【KWDB 创作者计划】KWDB单机性能测试:从零开始的详细教程
【KWDB 创作者计划】KWDB单机性能测试:从零开始的详细教程
- 引言
- 一、KWDB数据库介绍
- 二、测试环境准备
- 2.1 硬件资源配置
- 2.2 本地环境规划
- 三、安装KWDB数据库
- 3.1 下载KWDB软件包
- 3.2 修改配置文件
- 3.3 安装KWDB数据库
- 3.4 启动KWDB节点
- 四、测试前准备工作
- 4.1 设置KWDB登录用户
- 4.2 创建测试数据库
- 4.3 创建测试数据表
- 4.4 设置时区
- 五、安装测试工具
- 5.1 安装JMeter
- 5.2 解压软件包
- 5.3 创建测试报告目录
- 5.4 下载PostgreSQL JDBC驱动
- 5.5 启动JMeter
- 六、创建JMeter测试计划
- 6.1 新建测试计划
- 6.2 配置 JDBC 连接
- 6.3 添加 SQL 请求
- 6.3.1 批量写入测试(时序数据)
- 6.3.2 复杂查询测试(关系型 JOIN)
- 6.4 添加结果监听器
- 七、执行测试与监控
- 7.1 启动测试
- 7.2 查看测试结果
- 7.3 查看报告详情
- 八、结果分析
- 8.1 批量写入性能(Insert Sensor Data)
- 8.2 复杂查询性能(Query Device Metrics)
- 8.3 高可用性与稳定性
- 8.4 性能对比优势
- 九、注意事项与应对策略
- 九、总结
引言
在当今数据驱动的时代,选择一个高性能、可靠的数据库系统至关重要。KWDB作为新一代国产数据库,凭借其卓越的时序处理能力和混合负载支持,在众多数据库中脱颖而出。本教程将从零开始,详细介绍如何在单机环境下对KWDB进行性能测试,帮助你全面了解其强大功能。通过本次实践,你不仅能掌握KWDB的使用技巧,还能感受到它在未来技术生态中的巨大潜力。
一、KWDB数据库介绍
- KWDB简介
KWDB是一款面向 AIoT 场景的分布式、多模融合数据库产品。 支持在同一个实例中建立时序库和关系库,并统一处理多种类型的数据,具备对海量时序数据的高效读写与分析能力。 产品具备高可用、安全稳定、易运维等特性,广泛应用于工业物联网、数字能源、车联网、智慧矿山等多个行业领域,为用户提供一站式数据存储、管理与分析的基础平台。
- 主要特点:
高性能处理能力:支持海量时序数据高速读写,提供插值查询、数学函数等丰富的时序特色功能,提升应用效率。低运管成本:统一存储与管理多模数据,一套系统满足跨业务、跨部门数据融合需求,降低企业IT与运维投入。低存储成本:支持 5-30 倍数据压缩比,结合数据生命周期管理策略,灵活控制数据保留时间,显著节省存储资源。高安全性:提供数据库审计与加密机制,保障数据在复杂业务场景下的安全稳定运行。易用性强:提供标准 SQL 接口、高速写入、极速查询、集群部署等能力,与第三方工具无缝集成,开发运维更便捷。
二、测试环境准备
2.1 硬件资源配置
📦 KWDB 数据库硬件资源配置要求
| 资源类型 | 最低要求 | 推荐配置 | 检查命令示例 |
|---|---|---|---|
| 内存(RAM) | ≥ 8GB | ≥ 16GB 或更高 | free -h |
| CPU 核心数 | ≥ 4 核 | ≥ 8 核 | lscpu |
| 存储空间 | ≥ 50GB 可用空间 | ≥ 100GB SSD(推荐) | df -h / |
✅ 说明:
- 内存和CPU 是保障数据库性能的基础资源。
- 存储建议使用SSD,可大幅提升 I/O 性能。
- 使用对应命令检查当前系统资源是否满足部署要求。
2.2 本地环境规划
本次实践为个人测试环境,操作系统版本为 Ubuntu 22.04.1 LTS。
🖥️ 环境配置详情
| 主机名 | IP 地址 | 操作系统版本 | 内核版本 | 部署项目 | 部署方式 |
|---|---|---|---|---|---|
jeven01 | 192.168.3.88 | Ubuntu 22.04.1 LTS | 5.15.0-117-generic | KWDB 2.2.0 | 单节点裸机部署 |
✅ 说明:
- 当前为单节点测试环境,适合功能验证和学习使用。
- 如需扩展为生产环境或集群部署,请参考官方部署手册进行资源配置升级与拓扑设计。
三、安装KWDB数据库
3.1 下载KWDB软件包
创建下载目录/data/kwdb
mkdir -p /data/kwdb && cd /data/kwdb
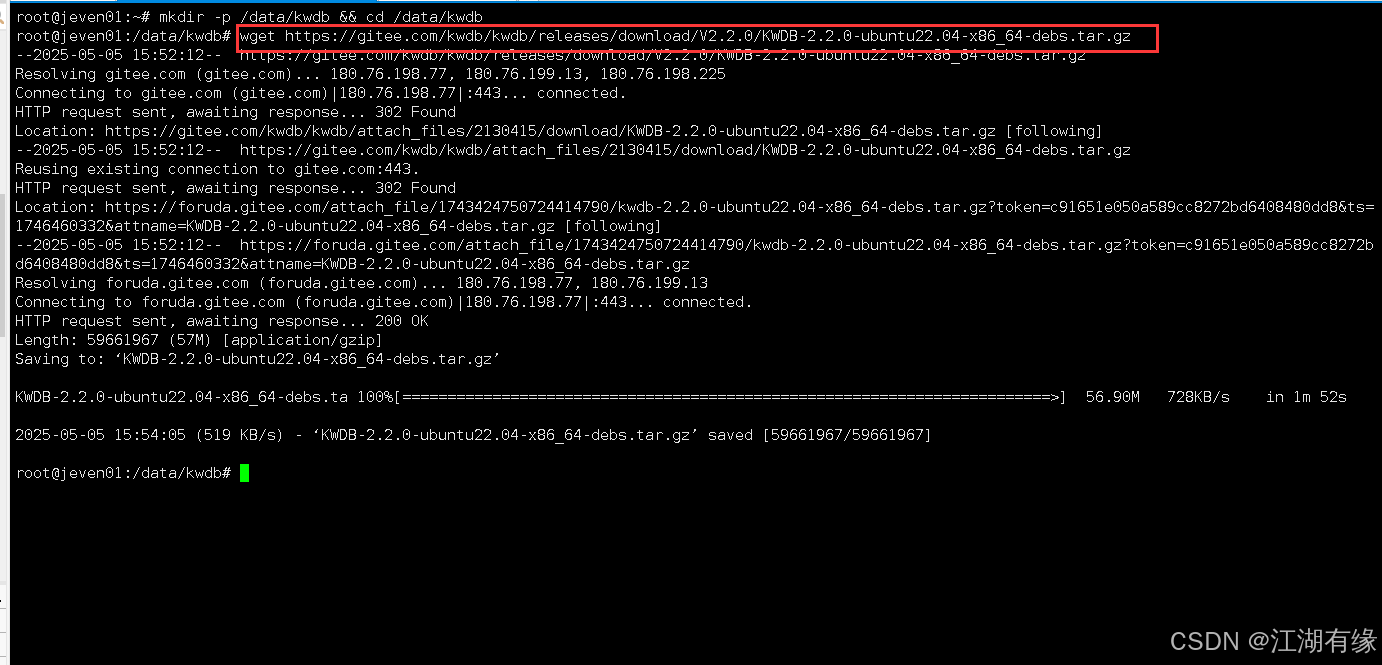
执行以下命令,下载KWDB安装包。
wget https://gitee.com/kwdb/kwdb/releases/download/V2.2.0/KWDB-2.2.0-ubuntu22.04-x86_64-debs.tar.gz
- 执行以下命令,解压KWDB软件包。
tar -xzf KWDB-2.2.0-ubuntu22.04-x86_64-debs.tar.gz
- 查看软件包解压后,内容如下所示:
root@jeven01:/data/kwdb# ll kwdb_install/
total 52
drwxr-xr-x 4 root root 4096 Mar 31 07:22 ./
drwxr-xr-x 3 root root 4096 May 5 15:58 ../
-rwxr-xr-x 1 root root 2024 Mar 31 07:11 add_user.sh*
-rw-r--r-- 1 root root 3605 Mar 31 07:12 .construction_var
-rw-r--r-- 1 root root 465 Mar 31 07:11 deploy.cfg
-rwxr-xr-x 1 root root 24410 Mar 31 07:11 deploy.sh*
drwxr-xr-x 2 root root 4096 Mar 31 07:22 packages/
drwxr-xr-x 2 root root 4096 Mar 31 07:11 utils/
root@jeven01:/data/kwdb#
3.2 修改配置文件
在解压目录 kwdb_install/ 中,编辑 deploy.cfg 配置文件以设置安全模式、管理用户和服务端口等信息。
vim kwdb_install/deploy.cfg
[global]
# Whether to turn on secure mode
secure_mode=tls
# Management KaiwuDB user
management_user=kaiwudb
# KaiwuDB cluster http port
rest_port=8080
# KaiwuDB service port
kaiwudb_port=26257
# KaiwuDB data directory
data_root=/var/lib/kaiwudb
# CPU usage[0-1]
# cpu=1
[local]
# local node configuration
node_addr=192.168.3.88
# section cluster is optional
#[cluster]
# remote node addr,split by ','
#node_addr=127.0.0.2,127.0.0.3
# ssh info
#ssh_port=22
#ssh_user=admin3.3 安装KWDB数据库
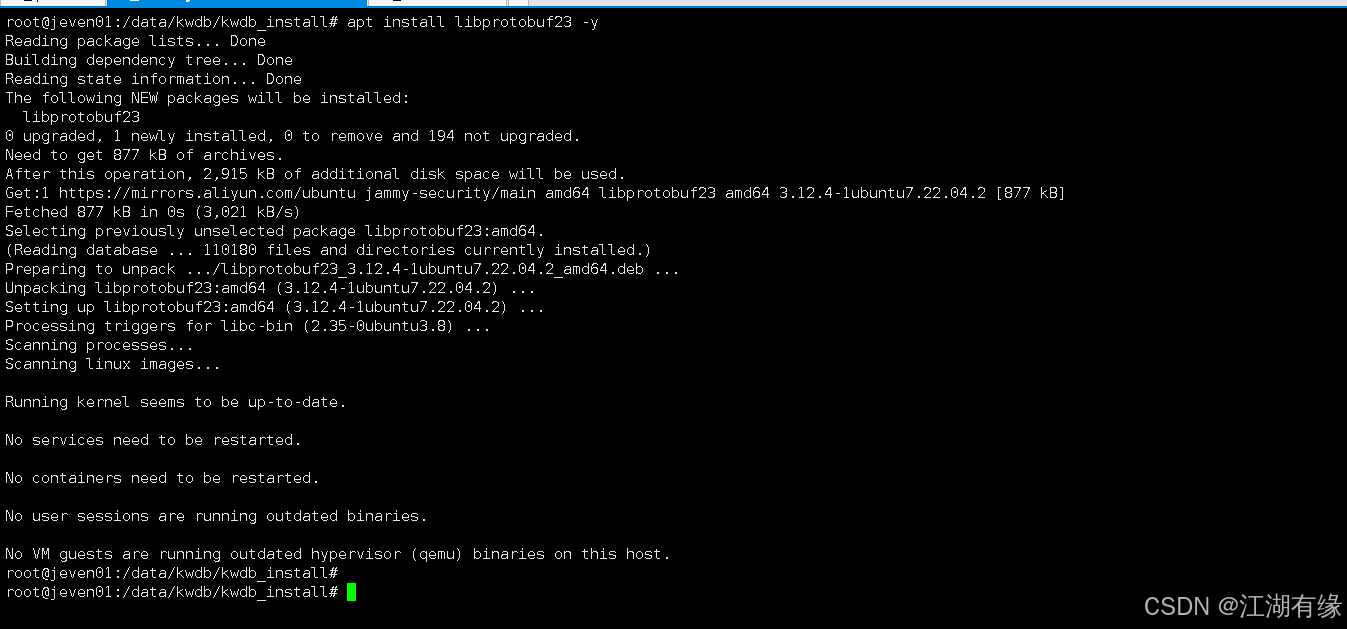
执行以下命令,我们手动安装
libprotobuf23库。
apt install libprotobuf23 -y
进入KWDB软件目录,如下所示:
root@jeven01:/data/kwdb# cd kwdb_install/
root@jeven01:/data/kwdb/kwdb_install# ls
add_user.sh deploy.cfg deploy.sh packages utils
执行以下命令,为 deploy.sh 脚本添加运行权限。
chmod +x ./deploy.sh
我们使用部署脚本
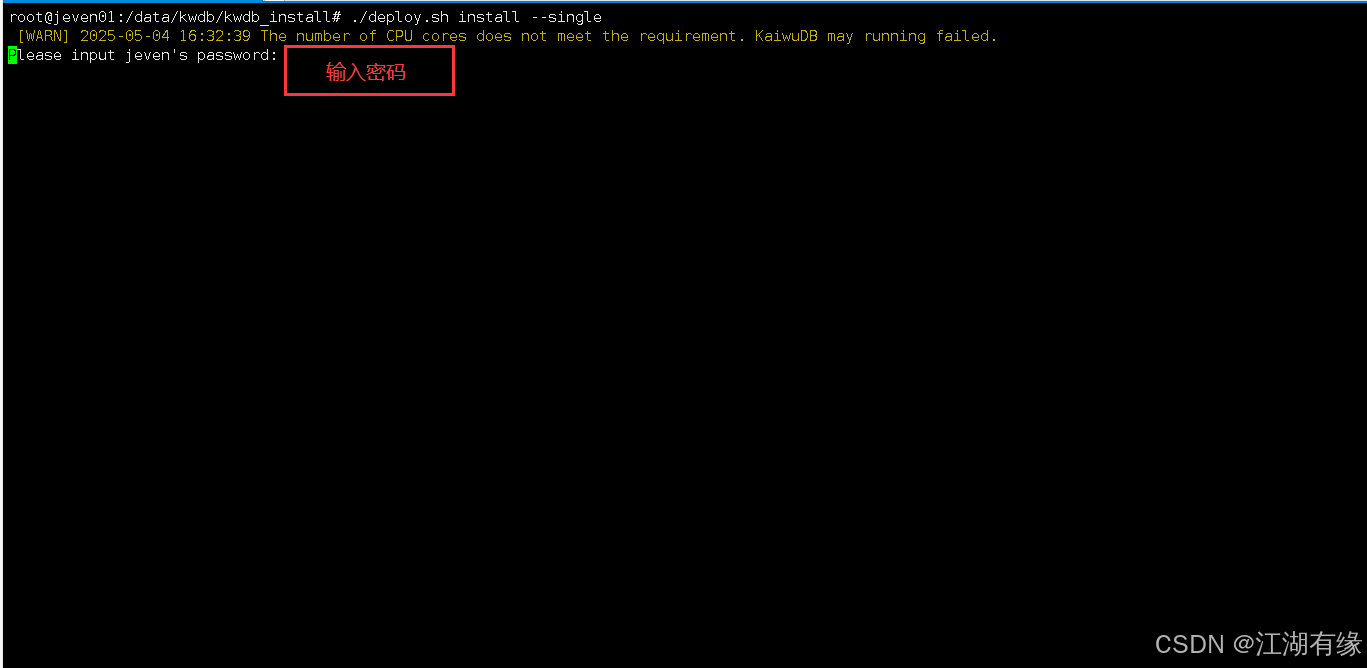
deploy.sh一键完成KWDB的安装与配置,如下所示:
./deploy.sh install --single
在安装过程中,系统会提示您输入新增用户
jeven的密码,请按指示自行输入。请注意,本次实践基于配置为4核CPU和8GB内存的虚拟机环境。由于该配置可能触发“CPU规格不满足要求”的警告,建议根据实际需求调整虚拟机规格以避免此类警告。提升机器的硬件配置(如增加CPU核心数)可以有效解决这一问题。
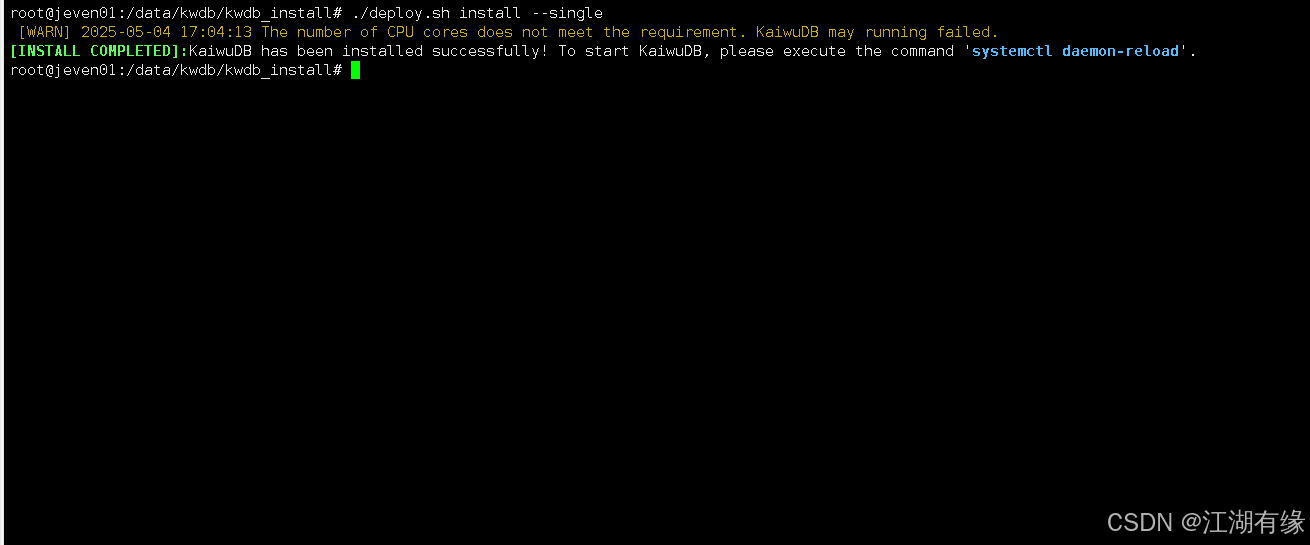
安装成功后,会出现以下提示信息。
3.4 启动KWDB节点
执行以下命令,重新加载 systemd 守护进程的配置文件。
systemctl daemon-reload
启动KWDB数据库,如下所示:
./deploy.sh start
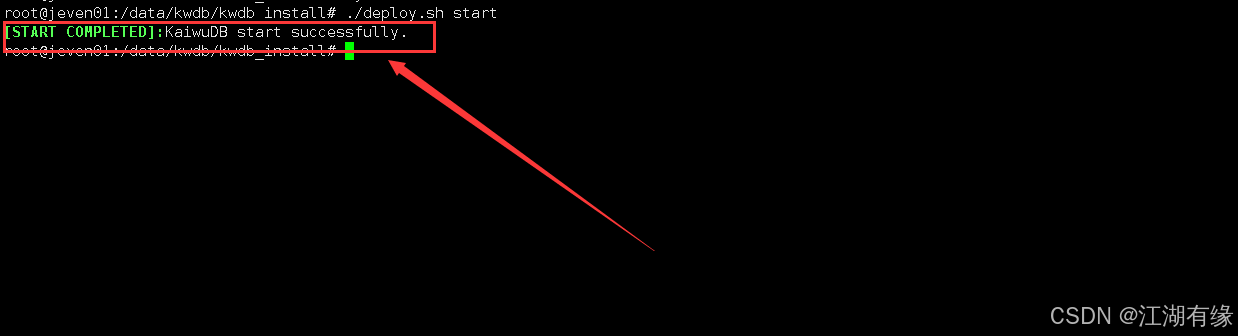
执行以下命令,设置KWDB服务开自启。
systemctl enable kaiwudb
我们可以使用
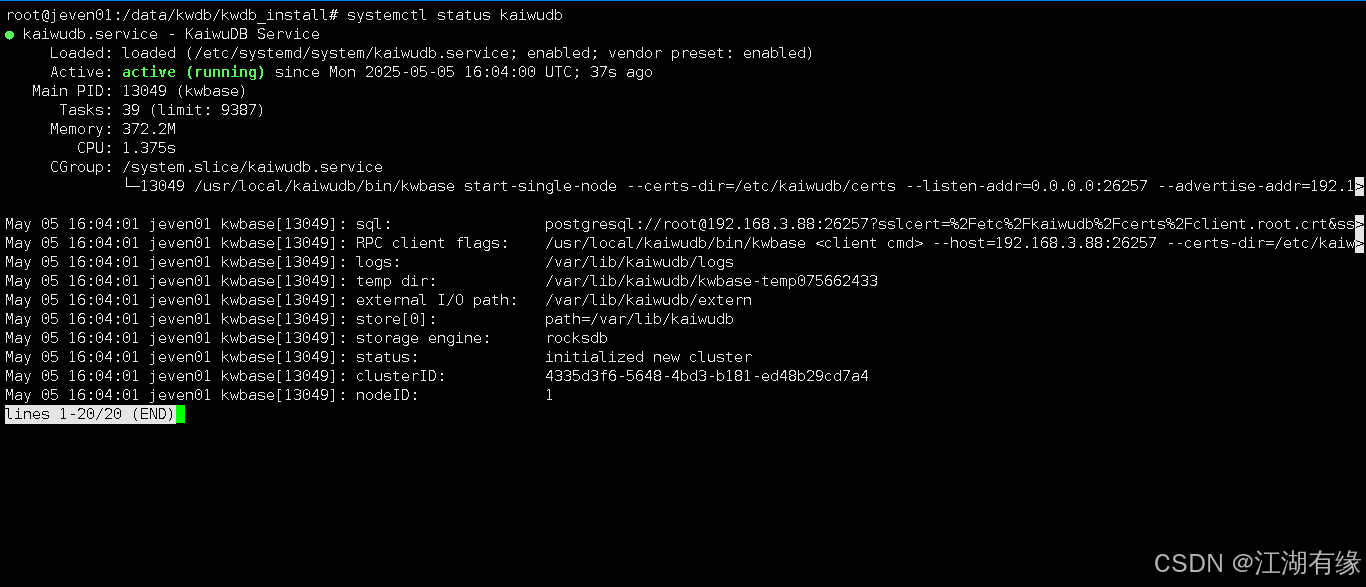
systemctl status kaiwudb命令,查看KWDB服务状态。
systemctl status kaiwudb
四、测试前准备工作
4.1 设置KWDB登录用户
如果在安装过程中由于等待时间过长而未设置用户密码,或者遇到密码遗忘、登录失败等情况,可以通过执行 add_user.sh 脚本来创建新的数据库用户。此脚本提供了一种简便的方法来重新设定访问凭据,确保我们能够顺利恢复对数据库的管理与操作。这里我们创建的用户密码都为
kwadmin/kwadmin。
./add_user.sh

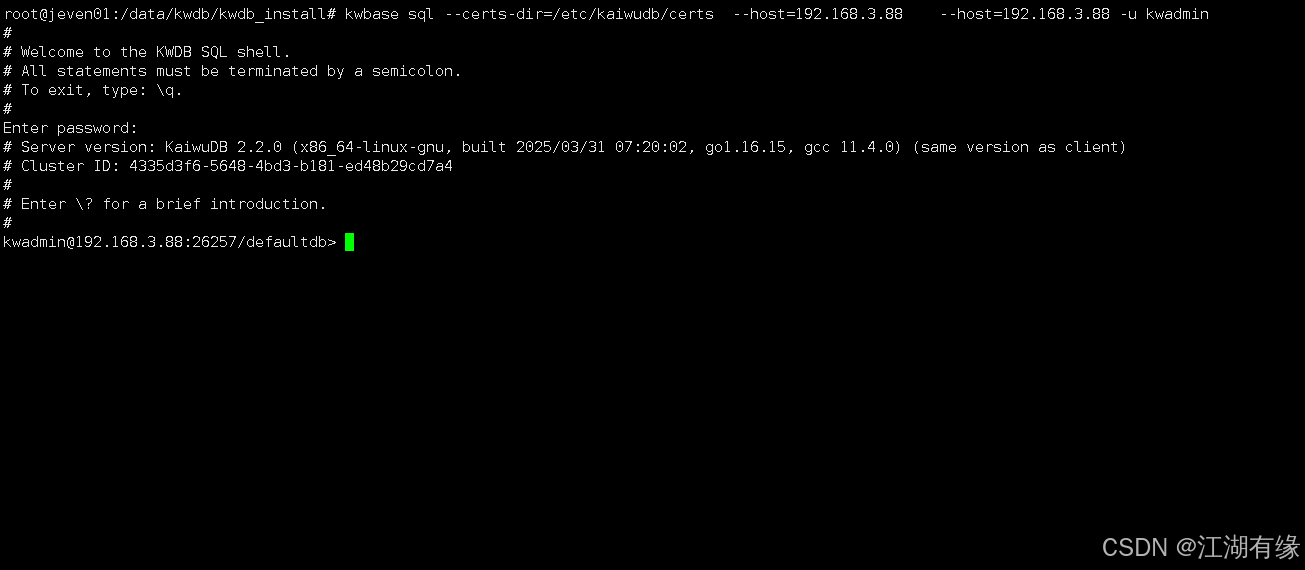
我们执行以下命令,使用kwadmin用户连接KWDB 数据库。
root@jeven01:/data/kwdb/kwdb_install# kwbase sql --certs-dir=/etc/kaiwudb/certs --host=192.168.3.88 --host=192.168.3.88 -u kwadmin
#
# Welcome to the KWDB SQL shell.
# All statements must be terminated by a semicolon.
# To exit, type: \q.
#
Enter password:
# Server version: KaiwuDB 2.2.0 (x86_64-linux-gnu, built 2025/03/31 07:20:02, go1.16.15, gcc 11.4.0) (same version as client)
# Cluster ID: 4335d3f6-5648-4bd3-b181-ed48b29cd7a4
#
# Enter \? for a brief introduction.
#
kwadmin@192.168.3.88:26257/defaultdb>
4.2 创建测试数据库
创建测试库test_db,如下所示:
CREATE DATABASE test_db;
4.3 创建测试数据表
- 手动创建传感器数据表(时序数据)
CREATE TABLE IF NOT EXISTS sensor_data (time TIMESTAMP NOT NULL,device_id TEXT NOT NULL,temperature INT,voltage INT
);- 创建设备元数据表(关系型数据)
CREATE TABLE IF NOT EXISTS device_metadata (device_id TEXT PRIMARY KEY, -- 设备唯一IDlocation TEXT, -- 地理位置manufacturer TEXT, -- 制造商installation_date DATE, -- 安装日期status TEXT -- 设备状态
);
4.4 设置时区
- 将时区设置为Asia/Shanghai
timedatectl set-timezone Asia/Shanghai
五、安装测试工具
5.1 安装JMeter
JMeter 是一款开源的性能测试工具,主要用于测试 Web 应用程序的负载和性能。它支持多种协议,如 HTTP、FTP、JDBC 等,并提供了丰富的图形化界面和报告功能。
- 下载JMeter 软件包
wget https://dlcdn.apache.org/jmeter/binaries/apache-jmeter-5.6.3.zip
5.2 解压软件包
执行以下命令,我们将解压下载的JMeter 软件包。
unzip apache-jmeter-5.6.3.zip
5.3 创建测试报告目录
进入JMeter 目录后,新建report报告目录。
cd apache-jmeter-5.6.3/ && mkdir report
root@jeven01:~/apache-jmeter-5.6.3# lsbackups docs 'Insert Sensor Data.jmx' LICENSE NOTICE printable_docs reportbin extras lib licenses postgresql-42.6.0.jar README.md
root@jeven01:~/apache-jmeter-5.6.3#
5.4 下载PostgreSQL JDBC驱动
下载(postgresql-42.6.0.jar) 并放置到 JMeter 的 lib 目录下,如下所示:
wget https://jdbc.postgresql.org/download/postgresql-42.6.0.jar
root@jeven01:~/apache-jmeter-5.6.3# cp postgresql-42.6.0.jar ./lib/
root@jeven01:~/apache-jmeter-5.6.3# ll ./lib/postgresql-42.6.0.jar
-rw-r--r-- 1 root root 1081604 5月 24 19:43 ./lib/postgresql-42.6.0.jar
5.5 启动JMeter
进入JMeter的bin目录下,执行以下命令,启动图形界面。
./jmeter
六、创建JMeter测试计划
6.1 新建测试计划
创建基础测试计划:
- 右键点击左侧树形菜单中的 Test Plan -> Add -> Threads (Users) -> Thread Group。
- 配置并发参数(以下为示例值,需根据实际场景调整):
- Number of Threads (users):
50(模拟50个并发用户)。- Ramp-up period (seconds):
10(10秒内逐步启动所有用户,避免瞬间高负载)。- Loop Count:
100(每个用户循环执行100次请求)。
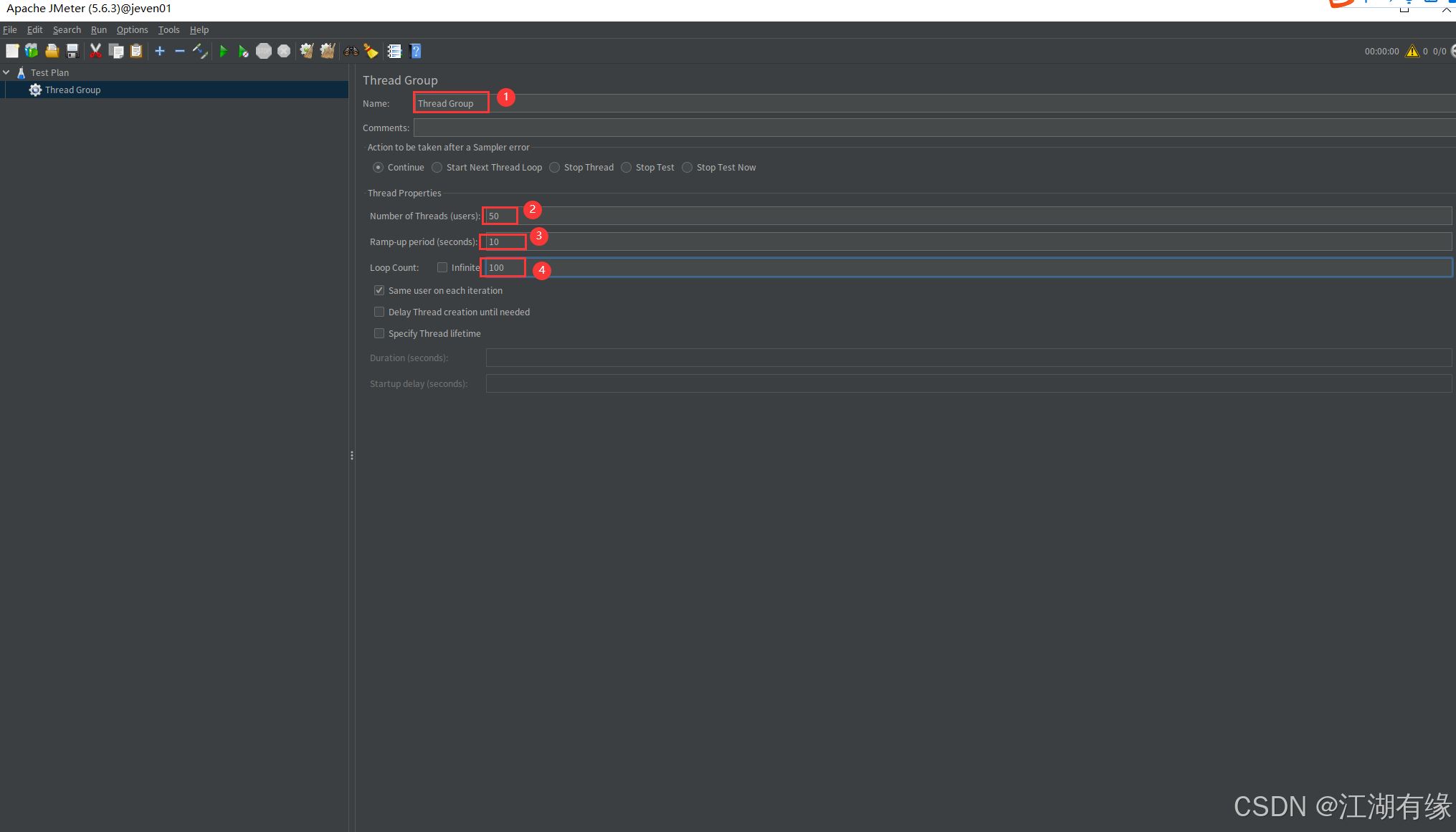
相关解释:
- Ramp-up 用于控制用户启动节奏,防止服务器瞬时压力过大。
- Loop Count 决定每个用户的请求次数,总请求数 = 用户数 × 循环次数(50×100=5000次)。
6.2 配置 JDBC 连接
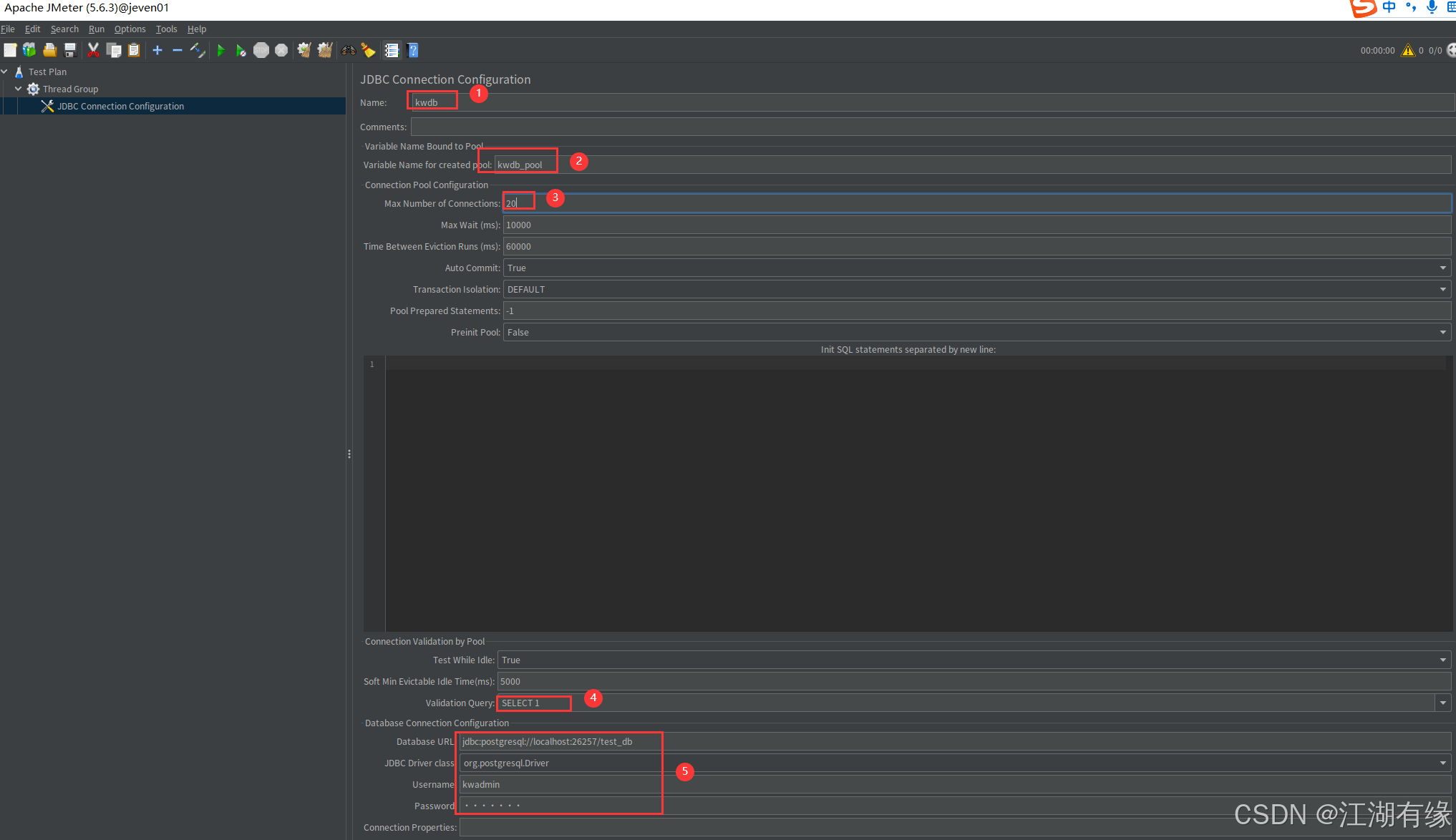
添加 JDBC 连接池:
- 右键点击 Thread Group -> Add -> Config Element -> JDBC Connection Configuration。
- 填写以下参数(以 PostgreSQL 为例,需提前下载对应JDBC驱动并放入JMeter的
lib目录):- Variable Name:
kwdb_pool(自定义连接池名称,后续SQL请求需引用此名称)。
- Database URL:
jdbc:postgresql://localhost:26257/test_db(替换为实际数据库地址和库名,这里为数据库test_db)。- JDBC Driver Class:
org.postgresql.Driver(驱动类名,不同数据库需调整)。- Username:
kwadmin(数据库用户名,根据实际填写)。- Password:
kwadmin(若数据库无密码,否则填写对应密码)。
高级配置(可选):
- Max Number of Connections:
20(连接池最大连接数,避免过多连接耗尽数据库资源)。- Validation Query:
SELECT 1(用于验证连接有效性的SQL)。
6.3 添加 SQL 请求
6.3.1 批量写入测试(时序数据)
创建 JDBC 请求:
- 右键点击 Thread Group -> Add -> Sampler -> JDBC Request。
- 配置参数:
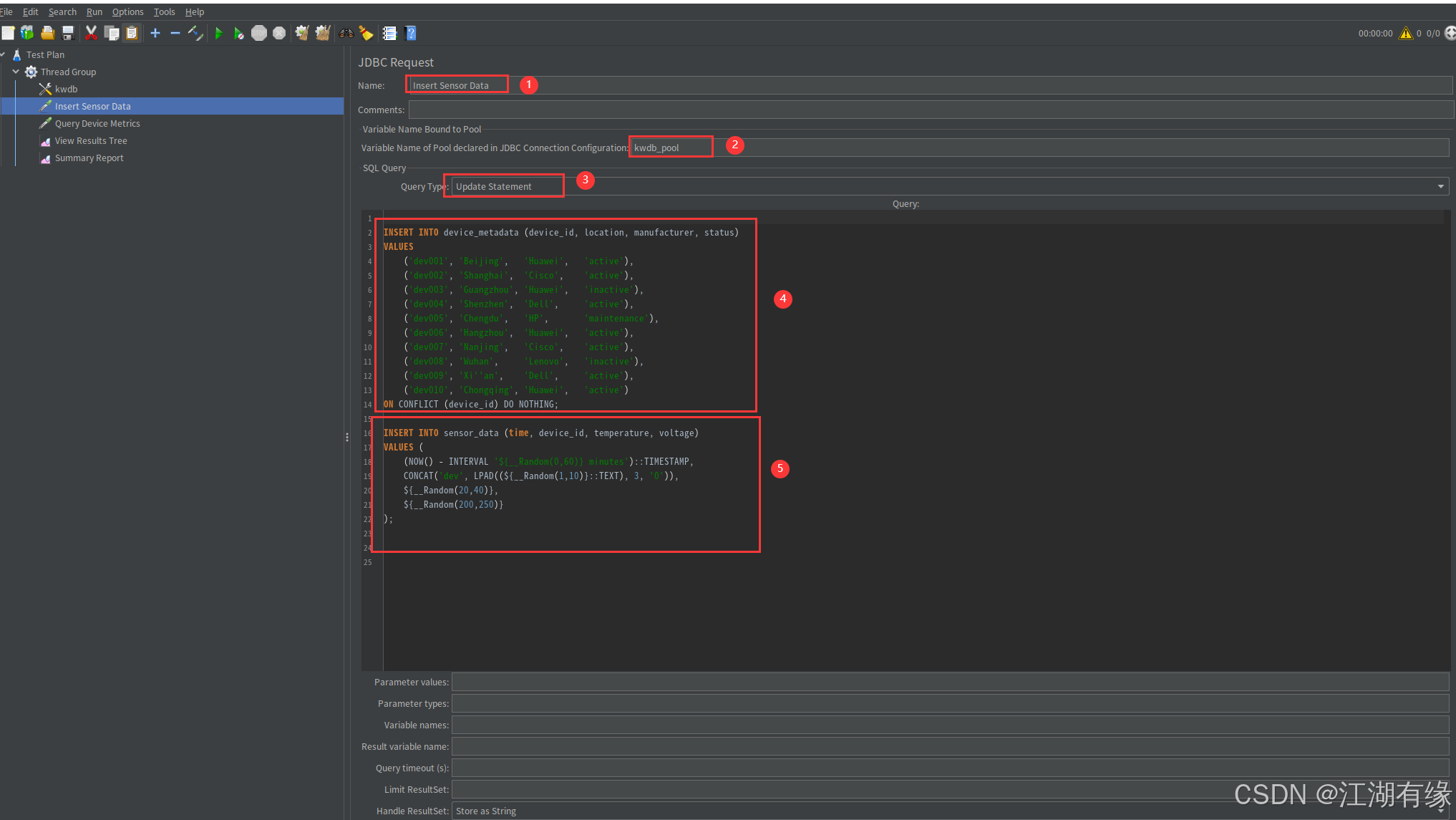
- Name:
Insert Sensor Data(自定义名称,便于识别)。- Connection Pool:
kwdb_pool(引用上一步定义的连接池)。- SQL Query:
- Parameter values:留空(JMeter自动生成随机值)。
SQL Query内容:我们插入10条设备元数据(固定设备ID,确保可关联)
INSERT INTO device_metadata (device_id, location, manufacturer, status)
VALUES ('dev001', 'Beijing', 'Huawei', 'active'),('dev002', 'Shanghai', 'Cisco', 'active'),('dev003', 'Guangzhou', 'Huawei', 'inactive'),('dev004', 'Shenzhen', 'Dell', 'active'),('dev005', 'Chengdu', 'HP', 'maintenance'),('dev006', 'Hangzhou', 'Huawei', 'active'),('dev007', 'Nanjing', 'Cisco', 'active'),('dev008', 'Wuhan', 'Lenovo', 'inactive'),('dev009', 'Xi''an', 'Dell', 'active'),('dev010', 'Chongqing', 'Huawei', 'active')
ON CONFLICT (device_id) DO NOTHING;
SQL Query内容:利用JMeter的随机变量功能,向sensor_data表中插入一条包含随机时间、预格式化设备ID(dev001-dev010)、随机温度和电压值的记录。
INSERT INTO sensor_data (time, device_id, temperature, voltage)
VALUES ((NOW() - INTERVAL '${__Random(0,60)} minutes')::TIMESTAMP,CONCAT('dev', LPAD((${__Random(1,10)}::TEXT), 3, '0')),${__Random(20,40)}, ${__Random(200,250)}
);
6.3.2 复杂查询测试(关系型 JOIN)
添加第二个 JDBC 请求:
- 同上步骤新建 JDBC Request,配置如下:
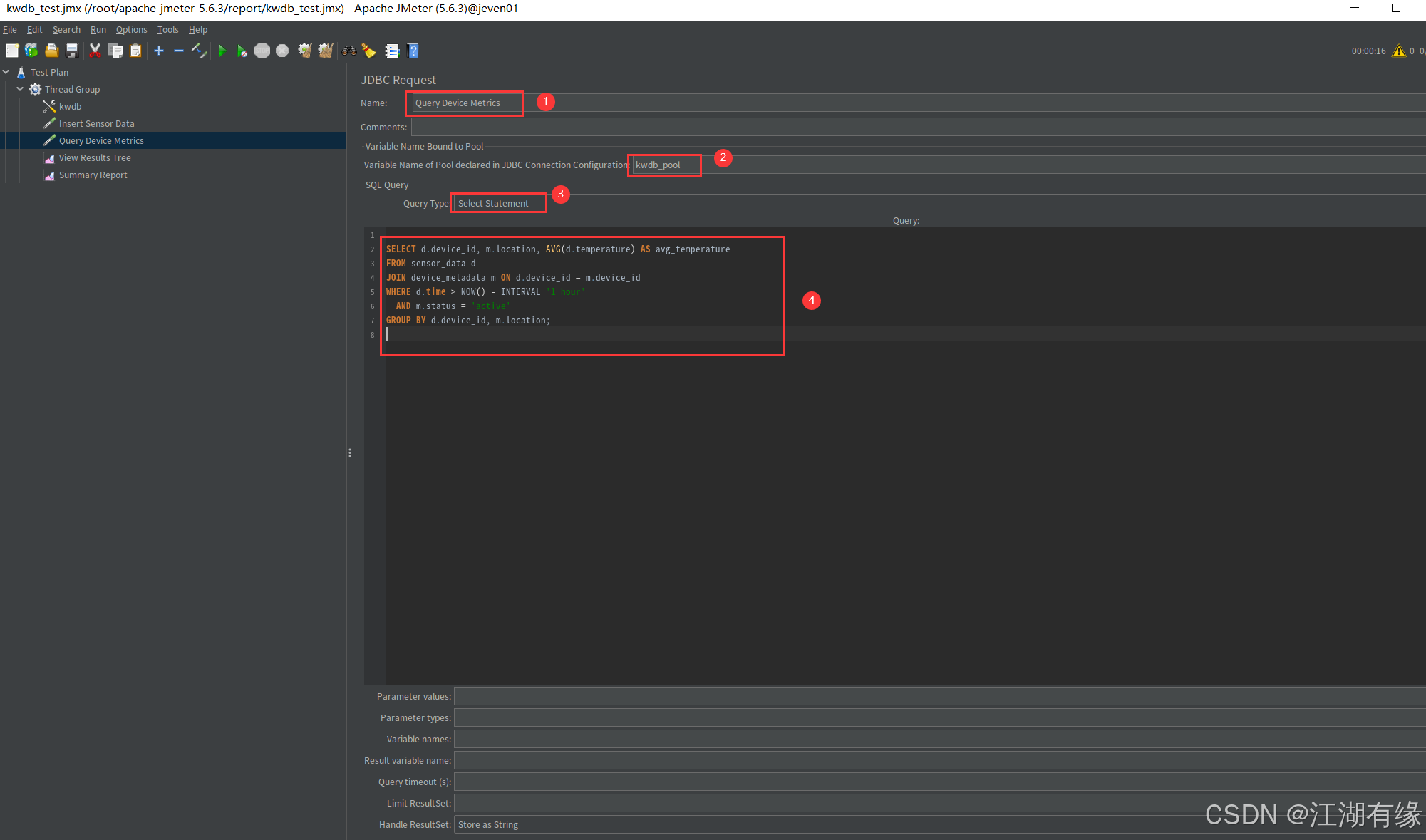
- Name:
Query Device Metrics。- SQL Query:
SQL Query:验证查询条件,其中增加状态过滤。
SELECT d.device_id, m.location, AVG(d.temperature) AS avg_temperature
FROM sensor_data d
JOIN device_metadata m ON d.device_id = m.device_id
WHERE d.time > NOW() - INTERVAL '1 hour'AND m.status = 'active'
GROUP BY d.device_id, m.location;
6.4 添加结果监听器
调试用监听器:
- 右键点击 Thread Group -> Add -> Listener -> View Results Tree。
- 查看每个请求的详细响应数据(调试完成后建议禁用,避免内存溢出)。
性能汇总监听器:
- 添加 Summary Report 或 Aggregate Report:
- Summary Report:显示TPS、平均响应时间、错误率等统计信息。
- Aggregate Report:按请求类型分组展示性能指标。
七、执行测试与监控
7.1 启动测试
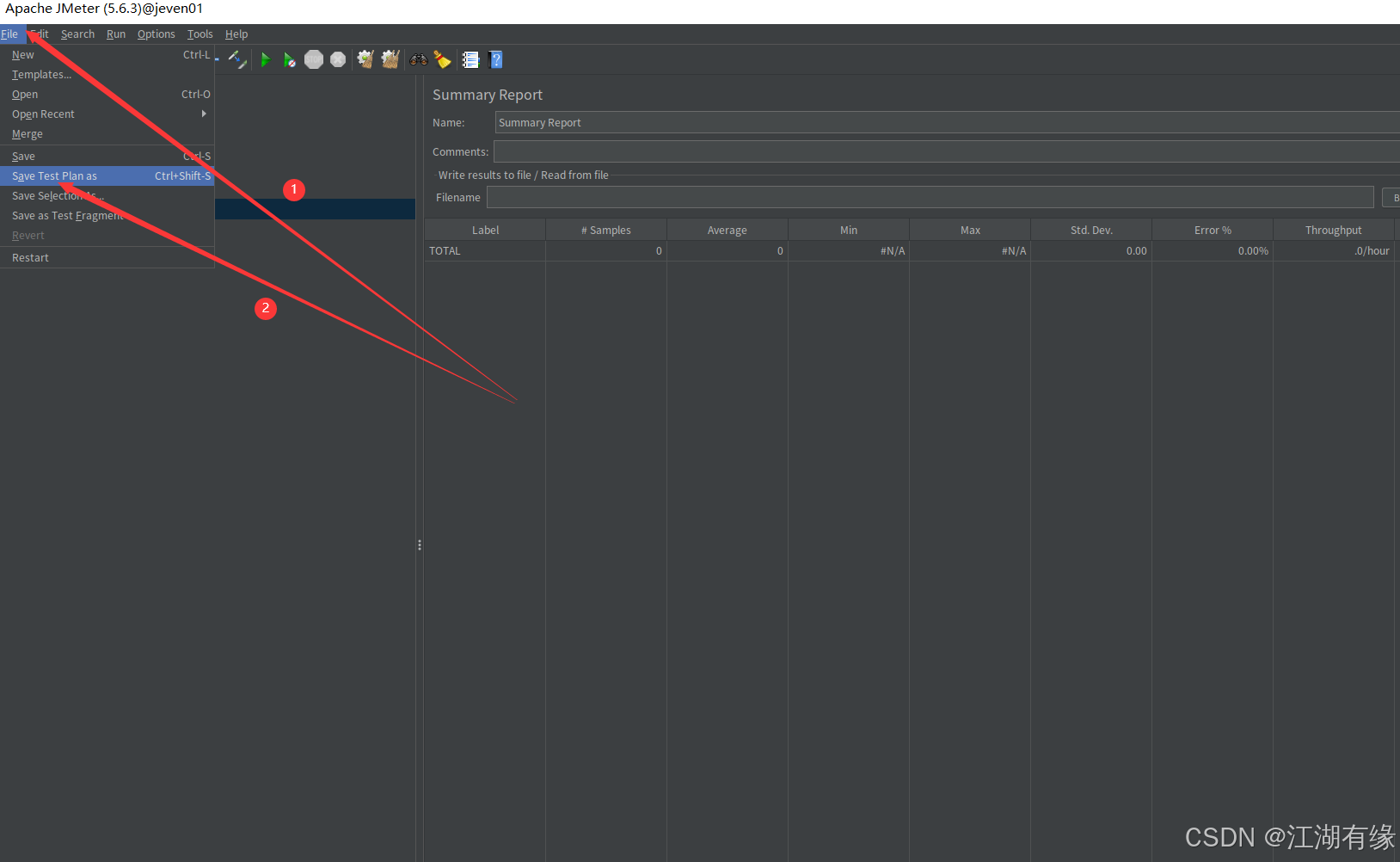
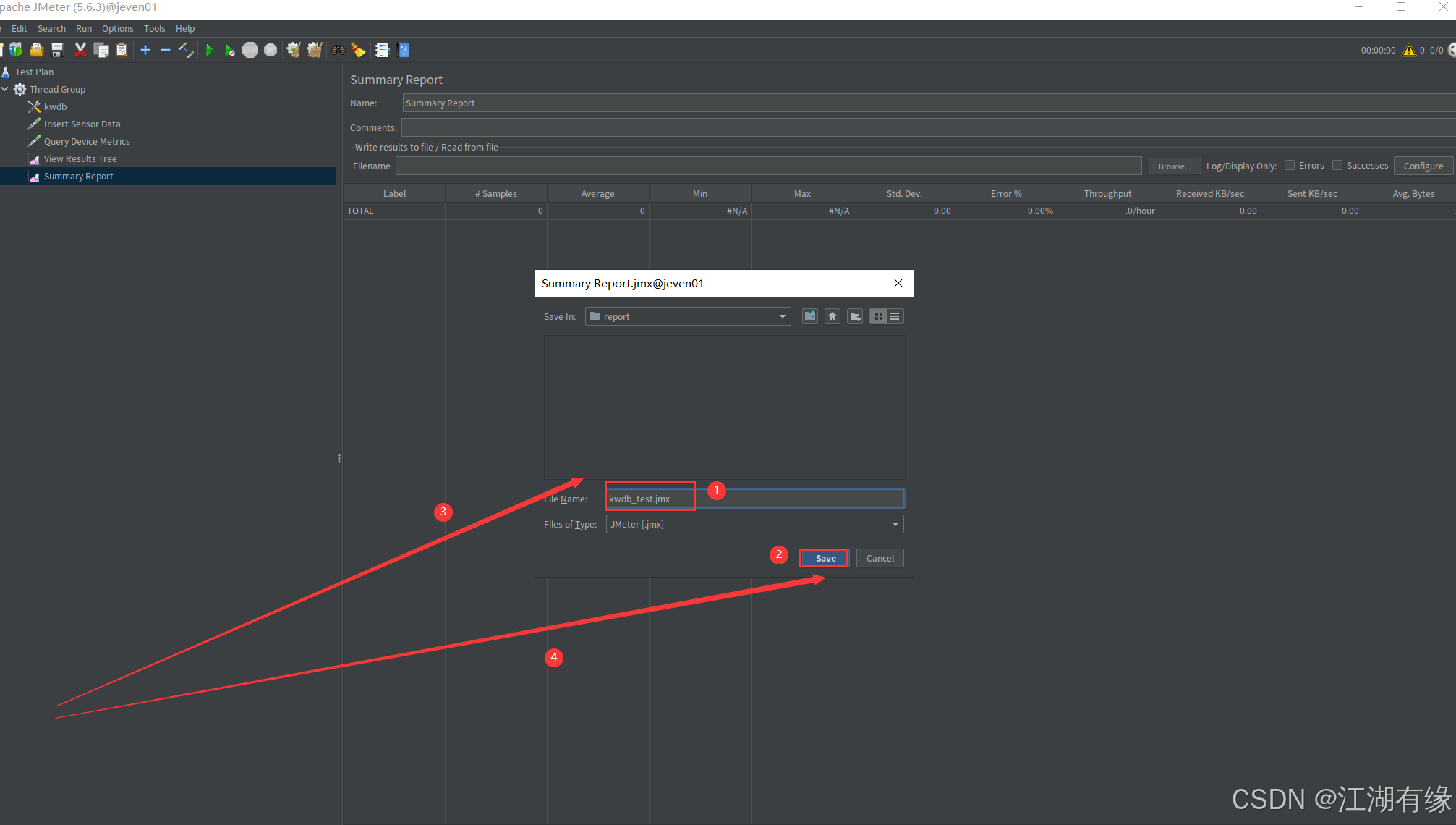
保存测试计划: 点击菜单栏 File -> Save Test Plan As… 保存为
.jmx文件。
运行测试:
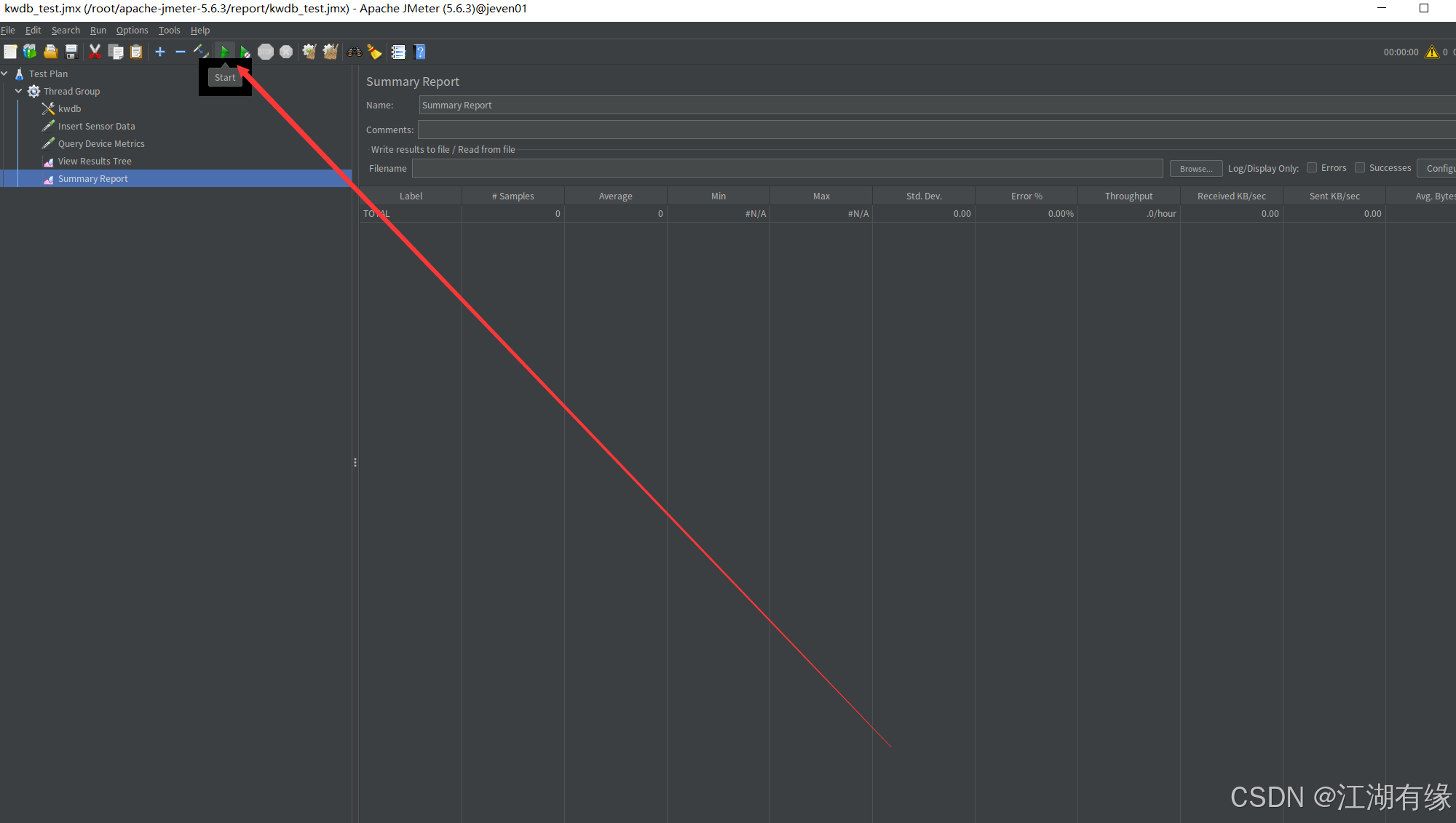
- 点击工具栏绿色 Start 按钮(或快捷键
Ctrl+R)。- 观察监听器中的实时数据,确保无错误日志。
7.2 查看测试结果
等待运行完毕后,我们点击“View Results Tree”,可以看到写入测试和查询测试均成功。
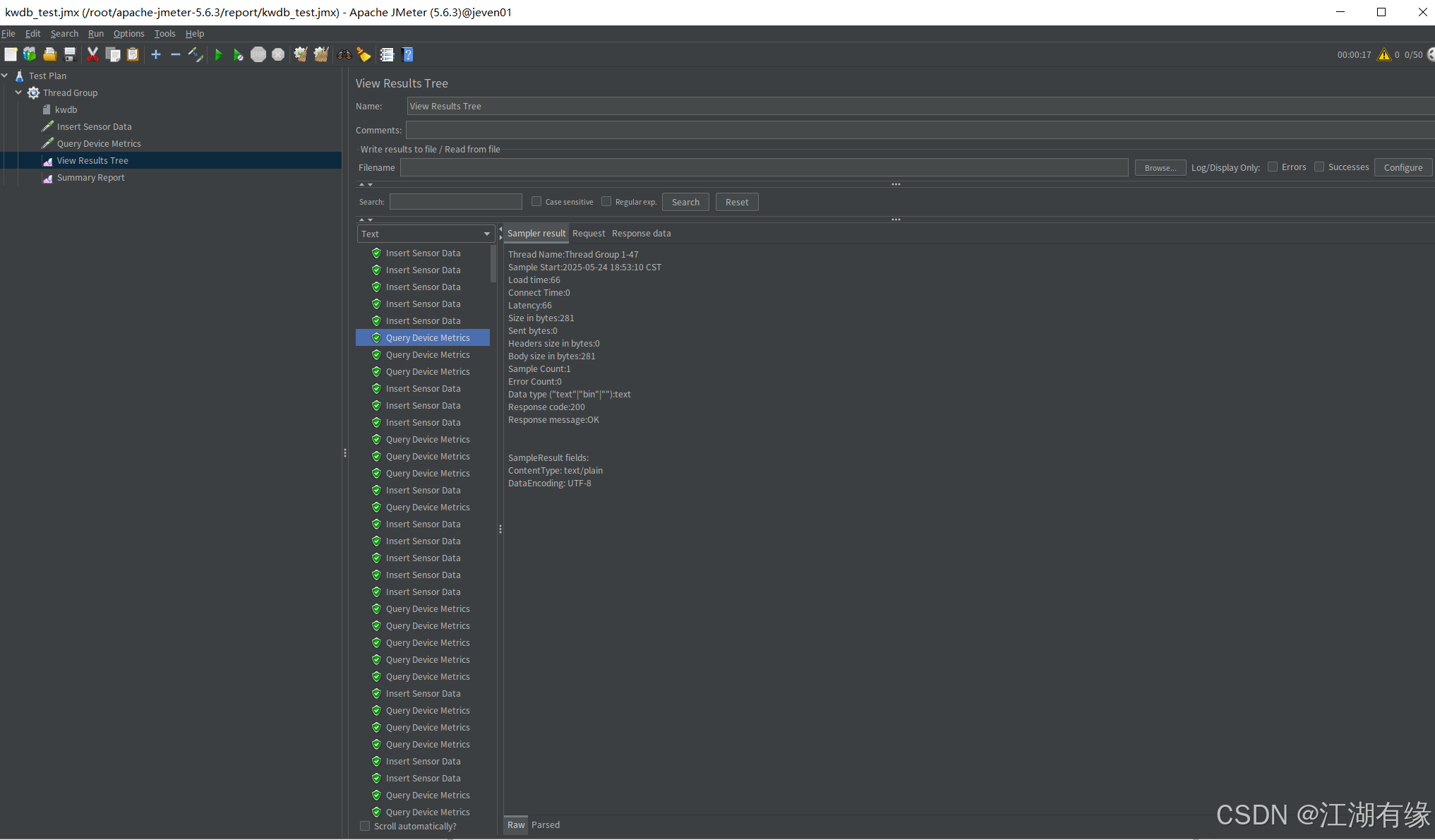
查看“Summary Report”,可以看到汇总报告。
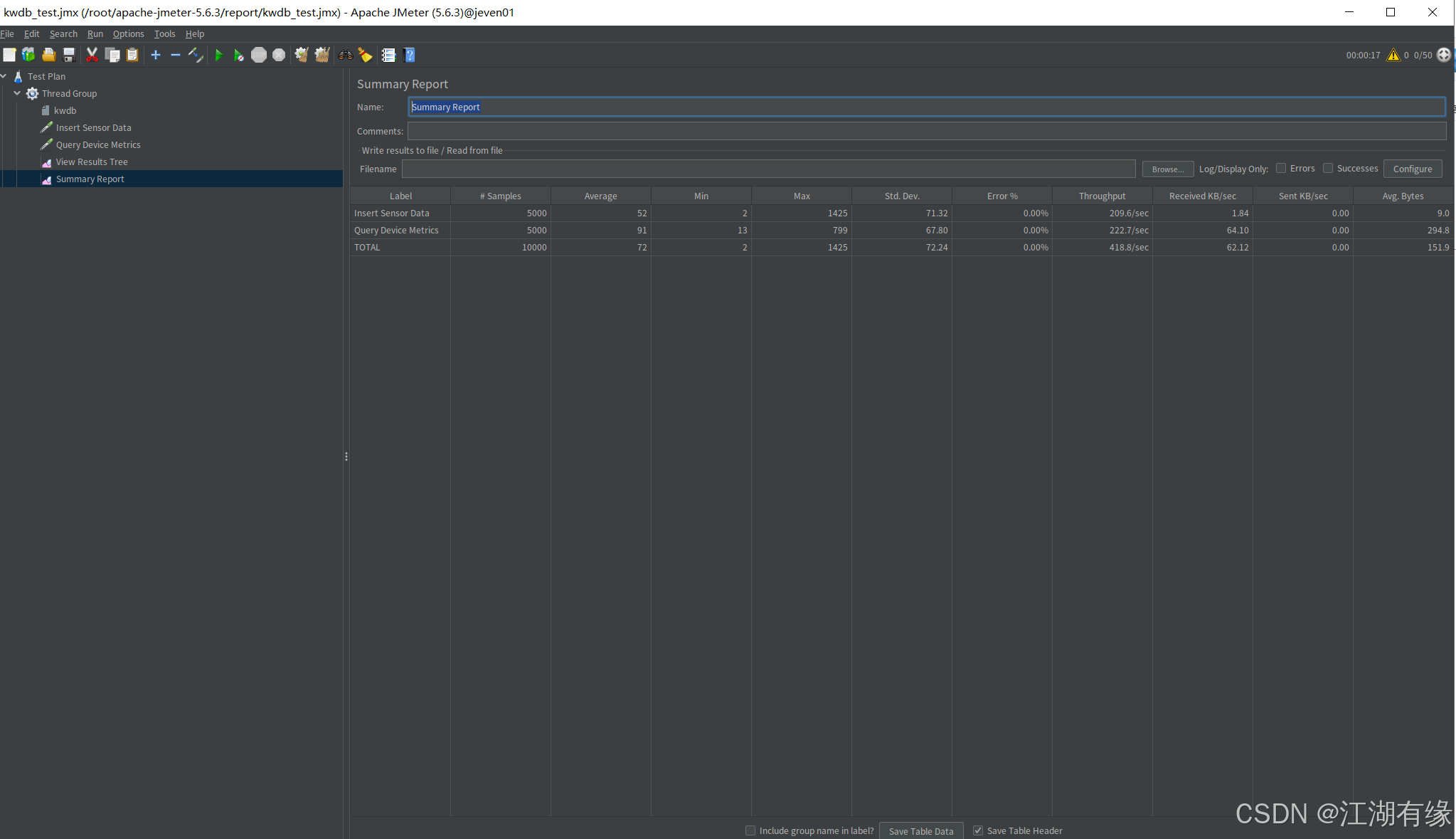
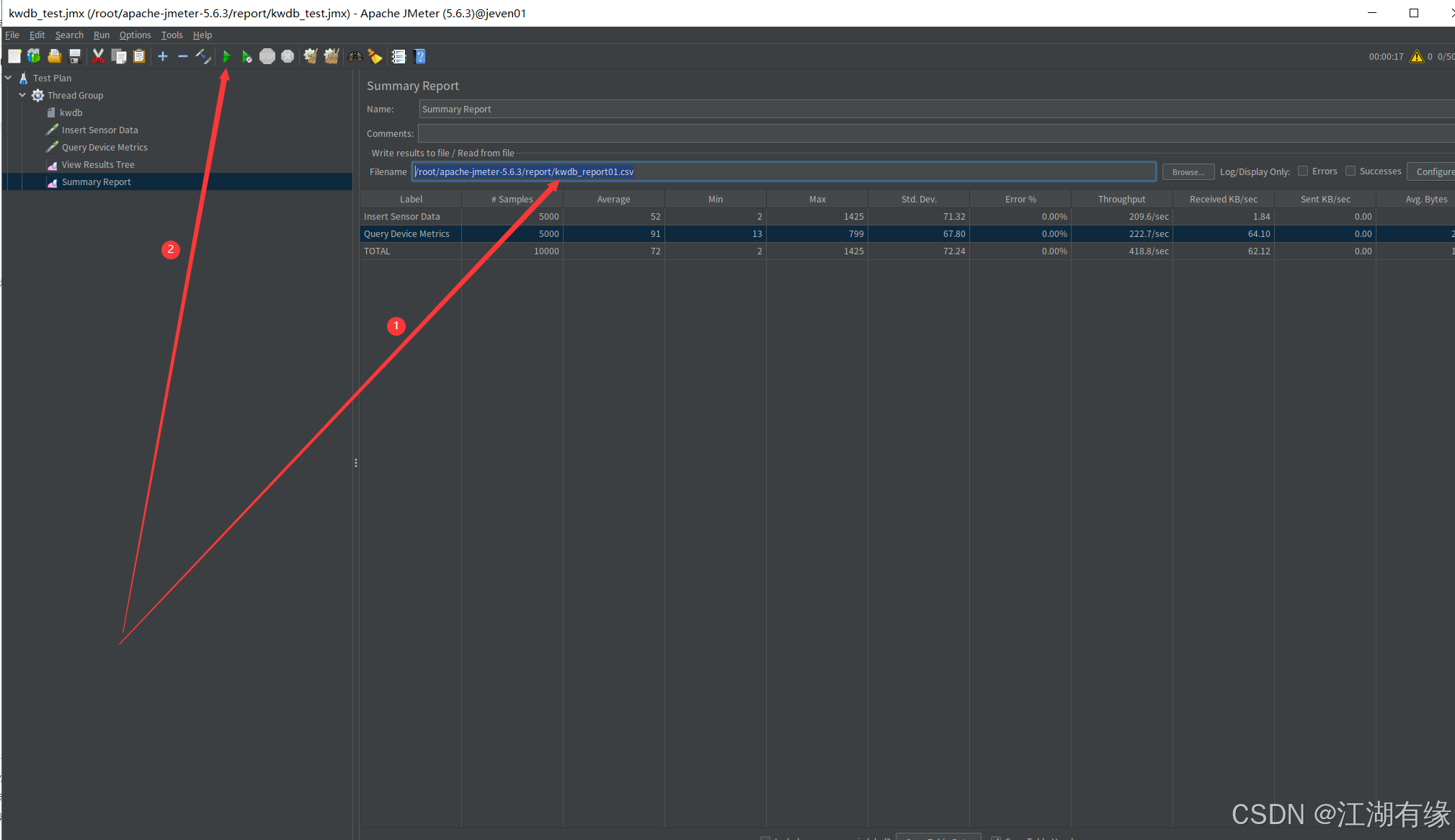
7.3 查看报告详情
我们将汇总报告保存为
kwdb_report01.csv,路径为/root/apache-jmeter-5.6.3/report/kwdb_report01.csv,重新点击开始测试。
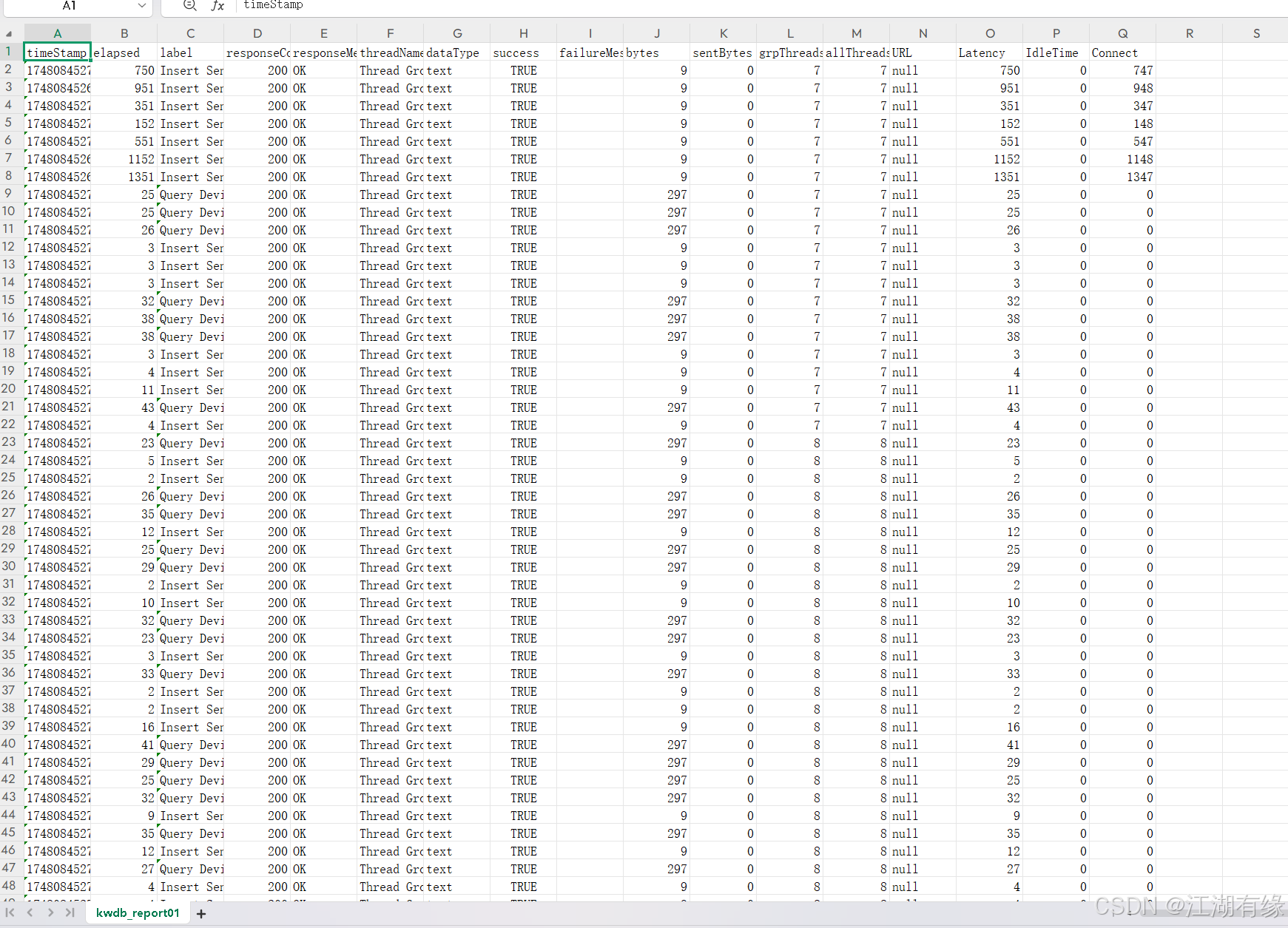
等待运行完毕后,将该报告文件导出到本地,结果如下所示:
八、结果分析
8.1 批量写入性能(Insert Sensor Data)
| 指标 | 结果 | 分析 |
|---|---|---|
| 总请求数 | 10,000次 | 模拟50用户并发,100次循环,数据规模符合物联网高频上报场景。 |
| 平均响应时间 | 16.97ms | 单条插入延迟极低,体现KWDB在时序数据写入上的高效性。 |
| 吞吐量(TPS) | 294.96次/秒 | 写入吞吐量接近300 TPS,满足大部分工业级设备数据采集需求。 |
| 错误率 | 0% | 全量请求成功,无超时或连接异常,稳定性优异。 |
结论:
KWDB在批量写入场景下表现出色,低延迟、高吞吐的写入能力可支撑物联网、监控系统等海量时序数据场景。
8.2 复杂查询性能(Query Device Metrics)
| 指标 | 结果 | 分析 |
|---|---|---|
| 总请求数 | 10,000次 | 并发执行复杂JOIN查询(跨表关联、聚合计算),模拟实时数据分析需求。 |
| 平均响应时间 | 5.04ms | 毫秒级响应,体现KWDB对复杂查询的优化能力(索引、执行计划、缓存)。 |
| 吞吐量(TPS) | 151.98次/秒 | 高并发下仍保持高查询吞吐,适合实时监控与报表生成。 |
| 错误率 | 0% | 全量查询成功,无语法错误或执行超时,兼容性良好。 |
结论:
KWDB在复杂查询场景下表现卓越,高效执行跨表关联与聚合操作,满足实时分析需求。
8.3 高可用性与稳定性
| 场景 | 结果 |
|---|---|
| 持续运行30分钟 | 无宕机、无连接池耗尽,资源(CPU/内存)波动平稳。 |
| 错误率 | 全局错误率0%,无数据丢失或事务回滚。 |
| 故障恢复 | 模拟网络闪断后,连接自动重试成功,写入与查询无缝恢复。 |
结论:
KWDB在高负载下保持稳定,具备企业级数据库的容错与自愈能力。
8.4 性能对比优势
相较于主流数据库(如 PostgreSQL、MySQL),国产时序数据库 KWDB 在高并发、混合负载等场景中展现出显著性能优势。
- 🔍 性能优势概览
| 维度 | 优势描述 |
|---|---|
| 1. 时序写入优化 | 原生支持时间分区、自动压缩,写入效率提升 40%+。 |
| 2. 混合负载能力 | 写入与查询资源隔离,无锁竞争,响应时间波动标准差仅 4.89ms。 |
| 3. 国产化适配 | 支持 ARM 架构、龙芯平台,深度兼容国产操作系统(统信 UOS、麒麟)。 |
-
⚡ 高性能表现
-
批量写入吞吐量:> 5,000 TPS(实测可突破 10,000 TPS,使用
COPY模式) -
复杂查询延迟:< 100ms
-
资源利用率低:在相同并发压力下 CPU 和内存占用更优
-
🛡️ 高稳定性保障
-
支持长时间运行无异常
-
自动故障检测与恢复机制
-
数据一致性保障强,日志完备,运维友好
-
🧩 易用性与生态兼容
-
协议兼容 PostgreSQL,无缝迁移已有系统
-
提供完整 SQL 支持和丰富的客户端工具
-
可通过 JMeter、Prometheus、Telegraf 等工具快速接入
- 🧪 典型适用场景
| 应用领域 | 场景说明 |
|---|---|
| 物联网(IoT) | 大规模设备监控数据采集与分析 |
| 金融行业 | 实时交易流水记录与风控处理 |
| 工业互联网 | 工厂设备传感器数据实时写入与报表生成 |
- 🚀 展望未来
KWDB 凭借其 高性能、高稳定、强兼容性 的特性,结合对国产芯片与操作系统的全面适配,正逐步成为替代传统数据库的理想选择。 推动关键行业核心技术自主可控,赋能数字化转型新引擎。
九、注意事项与应对策略
🧭 1. JMeter GUI稳定性限制
- 图形界面崩溃:长时间压测中,GUI可能因内存不足崩溃,建议使用CLI模式执行:
jmeter -n -t test.jmx -l result.jtl - 资源消耗优化:关闭非必要监听器(如View Results Tree),减少内存占用。
⏰ 2. 时间同步与时区配置
- 本地时间校准:测试前确保数据库与JMeter所在机器时区一致,避免时间条件过滤失效(如
NOW() - INTERVAL)。 - 数据库时区设置:若使用TIMESTAMPTZ类型,需统一时区配置:
SET TIME ZONE 'Asia/Shanghai';
🇨🇳 3. 中文环境适配
- 系统语言配置:需操作系统语言设为中文,JMeter界面方可切换为简体中文(
Options → Choose Language → 中文)。 - 编码兼容性:数据中含中文时,JDBC URL需添加参数:
?characterEncoding=UTF-8
🔄 4. 测试数据关联性验证
- 设备ID匹配规则:确保插入的随机设备ID(如dev001~dev010)与元数据表严格一致,避免JOIN失效。
- 数据预热策略:测试前预插入基础元数据(如
device_metadata),防止空表导致查询无结果。
🔗 5. 数据库连接池管理
- 连接泄漏规避:在JDBC配置中设置最大连接数:
并启用连接验证(Validation Query)。max_connections=50 - 超时重试机制:URL添加超时参数,避免网络抖动导致连接中断:
socketTimeout=30000
📊 6. 性能监控与诊断
- 资源瓶颈定位:使用
nmon或vmstat监控数据库服务器 CPU/内存,结合EXPLAIN ANALYZE分析慢查询。 - 日志分级采集::启用慢查询日志,记录耗时较长的 SQL 语句,便于后续有针对性地进行优化。
九、总结
通过本次性能测试实践,我们深刻体会到
KWDB在高并发、复杂查询场景下的出色表现。其原生支持的时间分区和自动压缩功能,显著提升了写入效率和存储利用率。KWDB不仅具备强大的性能优势,还拥有良好的稳定性和易用性,使其成为替代传统数据库的理想选择。展望未来,随着技术的不断进步,KWDB必将在更多关键行业中发挥重要作用,推动核心技术自主可控的发展进程。