生产环境CPU飙升问题排查与优化实战
1.问题背景与影响
CPU使用率飙升是计算机系统中常见的性能问题,它反映了处理器资源被过度消耗的状态。这一问题在各类计算环境中都可能出现,从个人电脑到企业级服务器,从本地应用到云计算平台。CPU飙升通常表现为系统响应变慢、服务超时甚至宕机,根据我线上问题问题排查经验,将从以下几个方面进行描述。

1.1 CPU飙升的典型表现
CPU使用率突然或持续升高到80%甚至100%,通常伴随:
- 系统响应变慢或服务不可用
- 请求超时率上升
- 线程阻塞或资源竞争
- 可能伴随内存增长或GC频繁
- 典型表现情况如下表格所示:
| 表现类型 | 特征描述 | 典型案例 | 常见场景 |
|---|---|---|---|
| 持续高占用 | CPU使用率长时间维持在80%-100% | 死循环、频繁GC | Java应用、数据库 |
| 间歇性峰值 | CPU周期性突然升高后回落 | 定时任务、批处理 | 大数据处理、报表生成 |
| 阶梯式增长 | CPU使用率逐步上升不回落 | 内存泄漏、连接泄漏 | 长期运行的服务 |
| 单核满载 | 单个CPU核心100%,其他空闲 | 单线程计算密集型任务 | 视频转码、加密解密 |
| 整体高负载 | 所有CPU核心均高负载 | 高并发请求、全表扫描 | Web服务、数据库查询 |
- 一些案例情况有:Java死循环案例,MySQL索引缺失案例,线程空转案例
1.Java死循环案例
表现:单个Java进程CPU使用率可达700%+(8核机器)
@RestController
public class CpuController {private static boolean running = true;@GetMapping("/cpu-loop")public String triggerLoop() {while(running) { // 无条件循环int a = 1 + 1; // 简单计算消耗CPU}return "success";}
}2. MySQL索引缺失案例
表现:MySQL进程CPU使用率可达900%
-- 没有索引的频繁查询
SELECT * FROM user WHERE user_code = 'xxx'; -- user_code字段无索引3.线程空转案例
表现:CPU持续高负载但实际无业务处理
// Netty空轮询BUG的简化示例
while(true) {if(selector.select(100) == 0) {// 没有事件但立即返回,导致空轮询continue;}// 处理事件...
}1.2 对业务系统的影响
CPU飙升会对系统运行产生多方面的负面影响,这些影响根据环境严重程度可能表现为暂时性性能下降或持续性服务中断。
系统性能影响
响应延迟与卡顿:最直接的表现是系统响应变慢,用户操作出现明显延迟。对于交互式应用,这种延迟会严重影响用户体验;对于服务端应用,则会导致请求处理超时。
吞吐量下降:CPU资源饱和会导致系统整体吞吐量降低。在服务器环境中,这意味着能够处理的并发请求数减少,服务能力下降。特别是在高流量网站或高频交易系统中,这种影响可能造成严重业务损失。
调度开销增加:当CPU资源紧张时,操作系统需要进行更频繁的上下文切换(context switch),这种切换本身也会消耗CPU资源,形成恶性循环。大量线程竞争有限CPU资源时,非自愿上下文切换(nvcswch)次数会显著增加。
系统稳定性影响
服务中断风险:持续的高CPU负载可能导致关键服务无法获得足够资源而停止响应。在生产环境中,这可能引发服务级联故障,如数据库连接池耗尽、中间件超时等。
过热与硬件损伤:CPU长时间高负荷运行会产生大量热量,如果散热系统不足,可能导致处理器过热降频(throttling)甚至硬件损坏。笔记本电脑等移动设备上,还会加速电池耗尽。
业务与运维影响
用户体验恶化:对于面向用户的应用,响应迟缓会直接降低用户满意度,增加用户流失率。研究表明,网页加载时间每增加1秒,转化率可能下降7%。
运维成本增加:CPU飙升问题往往需要紧急介入处理,消耗大量运维人力资源。反复出现此类问题还会迫使企业提前进行硬件升级,增加IT成本。
数据一致性风险:在数据库等关键系统中,CPU资源不足可能导致事务处理异常,甚至引发数据不一致问题。如在MySQL中,高CPU使用率可能伴随着锁等待和死锁。
影响维度分析表
| 影响维度 | 短期影响 | 长期影响 | 典型案例 |
|---|---|---|---|
| 响应时间 | 接口超时,响应变慢 | 用户流失,转化率下降 | 电商下单接口超时 |
| 系统稳定性 | 部分功能不可用 | 系统雪崩,多服务宕机 | 数据库CPU满导致全站瘫痪 |
| 数据一致性 | 数据写入延迟 | 数据丢失或错乱 | 订单支付状态不一致 |
| 资源成本 | 临时扩容需求 | 需要长期超配资源 | 云服务器频繁升配 |
| 监控误报 | 告警风暴 | 监控系统过载 | Prometheus抓取超时 |
1.3 黄金响应时间原则
| 响应时间 | 用户感知 | 允许的CPU使用率 | 应对措施 |
|---|---|---|---|
| 0-2秒 | 流畅体验 | <70% | 维持现状 |
| 2-5秒 | 可接受延迟 | 70-85% | 优化代码/SQL |
| 5-8秒 | 体验较差 | 85-95% | 扩容/限流 |
| >8秒 | 不可接受 | >95% | 紧急重启/降级 |
2.快速响应与初步诊断
当我们发现CPU飙升的问题后,我们需要及时尽快做出处置,防止对我们的业务进一步造成影响,带来不必要的损失,我们初步分析问题,对于不同的场景需要采取不同的处置方法和解决策略,主要从如下几个方面来进行处理。
2.1 紧急处理措施
服务降级策略:
- 立即识别非核心服务并暂时关闭,如数据分析、日志记录等非关键功能
- 对于微服务架构,可通过服务网格(Istio/Linkerd)快速关闭非必要服务
流量控制措施:
- 在入口网关(Nginx/API Gateway)层实施限流:
- 启用排队机制或返回降级内容(如静态页面)
异常进程处理流程:
- 使用top命令识别高CPU进程:
- 确定进程优先级
- 必要时终止进程
2.2 基础监控数据收集
系统化的监控数据收集是诊断CPU问题的关键基础,需要从多个维度获取系统状态信息。
- 核心系统指标收集:
| 指标类别 | 采集命令 | 关键指标 | 说明 |
|---|---|---|---|
| CPU使用 | vmstat 1 5 | us, sy, id | 用户/系统/空闲CPU占比 |
| 进程CPU | top -b -n 1 | %CPU, COMMAND | 进程CPU占用排序 |
| 负载 | uptime | load average | 1/5/15分钟负载 |
| 内存 | free -m | used, buff/cache | 内存使用情况 |
| 磁盘IO | iostat -x 1 | %util, await | 磁盘利用率与等待 |
- JVM诊断数据收集:
- 线程堆栈
- GC统计
- 堆内存快照
- JVM标志检查
2.3 问题现象快速分类
根据收集到的监控数据,可以快速将CPU飙升问题分类,针对不同类型采取不同的诊断路径。
| 问题类型 | 关键特征 | 诊断命令 | 可能原因 |
|---|---|---|---|
| 死循环 | 单线程CPU100%,jstack显示相同代码位置 | top -Hp <pid>jstack <pid> | 算法缺陷、循环条件错误 |
| 锁竞争 | 大量线程BLOCKED状态,高上下文切换 | jstack <pid>vmstat 1 | 同步范围过大、锁粒度不合理 |
| GC过频 | GC线程CPU高,jstat显示频繁YGC/FGC | jstat -gcutil <pid> | 内存泄漏、堆大小不合理 |
| 数据库问题 | MySQL进程CPU高,大量慢查询 | SHOW PROCESSLISTSHOW INDEX | 缺失索引、全表扫描 |
| IO等待 | CPU的wa值高,iostat显示高await | iostat -x 1 | 磁盘瓶颈、同步IO操作 |
| 网络问题 | 大量TCP连接,高软中断 | sar -n DEV 1netstat | DDoS攻击、连接泄漏 |
问题现象快速分类
| 现象特征 | 可能原因方向 |
|---|---|
| CPU高+响应慢 | 代码逻辑问题/死循环 |
| CPU高+内存高 | 内存泄漏/大对象处理 |
| CPU高+GC频繁 | JVM配置不当/对象创建过多 |
| CPU高+IO等待高 | 磁盘/网络瓶颈 |
| 间歇性CPU高 | 定时任务/队列处理 |
3.深度排查方法论
3.1 进程级分析
-
定位高CPU进程:top命令定位出占用CPU较高的PID
top -c # 按CPU排序 ps -aux --sort=-%cpu | head # 获取前10高CPU进程 -
区分进程类型:
- Java应用:结合jps/jcmd获取更详细信息
- 系统进程:检查是否正常系统任务
- 未知进程:检查来源和安全性
3.2 线程级定位
-
查找占用CPU高的进程
top # 找出高CPU的进程PID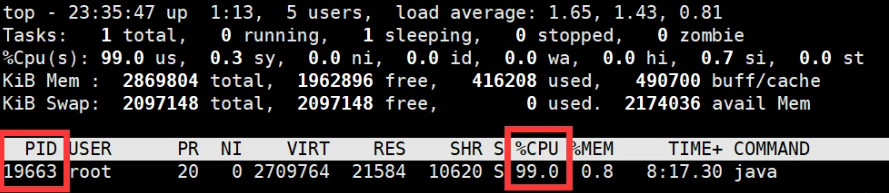
-
获取进程内线程CPU使用
top -Hp <PID> # 显示线程视图 # 或 ps -mp <PID> -o THREAD,tid,time | sort -rn # 按CPU排序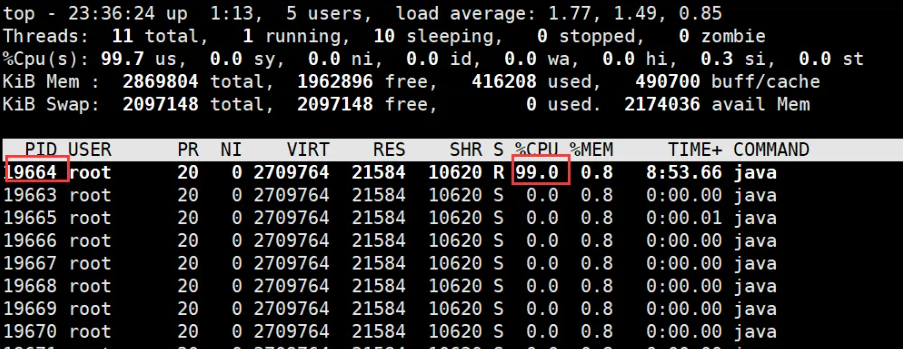
-
转换线程ID为16进制
printf "%x\n" <TID> # 用于jstack分析 -
分析线程堆栈
jstack <PID> > stack.log # 获取线程快照 grep -A 30 <HEX_TID> stack.log # 查看TID特定线程后面30行的日志
3.3 代码堆栈追踪
常见问题模式:
- 死循环:线程长时间处于RUNNABLE状态执行相同方法
- 锁竞争:大量线程BLOCKED等待同一锁
- 资源等待:线程WAITING或TIMED_WAITING状态
- IO阻塞:大量线程处于IO相关操作
3.3.1. 死循环导致CPU飙升
死循环是最直接导致CPU飙升的原因之一,线程会长时间处于RUNNABLE状态执行相同方法。
public class InfiniteLoopExample {public static void main(String[] args) {// 创建多个线程执行死循环for (int i = 0; i < Runtime.getRuntime().availableProcessors(); i++) {new Thread(() -> {while (true) {// 空循环占用CPUint a = 1 + 1;}}, "CPU-intensive-thread-" + i).start();}}
}原理分析:
- 这段代码创建了与CPU核心数相同的线程,每个线程都执行一个无限循环
- 由于循环体中没有阻塞操作(如sleep或IO),线程会一直处于RUNNABLE状态
- JVM会将线程状态显示为RUNNABLE,但实际上在操作系统层面线程会不断被调度
- 这种计算密集型任务会占满CPU资源,导致CPU使用率飙升到100%
监控表现:
- 使用
top命令会看到Java进程CPU使用率接近100% jstack查看线程状态会显示所有线程处于RUNNABLE状态- 线程堆栈会指向循环体的代码位置
3.3.2. 锁竞争导致CPU飙升
大量线程BLOCKED等待同一锁会导致CPU飙升,特别是在锁竞争激烈的情况下。
public class LockContentionExample {private static final Object sharedLock = new Object();public static void main(String[] args) {// 创建20个线程竞争同一个锁for (int i = 0; i < 20; i++) {new Thread(() -> {while (true) {synchronized (sharedLock) {// 持有锁时执行一些计算compute();}// 短暂释放CPU,模拟业务逻辑try {Thread.sleep(10);} catch (InterruptedException e) {e.printStackTrace();}}}, "Lock-Contention-Thread-" + i).start();}}private static void compute() {// 模拟一些计算long start = System.currentTimeMillis();while (System.currentTimeMillis() - start < 50) {// 占用CPU约50ms}}
}原理分析:
- 多个线程频繁竞争同一个锁会导致大量线程处于BLOCKED状态
- 虽然BLOCKED状态本身不消耗CPU,但线程从BLOCKED到RUNNABLE的转换会引发大量上下文切换
- 每次锁释放后,所有等待线程会同时被唤醒,导致"惊群效应"
- 高频率的锁竞争和上下文切换会显著增加CPU使用率
监控表现:
jstack会显示大量线程处于BLOCKED状态,等待获取对象监视器锁- VisualVM等工具会显示大量线程在等待锁
- CPU使用率高但不像死循环那样持续100%,而是呈现波动状态
3.3.3. 资源等待导致CPU飙升
大量线程处于WAITING或TIMED_WAITING状态,当条件满足时同时唤醒会导致CPU飙升。
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;public class ResourceWaitExample {private static final Object condition = new Object();private static volatile boolean resourceReady = false;public static void main(String[] args) {ExecutorService executor = Executors.newFixedThreadPool(50);// 创建50个等待线程for (int i = 0; i < 50; i++) {executor.execute(() -> {synchronized (condition) {while (!resourceReady) {try {// 等待条件满足condition.wait();} catch (InterruptedException e) {Thread.currentThread().interrupt();}}// 条件满足后执行计算密集型任务intensiveComputation();}});}// 模拟5秒后资源就绪,唤醒所有等待线程new Thread(() -> {try {Thread.sleep(5000);synchronized (condition) {resourceReady = true;condition.notifyAll(); // 同时唤醒所有等待线程}} catch (InterruptedException e) {e.printStackTrace();}}).start();}private static void intensiveComputation() {long start = System.currentTimeMillis();while (System.currentTimeMillis() - start < 100) {// 模拟100ms的计算double x = Math.random() * Math.random();}}
}原理分析:
- 大量线程在条件不满足时处于WAITING状态
- 当条件满足调用notifyAll()时,所有等待线程会同时被唤醒
- 这些线程会从WAITING状态转为BLOCKED状态(等待获取锁),然后转为RUNNABLE状态
- 短时间内大量线程同时竞争CPU资源会导致CPU使用率飙升
- 虽然TIMED_WAITING本身不消耗CPU,但大量线程同时唤醒会导致CPU峰值
监控表现:
- 在等待期间,线程状态为WAITING或TIMED_WAITING
- 唤醒瞬间会出现大量BLOCKED状态线程
- CPU使用率会在唤醒后出现短暂峰值
- Arthas等工具可能显示TIMED_WAITING线程有CPU使用率,这是采样瞬间值
3.3.4. IO阻塞导致CPU飙升
大量线程处于IO相关操作会导致CPU飙升,特别是在使用阻塞IO的情况下。
import java.io.IOException;
import java.io.InputStream;
import java.net.ServerSocket;
import java.net.Socket;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;public class IOBlockingExample {public static void main(String[] args) throws IOException {ExecutorService executor = Executors.newFixedThreadPool(100);ServerSocket serverSocket = new ServerSocket(8080);// 模拟IO密集型任务while (true) {final Socket clientSocket = serverSocket.accept();executor.execute(() -> {try {InputStream input = clientSocket.getInputStream();// 阻塞读取数据while (input.read() != -1) {// 模拟处理数据消耗CPUprocessData();}} catch (IOException e) {e.printStackTrace();}});}}private static void processData() {// 模拟处理数据消耗CPUlong start = System.currentTimeMillis();while (System.currentTimeMillis() - start < 5) {// 占用CPU约5ms处理每个字节}}
}原理分析:
- 使用阻塞IO时,每个连接需要一个独立线程
- 线程在read()时会阻塞,但Java线程状态仍显示为RUNNABLE
- 大量线程同时处理IO会导致频繁的上下文切换
- 虽然线程在等待IO时不消耗CPU,但线程管理和上下文切换会消耗CPU资源
- 当IO完成数据到达时,大量线程同时被唤醒会导致CPU使用率飙升
监控表现:
jstack显示线程状态为RUNNABLE,但堆栈显示在Socket读取- 操作系统层面线程实际处于睡眠状态,但JVM不感知
- CPU使用率会随着连接数增加而上升
- 系统负载高但CPU不一定完全饱和
3.3.5.总结对比表
| 场景类型 | Java线程状态 | 导致CPU飙升的原因 | 典型解决方案 |
|---|---|---|---|
| 死循环 | RUNNABLE | 持续占用CPU周期 | 添加sleep/yield,改用算法优化 5 |
| 锁竞争 | BLOCKED | 锁竞争和上下文切换 | 减小锁粒度,使用读写锁,无锁数据结构 12 |
| 资源等待 | WAITING/TIMED_WAITING | 大量线程同时唤醒 | 分批唤醒,使用Condition精确控制 19 |
| IO阻塞 | RUNNABLE(实际阻塞) | 线程管理和上下文切换 | 改用NIO,异步IO,反应器模式 56 57 |
这些代码示例都可以直接运行并观察到CPU使用率飙升的现象。在实际生产环境中,可以使用top、jstack、Arthas等工具来诊断具体是哪种情况导致的CPU问题。
4.典型场景与解决方案
4.1 死循环与算法问题
案例:字符串处理死循环
public static int getStringCount(String str, String key) {int count = 0;int index = 0;while ((index = str.indexOf(key)) != -1) {count++;str = str.substring(index + key.length());}return count;
}问题:当key为空字符串时陷入死循环
解决方案:
- 增加参数校验
- 使用更安全的字符串操作方法
- 添加循环保护机制
4.2 序列化/反序列化瓶颈
案例:大对象JSON序列化导致CPU飙高
- Fastjson:285.00ms
- Jackson:255.29ms
- Gson:283.08ms
- net.sf.json:655.06ms
解决方案:
- 选择高性能序列化框架
- 避免序列化大对象
- 采用增量或分块处理
- 使用二进制协议替代JSON
4.3 锁竞争与线程阻塞
识别方法:
- jstack显示大量BLOCKED线程
- 查找"waiting to lock"信息
- 检查锁持有链
解决方案:
- 减小锁粒度
- 使用读写锁替代独占锁
- 设置合理的锁超时
- 考虑无锁数据结构
4.4 大对象与内存泄漏
案例:HTTP请求头处理不当
# 错误配置
server:max-http-header-size: 10MB # 导致每个请求分配10MB数组排查工具:
- MAT(Memory Analyzer Tool)分析heap dump
- 查找Retained Heap大的对象
- 检查对象引用链
4.5 第三方组件性能缺陷
案例:Kafka消费阻塞导致CPU高
- 消费线程卡住不提交offset
- 重启后重新消费问题消息
- 形成恶性循环
解决方案:
- 增加消费超时机制
- 完善错误处理和补偿
- 监控消费延迟
以上我们逐一从问题出发的背景,到如何快速处置以及详细问题的排查和解决步骤到后面的一些问题场景示例,由浅入深就CPU飙升做出了讲解,希望能够在生产中帮助各位渡过难关。