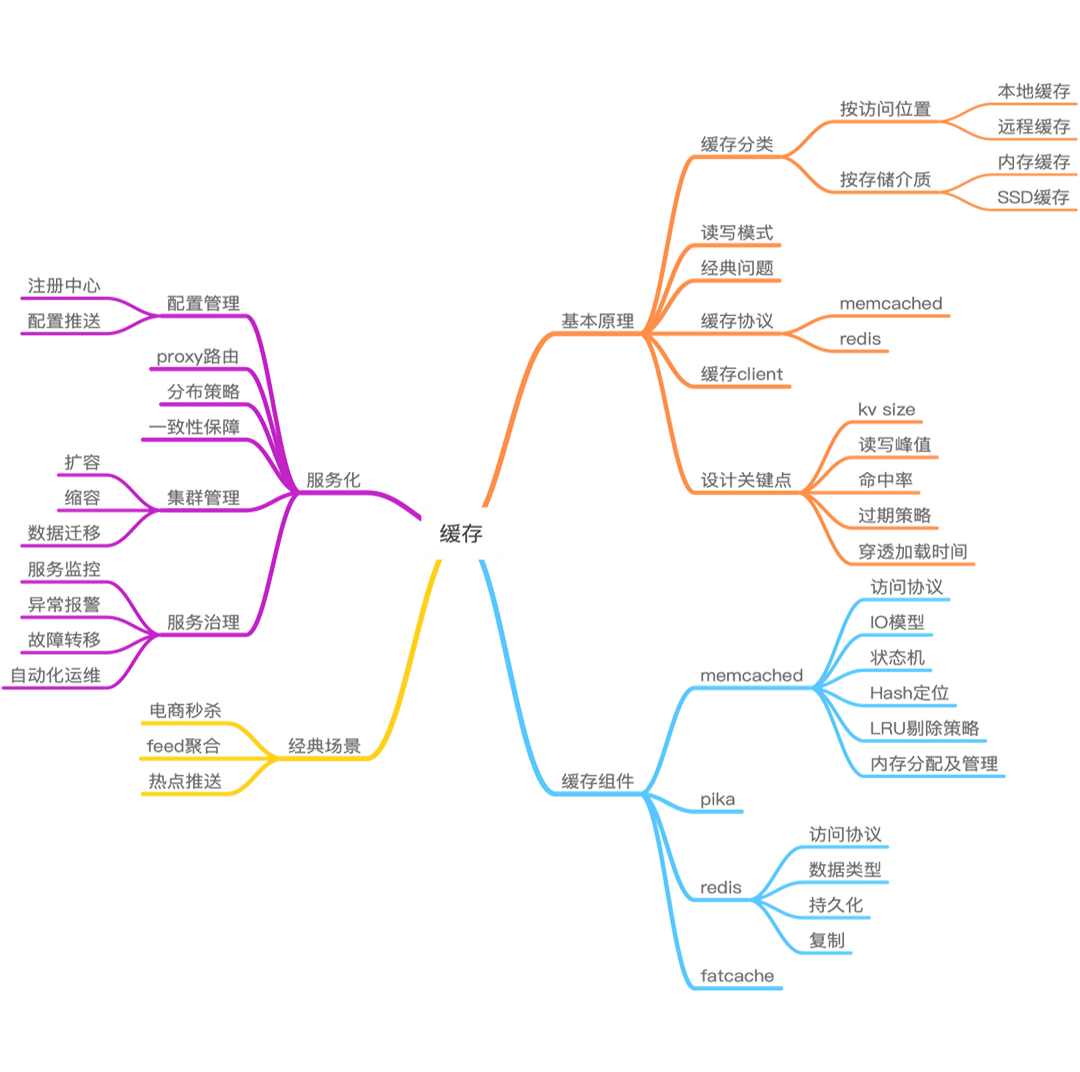
缓存全景图
Pre
分布式缓存:缓存设计三大核心思想
分布式缓存:缓存的三种读写模式及分类
分布式缓存:缓存架构设计的“四步走”方法
分布式缓存:缓存设计中的 7 大经典问题_缓存失效、缓存穿透、缓存雪崩
分布式缓存:缓存设计中的 7 大经典问题_数据不一致与数据并发竞争
分布式缓存:缓存设计中的 7 大经典问题_Hot Key和Big Key
分布式缓存:三万字详解Redis
分布式缓存:ZSET → MGET 跨槽(cross‐slot)/ 并发 GET解决思路
分布式缓存:CAP 理论在实践中的误区与思考
一、传统 CAP 的突破与 Brewer 的修正
在全球多云、多区域部署场景下,传统“CAP 三选二”过于理想化。2012 年,Brewer 对 CAP 理论提出修正:
- CAP 三要素并非非黑即白,而是在一致性、可用性与分区容忍度各自存在宽度,如:强一致 vs. 最终一致、读写可用的粒度等;
- 延迟即分区,任何超时都可视作短暂分区;
- 三要素可动态切换,不同业务、模块乃至同一操作的不同阶段,可灵活在 C↔A 之间切换。
Brewer 强调,应结合业务 SLA、故障概率、部署拓扑来优化分布式架构,而非简单三选二。
二、分区感知与处理
要在设计时充分考虑分区的检测与处置,可分三步走:
-
分区感知:通过心跳探测、服务状态汇报、关键时点预警、历史数据模型预测等及时发现节点或链路异常。
-
分区模式下业务降级:
- 短延迟场景:内存缓冲或消息队列先行,部分请求阻塞等待;
- 长时分区:下线非核心功能,只保留关键路径;
- 混合策略:对敏感服务阻塞,对可降级功能返回老数据或降级页面。
-
故障恢复与补偿:
- 利用消息队列(记录变更、幂等重放)或位点同步(记录最后同步点、续传);
- 异地快照比对与合并;
- 全量扫描+冲突解算策略保证最终一致性。
三、BASE 理论与实践
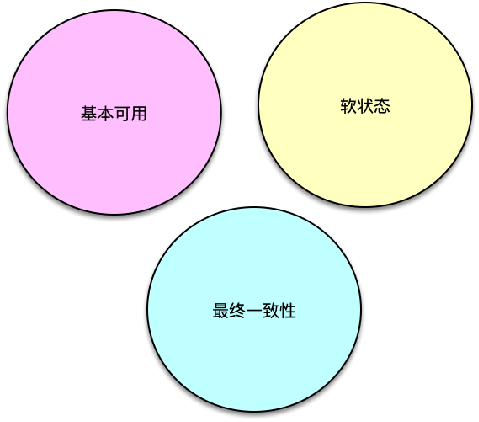
BASE 作为 CAP 的扩展,更契合大中型互联网系统:
- Basically Available(基本可用):允许部分 SLA 损失,通过降级页面、延迟响应、功能下线保证核心可用;
- Soft state(软状态):放宽同步要求,节点可在不一致中继续服务;
- Eventual consistency(最终一致性):故障恢复后再行同步,最终各副本收敛。
实践要点:
- 优先保证核心用户体验,并对延迟容忍度进行分级;
- 在降级期间,将业务流量导流、资源集中,确保核心路径可用;
- 恢复后以异步补偿、幂等重放等方式修复数据。
四、数据一致性应对方案概览
分布式系统常见一致性技术:
- 分布式事务(2PC/3PC、Paxos/Raft 等)——强一致;
- 主从复制(异步/半同步)——读写分离、弱一致;
- 业务层消息总线(Push/Pull)——异步同步、最终一致。
五、分布式事务:2PC/3PC 与共识算法
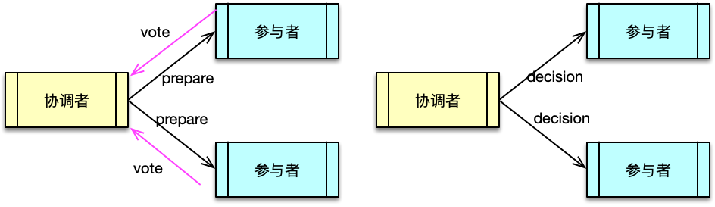
- 两阶段提交(2PC):协调者→参与者投票→提交/回滚,易阻塞;
- 三阶段提交(3PC):在 2PC 基础上拆分第一阶段并引入超时,降低阻塞风险;
- Paxos/Raft/Zab:多数派决策,写入需过半数,读可从多数派或指定节点读取,支持领导者或去中心化选举。
六、主从复制与业务层消息总线
- 主从复制:数据库层面保证一致,异步更新可优化性能;
- 消息总线:Pull 模式更易掌控一致性,Push+业务端合并可提升灵活性。
在多活场景中,通常采用主从复制做“最终落地”,而用消息队列做缓存更新或业务异步同步。
七、多区域多活案例
以多区缓存更新为例:
- 用户写操作封装消息写入本地 MQ;
- MQ 本地消费更新缓存/DB,同时异步推向异地 MQ;
- 分区时本地先行,异地积压;
- 恢复后异地消费,合并更新;
- 缓存过期策略与主从 DB 强一致保障最终一致。
此方案兼顾了局部高可用与全局最终一致。
