【LUT技术专题】极小尺寸LUT算法:TinyLUT

TinyLUT: Tiny Look-Up Table for Efficient Image Restoration at the Edge(2024 NeurIPS)
- 专题介绍
- 一、研究背景
- 二、TinyLUT方法
- 2.1 Separable Mapping Strategy
- 2.2 Dynamic Discretization Mechanism
- 三、实验结果
- 四、总结
本文将从头开始对TinyLUT: Tiny Look-Up Table for Efficient Image Restoration at the Edge,这篇极致轻量化的LUT算法进行讲解,这篇主要的亮点在于作者利用LUT去替代计算从而大幅减小了LUT的尺寸,在更小的尺寸下达到了更好的效果。参考资料如下:
[1]. TinyLUT论文地址
[2]. TinyLUT代码地址
专题介绍
Look-Up Table(查找表,LUT)是一种数据结构(也可以理解为字典),通过输入的key来查找到对应的value。其优势在于无需计算过程,不依赖于GPU、NPU等特殊硬件,本质就是一种内存换算力的思想。LUT在图像处理中是比较常见的操作,如Gamma映射,3D CLUT等。
近些年,LUT技术已被用于深度学习领域,由SR-LUT启发性地提出了模型训练+LUT推理的新范式。
本专题旨在跟进和解读LUT技术的发展趋势,为读者分享最全最新的LUT方法,欢迎一起探讨交流,对该专题感兴趣的读者可以订阅本专栏第一时间看到更新。
系列文章如下:
【1】SR-LUT
【2】Mu-LUT
【3】SP-LUT
【4】RC-LUT
【5】EC-LUT
【6】SPF-LUT
【7】Dn-LUT
一、研究背景
TinyLUT从名字就可以看到,作者是做了一个极小尺寸的LUT算法,可以看下图,作者画出了TinyLUT与其他算法的尺寸效果对比图。

图中可以发现很多熟悉的面孔,包含专栏前面讲到过的SRLUT、RCLUT、MuLUT、SPLUT以及SPFLUT,TinyLUT-S尺寸的优势非常明显,且效果是优于SRLUT以及SPLUT-S的,足以证明其策略对于尺寸压缩的优势,TinyLUT-F更是占据了最好的效果的同时,尺寸也是最小的。那么作者是如何做到这个效果的,主要是以下2个策略:
- 提出了Separable Mapping Strategy(分离映射策略)来解决因为LUT维度过大导致的尺寸爆炸问题。
- 设计了一种Dynamic Discretization Mechanism(动态离散化机制)来分解激活并压缩相应的量化尺度,在不造成较大精度损失的情况下进一步缩小存储需求。
作者通过很多实验证明了这两个策略训练后的TinyLUT可以在最小存储量的同时,比其他LUT方法的效果还要更好,展示了LUT-Based方法的潜力。
二、TinyLUT方法
TinyLUT网络结构如下图所示:

有以下2个重点:
- 输入分为MSBs和LSBs,分别经过一样的分支进行处理,这里可以发现整体结构跟专栏前面讲到过的SPLUT是很相像的,当然作者会在这基础上做了进一步的优化,后续会提到。
- 每一个支路由以下基础模块,3x3 Conv、PwBlock以及3x3 DwConv组合而成,最后将MSB和LSB进行一个相加并经过pixelshuffle层进行一个超分输出。
前面提到的两个策略会在这几个模块中体现出来,接下来会进行具体阐述。
2.1 Separable Mapping Strategy
一个老生常谈的问题,以前的LUT方法例如SRLUT,感受野越大,尺寸会爆炸性增长,这个策略就是为了解决这个问题,如下表所示。

可以看到,一个2x2 pixels的RF,需要4D的LUT,如果采用Full size来存储计算就是64GB=256 * 256 * 256 * 256 * 16 / 1024 / 1024 / 1024,而使用SRLUT的均匀采样后也需要1.27MB=17 * 17 *17 * 17 * 16 / 1024 / 1024。若采用本文的SMS策略,则可以减到16KB。再加上DDM后会更小。
SMS策略包含两个部分,分别是空间和通道的。
- 空间的SMS策略,如下图所示:
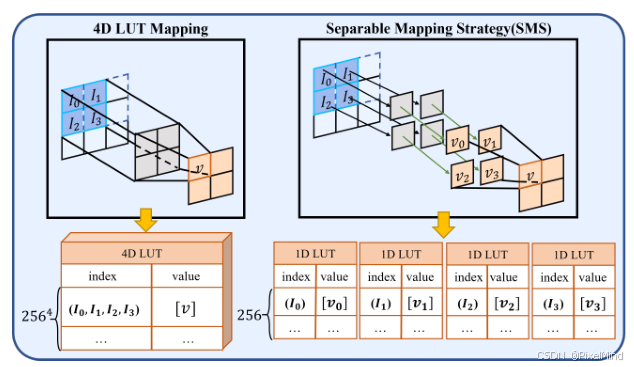
可以看到以前查询一个窗口时通过直接查询 I0 - I3 这4个点得到一个结果,这使得LUT维度太大,尺寸爆炸性增长(256^4),那作者就想换一个方式,先利用4个1D LUT查询每个点对应的结果,然后再将这些结果进行相加,这样我们发现就可以将LUT尺寸减小为(256*4)。博主认为,大家可以将SMS这个操作认为是将以前卷积计算的过程修改为一个LUT查找的过程,即用一次查找替换了一次乘法,以前LUT方法当然也是在用LUT替换计算,但其因为替换了更多的乘法和加法,因此需要更多的维度,也导致了尺寸爆炸增长。作者将这个过程用公式表示:
F ^ out = 1 n 2 ∑ i = 0 n − 1 ∑ j = 0 n − 1 L U T ( i , j ) [ x ( i , j ) ] \hat{F}_{\text {out }}=\frac{1}{n^{2}} \sum_{i=0}^{n-1} \sum_{j=0}^{n-1} L U T_{(i, j)}\left[x_{(i, j)}\right] F^out =n21i=0∑n−1j=0∑n−1LUT(i,j)[x(i,j)]
这里的n代表窗口的尺寸,例如SRLUT就是n=2,可以发现SMS空间的策略是一个Depthwise Conv,只在空间维度上操作。
- 通道的SMS策略,作者设计了一个模块叫PwBlock,如下图所示。

通道的交互,原理跟空间上的是一样的,在通道上我们仍然可以将查询维度变成1D,然后再加起来模拟正常的点卷积。图中可以看到有多个PwConv和ReLU串联,那因为最后这个PwBlock要变成一堆1D LUT,那么我们就需要确保每次只处理一个输入通道,相当于普通卷积设置groups参数为cin,如果此时cout=cin的话,就变成了我们熟悉的通道可分离卷积,最后的LUT查找过程跟空间上是大同小异的,公式如下所示:
F ^ out = 1 C in 2 ∑ c = 0 C in L U T c [ x c ] \hat{F}_{\text {out }}=\frac{1}{C_{\text {in }}^{2}} \sum_{c=0}^{C_{\text {in }}} L U T_{c}\left[x_{c}\right] F^out =Cin 21c=0∑Cin LUTc[xc]
可以看到一个输出通道是由Cin个LUT相加得来,尺寸也从(256 ^ Cin * Cout * 8bit)变成了(256 * Cin * Cout * 8bit)。
2.2 Dynamic Discretization Mechanism
前面提到TinyLUT会做MSB和LSB的分离,这个策略就是针对这个地方进行更深度的优化。因为数据是8bit,范围是[-128,127],当我们分成MSB和LSB时,MSB的范围是[-m,m-1],LSB的范围是[0,k](LSB是无符号的原因是MSB拿到了符号位),那我们可以根据MSB和LSB来推理出此时LUT的尺寸。
S i z e ( M S B ) = ( 2 ∗ m ) ∗ n 2 ∗ r 2 Size(MSB)=(2*m)*n^{2}*r^{2} Size(MSB)=(2∗m)∗n2∗r2 S i z e ( L S B ) = ( k + 1 ) ∗ n 2 ∗ r 2 Size(LSB)=(k+1)*n^{2}*r^{2} Size(LSB)=(k+1)∗n2∗r2
自然,尺寸这么计算的原因是因为MSB和LSB范围分别是2*m和k+1,然后我们再乘以kernel_size(n)和放大倍数(r)。这么一分析我们也能明白,分离能够将LUT尺寸减小的原因在于输入索引的范围减小了,为进一步优化,作者引入可学习裁剪参数 α \alpha α 以缩小范围为了进一步对其进行优化,公式如下所示:
F q = r o u n d ( F ∗ α y ) F_q=round(F*\alpha_{y}) Fq=round(F∗αy),其中 α y \alpha_{y} αy是一个放缩的系数,当我们减小F(MSB或LSB)时,自然可以进一步减小尺寸,尺寸可以减小至下列公式所示大小: S i z e = ( m a x ( F q ) − m i n ( F q ) ) ∗ n 2 ∗ r 2 Size=(max(F_q)-min(F_q))*n^2*r^2 Size=(max(Fq)−min(Fq))∗n2∗r2计算逻辑跟上面一致,作者还用了一个图来描述这个过程。

可以看到MSB开始是6bit,使用 α m \alpha_m αm之后可以被压缩,因为压缩了,自然LUT的尺寸就减小了,多个index对应的其实是一个value,且这个过程是单调的,可以作为一个LUT的index保存。作者提到这个优化手段会使用 α \alpha α为0.8的初值,且在后期的优化过程中,使用L2正则去控制它的大小,自然越小会有更强的压缩比。
博主这里的想法:使用这种压缩方法会不会使得查询过程引入更多的计算,因为 α \alpha α的存在虽然储存量增加微乎其微,但需要去对原始index做一个放缩从而找到放缩后的index,这个地方可能会引入多余的计算,在代码讲解的地方可以验证。
三、实验结果
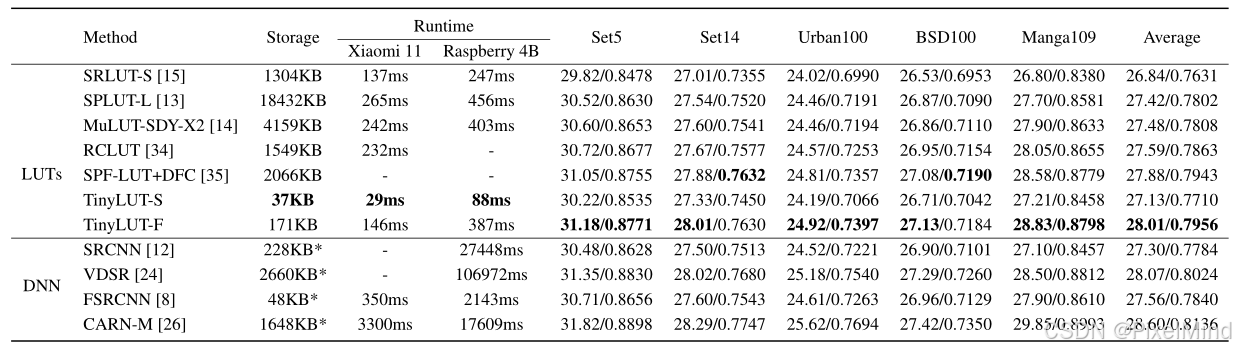
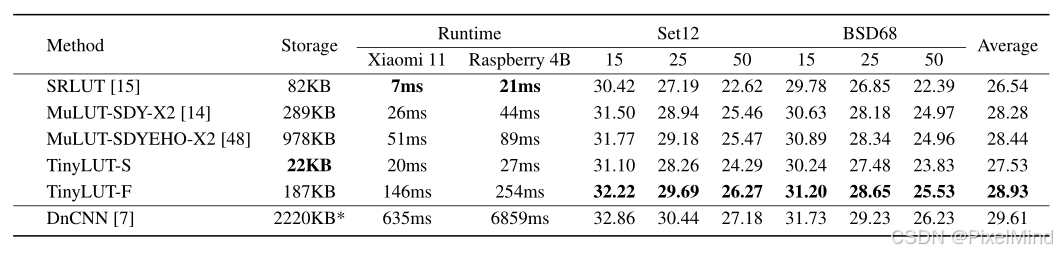
定量的实验结果显示:TinyLUT在LUT方法中效果是最具有性价比的,无论是效果上还是耗时和内存占用上。
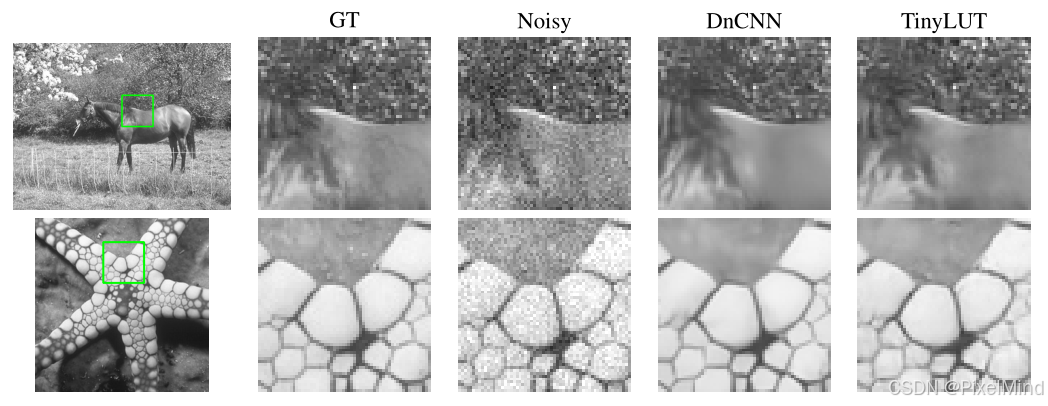
定性的实验结果显示,结论是一致的,强于FSRCNN,在LUT中是最具有性价比的。

接下来作者进行了消融实验:
1)SMS的消融实验:

SMS策略的有效性证明,作者对比了SMS与不压缩和均匀压缩的效果,显然优势很明显,效果逼近不压缩的结果,但是LUT Size是最小的。
2)DDM的消融实验:

作者对比了使用前后的指标,基本没变化,但是LUT size进一步减小了,所以是非常有效的。进一步的,作者使用了一个图来说明DDM的优势。

图中,红线显示的MSB 6bit的范围,自然是64,TinyLUT-S- α \alpha α是学习的范围,TinyLUT-S-E是实际数据所在的范围,可以基本学习到的可以包围数据的范围,说明学习到的 α \alpha α对激活数据的精度进行了自适应的调整,减小了输入数据的范围,自然就减小了LUT的大小,做到了物尽其用,空间没有浪费,因此可以做到无损的减小LUT尺寸。
四、总结
TinyLUT的方法相当于做了LUT实现的卷积网络,配合上原有的一些量化知识和技巧对其继续做了容量的削减,整体做了深度的优化,从指标上也能看到优势是非常明显的,可以期待下作者后续是否可以继续扩大尺寸或者扩展到其他新型结构上(transformer或mamba),这点在文章的limitations一节也有提到。
代码部分将会单起一篇进行解读。(未完待续)
感谢阅读,欢迎留言或私信,一起探讨和交流,如果对你有帮助的话,也希望可以给博主点一个关注,谢谢。