基于音频Transformer与动作单元的多模态情绪识别算法设计与实现(在RAVDESS数据集上的应用)
摘要:情感识别技术在医学、自动驾驶等多个领域的广泛应用,正吸引着研究界的持续关注。本研究提出了一种融合语音情感识别(SER)与面部情感识别(FER)的自动情绪识别系统。在SER方面,我们采用两种迁移学习技术评估了预训练的xlsr-Wav2Vec2.0转换器:嵌入提取和微调。实验结果显示,通过附加多层感知器进行整体微调时取得最佳准确率,验证了迁移学习相较于从头训练更具鲁棒性,且预训练知识有助于任务适应。在FER方面,通过提取视频动作单元对比静态模型与顺序模型的性能差异,发现两者差异较小。错误分析表明,视觉系统可通过高情绪负载帧检测器进行优化,这为视频情感识别方法研究提供了新思路。最终,采用晚期融合策略将两种模态结合后,在RAVDESS数据集的八种情绪分类任务中取得了86.70%的受试者5-CV评估准确率。研究证实,两种模态携带互补的情绪信息,其有效结合可显著提升系统性能。
1、多模态情绪识别
根据 Huang 等人 [58] 的综述,合并模式有三种基本方式:早期融合、关节融合和晚期融合。
早期融合包括组合从各种预训练模型中提取的特征或模态。在训练最终模型之前,这些属性被分组到单个向量中。
Huang等[58]将关节融合定义为“将从神经网络中间层学习到的特征表示与来自其他模态的特征作为最终模型的输入连接起来的过程。与早期融合相比,关键区别在于,在训练过程中,损失会传播回特征提取神经网络,从而为每次训练迭代创建更好的特征表示。
另一方面,晚期融合包括两个阶段:第一阶段训练与模态一样多的模型,第二阶段,最终模型接收第一阶段得出的联合后验以执行确定性分类。这些程序之间的界限有时可能很模糊,因为融合策略可能在训练期间的任何时间发生[59]。
早期融合的优势在于检测特征相关性以消除冗余信息并学习不同模态之间的交互。然而,由于采样率不同,在对齐来自许多模态的数据时可能会出现同步问题,当组合嵌入是高维时也会遇到困难[60,61]。这种方法包括一些工作,例如邓等人[62]提出的方法。他们收集了来自 T5 transformer 文本模型和 VGG、YAMNET 和 TRILL 听觉模型的代表性特征;然后,将这些嵌入连接并引入到共注意力 transformer 模型中,该模型增强了每个嵌入的最相关槽以产生融合表示,然后用于训练最终分类器。这两种模式的融合提高了 IEMOCAP 和 SAVEEE 两个数据集中情绪识别器的准确性。
作为早期融合策略的替代方案,在决策层面存在融合或晚期融合。Sun等[60]在以前的任务中利用了从预先训练模型中获取的特征来训练一个双LSTM模型,该模型为他们的三种使用模态(音频、视频和文本)中的每一种都有一个注意力层,以识别唤醒和效价。然后,通过采用晚期融合技术对 bi-LSTM 模型的后验进行整合,以学习最终的 LSTM 模型。
由于晚期融合策略在类似任务上的简化和充分性能[60,63],我们决定在每种模态(听觉或视觉)上应用每个训练模型的后验组合。后来,我们用生成的输出对多项式 Logistic 回归进行馈送。这个过程也可以理解为一种集成方法:我们自己组装每个模型学到的后验,然后我们训练一个多项式 logistic 回归模型来解决单个任务,即情绪识别。
我们的框架由两个系统组成:语音情感识别器和面部情感识别器。我们将这两个系统的结果与晚期融合策略相结合,如图 1 所示
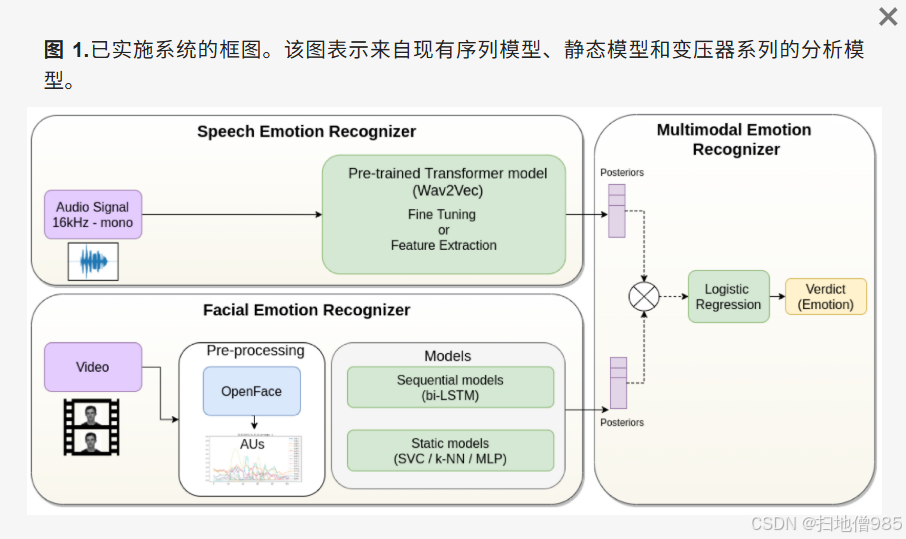
2、数据集和评估
在我们的分析中,我们使用了 RAVDESS [20]。此数据集包括 7356 个带有行为情感内容的录音。档案平均分为三种类型的内容(完整的 AV、纯视频和纯音频)和两个人声通道(语音和歌曲)。
除了中性情绪(仅包括常规强度)外,其余的表情都是在两个级别的情绪唤醒产生的:常规和强烈。每个文件都包含一个参与者,代表以下八种情绪之一:平静、中立、快乐、悲伤、愤怒、恐惧、惊讶和厌恶。
我们只在实验中使用了完整的 AV 材料和语音通道,因为我们对语音而不是歌曲的视听情感识别感兴趣。此选择将文件数量限制为 1440 个视频,最大和最小持续时间分别为 5.31 和 2.99 秒。语料库有 24 名演员,以性别平衡的方式分布,他们用中性的北美口音说词汇匹配的陈述。这种设置适用于研究与情绪相关的副语言学,隔离词汇并减少文化可能引起的情绪表达偏见。在其优点中,它还具有每种情绪的成比例文件数,这避免了使用非平衡数据训练算法所衍生的问题。此外,RAVDEESS 是研究界的参考数据集,用于多项工作 [33,64,65]。
尽管进行了简化,但该数据集对情绪识别构成了重大障碍,甚至对人类也是如此。仅使用语音刺激实现的人类准确率为 67%,而使用视觉信息时,这一准确率仅增加到 75%。
3、特征提取
对于 SER 模型,我们使用了预先训练的 xlsr-Wav2Vec2.0 [66] 模型。该模型具有 Wav2Vec2.0 转换器的原始架构 [67]。与 Wav2Vec2.0 不同,xlsr 版本使用 53 种不同的语言进行了训练,在语音转文本方面达到了最先进的性能。此外,xlsr-Wav2Vec2.0 是一个转换器,以自我监督的方式从数百万个原始音频数据中训练出来。在对未标记数据进行预训练后,该模型对标记数据进行了微调,以适应不同性质的下游语音识别任务。
正如 Baevski 等人在 [67] 中描述的那样,该模型由三个不同的部分组成(也出现在图 2 中):特征编码器、变压器和量化模块。
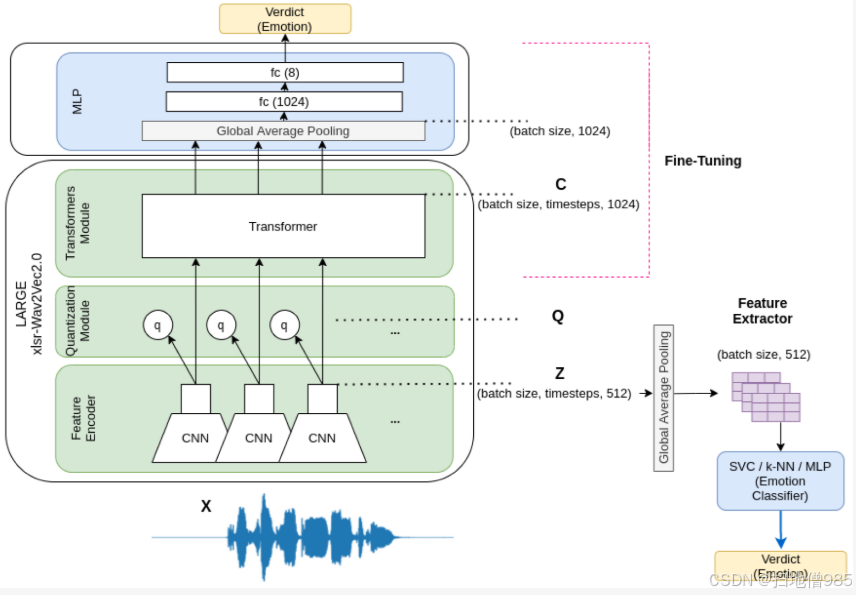
4、微调
作为嵌入提取的替代方案并重用以前网络的专业知识,我们还对预训练的 xlsr-Wav2Vec2.0 进行了微调。通过微调基础预训练模型,我们解冻了它的一些顶层,并联合训练了新添加的分类器层和基础模型的最后层。这项技术使我们能够“微调”基础模型中的高阶特征表示,使它们适应新的特定任务,同时保持从数百万个数据样本的训练中获得的知识。
在我们的例子中,要解决的新任务是语音情感识别。为了适应 xlsr-Wav2Vec2.0 架构,我们在 transformer 模块的输出之上引入了全局平均池化。该层将上下文表示 C 的所有时间步折叠成一个 1024 维向量。这些平均嵌入被传递给一个两层的 MLP,分别有 1024 个和 8 个神经元,堆叠在池化层的顶部。
在微调过程中,除了特征编码器的卷积层外,所有层都进行了调整。该模块的层保持冻结状态,因为它们包含来自大量数据的嵌入式知识,并且足够健壮,无需适应即可使用。
在图 2 中,我们展示了一个图表,阐明了特征提取器和微调策略。在“LARGE xlsr-Wav2Vec2.0”的方块下,我们可以看到模型具有的绿色默认层。从特征编码器阶段的输出中,我们提取了馈送到静态模型(SVM、k-NN 和 MLP)的嵌入。关于微调版本,粉红色的线条表示我们使用 RAVDESS 重新训练的层。在蓝色框内,我们还可以识别 transformer 顶部添加的层,用于执行情感分类。
5、静态模型与顺序模型
获得每个视频帧的 AU 后,我们需要完成一个预处理步骤,以使输入格式适应特定模型,无论是静态的还是顺序的。为了评估静态模型,我们计算了从每个视频中提取的 AU 序列的平均向量,将所有时间步骤折叠成一个柔化向量。在这个阶段,我们测试了两种策略,对每列的 AU 在 0-1 范围内进行归一化,或者不采用任何归一化。在使 AU 适应静态问题后,我们将样本引入不同的模型: SVC 、 k-NN 分类器和 MLP 。
这种方法作为我们的基准,有两个主要好处:第一个是简单,第二个是“平均效果”。为了说明这一点,假设一个视频在几个帧上与原型情绪有偏差,因为视频上的人闭上了眼睛。由于平均池化,只要所有其他帧都封装了正确的情感,这些帧就不会严重影响最终识别。然而,这种方法也有一个明显的缺点:顺序数据可能表现出自然的时间顺序。然而,这种单个帧级特征的启发式聚合忽略了时间顺序,这反过来又可能导致次优的判别能力。作为静态模型的替代方案,我们采用了顺序模型,假设帧的顺序中有相关信息,这通常是有效的,尤其是对于顺序数据。

关于序列模型的架构,它由几个双向 LSTM 层组成,具有深度的自我注意机制,类似于 [72] 中提出的。在图 4 中,显示了所采用的 Bi-LSTM 的结构图片。
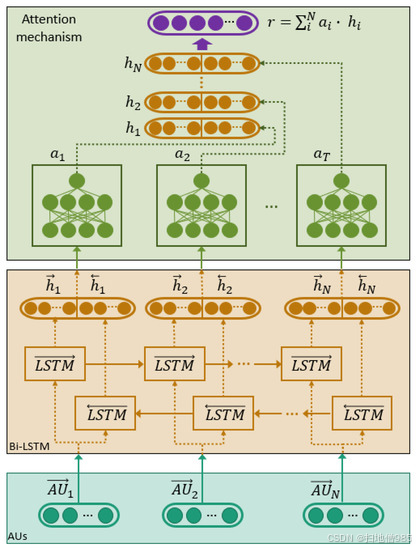

6、语音情感识别器设置
7、 面部情感识别器设置
Table 1. Quantitative evaluation of the different strategies on speech emotion recognition. In bold, the best models per TL strategy.
| TL Strategy | Inputs | Models | Hyper- Parameters | Accuracy ± 95% CI |
|---|---|---|---|---|
| - | - | Human perception | - | 67.00 |
| - | - | ZeroR | - | 13.33 ± 1.76 |
| Feature Extraction (Static) | Average xlsr-Wav2Vec2.0 embs. from feature encoder | SVC | C = 1.0 | 50.13 ± 2.58 |
| C = 10.0 | 53.12 ± 2.58 | |||
| C = 100.0 | 53.10 ± 2.58 | |||
| kNN | k = 10 | 36.07 ± 2.48 | ||
| k = 20 | 37.90 ± 2.51 | |||
| k = 30 | 38.65 ± 2.51 | |||
| k = 40 | 38.47 ± 2.51 | |||
| MLP | 1 layer (80) | 56.53 ± 2.56 | ||
| 2 layers (80,80) | 55.82 ± 2.56 | |||
| Fine Tuning (Sequential) | Raw audio | xlsr-Wav2Vec2.0 + MLP | MLP 2 layers (1024,8) | 81.82 ± 1.99 |
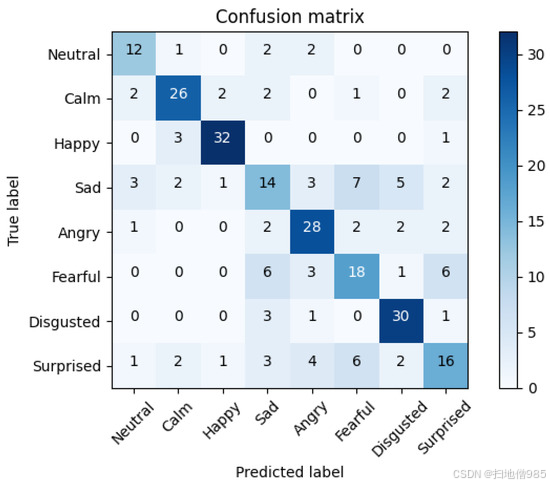
为了了解顶部解决方案的误差,我们从微调的 xlsr-Wav2Vec2.0 的预测中提取了混淆矩阵,该预测的准确率达到了 81.82%。图 5 中显示的混淆矩阵是在 5-CV 中获得的误差和预测的四舍五入平均值。因此,该矩阵总共有 288 个样本 (1440/5)。
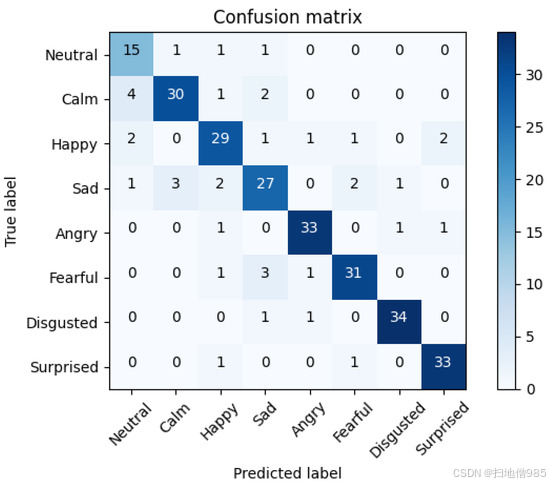
8、面部情绪识别结果
在表 2 中,我们可以看到面部情绪识别器的结果。使用 AU 的平均值训练的静态模型(SVC、k-NN 和 MLP)获得了与顺序模型相当的性能,尽管这些模型的计算机时间消耗较低且复杂性较低。在静态模型中,单层 80 个神经元的 MLP 准确率最高,为 58.93%。当我们将 0 到 1 之间的输入特征标准化为 60.22% 时,该指标有所改善。这些结果似乎表明,归一化强调了每种情绪的 AU 表示的差异,并赋予了 AU 的二元存在属性与强度属性的更多相关性。
Table 2. Quantitative evaluation of the different strategies applied for the facial emotion recognizer. In bold, the best models per input type.
| Inputs | Models | Hyper- Parameters | Norm. | Accuracy ± 95% CI |
|---|---|---|---|---|
| - | Human perception | - | - | 75.00 |
| - | ZeroR | - | - | 13.33 ± 1.76 |
| Average Action Units | SVC | C = 0.1 | Yes | 53.25 ± 2.58 |
| No | 48.07 ± 2.58 | |||
| C = 1.0 | Yes | 59.93 ± 2.53 | ||
| No | 54.88 ± 2.57 | |||
| C = 10.0 | Yes | 55.93 ± 2.56 | ||
| No | 51.65 ± 2.58 | |||
| kNN | k = 10 | Yes | 53.10 ± 2.58 | |
| No | 46.80 ± 2.58 | |||
| k = 20 | Yes | 54.30 ± 2.57 | ||
| No | 49.07 ± 2.58 | |||
| k = 30 | Yes | 55.18 ± 2.57 | ||
| No | 48.82 ± 2.58 | |||
| k = 40 | Yes | 55.40 ± 2.57 | ||
| No | 50.20 ± 2.58 | |||
| MLP | 1 layer (80) | Yes | 60.22 ± 2.53 | |
| No | 58.93 ± 2.54 | |||
| 2 layers (80,80) | Yes | 57.77 ± 2.55 | ||
| No | 55.82 ± 2.56 | |||
| Sequence of Action Units | bi-LSTM | 2 bi-LSTM layers (50,50) + 2 attention layers | No | 62.13 ± |
作为静态模型的替代方案,我们还考虑将从视频的每一帧中提取的 AU 用作单个实例,继承其父视频的标签。但是,使用所有样本训练模型并应用最大投票算法来预测视频级别类,报告的值较低。因此,表 2 中没有这些结果,但读者可以在附录 B 中查阅这些结果。
关于顺序模型,我们注意到非归一化顶部 MLP 模型增加了 3.2 个百分点。这一结果表明,数据的时间结构中也存在相关信息。尽管这个比率高于静态模型获得的速率,但它也表明这种模式仍有改进的空间,因为它仍然没有超过人类的感知准确性。此外,它开辟了一条有吸引力的研究路线,以了解哪些帧与决定视频何时属于一种或另一种情感最相关。这种理解可以支持生成更精确的算法来对视频执行情感识别。
为了分析错误的原因,我们绘制了 bi-LSTM 实验的混淆矩阵,准确率达到 62.13%。我们在图 6 中显示了这个矩阵。
9、多模态融合结果
多模态融合机制
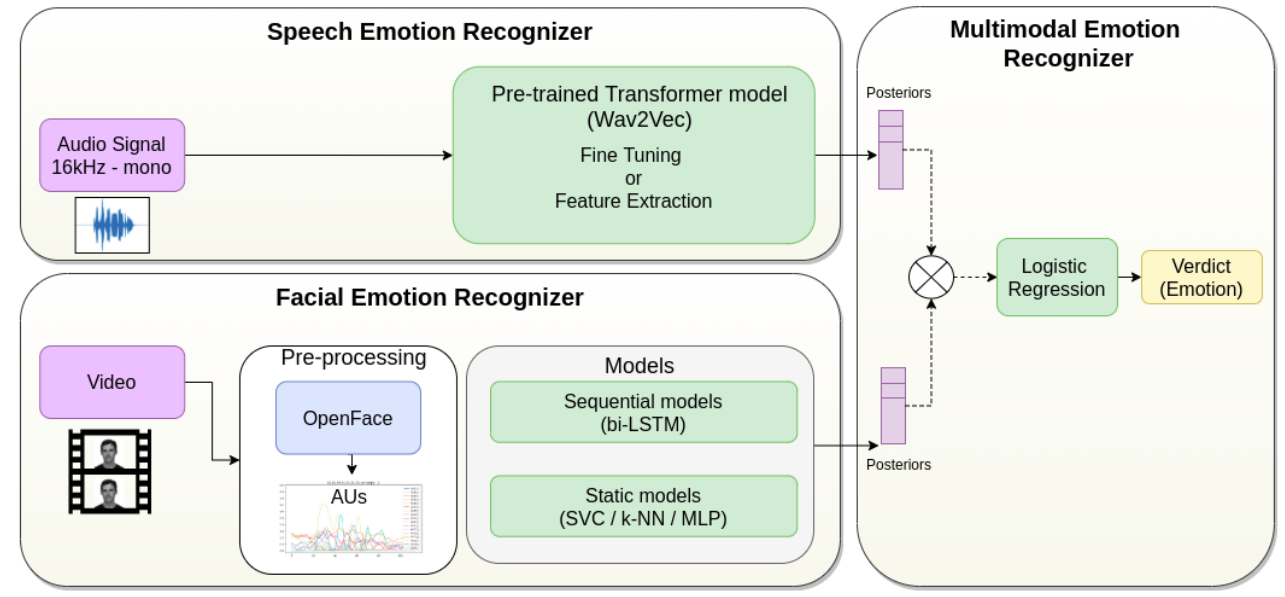
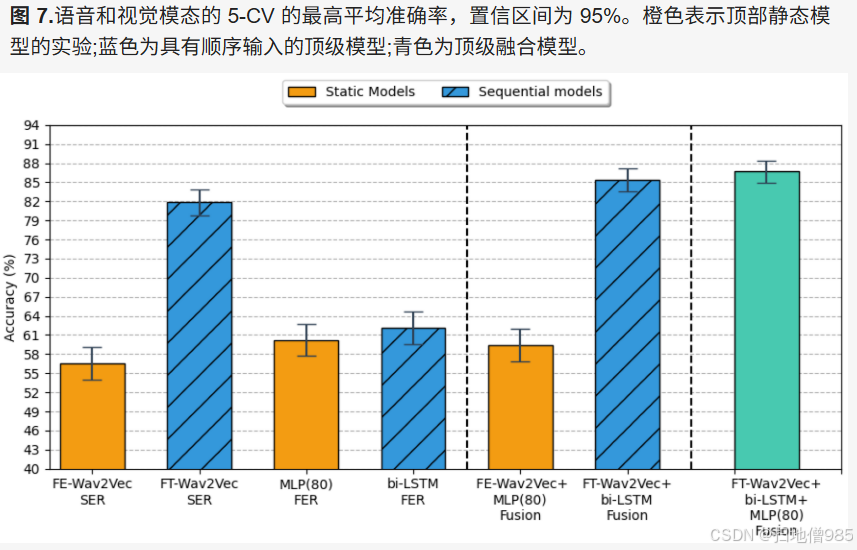
表 3.准确率达到 86.70% 的顶级模型的每种情绪的精度、召回率和准确率指标。所有指标均作为 5-CV 策略的平均值计算。
| Neutral | Calm | Happy | Sad | Angry | Fearful | Disgusted | Surprised | |
|---|---|---|---|---|---|---|---|---|
| Precision | 88.31 | 91.45 | 89.79 | 71.22 | 91.78 | 88.26 | 93.99 | 89.50 |
| Recall | 82.25 | 85.63 | 89.25 | 81.88 | 92.37 | 83.62 | 88.50 | 87.87 |
| Accuracy | 98.05 | 96.88 | 97.05 | 92.73 | 97.83 | 96.20 | 97.70 | 96.95 |
图 8 中的混淆矩阵。矩阵的对角线显示有关听觉模态的正确预测样本量较高。更具体地说,“Happy”类提高了它的准确性,这似乎是合理的,因为视觉模态可以高度确定地区分这种情绪。对于其他类别,如 'Angry', 'Fearful', 'Disgusted' 或 'Surprise',准确性与听觉模型所达到的准确性相似。“平静”和“悲伤”在融合后也反映了轻微的改善,而“中性”在微调后保持与 xlsr-Wav2Vec2.0 模型相似的值。总之,我们可以得出结论,这种融合导致了我们研究中分类的几乎所有情绪的更好结果。
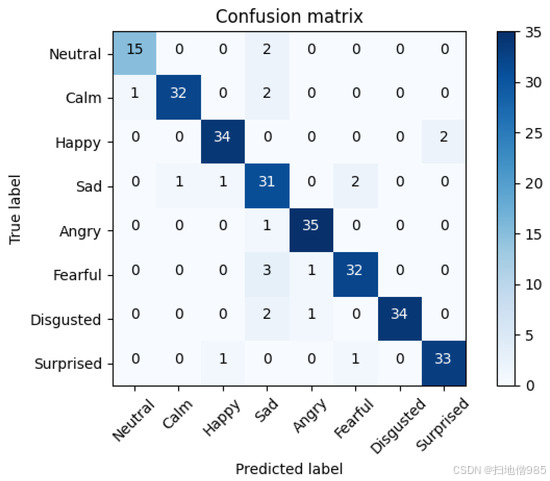
图 8.结合了 FT-xlsr-Wav2Vec2.0 、 bi-LSTM 和 80 个神经元的 MLP 后验的顶部晚期融合模型的平均混淆矩阵。准确率为 86.70%。
10、结论
自动情绪分类具有显著挑战性。虽然能够观察到某些共性模式,但个体间的差异性仍然显著,即使研究对象来自同一国籍并使用相同语言变体(如RAVDESS语料库中的情况)(主页联系)。
代码论文已实现,需要的联系我扣扣2551931023欢迎讨论()
本研究提出了一种融合语音和面部数据的多模态情感识别系统。在语音模型方面,实验表明:采用预训练转换器的微调模型比特征提取策略性能提升25.29分;相较于人类感知基准,该模型实现了14.82%的性能提升,验证了方法的稳健性;同时,我们的方案较先前研究[35]获得了10.21%的改进。
视觉模态的研究显示,序列模型取得了最佳准确率。但需要指出的是,静态和序列模型的表现仍低于语音情感识别(SER)及人类识别水平。研究过程中发现了一些有待深入探讨的问题,特别是关于情绪动态特性的建模。例如,视频中某些关键帧包含更显著的情绪信息,而现有时序和静态模型均未能有效从动作单元中捕获这些特征。
尽管视觉模态表现相对较弱,但双模态融合仍实现了86.70%的分类准确率,显著优于单一模态的结果。
未来工作将着眼于以下方向:通过架构优化或尝试其他transformer模型来提升视觉模型性能;开发能够提取高情绪负荷关键帧的技术;若研究进展顺利,有望使模型性能更接近人类水平;最终将在实际应用场景中验证这些改进方案。
自动情绪分类具有显著挑战性。虽然能够观察到某些共性模式,但个体间的差异性仍然显著,即使研究对象来自同一国籍并使用相同语言变体(如RAVDESS语料库中的情况)。
本研究提出了一种融合语音和面部数据的多模态情感识别系统。在语音模型方面,实验表明:采用预训练转换器的微调模型比特征提取策略性能提升25.29分;相较于人类感知基准,该模型实现了14.82%的性能提升,验证了方法的稳健性;同时,我们的方案较先前研究[35]获得了10.21%的改进。
视觉模态的研究显示,序列模型取得了最佳准确率。但需要指出的是,静态和序列模型的表现仍低于语音情感识别(SER)及人类识别水平。研究过程中发现了一些有待深入探讨的问题,特别是关于情绪动态特性的建模。例如,视频中某些关键帧包含更显著的情绪信息,而现有时序和静态模型均未能有效从动作单元中捕获这些特征。
尽管视觉模态表现相对较弱,但双模态融合仍实现了86.70%的分类准确率,显著优于单一模态的结果。
未来工作将着眼于以下方向:通过架构优化或尝试其他transformer模型来提升视觉模型性能;开发能够提取高情绪负荷关键帧的技术;若研究进展顺利,有望使模型性能更接近人类水平;最终将在实际应用场景中验证这些改进方案。
11、下载模型权重
要下载经过训练的模型的权重(仅限 Wav2Vec2.0 和 bi-LSTM),请单击此链接 B (~16GB):
models.zip - UPMdrive
最后,感谢 m3hrdadfi 提供的关于语音情感识别 (Wav2Vec 2.0) 的开放教程,我们将其用作基础 在 RAVDESS 数据集上训练我们的语音情感识别模型。