生成模型——变分自动编码器(Variational Autoencoders, VAEs)
一、自动化编码器
自动编码器(Autoencoder)是一种无监督学习的神经网络,它通过学习输入数据的高效表示来重构输入数据。自动编码器的目标是将输入编码成一个较低维度的表示,然后再从这个表示中重构出原始输入数据。这种网络结构通常用于数据降维、特征提取、去噪等任务。
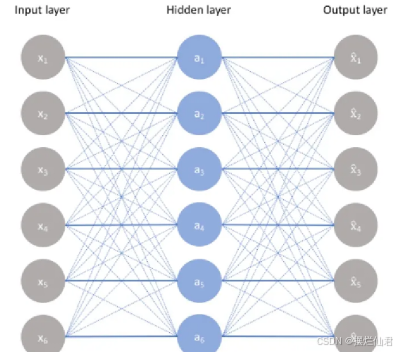
一个最简单的自编码器(上图所示)只有三层结构,从输入到隐藏层即为Encoder(编码器),从隐藏层到输出即为Decoder(解码器),而自动编码器的基本结构也可以据此可以分为三部分:
- 编码器(Encoder):编码器将输入数据压缩成一个低维的“编码”或“潜在表示”。这个编码是输入数据的压缩版本,通常比原始输入数据的维度要小。
- 瓶颈(Bottleneck):这是编码器输出和解码器输入之间的部分,它代表了数据的低维表示。瓶颈层的大小决定了数据压缩的程度。
- 解码器(Decoder):解码器的任务是从编码中重建输入数据。它接收编码器的输出,并尝试重构出与原始输入尽可能相似的数据。
编码器将输入进行编码,变成中间结果,中间结果再经过解码器还原,这种输入等于输出的结构没有什么实际意义。对于上述结构,如果我们只看左边部分,即编码器的部分,就很容易理解降维的原理:隐藏层神经元的数目远低于输入层,那么我们就可以用更少的特征(神经元)去表征输入数据,从而到降维目的。下面是一个使用Python和TensorFlow/Keras库实现的简单自动化编码器的示例代码:
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.models import Model# 生成一些示例数据
data = np.random.rand(1000, 20) # 1000个样本,每个样本20个特征# 定义输入层
input_dim = data.shape[1] # 特征数量
encoding_dim = 3 # 编码后的维度# 输入层
input_layer = Input(shape=(input_dim,))
# 编码层
encoded = Dense(encoding_dim, activation='relu')(input_layer)
# 解码层
decoded = Dense(input_dim, activation='sigmoid')(encoded)# 自动编码器模型
autoencoder = Model(input_layer, decoded)# 编码器模型
encoder = Model(input_layer, encoded)# 构建解码器模型
encoded_input = Input(shape=(encoding_dim,))
decoder_layer = autoencoder.layers[-1] # 取出解码层
decoder = Model(encoded_input, decoder_layer(encoded_input))# 编译自动编码器模型
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')# 训练自动编码器
autoencoder.fit(data, data, epochs=50, batch_size=256, shuffle=True)# 使用编码器将数据编码
encoded_data = encoder.predict(data)# 使用解码器重建数据
decoded_data = decoder.predict(encoded_data)print("原始数据形状:", data.shape)
print("编码后的数据形状:", encoded_data.shape)
print("解码后的数据形状:", decoded_data.shape)这个示例展示了如何使用自动化编码器进行基本的数据压缩和重建。你可以根据需要调整编码维度和网络结构。
二、变分自动编码器
变分自动编码器(Variational Autoencoders, VAEs)在自动编码器的基础上结合了概率生成模型,用于生成新的数据点。
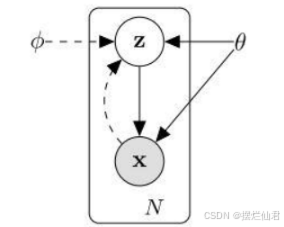
我们能观测到的数据是x,而x由隐变量z产生,由z→x是生成模型p(x|z),从自编码器(auto-encoder)的角度来看,就是解码器;而由x→z是识别模型(recognition model)q(z|x),类似于自编码器的编码器。
- 概率编码:与传统自编码器不同,VAEs的编码器输出的不是单一的潜在表示,而是潜在空间中的概率分布参数(通常是均值和方差),这允许模型在潜在空间中进行采样,从而生成新的数据点。
- 重参数化技巧:VAEs使用重参数化技巧来实现从潜在分布中的采样,并确保整个过程可导,从而可以使用反向传播进行训练。具体来说,如果潜在变量z服从分布P(z|x),可以通过从标准正态分布中采样噪声ϵ 并使用变换z=μ+σ*ϵ 来获得z,其中μ 和σ 是编码器网络的输出。
- 目标函数:VAEs的目标函数包括两部分:重构损失(衡量生成数据与原始数据的相似度)和KL散度(衡量潜在分布与先验分布的差异)。通过优化这个目标函数,VAEs能够在学习数据有效表示的同时,保持潜在空间的连续性和平滑性。
- 应用:VAEs最直观的应用之一是数据生成,它可以学习数据的潜在分布,并从这个分布中采样生成新的数据样本。此外,VAEs还可以用于降维与可视化、异常检测等领域。
- 在推荐系统中的应用:VAEs在推荐系统中可以提升用户体验和系统性能,通过学习用户的兴趣和行为模式,提供更精准的推荐。VAEs能够捕捉用户兴趣的分布,并通过调整正则化因子来控制学习效果,以适应不同的应用场景。
VAE的目标是学习输入数据的潜在表示,并能够从这些潜在表示中生成新的数据样本。下面是一个使用Python和TensorFlow/Keras库实现的简单变分自动编码器的示例代码:
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense, Lambda
from tensorflow.keras.models import Model
from tensorflow.keras import backend as K# 参数设置
original_dim = 784 # 输入数据的维度,例如MNIST数据集是784
intermediate_dim = 64 # 编码器和解码器中的隐藏层维度
batch_size = 100 # 批处理大小
latent_dim = 2 # 潜在空间的维度
epochs = 50 # 训练的轮数# VAE模型需要两个模型:编码器和解码器
# 编码器
inputs = Input(shape=(original_dim,))
h = Dense(intermediate_dim, activation='relu')(inputs)
z_mean = Dense(latent_dim)(h)
z_log_var = Dense(latent_dim)(h)# 重参数技巧
def sampling(args):z_mean, z_log_var = argsbatch = K.shape(z_mean)[0]dim = K.int_shape(z_mean)[1]epsilon = K.random_normal(shape=(batch, dim))return z_mean + K.exp(0.5 * z_log_var) * epsilonz = Lambda(sampling, output_shape=(latent_dim,))([z_mean, z_log_var])# 编码器模型
encoder = Model(inputs, [z_mean, z_log_var, z])
encoder.summary()# 解码器
latent_inputs = Input(shape=(latent_dim,))
x = Dense(intermediate_dim, activation='relu')(latent_inputs)
outputs = Dense(original_dim, activation='sigmoid')(x)# 解码器模型
decoder = Model(latent_inputs, outputs)
decoder.summary()# VAE模型
outputs = decoder(encoder(inputs)[2])
vae = Model(inputs, outputs)# VAE损失函数
reconstruction_loss = K.sum(K.binary_crossentropy(inputs,这个示例展示了如何使用变分自动编码器进行数据的潜在表示学习和新数据样本的生成。你可以根据需要调整网络结构和参数