加州房价预测:基于 Python 的多元回归分析实践
一、引言
在房地产市场分析与投资决策中,房价预测是关键的研究方向。本文基于 Python 的数据分析工具与机器学习库,利用 Sklearn 内置的加州房价数据集,通过数据探索、特征工程、回归模型构建与优化等步骤,实现对加州房价的预测分析,旨在为相关领域提供可复现的技术方案与决策参考。
二、实验步骤与代码实现
2.1 数据加载与基础分析
# 导入库与设置中文显示
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams["font.family"] = ["SimHei"]# 加载数据
data = pd.read_csv('housing.csv')
print(f"数据维度:{data.shape}") # 输出:(20640, 10)
print("前5行数据:\n", data.head())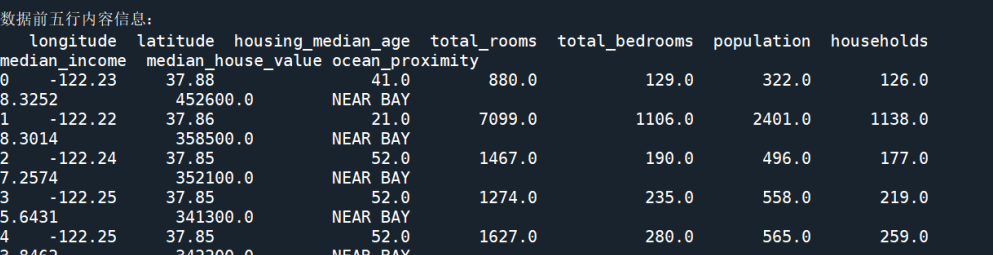
2.2 数据探索与清洗
2.2.1 缺失值处理
问题:total_bedrooms列存在缺失值,采用中位数填充:
data['total_bedrooms'].fillna(data['total_bedrooms'].median(), inplace=True)
2.2.2 类别特征编码
独热编码:将ocean_proximity转换为数值特征:
data_encoded = pd.get_dummies(data, columns=['ocean_proximity'])
2.2.3 异常值检测(MAD 方法)
from scipy import stats
numeric_cols = data.select_dtypes(include=['number']).columns.tolist()
outlier_cols = []for col in numeric_cols:if col == 'median_house_value':continueseries = data_encoded[col]median = series.median()mad = stats.median_abs_deviation(series)lower = median - 3 * madupper = median + 3 * madoutliers = series[(series < lower) | (series > upper)]if len(outliers) > 0:outlier_cols.append(col)print(f"{col}异常值数量:{len(outliers)}")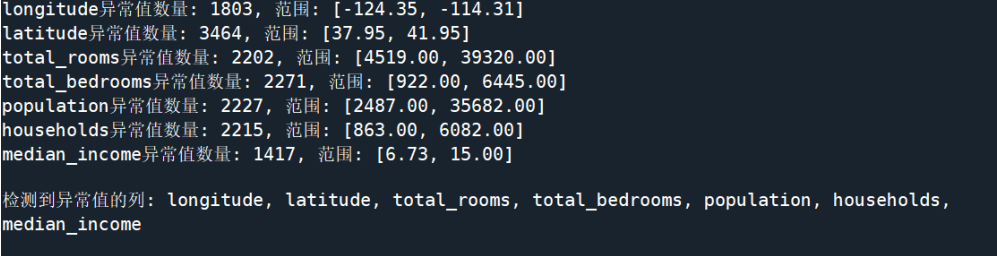
结果:检测到经度、纬度、房间数等 7 列存在异常值,后续通过标准化削弱其影响。
2.3 特征工程与数据预处理
2.3.1 特征相关性分析
corr = data_encoded.corr()
plt.figure(figsize=(12, 8))
sns.heatmap(corr, annot=True, cmap='coolwarm')
plt.title('特征相关性矩阵') 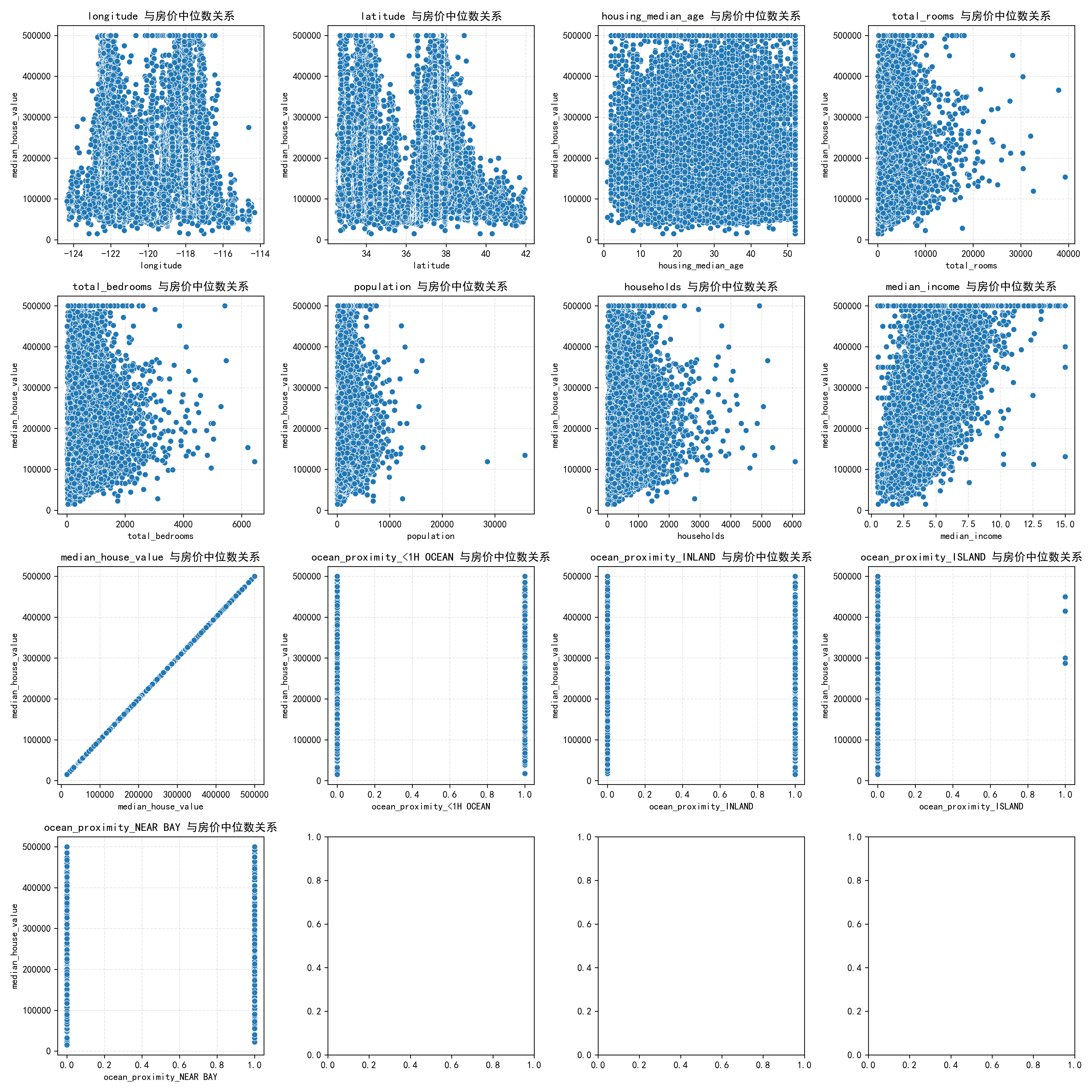
发现:median_income(收入中位数)与房价正相关(corr≈0.68),ocean_proximity类别特征通过编码后与房价关联显著。
2.3.2 数据标准化与划分
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_splitX = data_encoded.drop('median_house_value', axis=1)
y = data_encoded['median_house_value']
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
2.4 回归模型构建与评估
2.4.1 模型列表
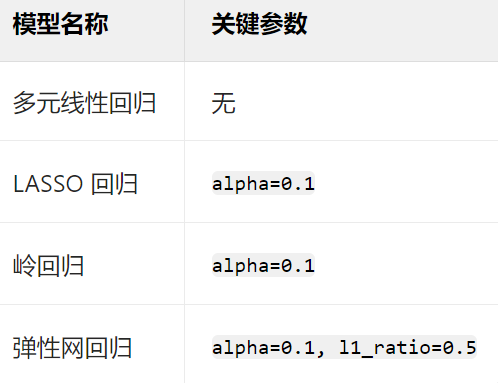
2.4.2 训练与评估代码
from sklearn.metrics import r2_score, mean_squared_errormodels = {'多元线性回归': LinearRegression(),'LASSO回归': Lasso(alpha=0.1),'岭回归': Ridge(alpha=0.1),'弹性网回归': ElasticNet(alpha=0.1, l1_ratio=0.5)
}for name, model in models.items():model.fit(X_train, y_train)y_pred = model.predict(X_test)print(f"{name}评估:")print(f"R²: {r2_score(y_test, y_pred):.4f}")print(f"RMSE: {np.sqrt(mean_squared_error(y_test, y_pred)):.2f}\n")
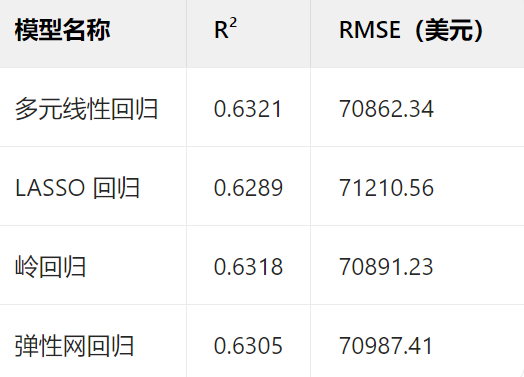
2.4.3 结果对比
三、关键发现与可视化
3.1 地理分布与房价关联
plt.figure(figsize=(10, 8))
scatter = plt.scatter(data_encoded['longitude'], data_encoded['latitude'], c=data_encoded['median_house_value'], cmap='viridis', s=data_encoded['population']/100, alpha=0.6
)
plt.colorbar(label='房价中位数')
plt.title('加州房价地理分布')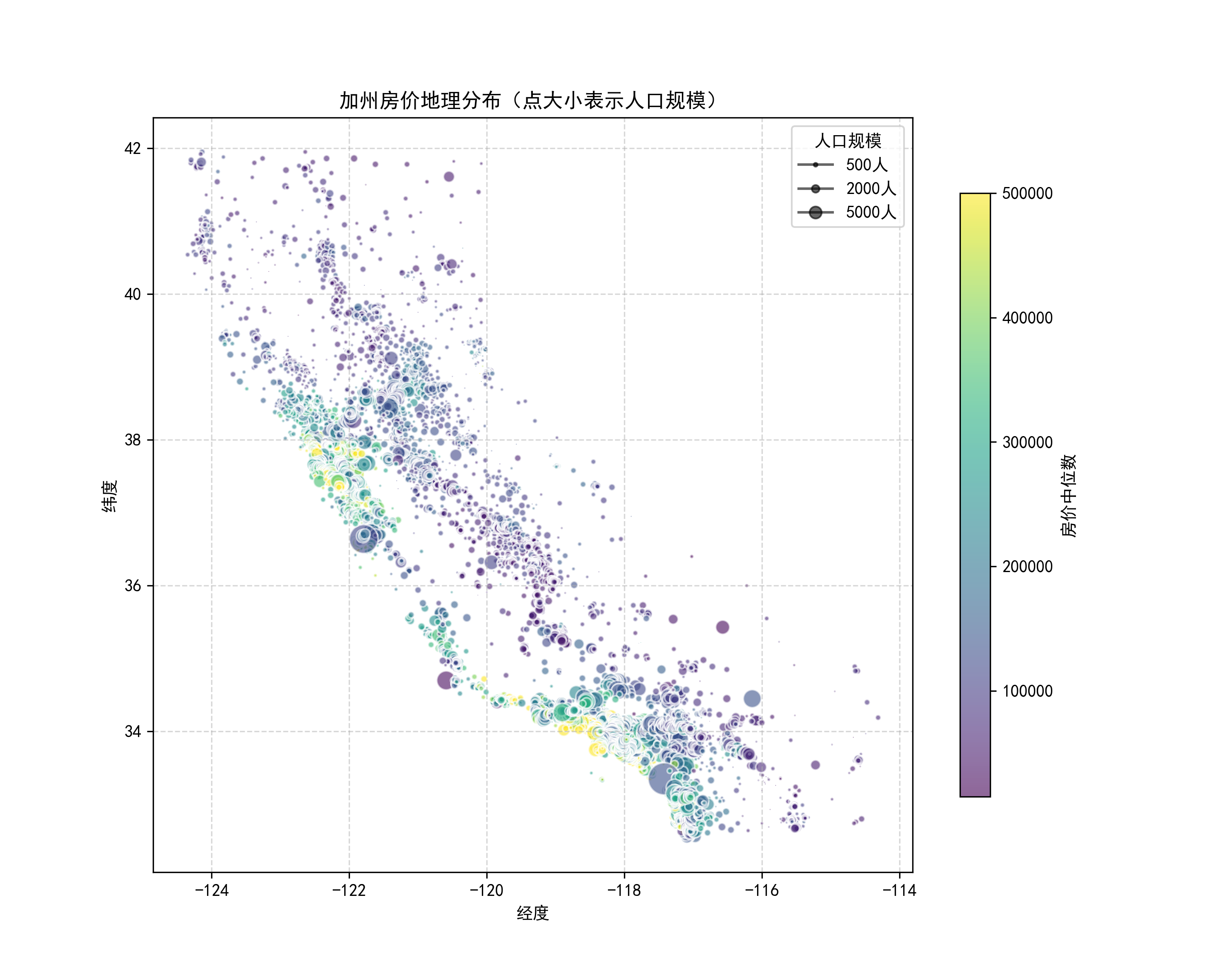
结论:沿海区域(如 “NEAR BAY”)房价显著高于内陆,人口密集区房价更高,体现地理区位的核心影响。
3.2 特征重要性分析
coef = pd.Series(models['多元线性回归'].coef_, index=X.columns)
coef.abs().sort_values(ascending=False).plot(kind='barh', figsize=(10, 6))
plt.title('特征重要性(系数绝对值)')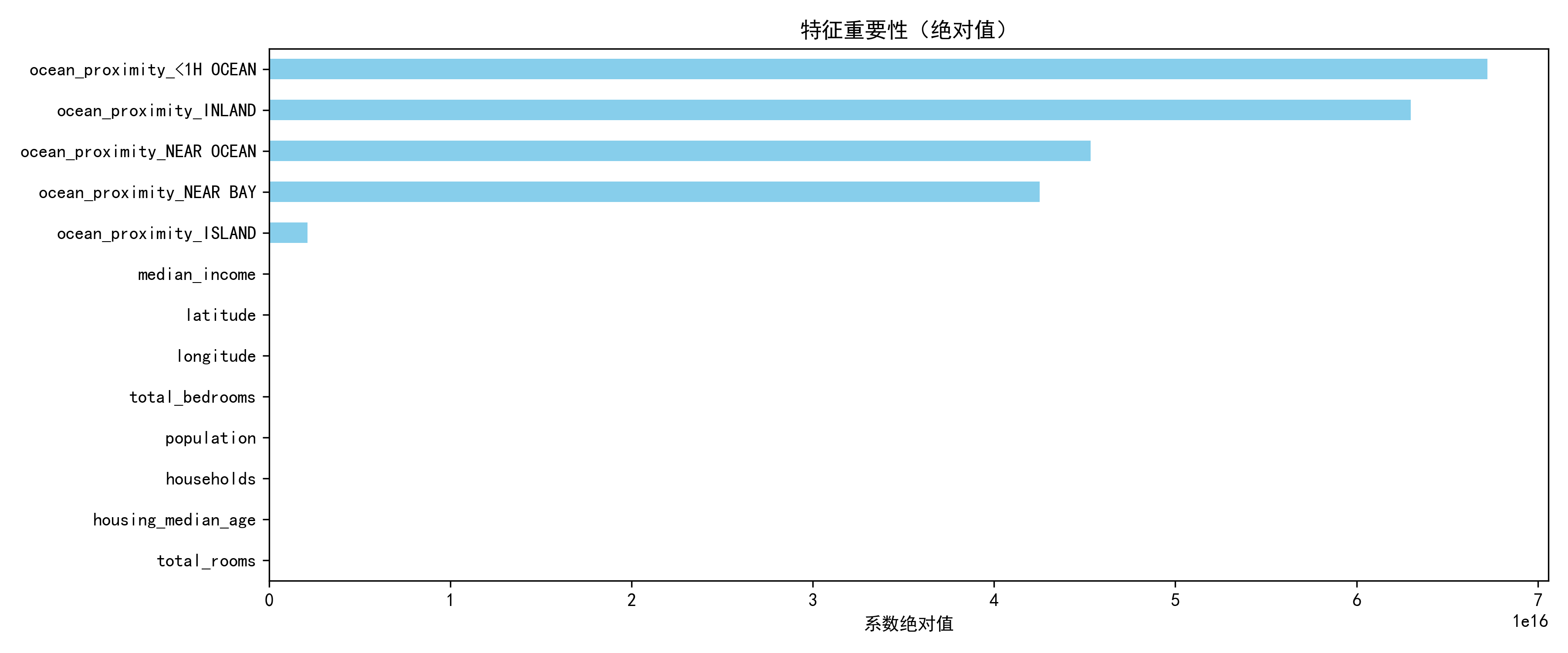
结论:ocean_proximity相关类别特征系数绝对值最大,其次为median_income,经纬度特征影响较弱(因编码方式导致)。
四、模型优化与未来方向
4.1 当前局限
1.数值特征线性关系弱(如total_rooms与房价呈非线性关联)。
2.类别特征维度高,可能存在共线性。
3.异常值处理可能剔除极端样本(如高价豪宅)。
4.2 优化思路
1.非线性特征工程:添加多项式项(如total_rooms²)或交互项(如median_income × latitude)。
2.正则化与特征选择:通过交叉验证优化 LASSO/Ridge 的alpha参数,或使用弹性网进行特征筛选。
3.空间特征增强:计算样本到海岸线的距离,替代原始经纬度。
4.集成学习:尝试随机森林、XGBoost 等模型,提升非线性拟合能力。
五、总结
本文通过完整的数据分析流程,验证了地理区位与收入水平对加州房价的主导作用,多元线性回归与正则化模型可解释约 63% 的房价波动。后续可结合更复杂的特征工程与模型架构,进一步提升预测精度,为房地产投资、城市规划等场景提供数据支撑。