深度学习损失“三位一体”——从 Fisher 的最大似然到 Shannon 的交叉熵再到 KL 散度,并走进 PET·P-Tuning微调·知识蒸馏的实战
一页速览:
1912 Fisher 用最大似然把「让数据出现概率最高」变成参数学习;
1948 Shannon 把交叉熵解释成「最短平均编码长度」;
1951 Kullback-Leibler 用相对熵量化「多余信息」。
三条历史线落到今天深度学习同一个损失——交叉熵。
也就是我们常用的:CrossEntropyLoss 函数
下面按 时间 → 问题 → 数学 → 代码 的顺序拆解,并演示它们在二/多分类、大模型知识蒸馏(含温度 T)和 PET 软模板大模型微调里的角色。
1 三个名字、三个年代、一个目标
| 年代 | 人物 | 术语 | 初衷 | 关键论文 |
|---|---|---|---|---|
| 1912→1922 | R. A. Fisher | 最大似然 (MLE) | 用参数让训练数据出现的联合概率最大 | “On the mathematical foundations…” 1922 |
| 1948 | C. E. Shannon | 交叉熵 H(p,q) | 用 预测分布 q 压缩 真实分布 p 的平均比特数 | 《A Mathematical Theory of Communication》 |
| 1951 | S. Kullback & R. Leibler | KL 散度 DKL | 衡量 p→q 需要的额外信息量 | 《On Information and Sufficiency》 |
表示交叉熵, MLE 表示最大似然,
表示KL散度
一句话概览
最大似然(MLE)、交叉熵 H(p,q) 与 KL 散度 其实是同一指标在三位不同学者手中的“别名”。
1912-1922 Fisher 用它做参数估计;
1948 Shannon 用它算最短平均比特;
1951 Kullback-Leibler 把它写成“额外信息”。
由于 而熵 H(p) 只跟数据真分布有关、与模型参数毫无关系,最小 KL ⇔ 最小交叉熵 ⇔ 最大似然。


2 二/多分类:把公式算一遍
| 场景 | 激活 | 损失公式 | PyTorch |
|---|---|---|---|
| 二分类 | Sigmoid | -[y log ŷ+(1-y) log(1-ŷ)] | BCEWithLogitsLoss |
| 多分类 C≥2 | Softmax | -log qk | CrossEntropyLoss |
2.1 二分类示例
logits = torch.tensor([1.386, -0.847, 0.405]) # ≈[0.8,0.3,0.6]
labels = torch.tensor([1., 0., 1.])
loss = torch.nn.BCEWithLogitsLoss()(logits, labels) # ≈1.062.2 多分类示例:三分类为例子
logits = torch.tensor([[ 2.3, 0.1,-1.2],[ 0.2, 1.4, 0.0],[-0.5, 0.3, 2.1]])
labels = torch.tensor([0,1,2])
loss = torch.nn.CrossEntropyLoss()(logits, labels)C=2 时 Softmax+CCE 可化简为 Sigmoid+BCE,数学上等价 。
3 知识蒸馏:KL / 交叉熵 + 温度 T
核心损失
温度 T>1 让 logits 变平滑,更易传递「软知识」 。
为什么要温度? 把 logits / T (T>1) 能“压平”概率,使学生更容易学习细粒度信息

T, alpha = 4.0, 0.7
for x,y in loader:with torch.no_grad():p_soft = torch.softmax(teacher(x)/T, -1)q_logits = student(x)/Tq_log = torch.log_softmax(q_logits, -1)loss_kd = (p_soft*(p_soft.log()-q_log)).sum(1).mean()*T*T # KL 项loss_ce = torch.nn.CrossEntropyLoss()(q_logits*T, y) # 硬标签loss = alpha*loss_ce + (1-alpha)*loss_kdloss.backward(); opt.step()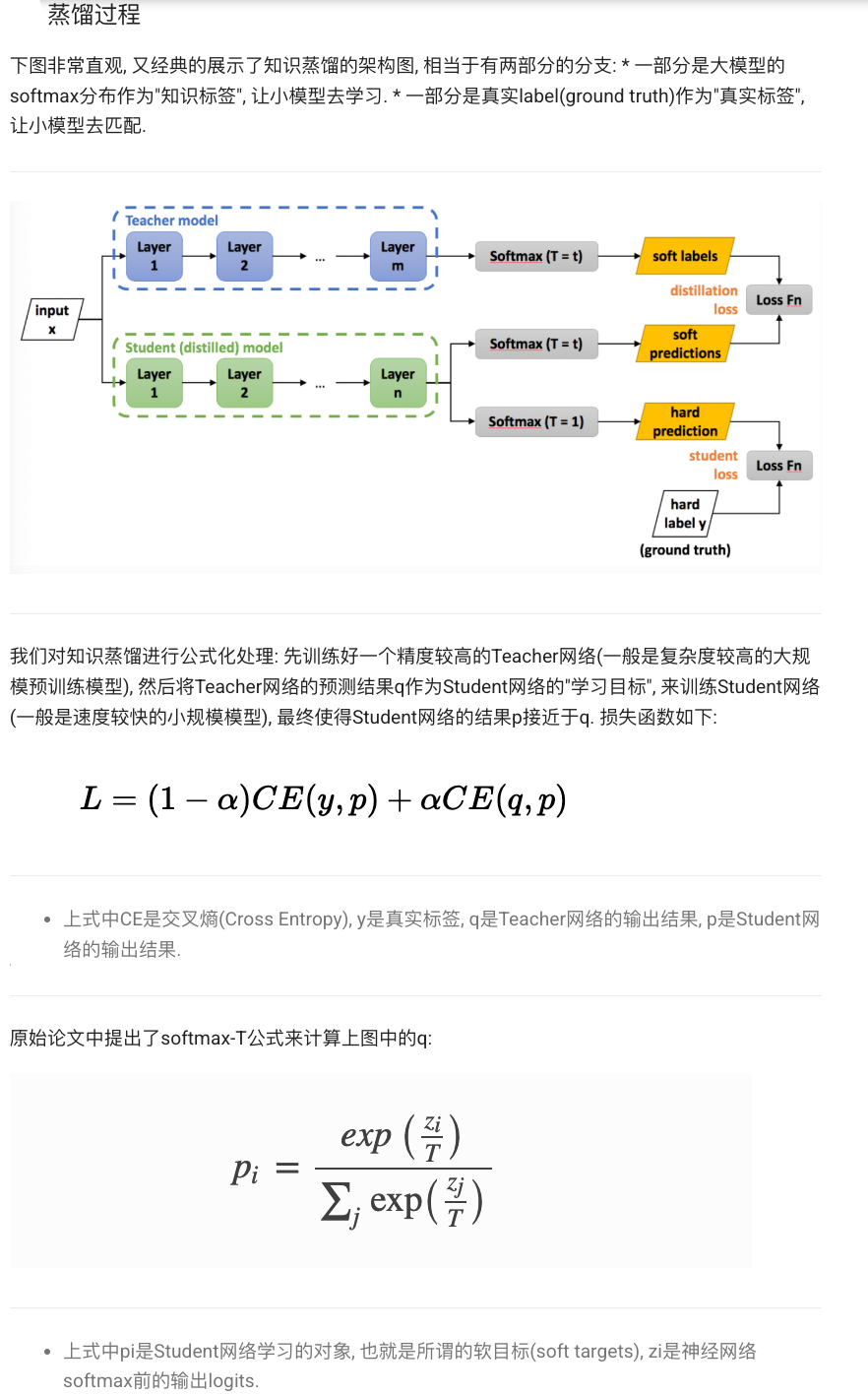
4 PET微调:把分类任务改成「完形填空」
说人话,就是自己弄一个[mask] ----》 映射表,这样以bert 为案例的预测出来的 【mask】通过映射表,就是我们的真实分类了,所以我们在微调的时候,把数据弄成原始句子 ➕ 【mask】模式,真实分类给进去,然后微调bert 模型,训练好的这个就是我们的老师,这个老师,去给其他样本进行打软标签, 也就是提供软标签这个,用于指导我们的另一个模型去拟合或者接近老师的答案。
(PET 产生的原因就是,因为我们的bert 在预训练的时候,就是MLM任务,我们直接把任务改成这种,就不用拟合或者说训练太久,即可达到好的效果。)
-
Stage-A:5-10 条标注 + Pattern T + Verbalizer V → 微调 K 个 BERT-MLM(填 [MASK],损失=交叉熵)。
-
Stage-B:老师集成给未标注文本打软标签
。
-
Stage-C:把
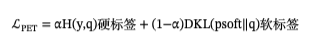
PVP 组件:Pattern T + Verbalizer V
例:"Review: <x>. Sentiment: [MASK]." ,terrible↔0,great↔1
Step-A 少量标注 → 微调 K 个教师 MLM
-
损失:CrossEntropyLoss 填 [MASK](即交叉熵)
Step-B 教师集成 → 大量未标注文本生成软标签 psoft
Step-C 学生分类器
# --- Stage-A: 训练 K 个教师 MLM ---
for T in patterns:teacher = BertForMaskedLM.from_pretrained('bert-base')finetune_mlm(teacher, few_shot_data, T, verbalizer) # 交叉熵填空teachers.append(teacher)# --- Stage-B: 生成软标签 ---
soft = []
for x in unlabeled:logits = [mask_logits(m,x,T,V) for m,T in zip(teachers,patterns)]soft.append(torch.mean(torch.stack(logits),0).softmax(-1)) # p_soft# --- Stage-C: 学生分类器 ---
student = BertForSequenceClassification.from_pretrained('bert-base')
for x, p_soft in zip(unlabeled, soft):q = student(x).log_softmax(-1)kl = (p_soft * (p_soft.log() - q)).sum()loss = kl # α=0,可选加硬标签交叉熵loss.backward(); opt.step()用 KL/交叉熵把学生分布 qθ 贴到教师软标签 psoft 上 。
5 2025 Prompt-Tuning ,lora 家族选型
| 方法 | 额外参数 | 优点 | 缺点 | 推荐场景 |
|---|---|---|---|---|
| Prompt-Tuning | 0 | 零成本 PoC | 方差大,需≥100B 模型 | 原型验证 |
| PET | 全量+集成 | 1-10 样本即可 | 两阶段工程复杂 | 极少标签 |
| P-Tuning v2 | 0.1-3 % | 稳定通用 | 需提示编码器 | NLU few-shot |
| PPT | 同上 + 预训 | 最优精度 | 预训练成本高 | 少样本高精度 |
| LoRA / QLoRA | 0.05-1 % | 工业主流 | 需改 Linear | 任务量产 |
一般都是用 P-Tuning v2 和 LoRA 这几个
参考文献
-
Fisher R. A., Maximum Likelihood (1922)
-
Shannon C. E., A Mathematical Theory of Communication (1948)
-
Kullback S., Leibler R., On Information and Sufficiency (1951)
-
PyTorch Docs — BCEWithLogitsLoss
-
PyTorch Docs — CrossEntropyLoss
-
Schick T., Schütze H., Pattern-Exploiting Training (EACL 2021)
-
Hinton G. et al., Distilling the Knowledge… (2015)
-
Liu X. et al., GPT Understands, Too — P-Tuning v2 (2021)
-
Gu P. et al., PPT: Pre-trained Prompt Tuning (ACL 2022)
-
Stats.SE 讨论 BCE vs CCE
-
KD 温度研究综述
一句话总结
Fisher 说:让样本出现概率最大;Shannon 说:把平均比特压到最小;Kullback-Leibler 说:去掉无用信息。
三句话 = 一个训练目标:把交叉熵降到最低。 无论你在训练模型,还是蒸馏学生,还是用一个小小 Prompt 让大模型「开窍」,它始终是深度学习的黄金公式。