在Visual Studio中进行cuda编程
首先下载与CUDA Toolkit匹配的Visual Studio版本
比如我的CUDA Toolkit版本是12.6,那么我可以使用2022的Visual Studio。
查看Toolkit版本
nvcc -V配置
ok,让我们开始Visual Studio的nvcc编译器配置
参考例文https://github.com/apachecn/succinctly-zh/blob/master/docs/cuda/02.md
(1)头文件包含
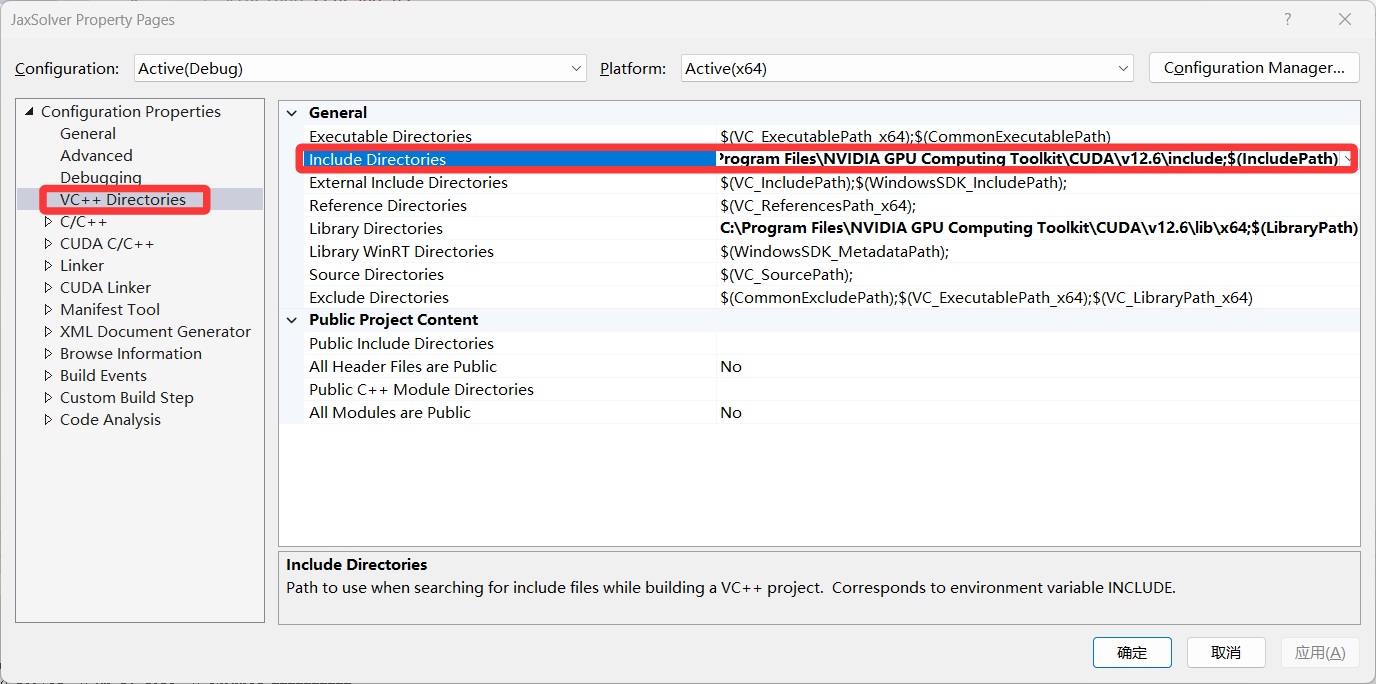
这里的路径可以使用如下命令查看
where nvcc(2)语法颜色
这样可将CU文件的语法颜色同cpp文件
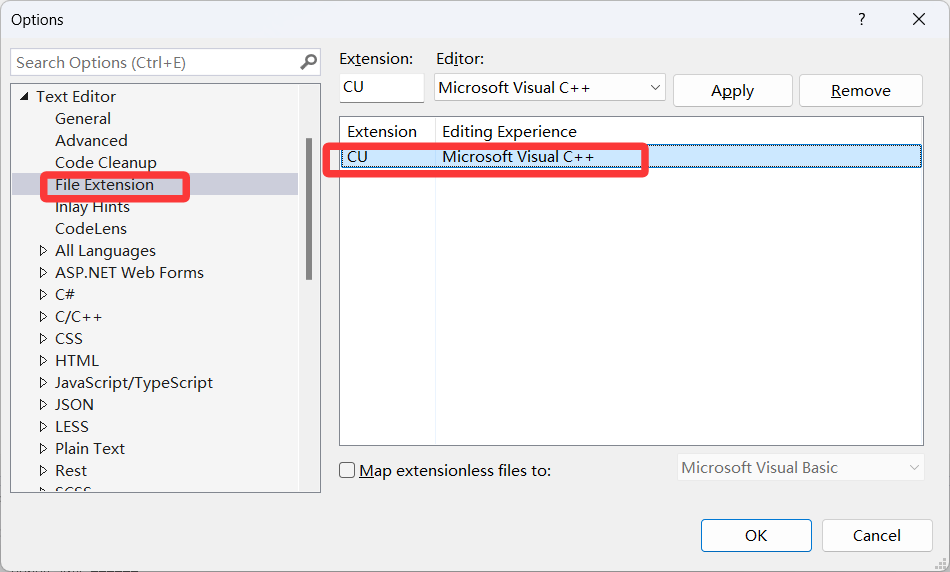
测试
文件结构
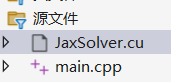
//main.cppextern "C" void run_CUDA();int main() {run_CUDA();return 0;
}//jaxsolver.cu#include <iostream>
#include <cuda.h> // Main CUDA header
#include <curand_kernel.h>
#include <curand.h>#define N 256__global__ void VecAdd(float* A, float* B, float* C) {int i = threadIdx.x;if (i < N) {C[i] = A[i] + B[i];}
}extern "C" int run_CUDA() {float* h_A, * h_B, * h_C;float* d_A, * d_B, * d_C;size_t size = N * sizeof(float);// 分配主机内存h_A = (float*)malloc(size);h_B = (float*)malloc(size);h_C = (float*)malloc(size);// 初始化主机数据for (int i = 0; i < N; i++) {h_A[i] = i;h_B[i] = i * 2;}// 分配设备内存cudaMalloc((void**)&d_A, size);cudaMalloc((void**)&d_B, size);cudaMalloc((void**)&d_C, size);// 拷贝数据到设备cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);// 调用核函数VecAdd <<<1, N >>> (d_A, d_B, d_C);// 拷贝结果回主机cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);// 输出部分结果for (int i = 0; i < 10; i++) {std::cout << h_A[i] << " + " << h_B[i] << " = " << h_C[i] << std::endl;}// 清理cudaFree(d_A);cudaFree(d_B);cudaFree(d_C);free(h_A);free(h_B);free(h_C);return 0;
}会显示<<<>>>表达 不能识别,但是可以编译
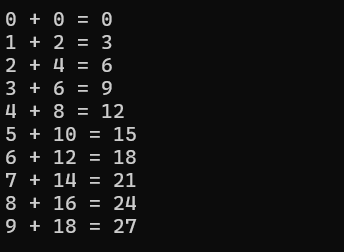
如果不使用extern "C",而是直接使用#include "JaxSolver.cu"中的函数,Visual Studio的C++的编译器会编译cu导致报错,这时会引发错误。
但当我们使用头文件,就不会编译出错误:
将文件结构修改为
//cudaInterface.hint run_CUDA();
//main.cpp#include "cudaInterface.h"int main() {run_CUDA();return 0;
}这样也可以成功进行编译
那么为什么可以使用头文件的方式进行编译,而不使用头文件则不可行呢?这就要从编译的四个流程讲起:

对于本文的例子,不使用头文件,在预处理阶段会把include<.cu>的内容直接插入cpp文件,然后接下来进入编译阶段的时候,由于使用的是C++的编译器,CUDA语法是不存在的,所以会产生错误而导致编译过程不会进行。
而如果使用了头文件,在预处理阶段插入的是int run_CUDA();,在编译阶段,并没有C++编译器所不能“识别”的语法,编译和汇编的过程就能顺利执行。在链接阶段,nvcc编译器所编译出的.o会与C++编译的共同形成可执行文件。
下面写一下简单写一下nvcc编译的原理
nvcc编译原理
对于整个的编译过程而言,.cu文件会使用nvcc编译器编译,.cpp文件会使用cpp的编译器编译
对于nvcc编译的过程而言,这个编译器到底干了一件什么事?
nvcc编译器本质是一个元编译器,意思是管理各种编译器的编译器。原理是:将CUDA的特定函数,如Kernel函数,也就是本例中的VecAdd,通过__global__ 等关键字“识别”,使用ptxas编译器编译,而其他不能识别出来的则交给系统的C++编译器来编译。
Kernel函数与其他函数不同的是,它使用GPU执行该函数。
本例中Kernel函数的索引int i = threadIdx.x; 形成1个Block中的N个线程 <<<1, N >>>,该Block通过CUDA调度器调度到硬件层。

也可以形成多个Block,有什么需要注意的,这就不再展开。
多说一句
nvcc使用的是C++编译器,而不是C编译器,所以cpp文件可以通过头文件调用cu文件,而c文件不能调用。
所以,cu文件也具备C++的性质,比如函数的重载。众所周知,C语言是不能进行函数重载的,原因就在于C的编译器在链接过程中,不会更改函数的名称,而C++的编译器会更改函数的名称,这就允许了函数重载。
我使用的测试如下:
//JaxSolver.cpp#include <iostream>
#include <cuda.h> // Main CUDA header
#include <curand_kernel.h>
#include <curand.h>#define N 256__global__ void VecAdd(float* A, float* B, float* C) {int i = threadIdx.x;if (i < N) {C[i] = A[i] + B[i];}
}__global__ void VecAdd(float* A, float* C) {int i = threadIdx.x;if (i < N) {C[i] = A[i];}
}//int run_CUDA() {
int run_CUDA() {float* h_A, * h_B, * h_C;float* d_A, * d_B, * d_C;size_t size = N * sizeof(float);// 分配主机内存h_A = (float*)malloc(size);h_B = (float*)malloc(size);h_C = (float*)malloc(size);// 初始化主机数据float j = 0;for (int i = 0; i < N; i++,j++) {h_A[i] = j;h_B[i] = j * 2;}// 分配设备内存cudaMalloc((void**)&d_A, size);cudaMalloc((void**)&d_B, size);cudaMalloc((void**)&d_C, size);// 拷贝数据到设备cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);// 调用核函数VecAdd <<<1, N >>> (d_A, d_B, d_C);// 拷贝结果回主机cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);// 输出部分结果for (int i = 0; i < 10; i++) {std::cout << h_A[i] << " + " << h_B[i] << " = " << h_C[i] << std::endl;}VecAdd << <1, N >> > (d_A, d_C);// 拷贝结果回主机cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);// 输出部分结果for (int i = 0; i < 10; i++) {std::cout << h_A[i] <<" = " << h_C[i] << std::endl;}// 清理cudaFree(d_A);cudaFree(d_B);cudaFree(d_C);free(h_A);free(h_B);free(h_C);return 0;
}欢迎交流!