ConvSearch-R1: 让LLM适应检索器的偏好或缺陷
论文标题
ConvSearch-R1: Enhancing Query Reformulation for Conversational Search with Reasoning via Reinforcement Learning
论文地址
https://arxiv.org/pdf/2505.15776
代码地址
https://github.com/BeastyZ/ConvSearch-R1
作者背景
复旦大学,字节跳动,新南威尔士大学
动机
在对话式检索场景中,用户输入的query可能存在歧义、遗漏、共指、错别字等问题,导致系统无法准确捕捉用户意图;query重写(Conversational Query Reformulation, CQR)是一种常用解决方案,核心思想是将带上下文的用户query重写为自包含(能独立表达完整查询意图的文本)形式,再去调用检索器处理。重写后的query显式包含上下文中隐含的信息,并且在实现过程中可以充分复用现有成熟的检索技术
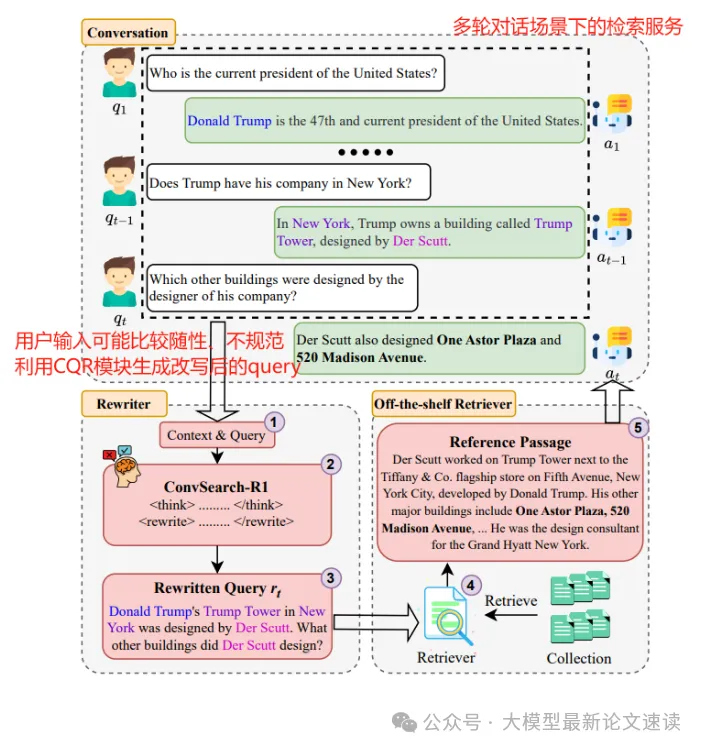
实际上,即便用户query很标准规范,检索系统内部也可能存在模型表征能力不足、文档治理不充分的缺陷,导致查找不到目标文档(例如query语句“2024年经营情况”匹配不上“二〇二四年报”),此时也需要query改写来优化
但CQR方法在实际使用时存在缺陷:
- 需要有一个强LLM来准确完成重写任务,或者需要通过大量标注训练一个较小的专用模型,实现成本较高
检索器一般都有隐式的业务特性或固有缺陷,客观上更好的query未必能更好地找到目标文档,即CQR模型与下游检索器缺乏对齐 - 尽管有一些最新方法尝试将检索反馈融入重写优化中,但它们仍然离不开初始的人工数据,并且大多仅限于利用成对比较的偏好信号。于是本文提出了ConvSearch-R1,希望通过强化学习让LLM学会更高效的query重写,并与下游检索环境对齐
与之前介绍的Search-R1相比,此工作的差异在于:
- Search-R1是更通用的推理+搜索模型,未考虑搜索工具的业务特性;而ConvSearch-R1专注于query重写这一话题,更适合检索器不完美的真实业务场景
- Search-R1仅以搜索结果与ground truth是否匹配为优化目标;而ConvSearch-R1则基于检索结果排序位置设计奖励,奖励信号更稠密、学习更高效
search-r1:让大模型学会自己使用搜索引擎
本文方法
与Search-R1类似,ConvSearch-R1也是要求模型先思考再发起检索请求,以便于充分消化上下文中的信息缺失和歧义
在模型训练方面,ConvSearch-R1采用了两阶段策略来集成推理能力并利用强化学习进行优化:
一、自驱动预热
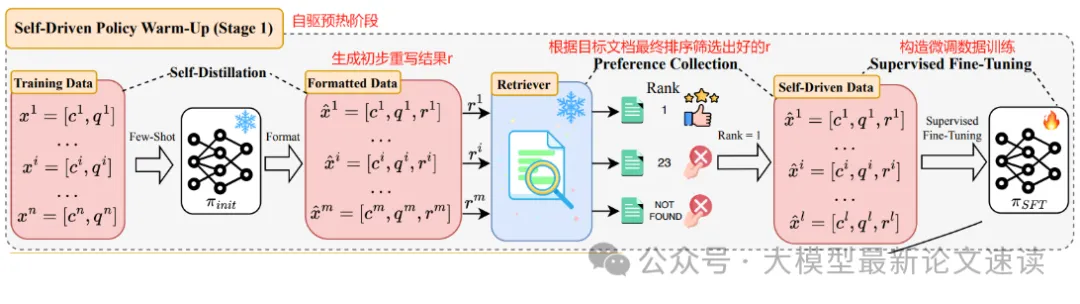
假设我们已经有一批不完美的<context, query, doc> (可以使用强LLM根据doc构造),通过精心设计的prompt让模型在少量示例的引导下对大量query进行推理并生成重写query,然后将重写结果送入检索器,根据检索排名筛选出效果好的重写,如此便在没有任何人工答案或外部教师的情况下,自行蒸馏出了一个初始重写数据集(SD-DATA);接着对模型进行SFT使之具备符合格式要求的“先推理再重写”能力
二、检索引导的强化学习
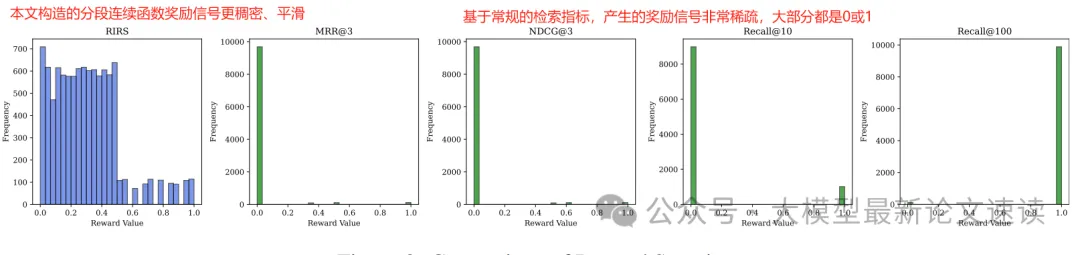
为了让模型生成的重写结果与检索器特性高度对齐,ConvSearch-R1基于重写query送入检索器后得到的相关文档排名计算奖励值(RIRS)。具体地,考虑到用户通常更关注顶部位置,RIRS采用分段奖励函数,分配差异化的奖励强度:为顶部位置(1-10)赋予较高奖励(如线性映射到1-2分),同时为中段位置(11- 100)保持成比例较小但仍具意义的奖励(如线性映射到0-1分)
此外ConvSearch-R1还应用了格式规则奖励,惩罚输出结果不符合要求(比如没有生成思考标签等)的响应

此方法在确保了策略优化过程中,反馈信号更加稠密,同时也保留了检索器给出的打分结果信息,使得奖励信号不仅区分成功/失败,还对排名提升幅度敏感。这样一来,即使模型生成的重写不能未完全命中目标文档,也能从部分排名改进中获得正向激励
在具体优化算法上,ConvSearch-R1采用了GRPO方法,允许模型在每次策略更新中考虑一组重写候选的相对效果,通过偏好比较来进行高效优化(模型会尝试多种不同的重写方式,根据检索结果确定更优的改写方向)。经过强化学习训练,ConvSearch-R1的重写策略与检索器高度契合,能够针对检索系统的偏好生成最有利于找到答案的查询表达
实验效果
一、实验设置
测试基准
- TopiOCQA:包含复杂话题和长对话的开放域问答数据集,具有挑战性
- QReCC:常用的对话问答重写评测数据集
检索器设置
- BM25:传统的文本检索方法
- ANCE:预训练的dense检索模型
评估指标
- MRR
- NDCG
- Recall
二、对比实验
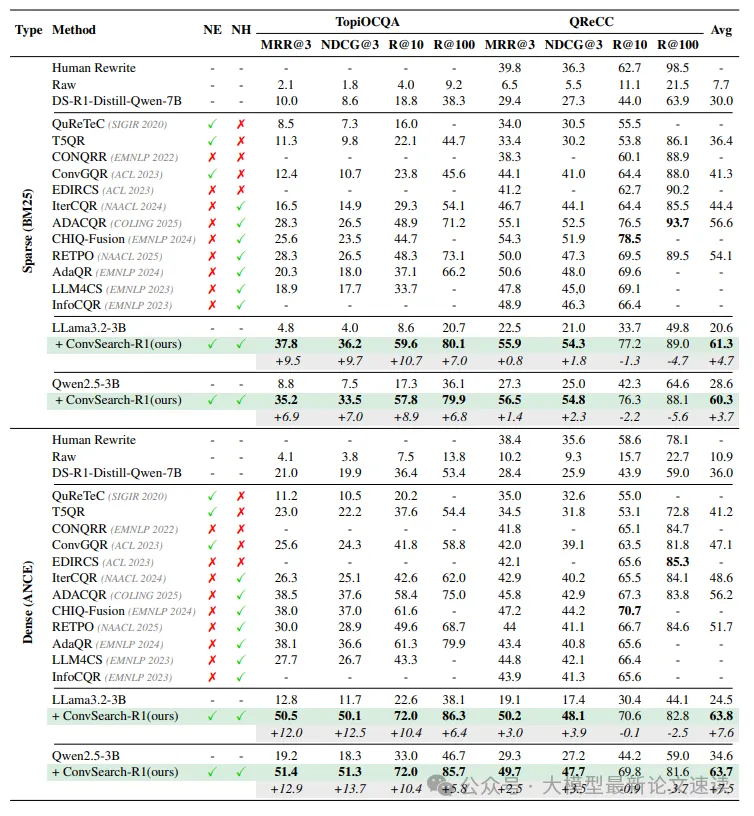
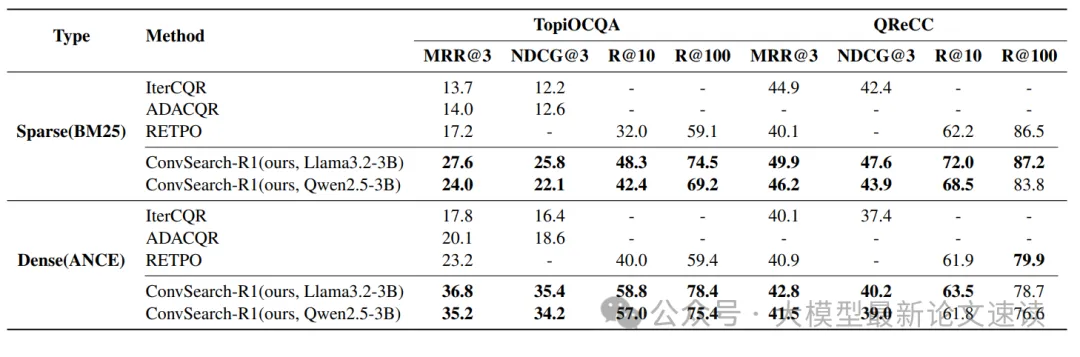
ConvSearch-R1全面超越了现有最先进方法,取得了新的sota性能。值得强调的是,ConvSearch-R1只使用了约3B模型作为重写器,却超过了先前基于7B模型的方法。在更具挑战性的TopiOCQA数据集上,ConvSearch-R1相较之前的最佳结果平均提升超过10%,这一显著增幅是在使用更小模型且完全没有借助任何人工重写或外部大模型数据的前提下获得的
此外还发现,即便是人去重写 query(human rewrite),最终效果也不如实验组甚至大部分先进对照组,这充分说明了检索器偏好与人类偏好的不一致,如果不做面向检索器的偏好训练,再强大的改写模型也无法弥合这一差距
三、消融实验
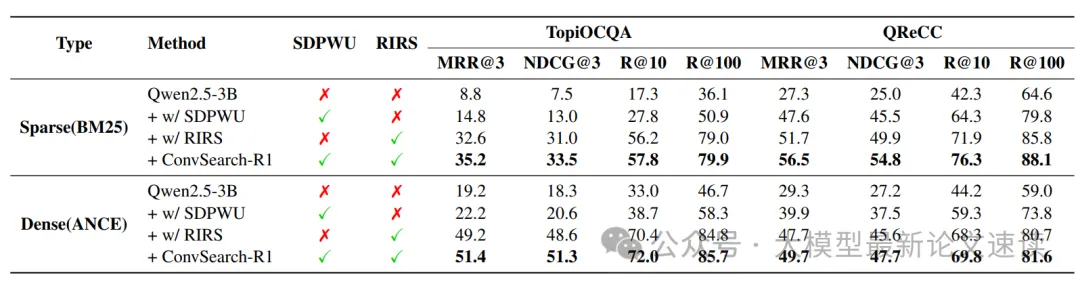
将模型直接用于重写(不经过任何自驱动预训练或强化学习)时,检索性能很低;而加入第一阶段的自驱动策略预热后,模型重写质量有了大幅提升。在此基础上,再通过第二阶段的强化学习优化,模型的排名指标进一步攀升,达到当前报告的最高水平
作者还进行了跨数据集的泛化测试:将ConvSearch-R1在一个数据集上训练后的模型直接用于另一个数据集的重写。结果显示,相较其他方法,ConvSearch-R1在未知数据集上的性能下降更小,表现出更好的泛化能力。这主要归功于强化学习过程中的排名激励机制,模型学会了“如何让重写更符合检索系统偏好”的通用策略,而非仅记忆特定数据集的表达方式