R基于多元线性回归模型实现汽车燃油效率预测及SHAP值解释项目实战
说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后关注获取。
1.项目背景
在全球环保意识日益增强和技术进步的推动下,汽车燃油效率成为了汽车行业关注的核心指标之一。提高燃油效率不仅有助于减少温室气体排放,还能显著降低车主的运营成本。然而,由于影响燃油效率的因素众多且复杂,包括但不限于发动机排量、马力、车重、空气动力学设计等,传统的基于经验或简单统计方法难以准确预测和优化燃油效率。因此,利用先进的数据分析技术和机器学习模型来预测和解释汽车燃油效率变得尤为重要。本项目旨在通过构建多元线性回归模型,结合SHAP(Shapley Additive exPlanations)值解释技术,深入分析并预测汽车燃油效率,为汽车行业提供科学依据和技术支持。
本项目的具体目标是开发一个能够准确预测汽车燃油效率的多元线性回归模型,并利用SHAP值解释技术揭示各个特征对模型预测结果的影响程度。为了实现这一目标,我们将首先收集并整理公开的汽车数据集,该数据集包含多个与燃油效率相关的特征变量。接着,通过探索性数据分析(EDA)识别出关键特征,并使用多元线性回归模型进行训练和验证。在模型评估阶段,我们将采用均方误差(MSE)、平均绝对误差(MAE)和决定系数(R²)等指标来衡量模型性能。此外,为了增强模型的可解释性,我们将引入SHAP值解释技术,生成可视化图表展示各特征对预测结果的具体贡献,帮助工程师和决策者更好地理解模型的工作机制。
通过本项目的实施,我们期望达到以下几方面的成果:首先,构建一个高精度的多元线性回归模型,能够有效预测汽车的燃油效率;其次,利用SHAP值解释技术生成直观的可视化图表,详细展示各个特征对模型预测结果的影响,从而提升模型的透明度和可信度;最后,基于模型预测结果和特征重要性分析,提出针对性的优化建议,如调整发动机参数或改进车身设计等,以进一步提高燃油效率。这些成果不仅有助于推动汽车行业向更加环保和高效的方向发展,还可以为其他领域的类似问题提供借鉴和参考。未来,随着更多高质量数据的积累和技术的进步,我们可以进一步优化模型结构,拓展其应用场景,为实现更广泛的节能减排目标贡献力量。
本项目通过R基于多元线性回归模型实现汽车燃油效率预测及SHAP值解释实战。
2.数据获取
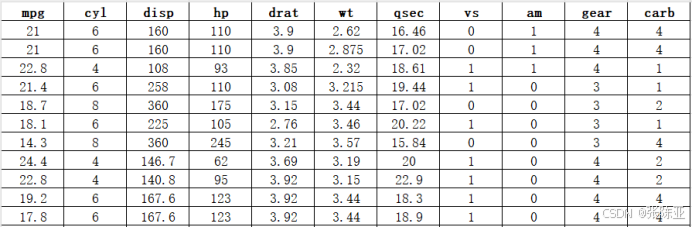
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
| 编号 | 变量名称 | 描述 |
| 1 | mpg | 因变量 Miles/(US) gallon - 每加仑燃油可以行驶的英里数(油耗),数值越高表示燃油效率越高。 |
| 2 | cyl | Number of cylinders - 发动机气缸的数量,一般有4、6或8个气缸,反映了发动机的大小和功率潜力。 |
| 3 | disp | Displacement (cu.in.) - 发动机排量,单位为立方英寸,反映了发动机内部所有气缸的总体积。数值越大通常意味着更强的动力输出。 |
| 4 | hp | Gross horsepower - 发动机的总马力,衡量发动机的最大功率输出能力。 |
| 5 | drat | Rear axle ratio - 后桥传动比,描述了驱动轴每转一圈车轮要转多少圈,影响车辆的加速性能和燃油经济性。 |
| 6 | wt | Weight (1000 lbs) - 车辆重量,以千磅为单位。车辆的重量对燃油经济性和加速度有显著影响。 |
| 7 | qsec | 1/4 mile time - 完成四分之一英里赛程所需的时间(秒),是衡量车辆加速性能的一个指标。 |
| 8 | vs | V/S - 发动机布局类型,0代表V型发动机,1代表直列式发动机。不同的发动机布局会影响车辆的平衡性和空间利用率。 |
| 9 | am | Transmission (0 = automatic, 1 = manual) - 变速箱类型,0表示自动变速器,1表示手动变速器。变速箱类型会影响驾驶体验和燃油经济性。 |
| 10 | gear | Number of forward gears - 前进挡位数量,指的是车辆变速箱中的前进档位数目。更多的挡位可以提高燃油效率和驾驶平顺性。 |
| 11 | carb | Number of carburetors - 化油器数量,化油器用于将空气和燃油混合后送入发动机燃烧室,多个化油器可以增加发动机的响应速度和动力输出。 |
数据详情如下(部分展示):
3.数据预处理
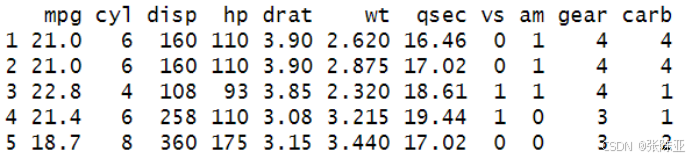
3.1 查看数据
使用head()方法查看前五行数据:
关键代码:

3.2数据缺失查看
使用colSums方法统计数据缺失信息:
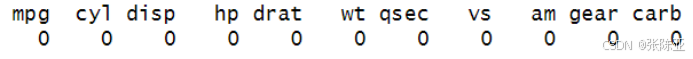
从上图可以看到,总共有11个变量,数据中无缺失值。
关键代码:

3.3数据描述性统计
通过summary方法来查看数据的平均值、最小值、分位数、最大值。

关键代码如下:

4.探索性数据分析
4.1 mpg变量分布直方图
用ggplot工具绘制直方图:
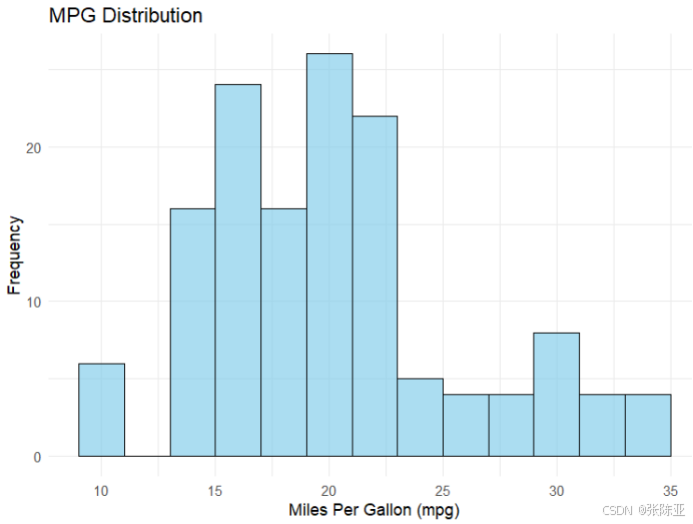
4.2 相关性分析
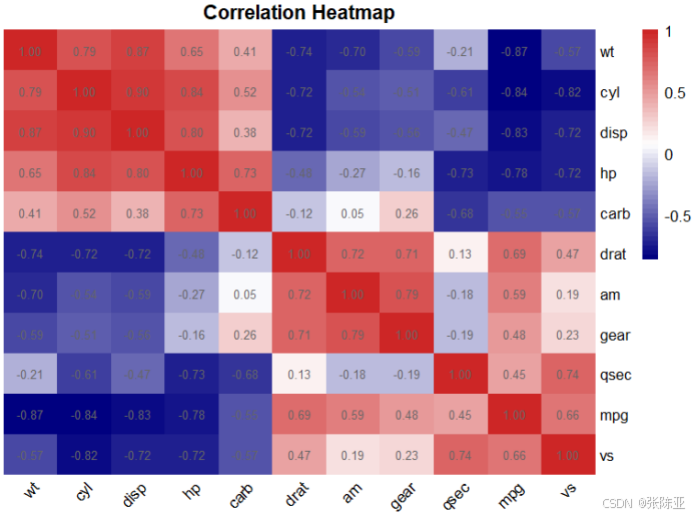
从上图中可以看到,数值越大相关性越强,正值是正相关、负值是负相关。
5.特征工程
5.1 数据集拆分
通过subset方法按照80%训练集、20%测试集进行划分,关键代码如下:

6.构建多元线性回归模型
主要使用通过R基于多元线性回归模型实现汽车燃油效率预测,用于目标回归。
6.1 构建模型
| 编号 | 模型名称 | 参数 |
| 1 | 多元线性回归模型 | mpg ~ . |
| 2 | data = train_data |
6.2 模型摘要信息
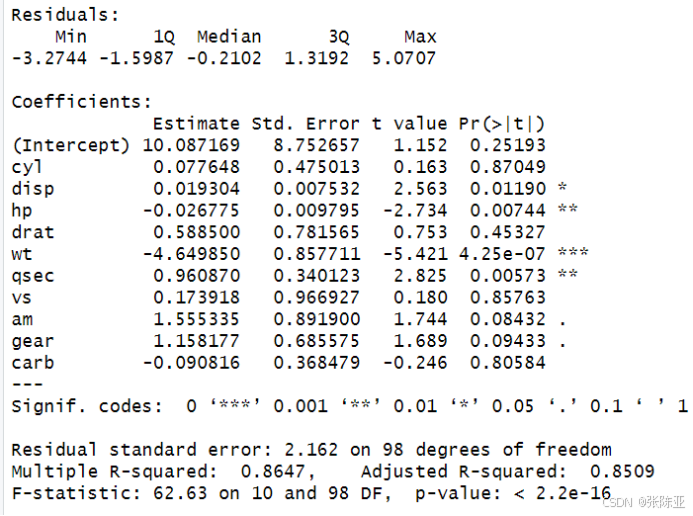
7.模型评估
7.1评估指标及结果
评估指标主要包括R方、均方误差、解释性方差、绝对误差等等。
| 模型名称 | 指标名称 | 指标值 |
| 测试集 | ||
| 多元线性回归模型 | R方 | 0.8677125 |
| 均方误差 | 4.533417 | |
| 解释方差分 | 0.8677953 | |
| 绝对误差 | 1.604026 | |
从上表可以看出,R方分值为0.8677,说明模型效果良好。
关键代码如下:

7.2 真实值与预测值对比图

从上图可以看出真实值和预测值波动基本一致,模型效果良好。
7.3 SHAP解释图
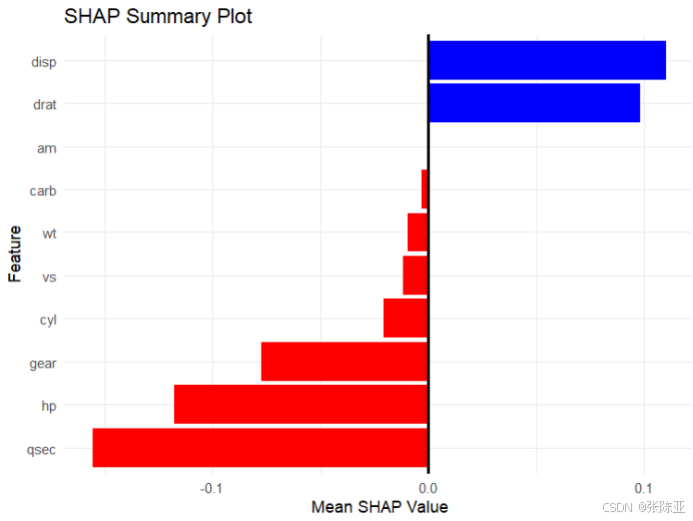
SHAP图通常用来展示特征对模型预测的贡献程度,从上图可以看出,蓝色代表正向影响,红色代表负向影响, SHAP值越大对模型的贡献越大。
8.结论与展望
综上所述,本文采用了R基于多元线性回归模型实现汽车燃油效率预测及SHAP值解释项目实战,最终证明了我们提出的模型效果良好。此模型可用于日常产品的预测。