Java基础复习-中-集合
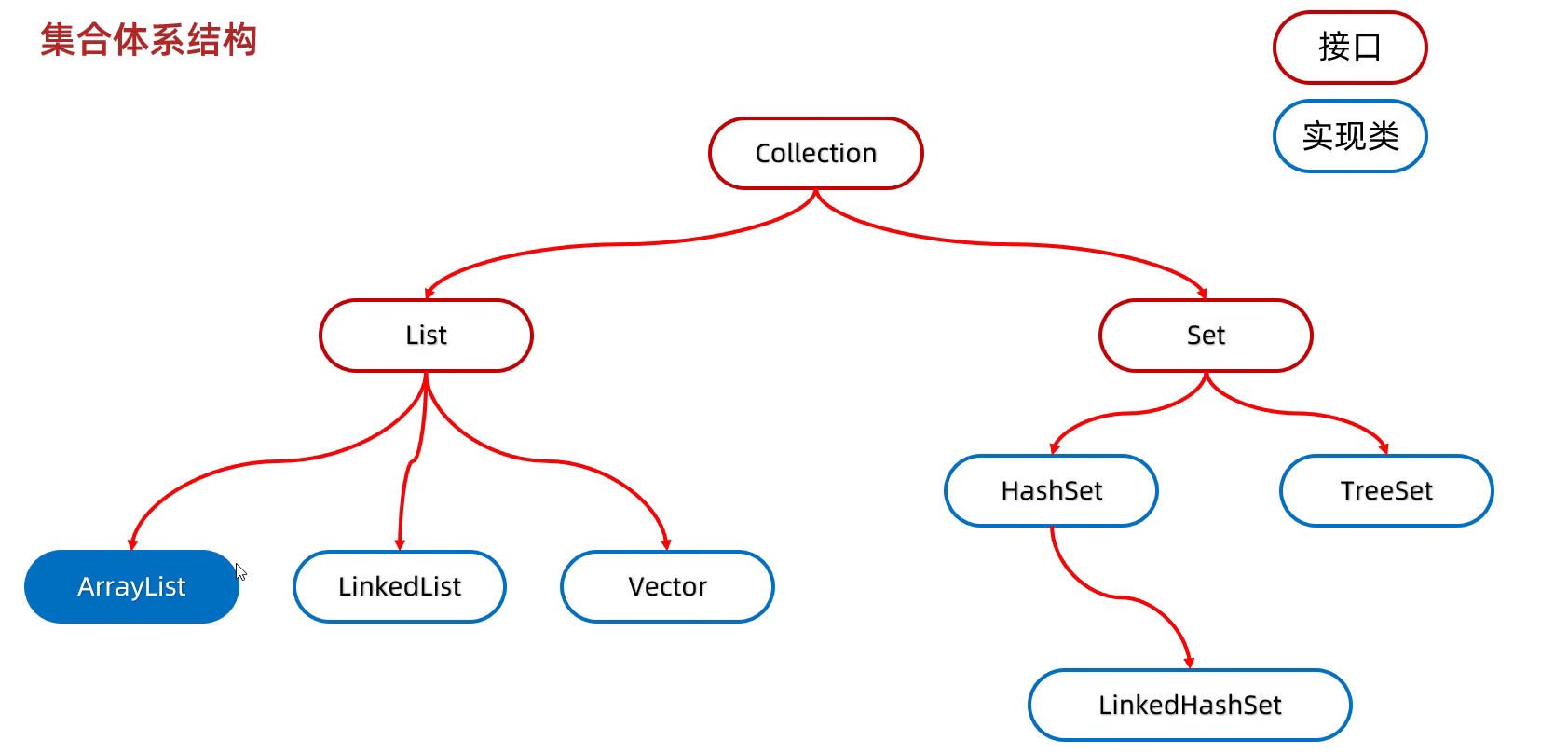
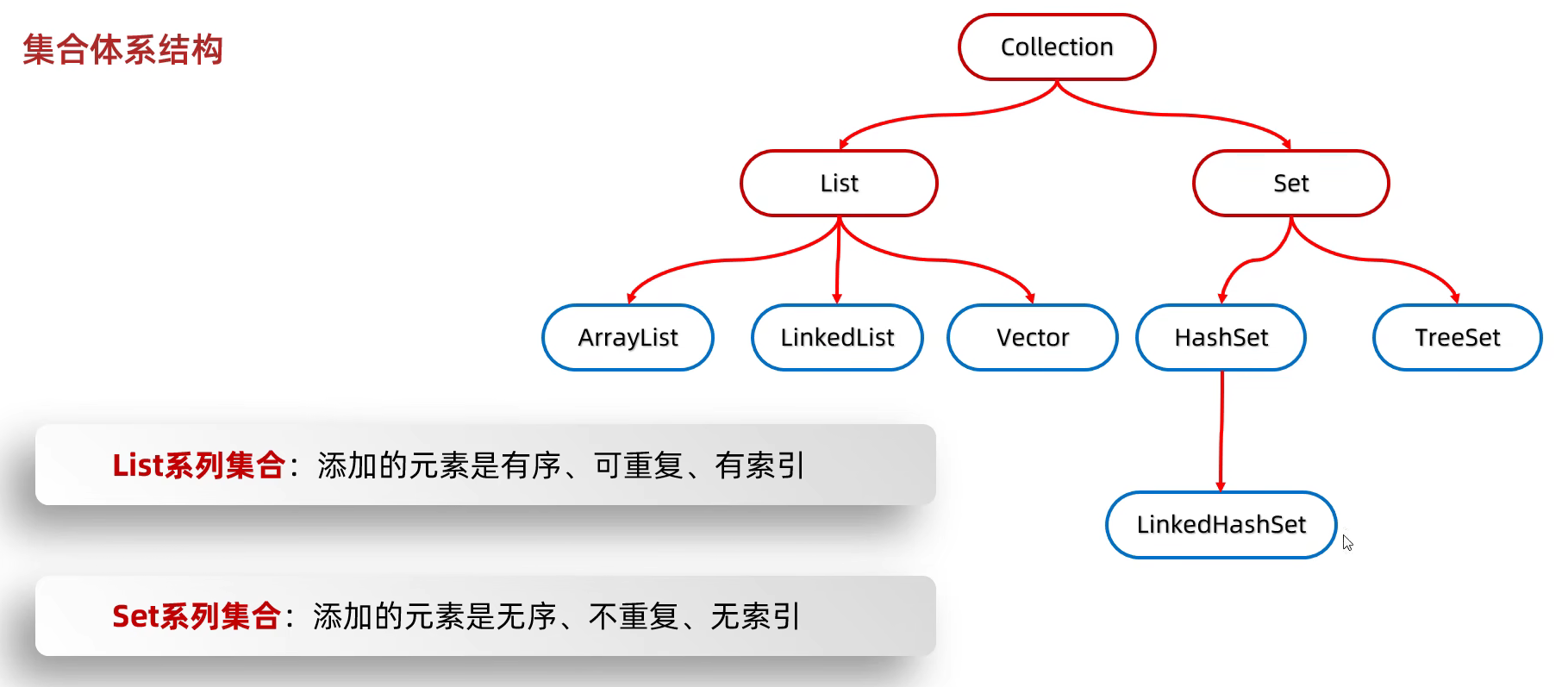
集合

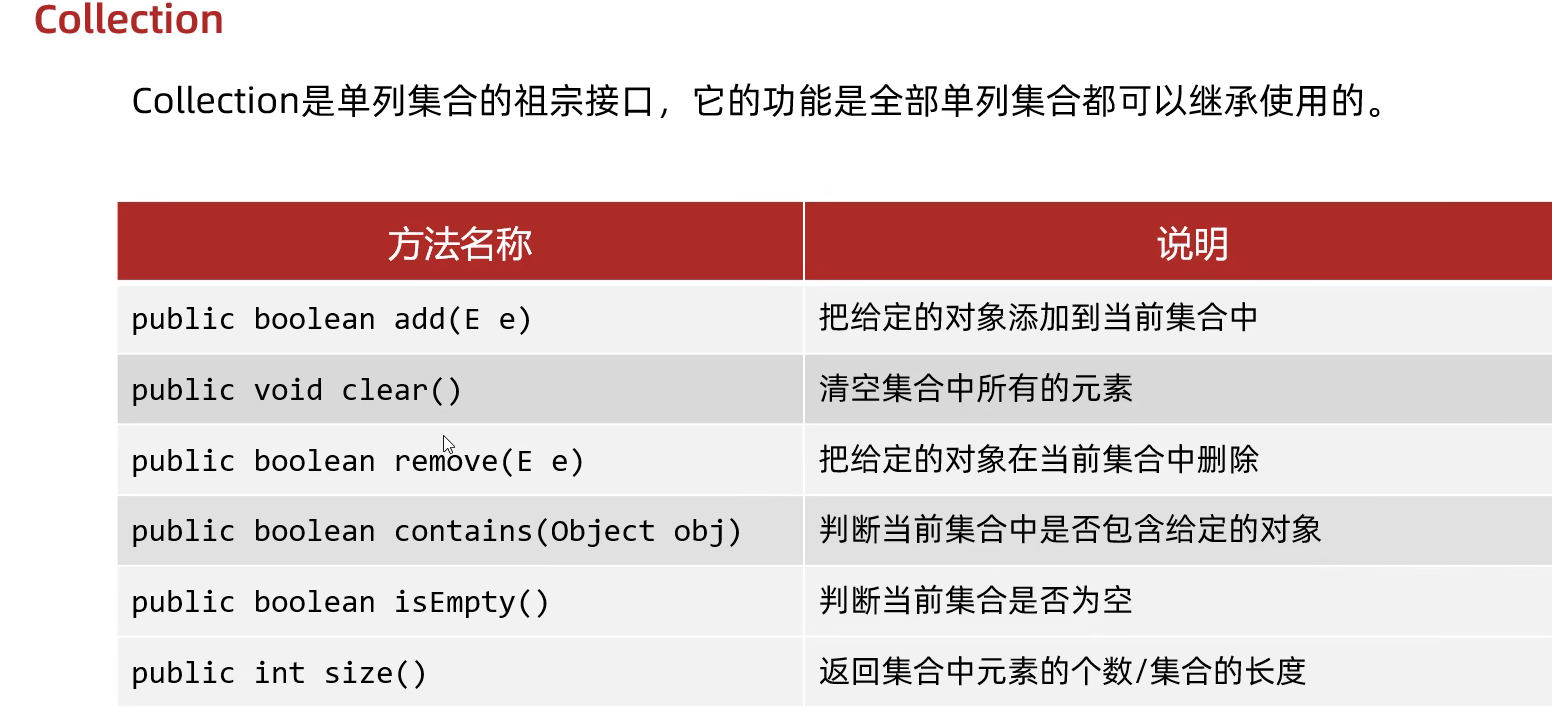
Collection

遍历
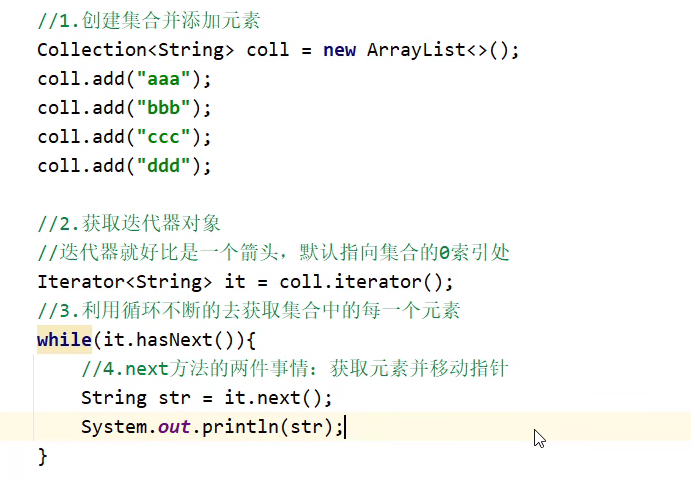
迭代器


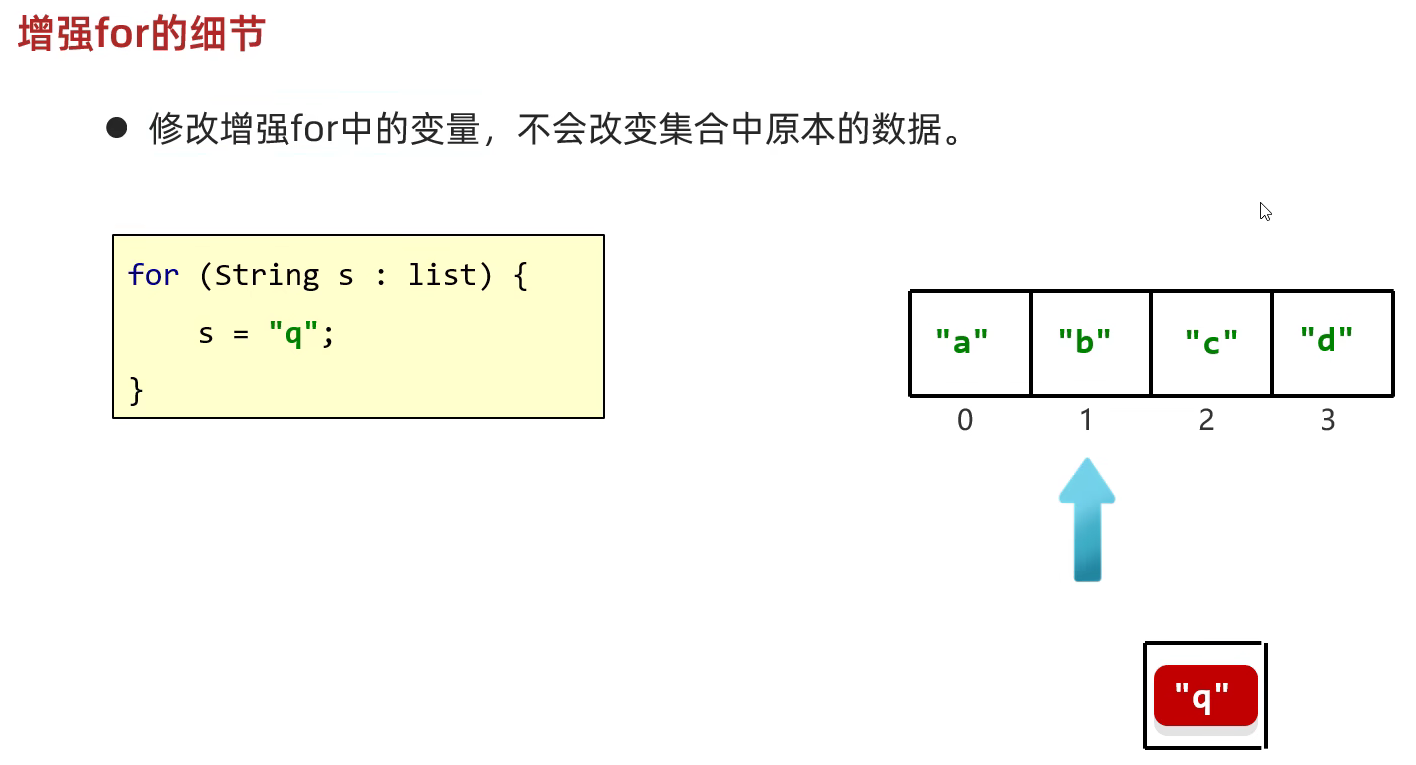
增强for遍历

Lambda表达式遍历


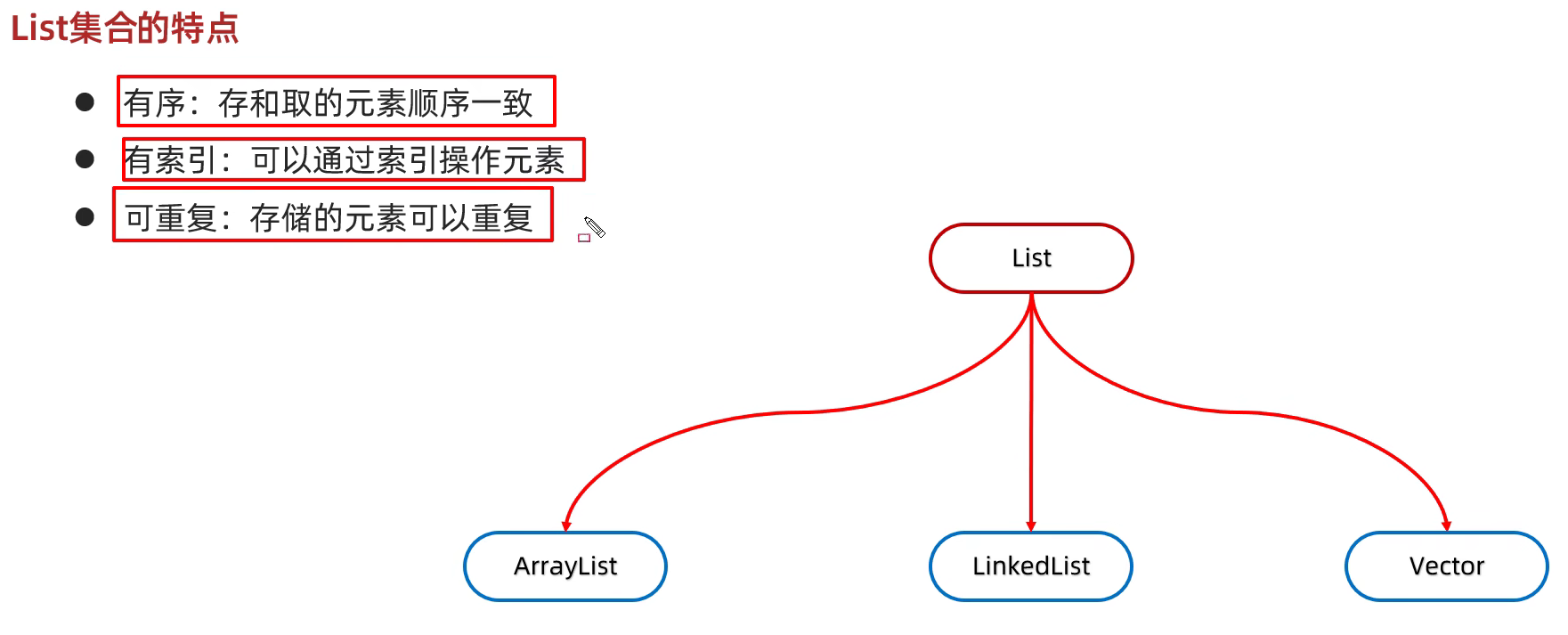
List集合


1的数据类型默认是Integer类型,所以,这里删除的是索引1上的数据
list的5种遍历方式:



代码演示
public static void main(String[] args) {List<String> list = new ArrayList<>();list.add("aaa");list.add("bbb");list.add("ccc");
// 1、迭代器遍历
// Iterator<String> it = list.iterator();
// while (it.hasNext()) {
//// 删除某个元素,这里不能使用list.remove方法,会报并发修改异常,需要使用迭代器的remove方法
// String str = it.next();
// if ("bbb".equals(str)){
// it.remove();
// continue;
// }
// System.out.println(str);
// }
// 2、列表迭代器
// ListIterator<String> it = list.listIterator();
//// 使用列表迭代器可以往集合中添加元素,或者反向遍历等
// while (it.hasNext()) {
// String str = it.next();
// if ("bbb".equals(str)){
// it.add("ddd");
// }
// }
// System.out.println(list);
// 3、增强for循环
// for (String s : list) {
// System.out.println(s);
// }
// 4、lambda表达式
// list.forEach(item -> System.out.println(item));
// lambda继续简化:list.forEach(System.out::println);// 5、普通for循环
// for (int i = 0; i < list.size(); i++) {
// System.out.println(list.get(i));
// }}常用的数据结构
栈

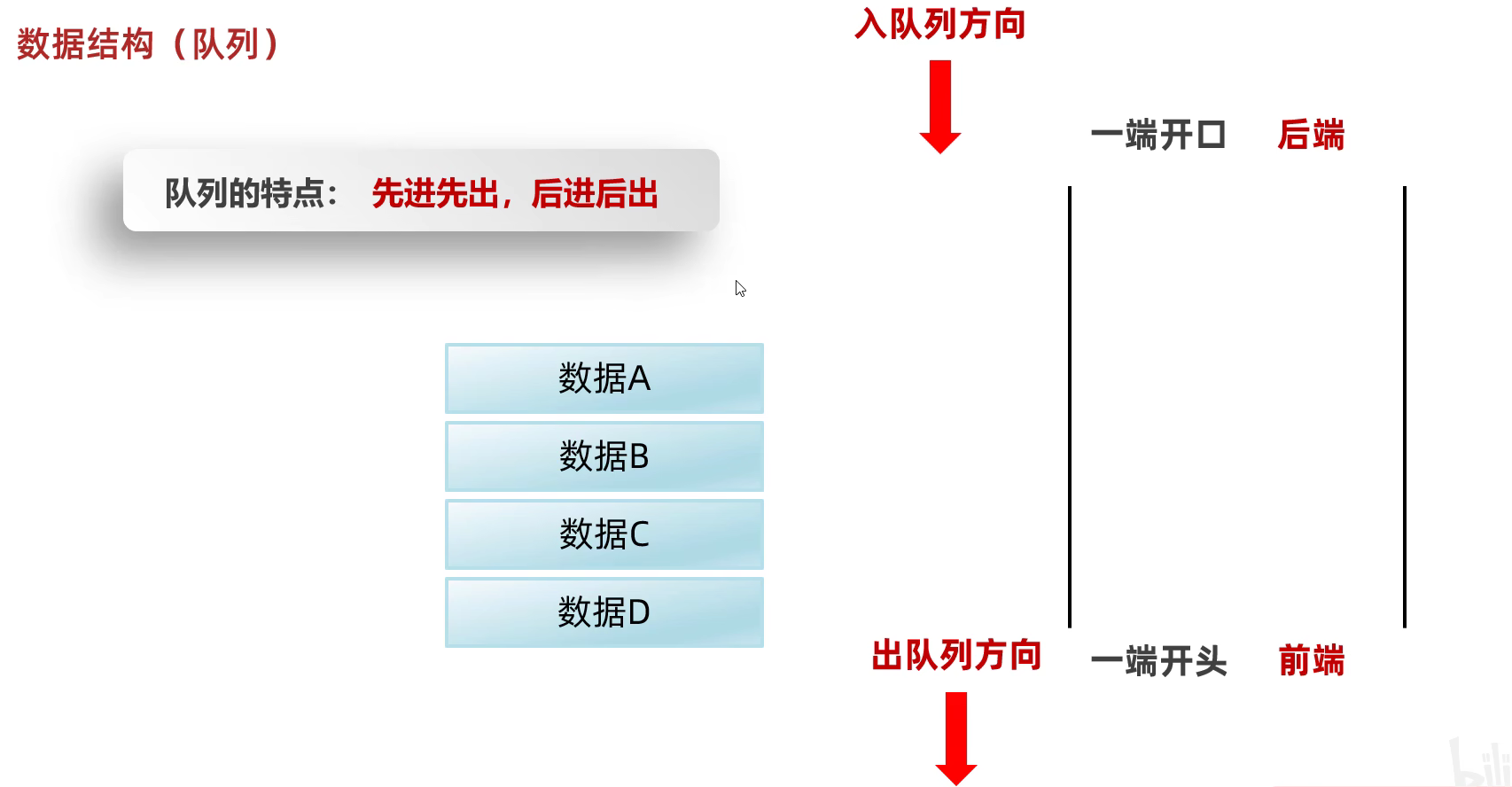
队列
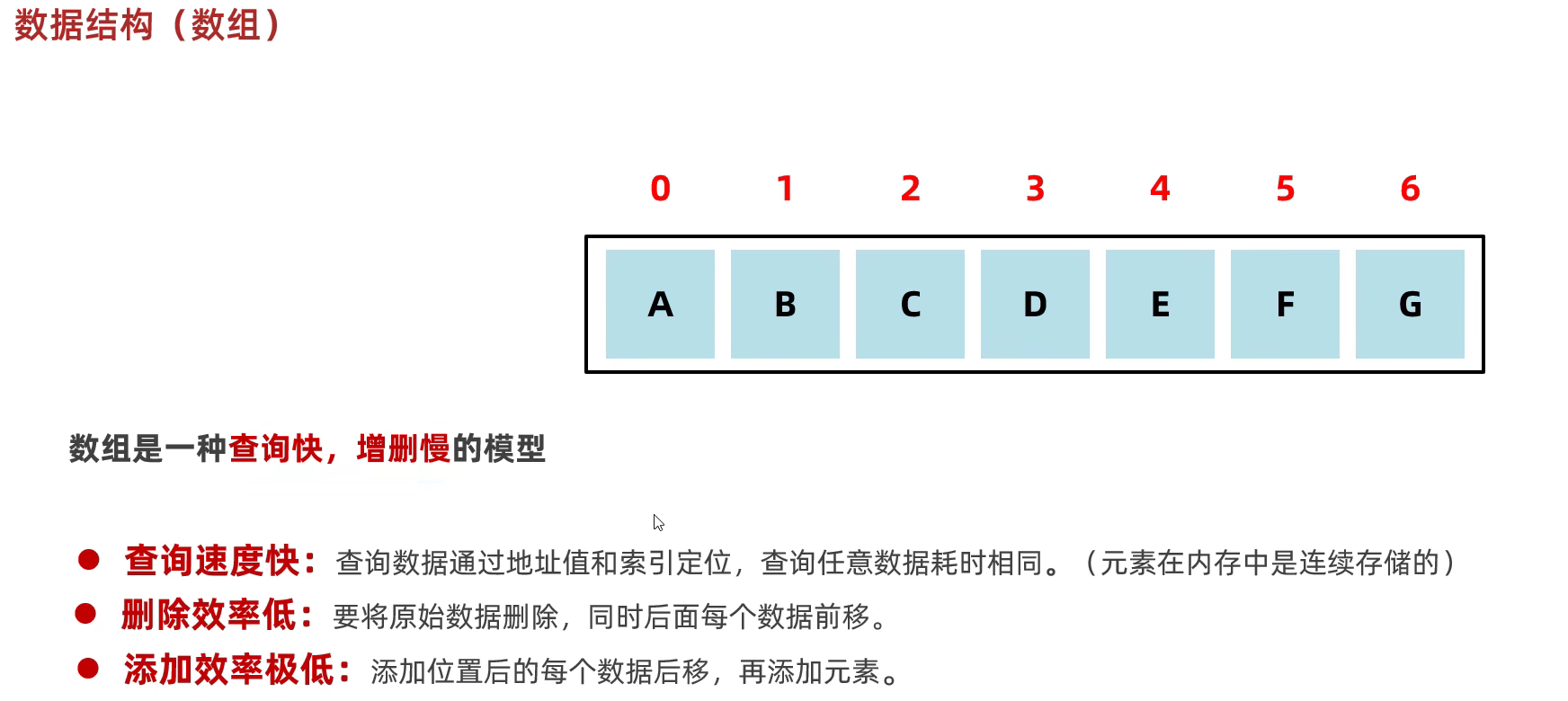
数组
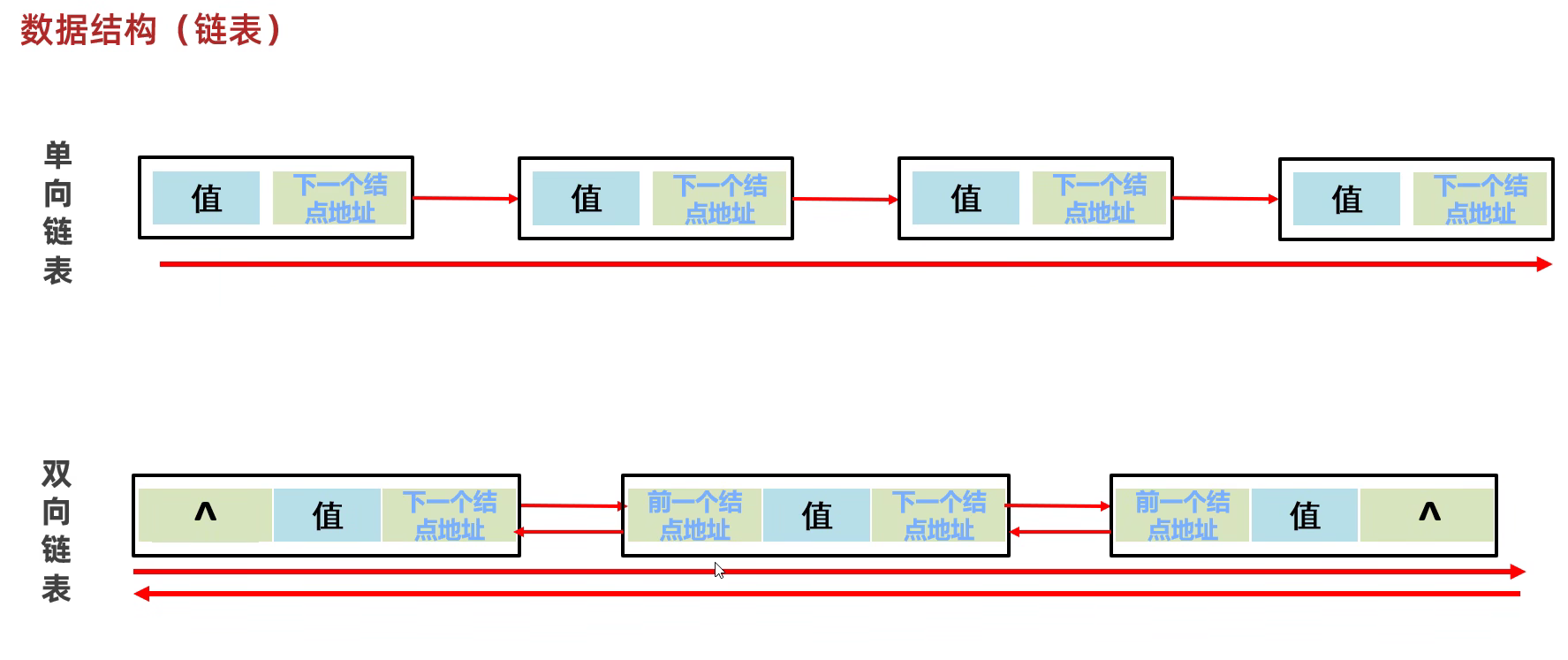
单向链表
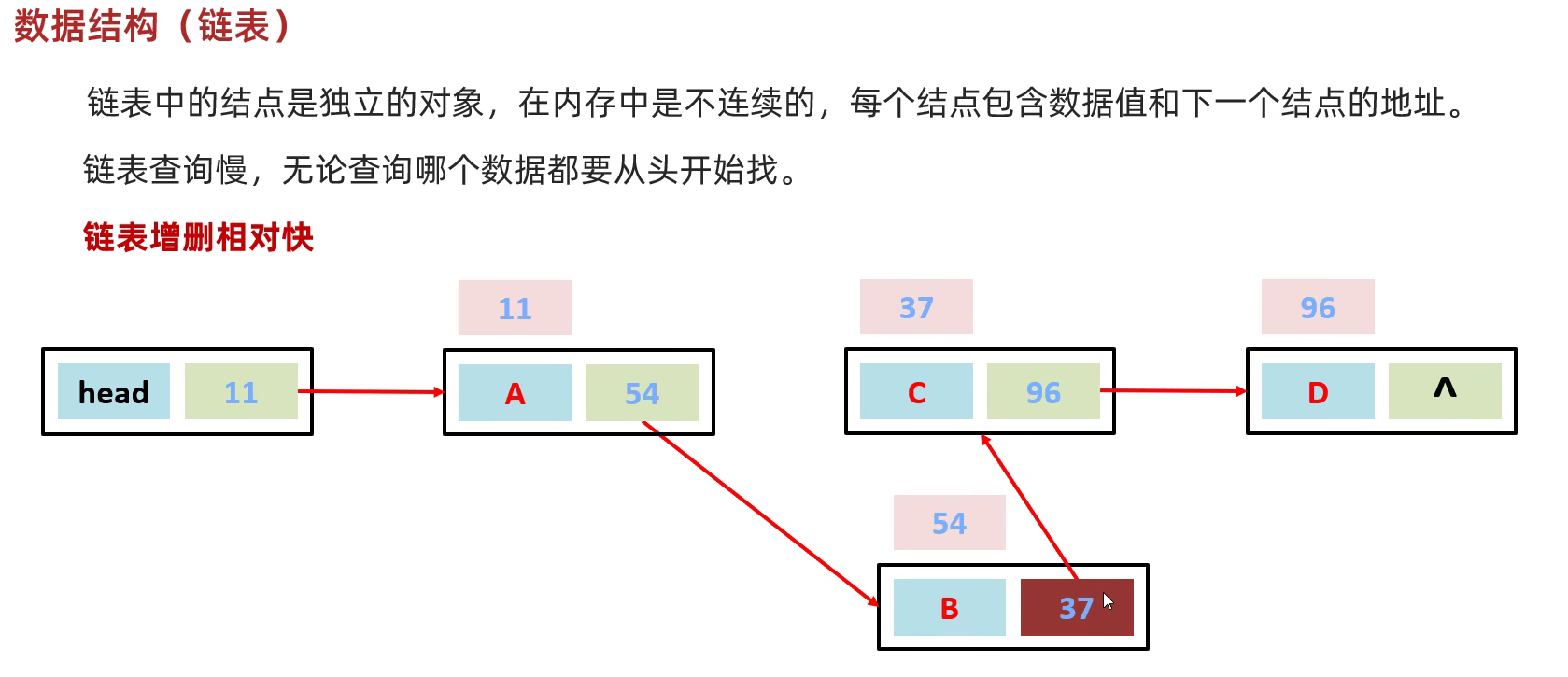
双向链表
集合底层原理
ArrayList底层原理

扩容
一次添加一个元素:

一次添加多个元素:

LinkedList底层原理
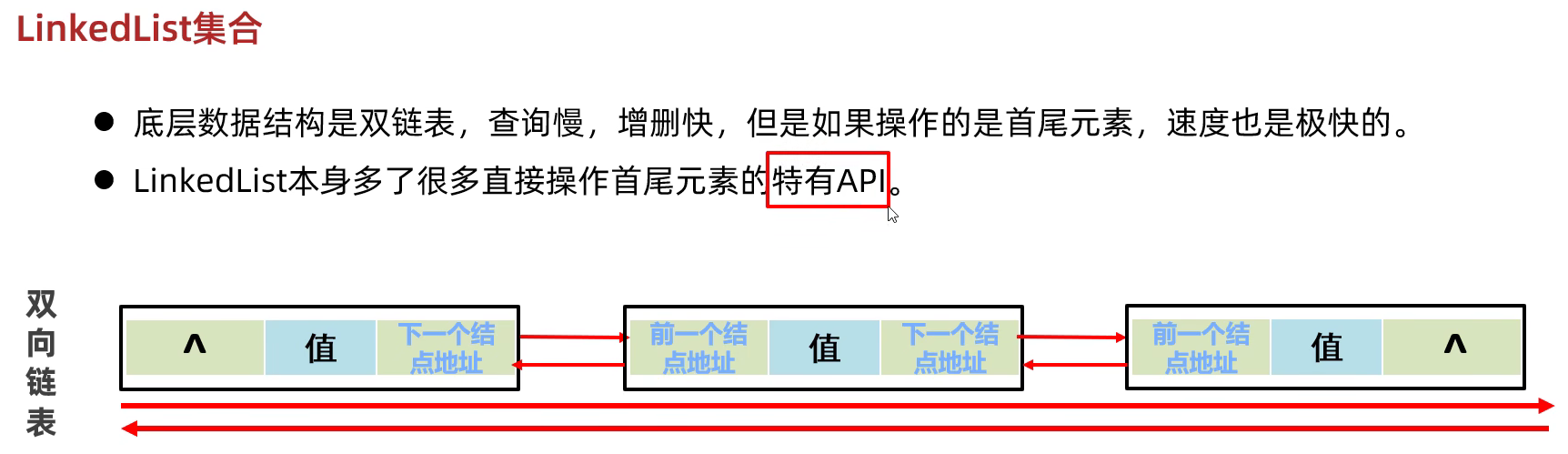
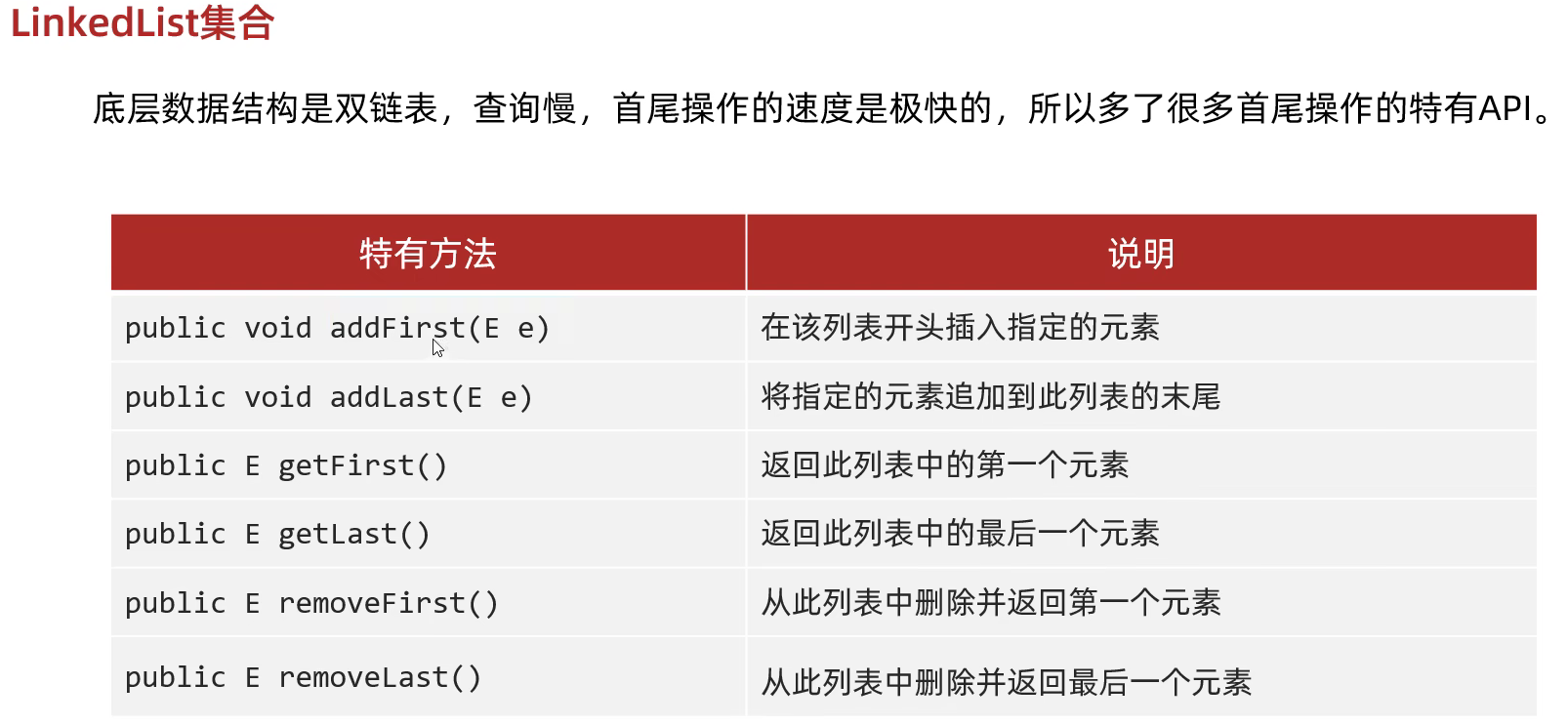
底层原理
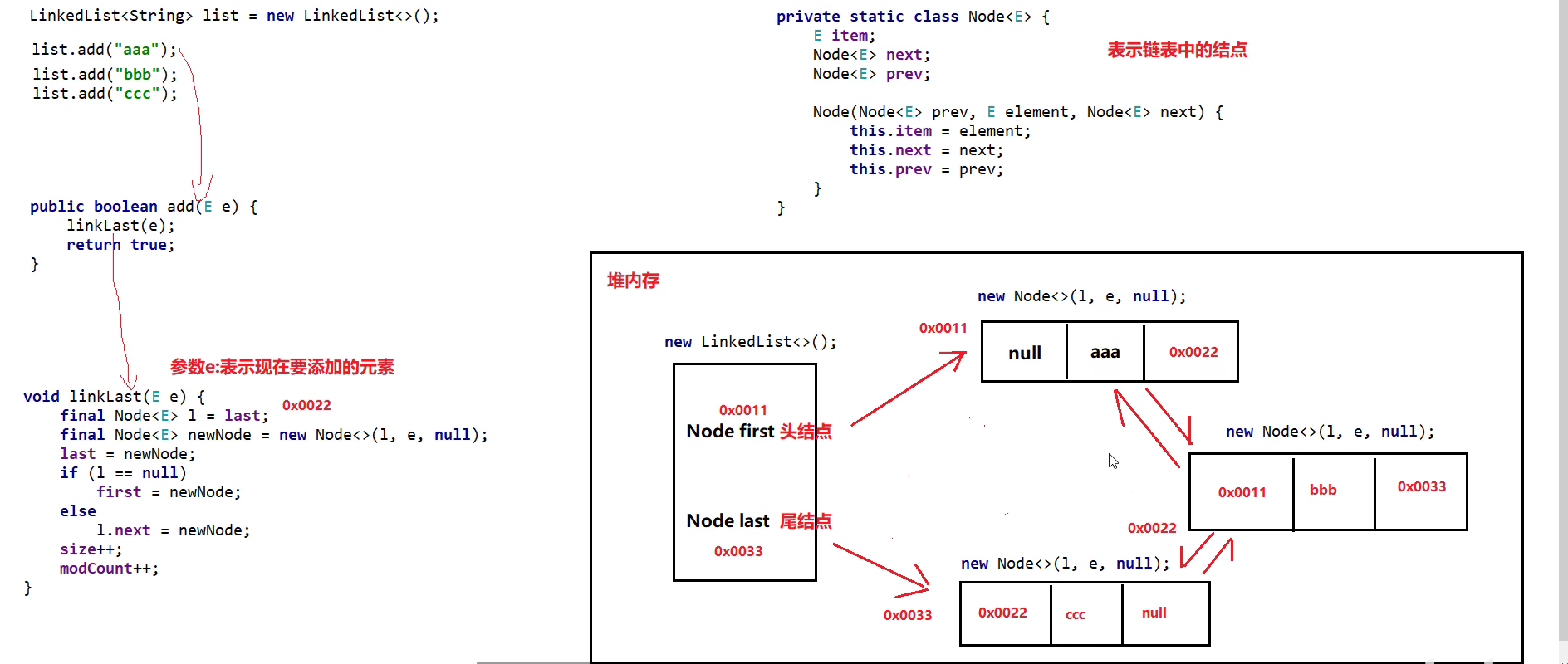
迭代器底层原理

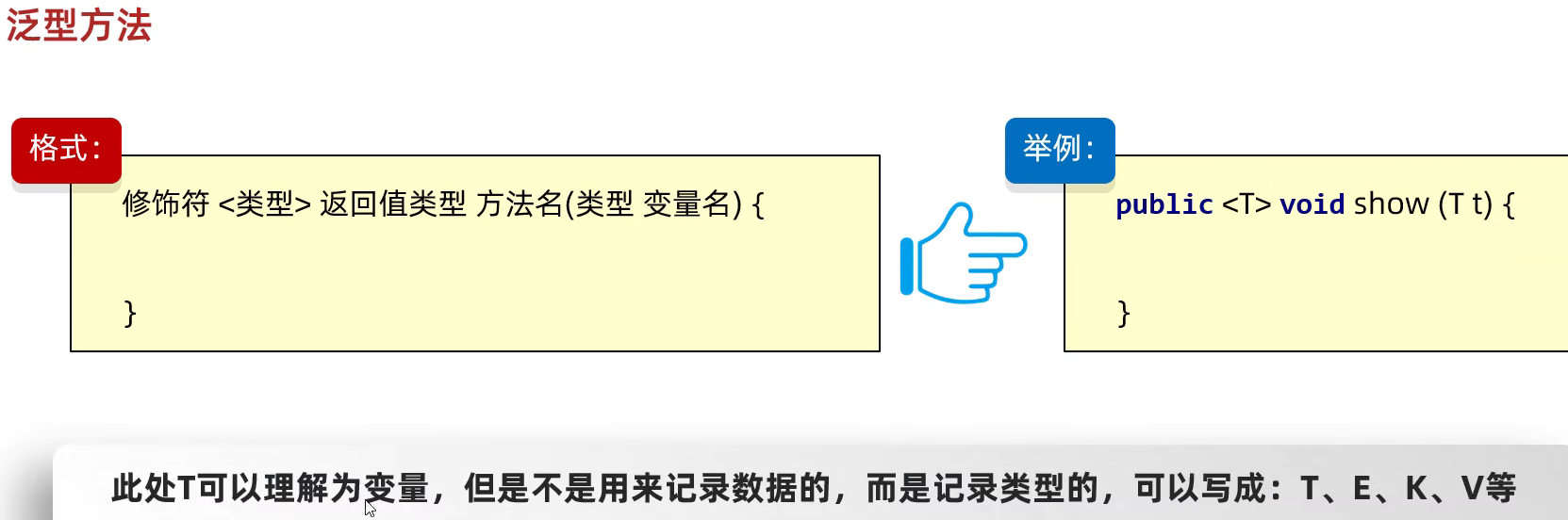
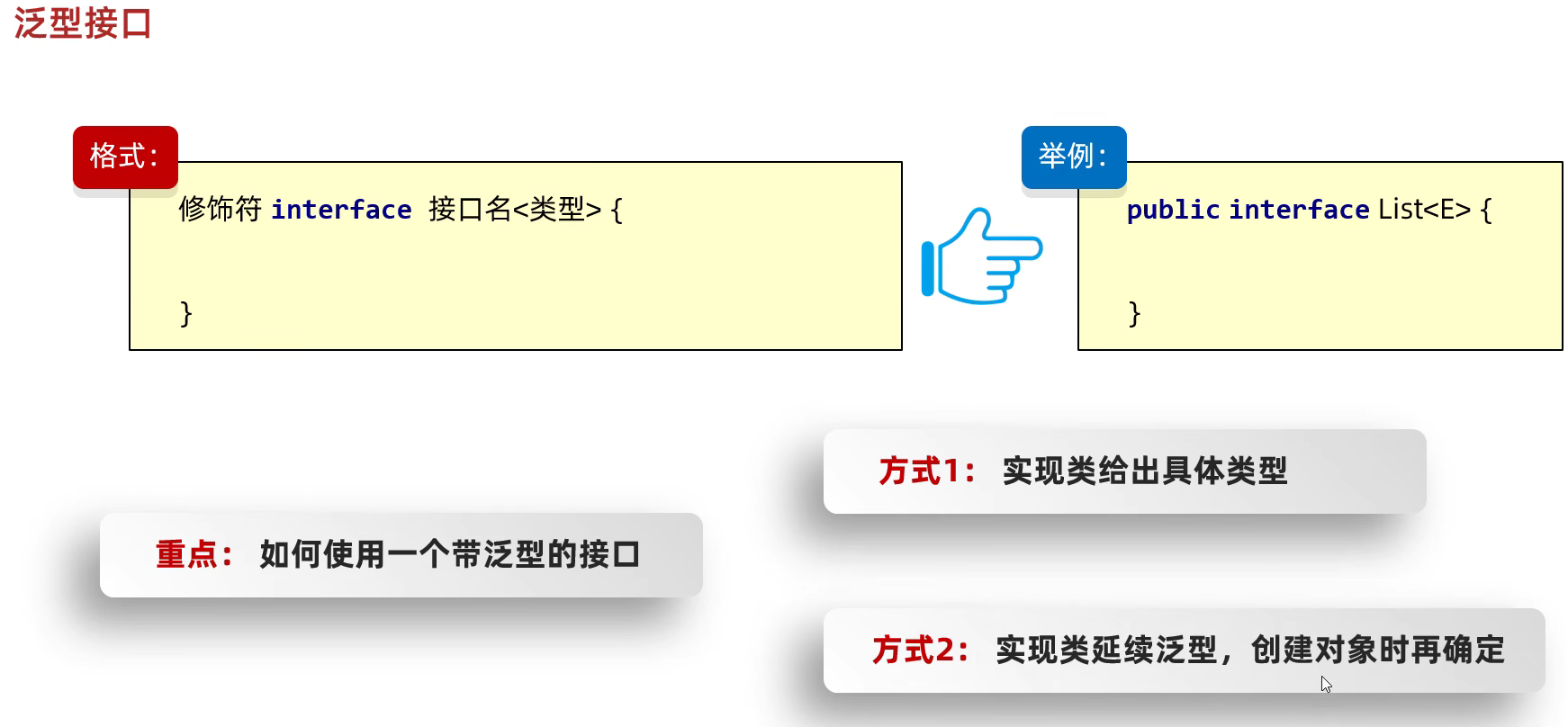
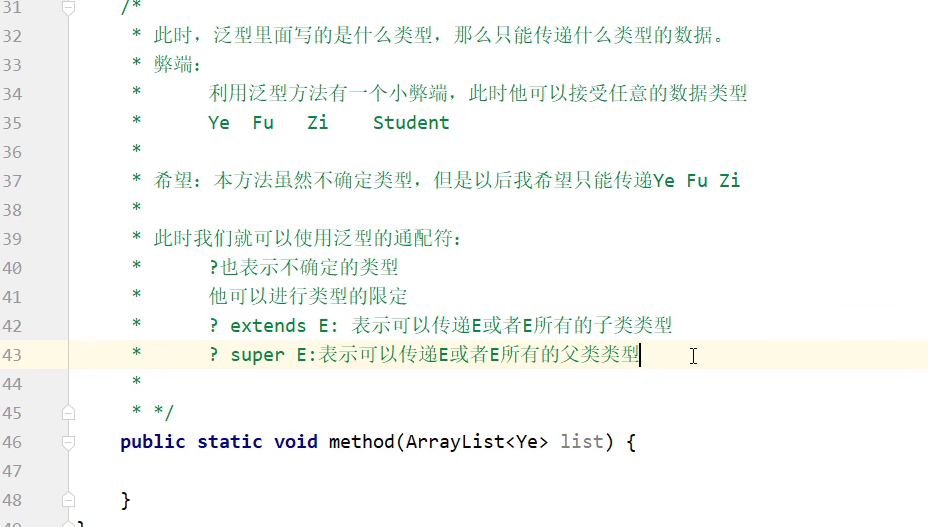
 泛型
泛型


Java的泛型是伪泛型,只是在编译阶段检查一下,程序运行后,会把元素都转成Object类型,然后,在后续使用时根据泛型对元素做一次强转。(这样是为了兼容老的版本)




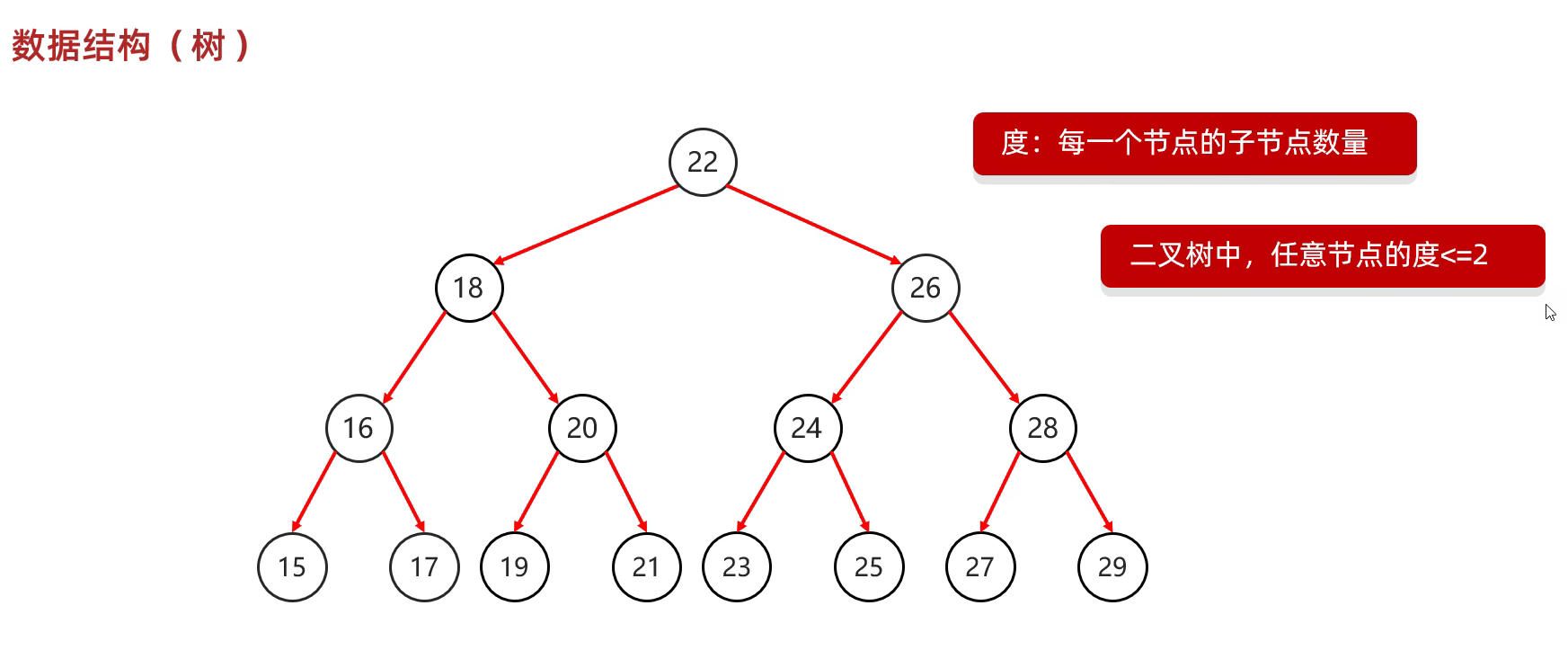
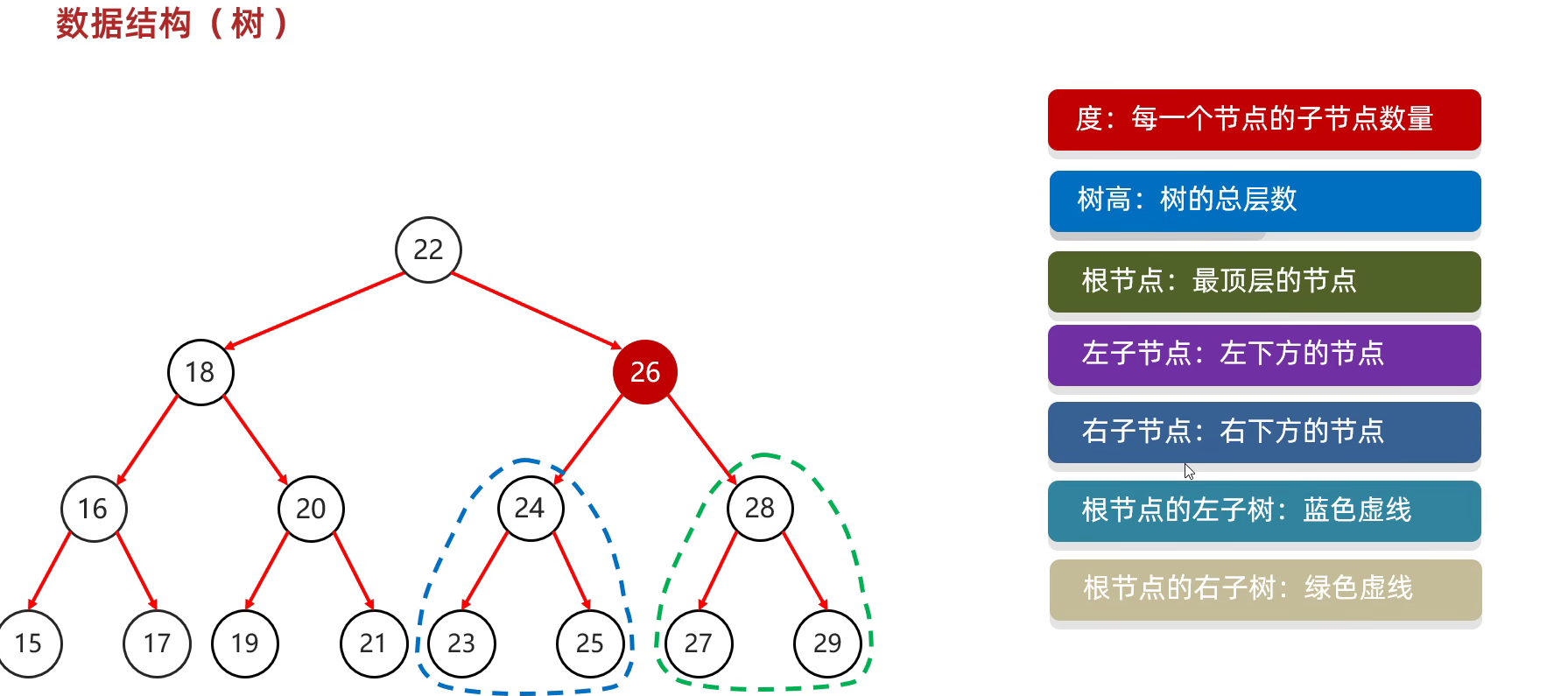
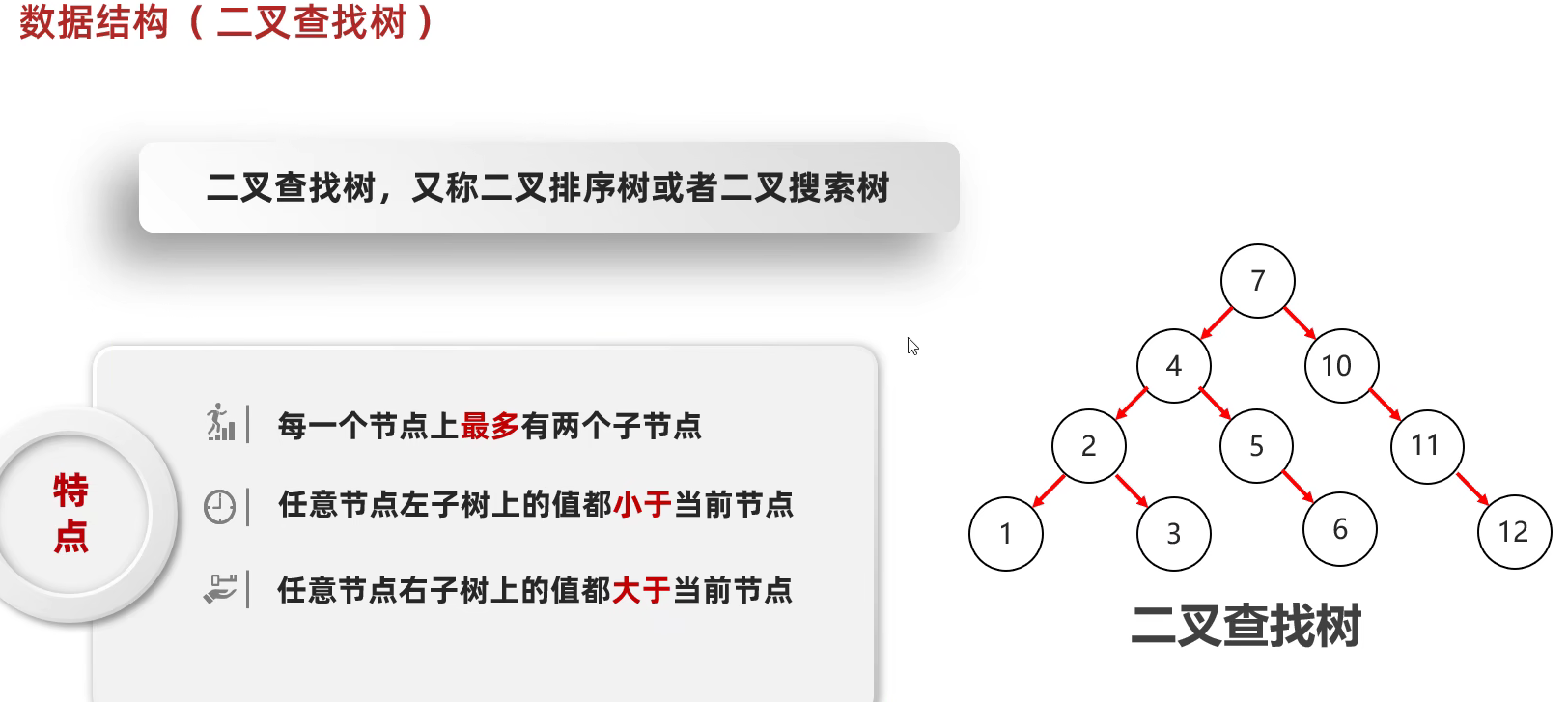
数据结构
树


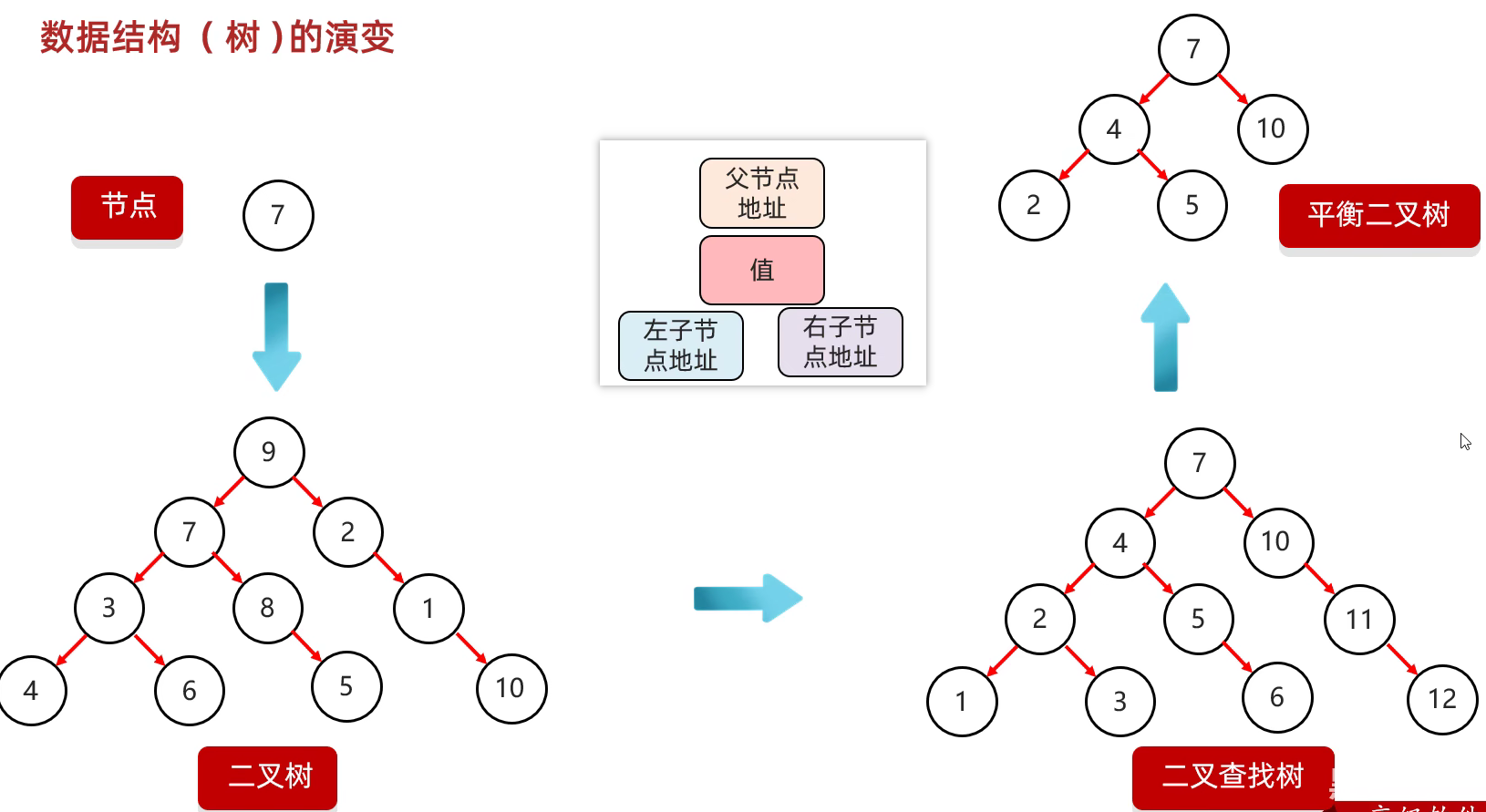
平衡二叉树保持平衡的原理-旋转机制


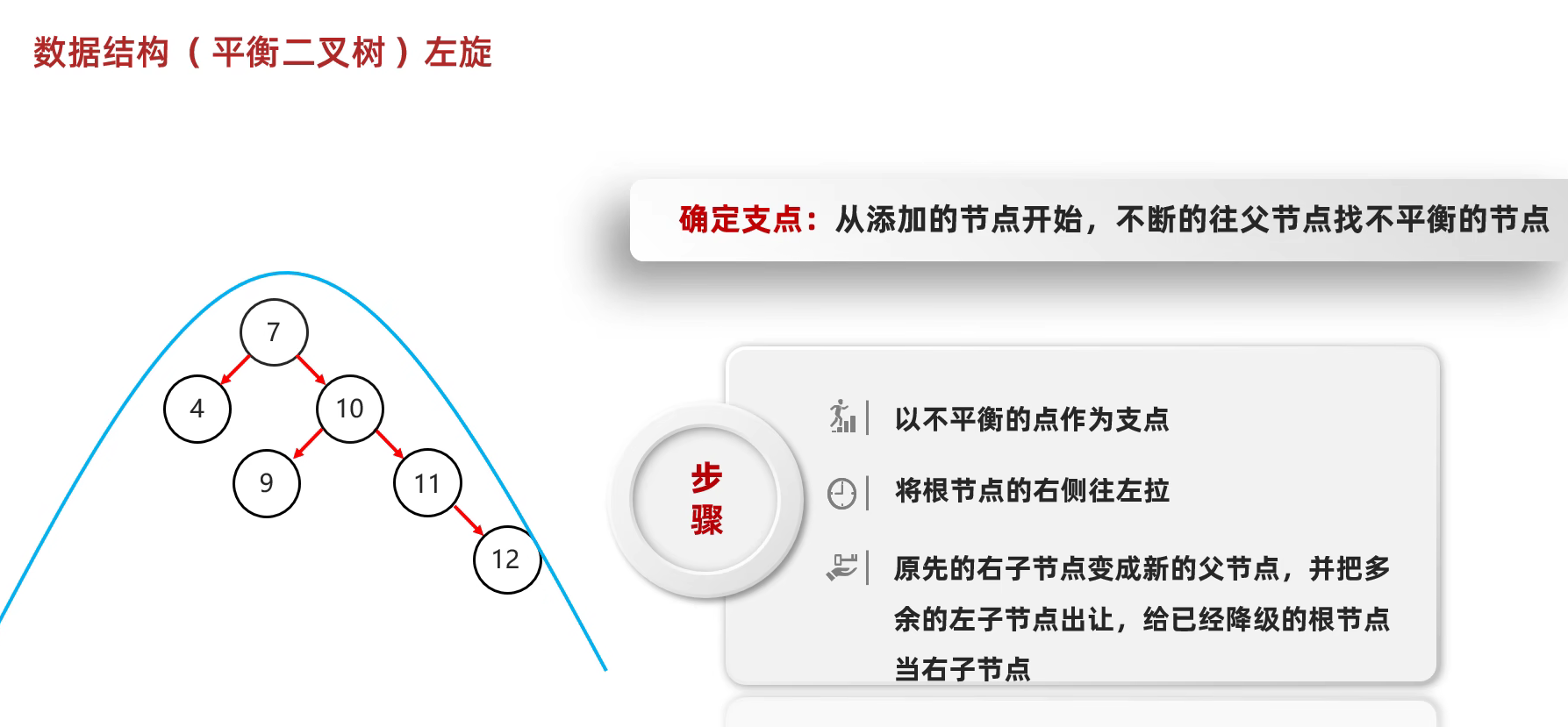


左左:在根节点的左子树的左子树上插入新的节点,其他类似...
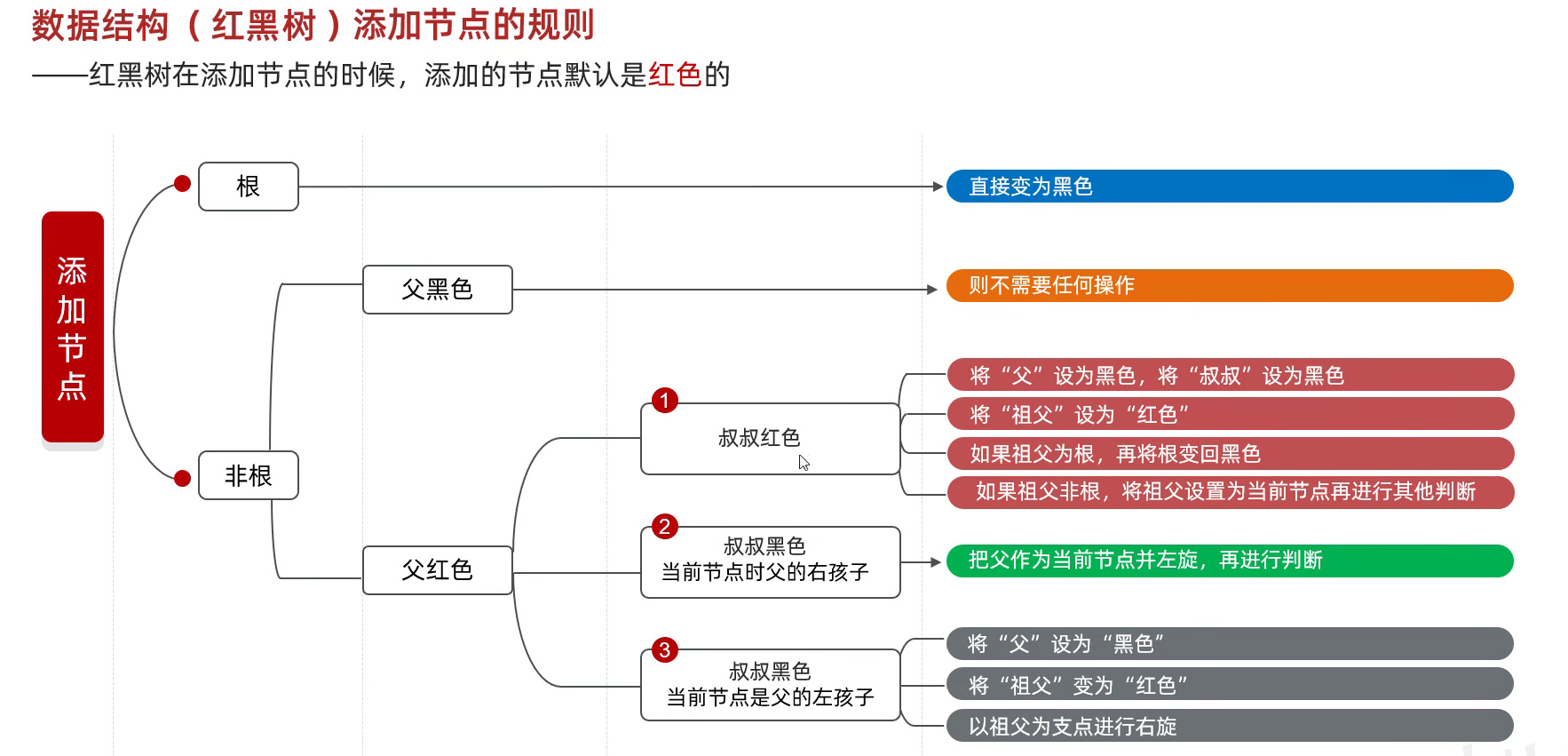
红黑树

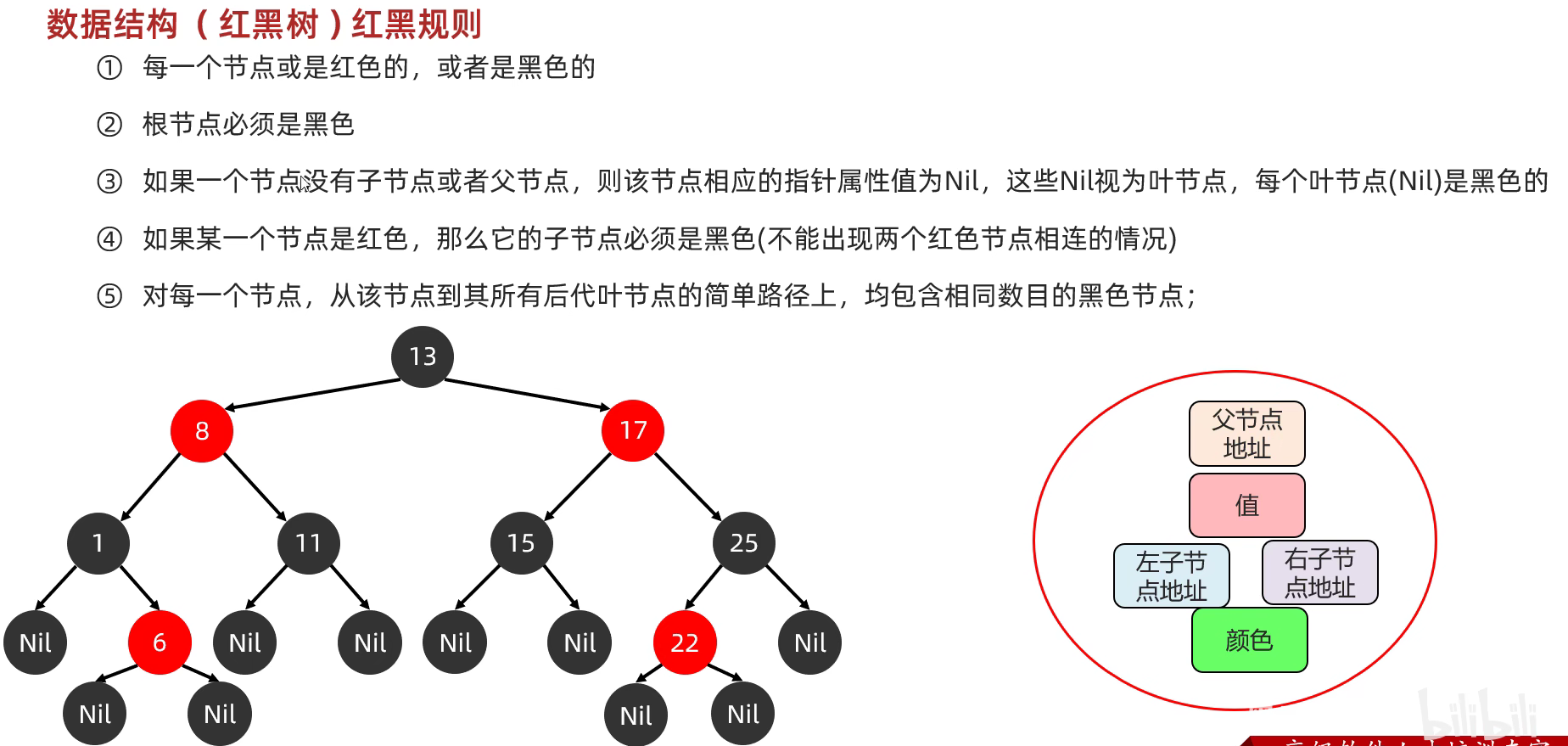
红黑树添加节点规则:
Set集合


HashSet


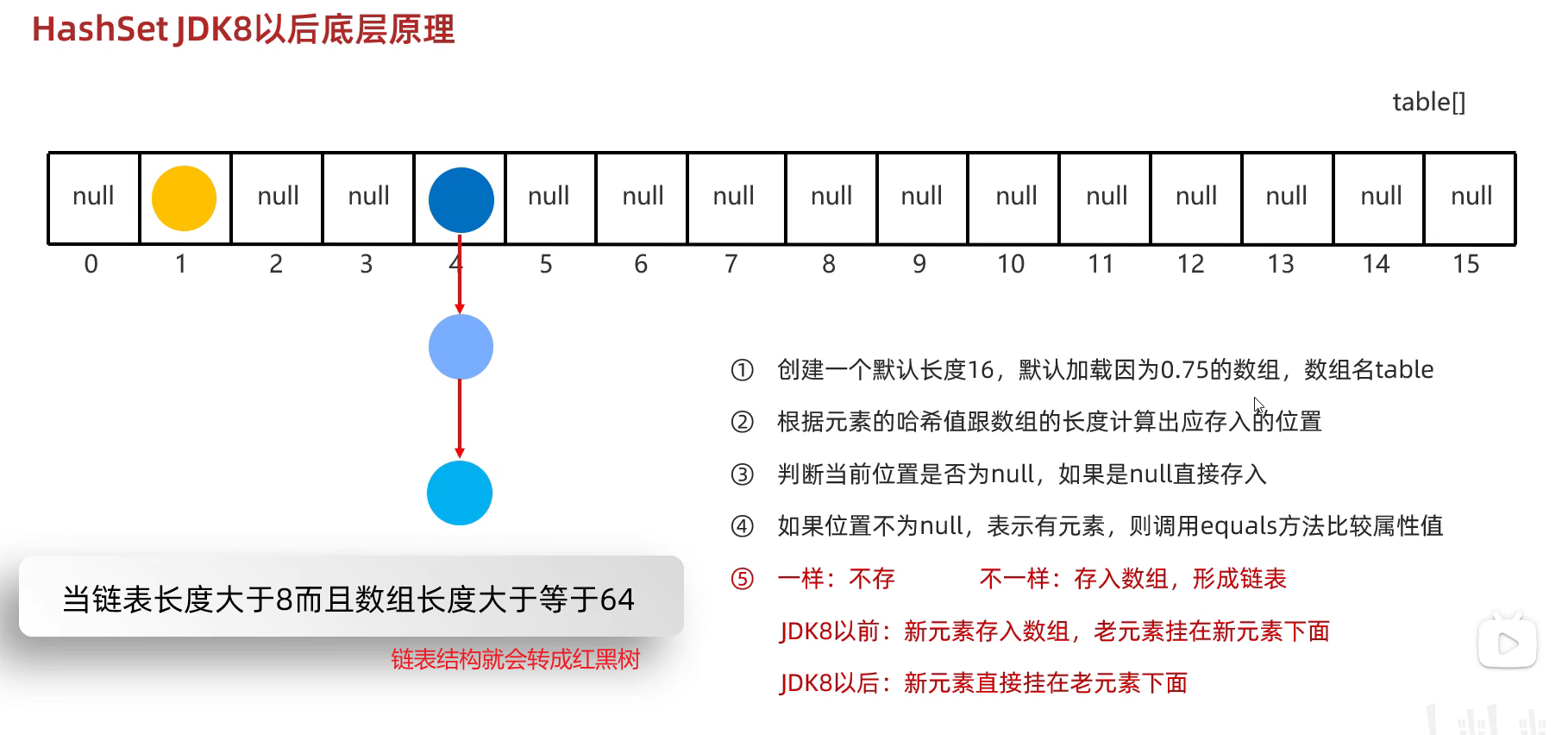
默认创建长度为16的数组,加载因子为0.75,当存入的数据超过:数组长度(16) * 加载因子(0.75) = 12 时,就会触发扩容,扩容成原来的2倍。


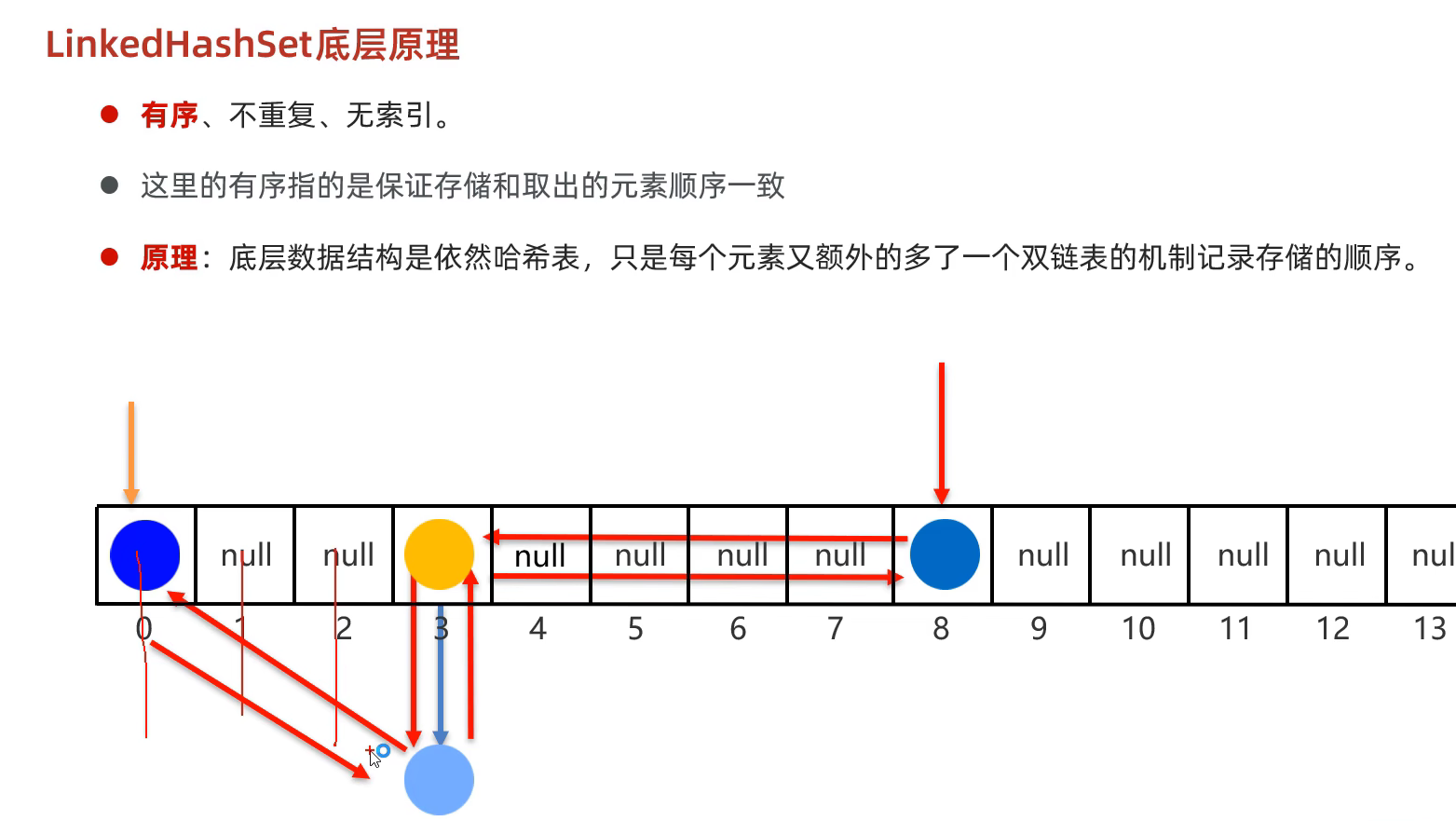
LinkedHashSet
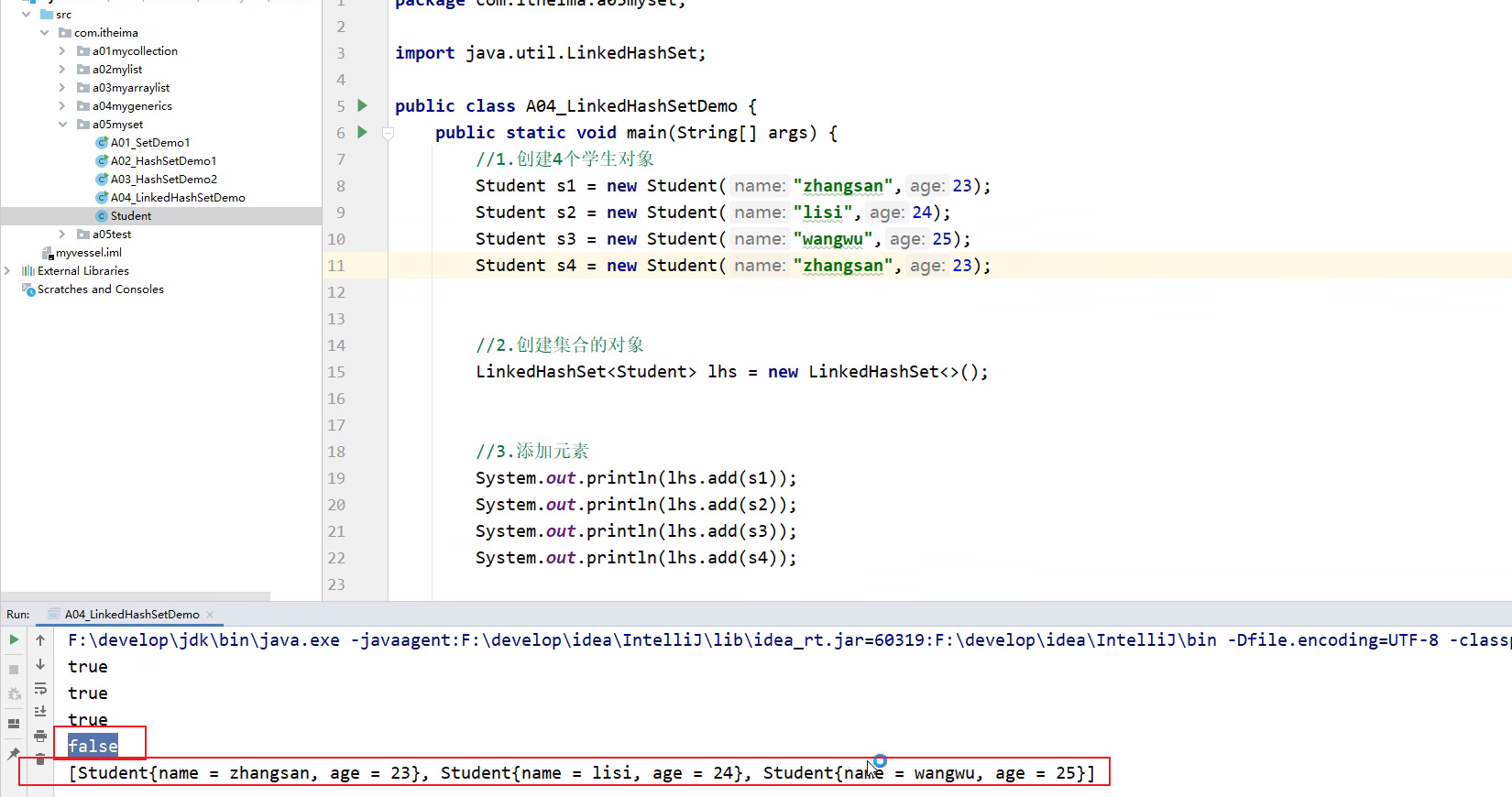

TreeSet
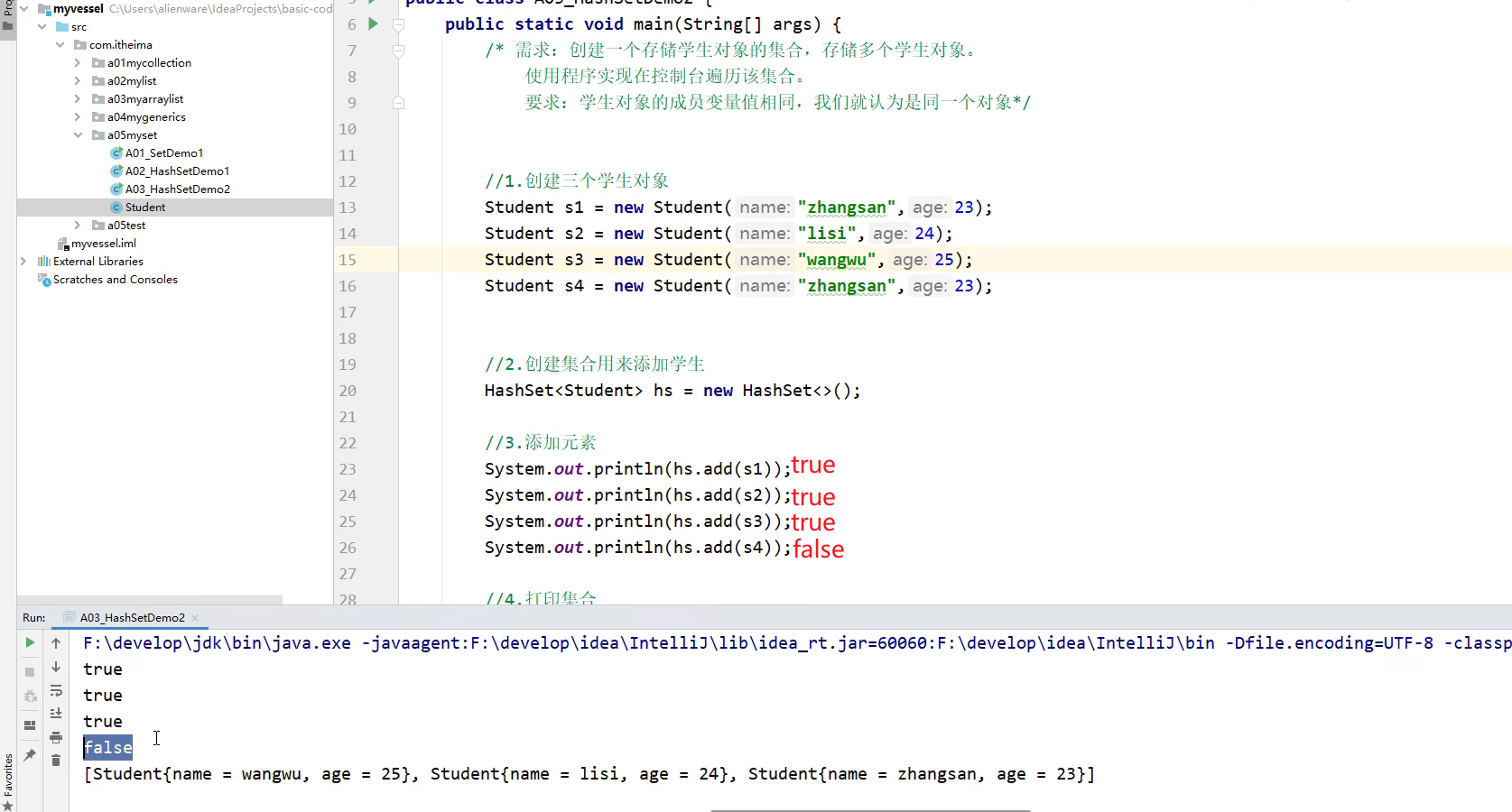
treeset底层是基于红黑树实现的,所以不HashCode方法和equals方法



方式1:
@Data
@AllArgsConstructor
@NoArgsConstructor
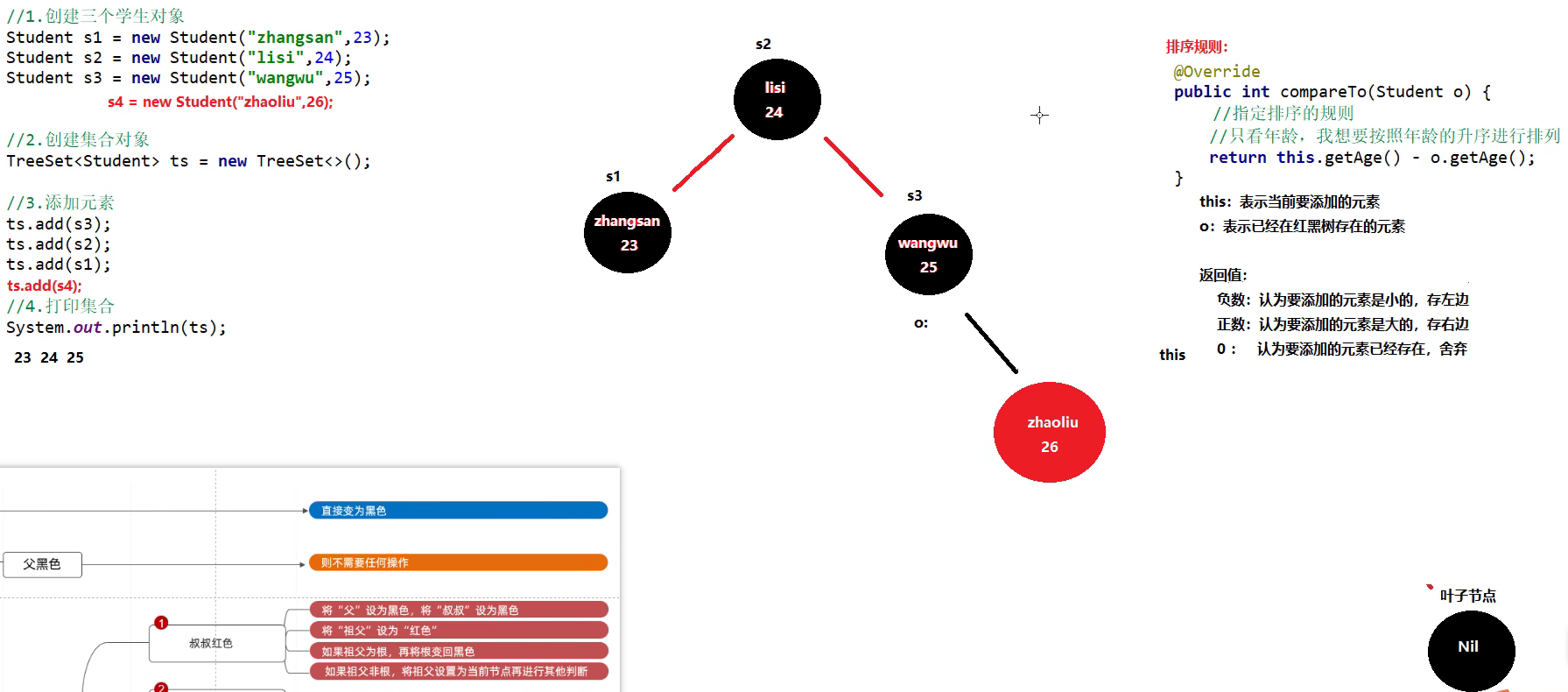
public class Student implements Comparable<Student>{private String name;private Integer age;@Overridepublic int compareTo(Student o) {
// 使用TreeSet存储时,Student类需要实现Comparable接口,并重写compareTo方法/** this: 表示当前要添加的元素* o : 表示已经在红黑树中存在的元素* 返回值:* 负数: 表示当前要添加的元素是小的,存放时存放在o节点的左边* 正数: 表示当前要添加的元素是大的,存放时存放在o节点的右边* 0 : 表示当前要添加的元素在红黑树中已经存在了,舍弃* */return this.age - o.getAge();}
}方式2:
public static void main(String[] args) {
// 参数传递Comparator自定义排序规则,
// o1:当前要添加的元素。
// o2:已经在红黑树中存在的元素。
// 返回值跟之前是一样的TreeSet<String> ts = new TreeSet<>(new Comparator<String>() {@Overridepublic int compare(String o1, String o2) {int i = o1.length() - o2.length();
// 如果是0说明o1和o2的长度相同,那么就调用默认的比较规则
// 如果不是0,说明o1和o2的长度不同,那么就返回i,根据字符串长度排序return i == 0 ? o1.compareTo(o2) : i;}});
// 按照字符串长度排序,长度一样按照字母顺序排序ts.add("c");ts.add("ab");ts.add("df");ts.add("qwer");System.out.println(ts);}使用时,如果方式一和方式二都存在,则以方式二为准


在set集合的底层,其实是新建了一个Map集合,只不过只用到了Key,没有用Value。
双列集合

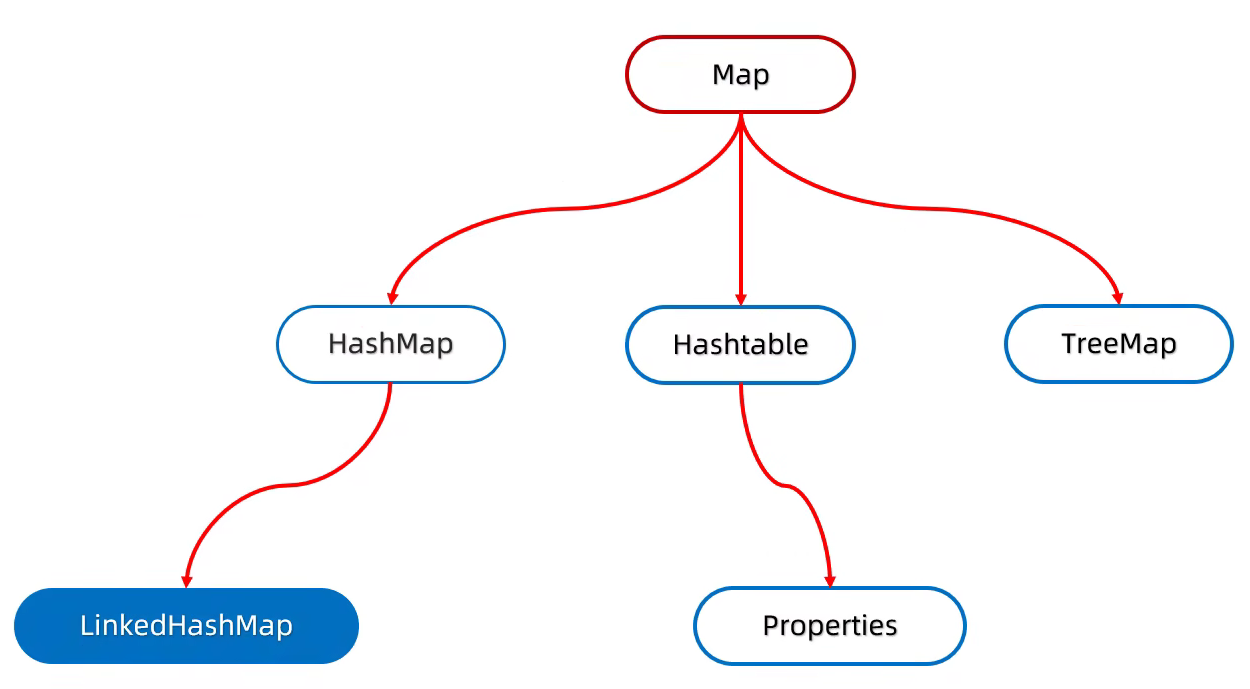
Map



map使用forEach遍历时,底层其实是增强for。
public static void main(String[] args) {Map<String,String> map = new HashMap<>();map.put("aaa","1");map.put("mmm","2");map.put("ggg","3");// 1、遍历Map集合,键找值Set<String> keys = map.keySet();
// 1.1、增强for/*for (String key : keys) {String value = map.get(key);System.out.println(key+" -- "+value);}*/
// 1.2、迭代器/*Iterator<String> it = keys.iterator();while (it.hasNext()) {String key = it.next();String value = map.get(key);System.out.println(key+" -- "+value);}*/
// 1.3、lambda/*keys.forEach(item -> {String value = map.get(item);System.out.println(item+" -- "+value);});*/
// 2、遍历Map集合,遍历键值对Set<Map.Entry<String, String>> entries = map.entrySet();
// 2.1、增强for/*for (Map.Entry<String, String> entry : entries) {System.out.println(entry.getKey()+" -- "+entry.getValue());}*/
// 2.2、迭代器/*Iterator<Map.Entry<String, String>> iterator = entries.iterator();while (iterator.hasNext()) {Map.Entry<String, String> entry = iterator.next();System.out.println(entry.getKey()+" -- "+entry.getValue());}*/
// 2.3、lambda/*entries.forEach(item ->System.out.println(item.getKey()+" -- "+item.getValue()));*/
// 3、lambda
// 完整写法 底层其实是增强for/*map.forEach(new BiConsumer<String, String>() {@Overridepublic void accept(String key, String value) {System.out.println(key+" -- "+value);}});*/
// 简化写法map.forEach((key,value) -> System.out.println(key+" -- "+value));}HashMap

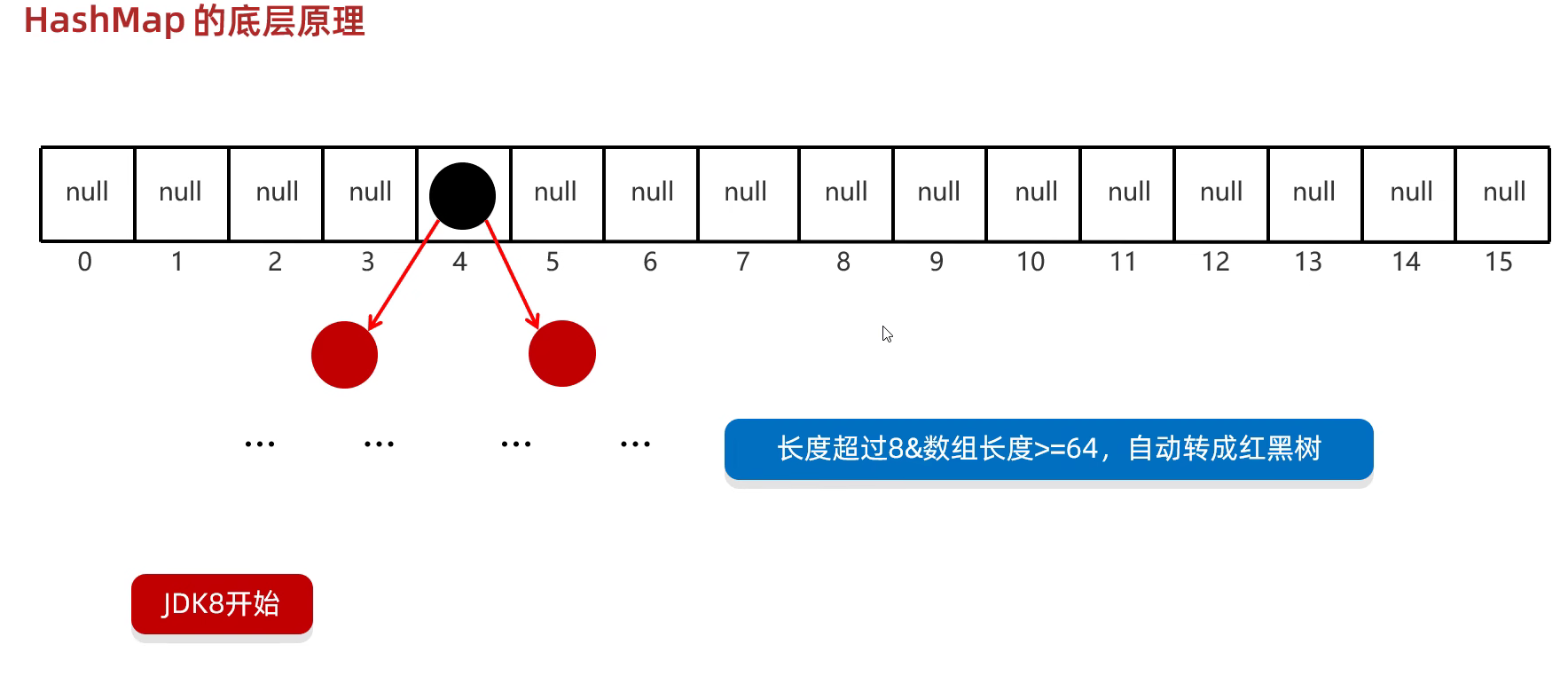
存入数据时,根据key值进行哈希运算,找到应存入的位置后,如果已经有元素了,会调用equals进行比较,如果发现key相同,就会进行覆盖操作,如果key不同就会形成链表挂在下面。
LinkedHashMap
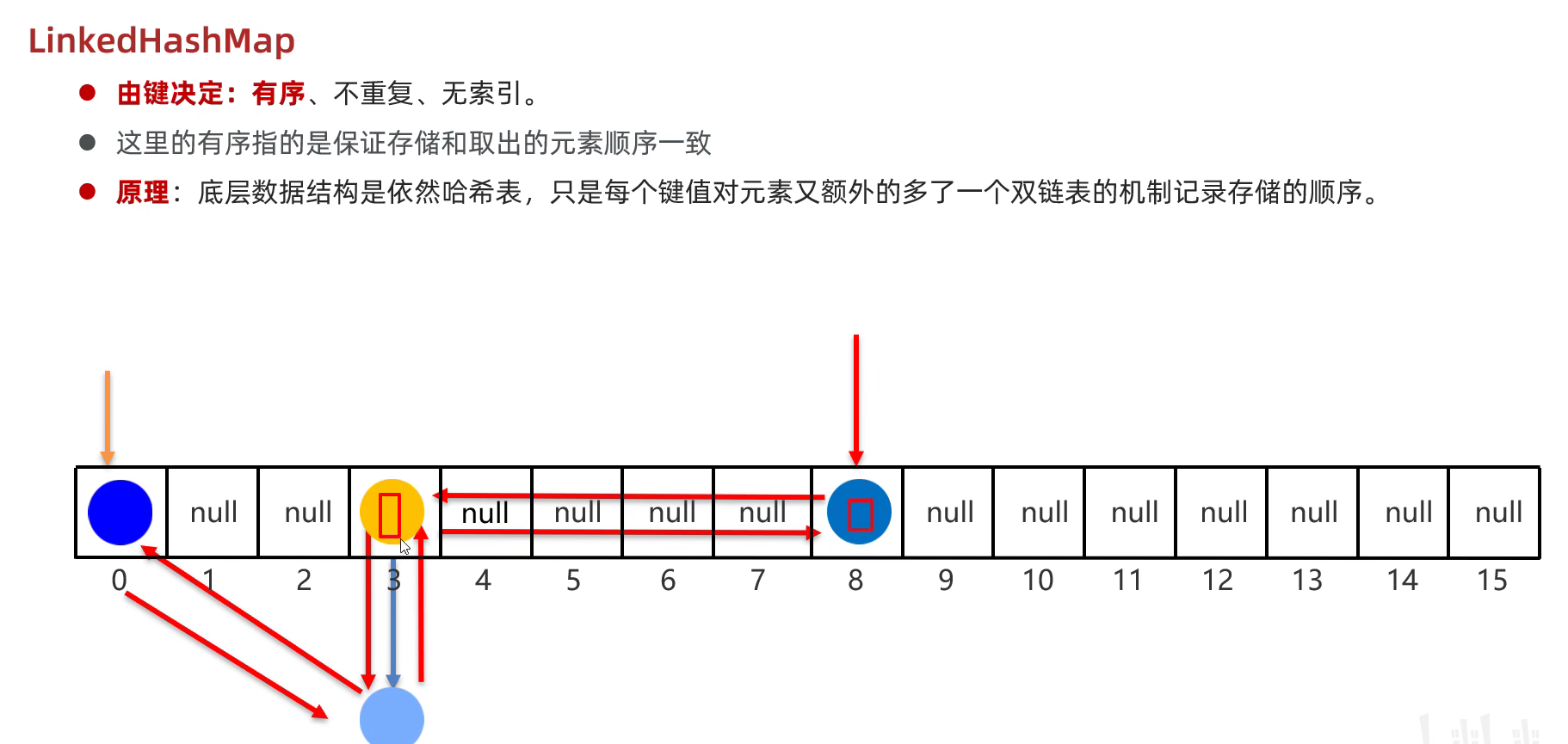
LinkedHashMap可以保证存取顺序不变,因为底层除了数组链表红黑树外还维护了一条双向链表来记录顺序
TreeMap



HashMap源码
建议观看视频:HashMap源码讲解![]() https://www.bilibili.com/video/BV1yW4y1Y7Ms?spm_id_from=333.788.videopod.episodes&vd_source=7345a308eb65e371bc42630bee670443&p=14
https://www.bilibili.com/video/BV1yW4y1Y7Ms?spm_id_from=333.788.videopod.episodes&vd_source=7345a308eb65e371bc42630bee670443&p=14
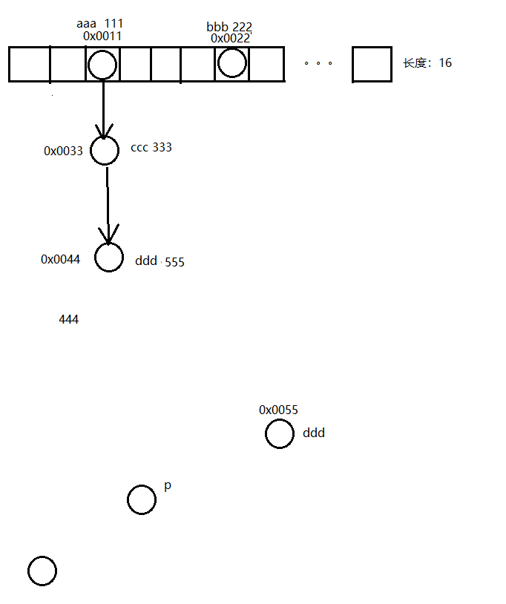
public class HashMapCode {1.看源码之前需要了解的一些内容Node<K,V>[] table 哈希表结构中数组的名字DEFAULT_INITIAL_CAPACITY: 数组默认长度16DEFAULT_LOAD_FACTOR: 默认加载因子0.75HashMap里面每一个对象包含以下内容:1.1 链表中的键值对对象包含:int hash; //键的哈希值final K key; //键V value; //值Node<K,V> next; //下一个节点的地址值1.2 红黑树中的键值对对象包含:int hash; //键的哈希值final K key; //键V value; //值TreeNode<K,V> parent; //父节点的地址值TreeNode<K,V> left; //左子节点的地址值TreeNode<K,V> right; //右子节点的地址值boolean red; //节点的颜色2.添加元素
HashMap<String,Integer> hm = new HashMap<>();
hm.put("aaa" , 111);
hm.put("bbb" , 222);
hm.put("ccc" , 333);
hm.put("ddd" , 444);
hm.put("eee" , 555);添加元素的时候至少考虑三种情况:2.1数组位置为null2.2数组位置不为null,键不重复,挂在下面形成链表或者红黑树2.3数组位置不为null,键重复,元素覆盖//参数一:键
//参数二:值//返回值:被覆盖元素的值,如果没有覆盖,返回nullpublic V put(K key, V value) {return putVal(hash(key), key, value, false, true);}//利用键计算出对应的哈希值,再把哈希值进行一些额外的处理
//简单理解:返回值就是返回键的哈希值static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}//参数一:键的哈希值
//参数二:键
//参数三:值
//参数四:如果键重复了是否保留
// true,表示老元素的值保留,不会覆盖
// false,表示老元素的值不保留,会进行覆盖final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {//定义一个局部变量,用来记录哈希表中数组的地址值。Node<K,V>[] tab;//临时的第三方变量,用来记录键值对对象的地址值Node<K,V> p;//表示当前数组的长度int n;//表示索引int i;//把哈希表中数组的地址值,赋值给局部变量tabtab = table;if (tab == null || (n = tab.length) == 0){//1.如果当前是第一次添加数据,底层会创建一个默认长度为16,加载因子为0.75的数组//2.如果不是第一次添加数据,会看数组中的元素是否达到了扩容的条件//如果没有达到扩容条件,底层不会做任何操作//如果达到了扩容条件,底层会把数组扩容为原先的两倍,并把数据全部转移到新的哈希表中tab = resize();//表示把当前数组的长度赋值给nn = tab.length;}//拿着数组的长度跟键的哈希值进行计算,计算出当前键值对对象,在数组中应存入的位置i = (n - 1) & hash;//index//获取数组中对应元素的数据p = tab[i];if (p == null){//底层会创建一个键值对对象,直接放到数组当中tab[i] = newNode(hash, key, value, null);}else {Node<K,V> e;K k;//等号的左边:数组中键值对的哈希值//等号的右边:当前要添加键值对的哈希值//如果键不一样,此时返回false//如果键一样,返回trueboolean b1 = p.hash == hash;if (b1 && ((k = p.key) == key || (key != null && key.equals(k)))){e = p;} else if (p instanceof TreeNode){//判断数组中获取出来的键值对是不是红黑树中的节点//如果是,则调用方法putTreeVal,把当前的节点按照红黑树的规则添加到树当中。e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);} else {//如果从数组中获取出来的键值对不是红黑树中的节点//表示此时下面挂的是链表for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {//此时就会创建一个新的节点,挂在下面形成链表p.next = newNode(hash, key, value, null);//判断当前链表长度是否超过8,如果超过8,就会调用方法treeifyBin//treeifyBin方法的底层还会继续判断//判断数组的长度是否大于等于64//如果同时满足这两个条件,就会把这个链表转成红黑树if (binCount >= TREEIFY_THRESHOLD - 1)treeifyBin(tab, hash);break;}//e: 0x0044 ddd 444//要添加的元素: 0x0055 ddd 555//如果哈希值一样,就会调用equals方法比较内部的属性值是否相同if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))){break;}p = e;}}//如果e为null,表示当前不需要覆盖任何元素//如果e不为null,表示当前的键是一样的,值会被覆盖//e:0x0044 ddd 555//要添加的元素: 0x0055 ddd 555if (e != null) {V oldValue = e.value;if (!onlyIfAbsent || oldValue == null){//等号的右边:当前要添加的值//等号的左边:0x0044的值e.value = value;}afterNodeAccess(e);return oldValue;}}//threshold:记录的就是数组的长度 * 0.75,哈希表的扩容时机 16 * 0.75 = 12if (++size > threshold){resize();}//表示当前没有覆盖任何元素,返回nullreturn null;}
}
TreeMap源码
视频地址:TreeMap源码讲解![]() https://www.bilibili.com/video/BV1yW4y1Y7Ms?spm_id_from=333.788.videopod.episodes&vd_source=7345a308eb65e371bc42630bee670443&p=18
https://www.bilibili.com/video/BV1yW4y1Y7Ms?spm_id_from=333.788.videopod.episodes&vd_source=7345a308eb65e371bc42630bee670443&p=18
public class TreeMapCode {1.TreeMap中每一个节点的内部属性K key; //键V value; //值Entry<K,V> left; //左子节点Entry<K,V> right; //右子节点Entry<K,V> parent; //父节点boolean color; //节点的颜色2.TreeMap类中中要知道的一些成员变量public class TreeMap<K,V>{//比较器对象private final Comparator<? super K> comparator;//根节点private transient Entry<K,V> root;//集合的长度private transient int size = 0;3.空参构造//空参构造就是没有传递比较器对象public TreeMap() {comparator = null;}4.带参构造//带参构造就是传递了比较器对象。public TreeMap(Comparator<? super K> comparator) {this.comparator = comparator;}5.添加元素public V put(K key, V value) {return put(key, value, true);}参数一:键参数二:值参数三:当键重复的时候,是否需要覆盖值true:覆盖false:不覆盖private V put(K key, V value, boolean replaceOld) {//获取根节点的地址值,赋值给局部变量tEntry<K,V> t = root;//判断根节点是否为null//如果为null,表示当前是第一次添加,会把当前要添加的元素,当做根节点//如果不为null,表示当前不是第一次添加,跳过这个判断继续执行下面的代码if (t == null) {//方法的底层,会创建一个Entry对象,把他当做根节点addEntryToEmptyMap(key, value);//表示此时没有覆盖任何的元素return null;}//表示两个元素的键比较之后的结果int cmp;//表示当前要添加节点的父节点Entry<K,V> parent;//表示当前的比较规则//如果我们是采取默认的自然排序,那么此时comparator记录的是null,cpr记录的也是null//如果我们是采取比较去排序方式,那么此时comparator记录的是就是比较器Comparator<? super K> cpr = comparator;//表示判断当前是否有比较器对象//如果传递了比较器对象,就执行if里面的代码,此时以比较器的规则为准//如果没有传递比较器对象,就执行else里面的代码,此时以自然排序的规则为准if (cpr != null) {do {parent = t;cmp = cpr.compare(key, t.key);if (cmp < 0)t = t.left;else if (cmp > 0)t = t.right;else {V oldValue = t.value;if (replaceOld || oldValue == null) {t.value = value;}return oldValue;}} while (t != null);} else {//把键进行强转,强转成Comparable类型的//要求:键必须要实现Comparable接口,如果没有实现这个接口//此时在强转的时候,就会报错。Comparable<? super K> k = (Comparable<? super K>) key;do {//把根节点当做当前节点的父节点parent = t;//调用compareTo方法,比较根节点和当前要添加节点的大小关系cmp = k.compareTo(t.key);if (cmp < 0)//如果比较的结果为负数//那么继续到根节点的左边去找t = t.left;else if (cmp > 0)//如果比较的结果为正数//那么继续到根节点的右边去找t = t.right;else {//如果比较的结果为0,会覆盖V oldValue = t.value;if (replaceOld || oldValue == null) {t.value = value;}return oldValue;}} while (t != null);}//就会把当前节点按照指定的规则进行添加addEntry(key, value, parent, cmp < 0);return null;}private void addEntry(K key, V value, Entry<K, V> parent, boolean addToLeft) {Entry<K,V> e = new Entry<>(key, value, parent);if (addToLeft)parent.left = e;elseparent.right = e;//添加完毕之后,需要按照红黑树的规则进行调整fixAfterInsertion(e);size++;modCount++;}private void fixAfterInsertion(Entry<K,V> x) {//因为红黑树的节点默认就是红色的x.color = RED;//按照红黑规则进行调整//parentOf:获取x的父节点//parentOf(parentOf(x)):获取x的爷爷节点//leftOf:获取左子节点while (x != null && x != root && x.parent.color == RED) {//判断当前节点的父节点是爷爷节点的左子节点还是右子节点//目的:为了获取当前节点的叔叔节点if (parentOf(x) == leftOf(parentOf(parentOf(x)))) {//表示当前节点的父节点是爷爷节点的左子节点//那么下面就可以用rightOf获取到当前节点的叔叔节点Entry<K,V> y = rightOf(parentOf(parentOf(x)));if (colorOf(y) == RED) {//叔叔节点为红色的处理方案//把父节点设置为黑色setColor(parentOf(x), BLACK);//把叔叔节点设置为黑色setColor(y, BLACK);//把爷爷节点设置为红色setColor(parentOf(parentOf(x)), RED);//把爷爷节点设置为当前节点x = parentOf(parentOf(x));} else {//叔叔节点为黑色的处理方案//表示判断当前节点是否为父节点的右子节点if (x == rightOf(parentOf(x))) {//表示当前节点是父节点的右子节点x = parentOf(x);//左旋rotateLeft(x);}setColor(parentOf(x), BLACK);setColor(parentOf(parentOf(x)), RED);rotateRight(parentOf(parentOf(x)));}} else {//表示当前节点的父节点是爷爷节点的右子节点//那么下面就可以用leftOf获取到当前节点的叔叔节点Entry<K,V> y = leftOf(parentOf(parentOf(x)));if (colorOf(y) == RED) {setColor(parentOf(x), BLACK);setColor(y, BLACK);setColor(parentOf(parentOf(x)), RED);x = parentOf(parentOf(x));} else {if (x == leftOf(parentOf(x))) {x = parentOf(x);rotateRight(x);}setColor(parentOf(x), BLACK);setColor(parentOf(parentOf(x)), RED);rotateLeft(parentOf(parentOf(x)));}}}//把根节点设置为黑色root.color = BLACK;}
6.课堂思考问题:6.1TreeMap添加元素的时候,键是否需要重写hashCode和equals方法?此时是不需要重写的。6.2HashMap是哈希表结构的,JDK8开始由数组,链表,红黑树组成的。既然有红黑树,HashMap的键是否需要实现Compareable接口或者传递比较器对象呢?不需要的。因为在HashMap的底层,默认是利用哈希值的大小关系来创建红黑树的6.3TreeMap和HashMap谁的效率更高?如果是最坏情况,添加了8个元素,这8个元素形成了链表,此时TreeMap的效率要更高但是这种情况出现的几率非常的少。一般而言,还是HashMap的效率要更高。6.4你觉得在Map集合中,java会提供一个如果键重复了,不会覆盖的put方法呢?此时putIfAbsent本身不重要。传递一个思想:代码中的逻辑都有两面性,如果我们只知道了其中的A面,而且代码中还发现了有变量可以控制两面性的发生。那么该逻辑一定会有B面。习惯:boolean类型的变量控制,一般只有AB两面,因为boolean只有两个值int类型的变量控制,一般至少有三面,因为int可以取多个值。6.5三种双列集合,以后如何选择?HashMap LinkedHashMap TreeMap默认:HashMap(效率最高)如果要保证存取有序:LinkedHashMap如果要进行排序:TreeMap}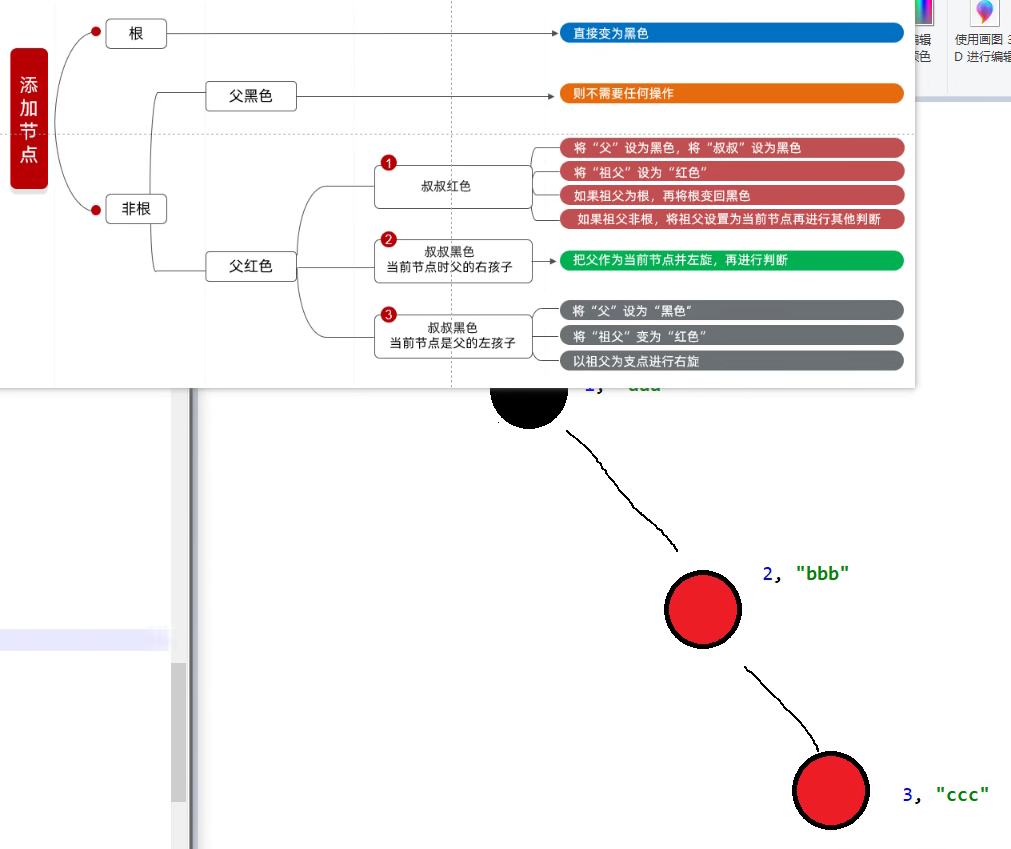
后续
可变参数


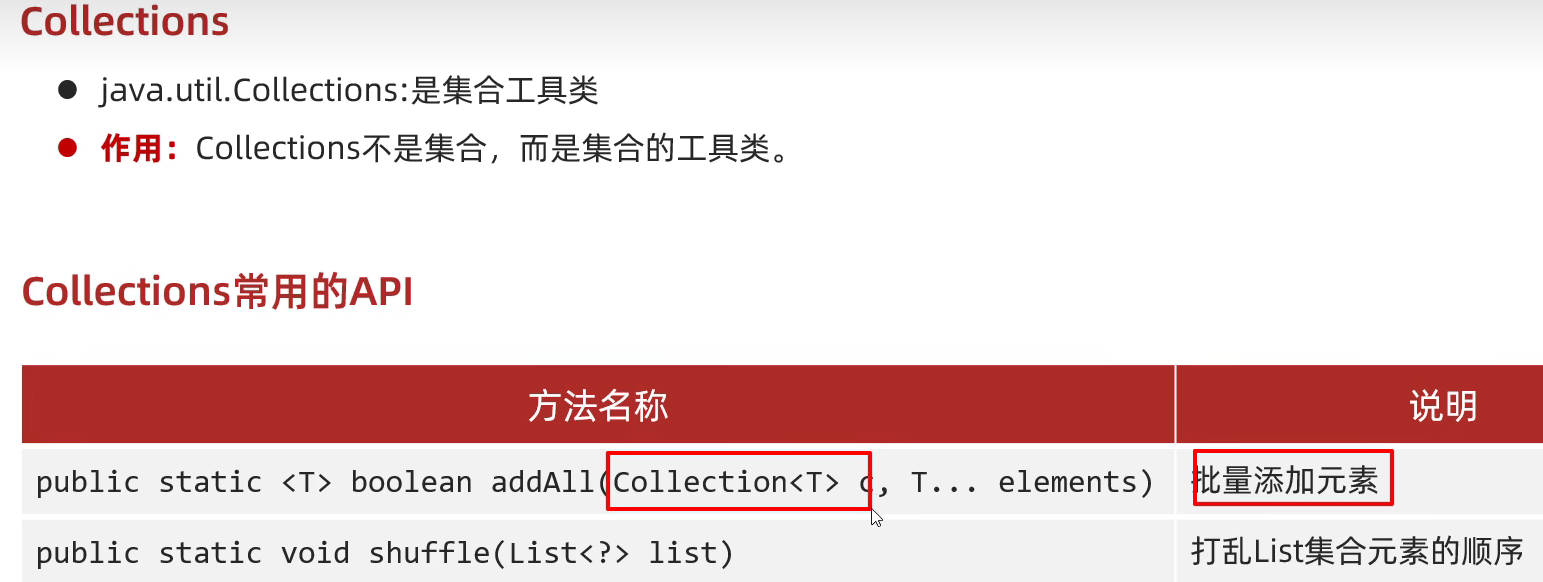
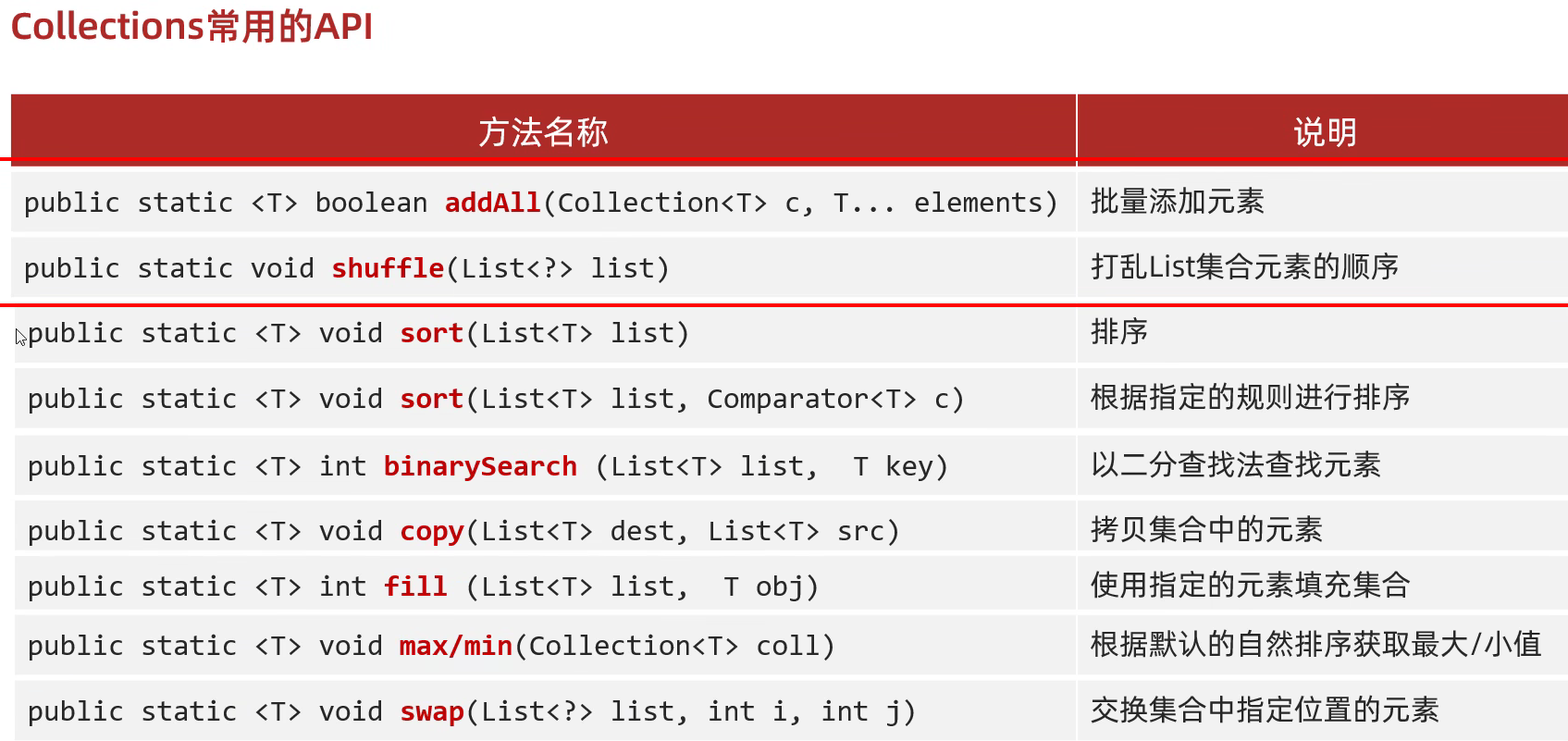
集合工具类Collections
不可变集合
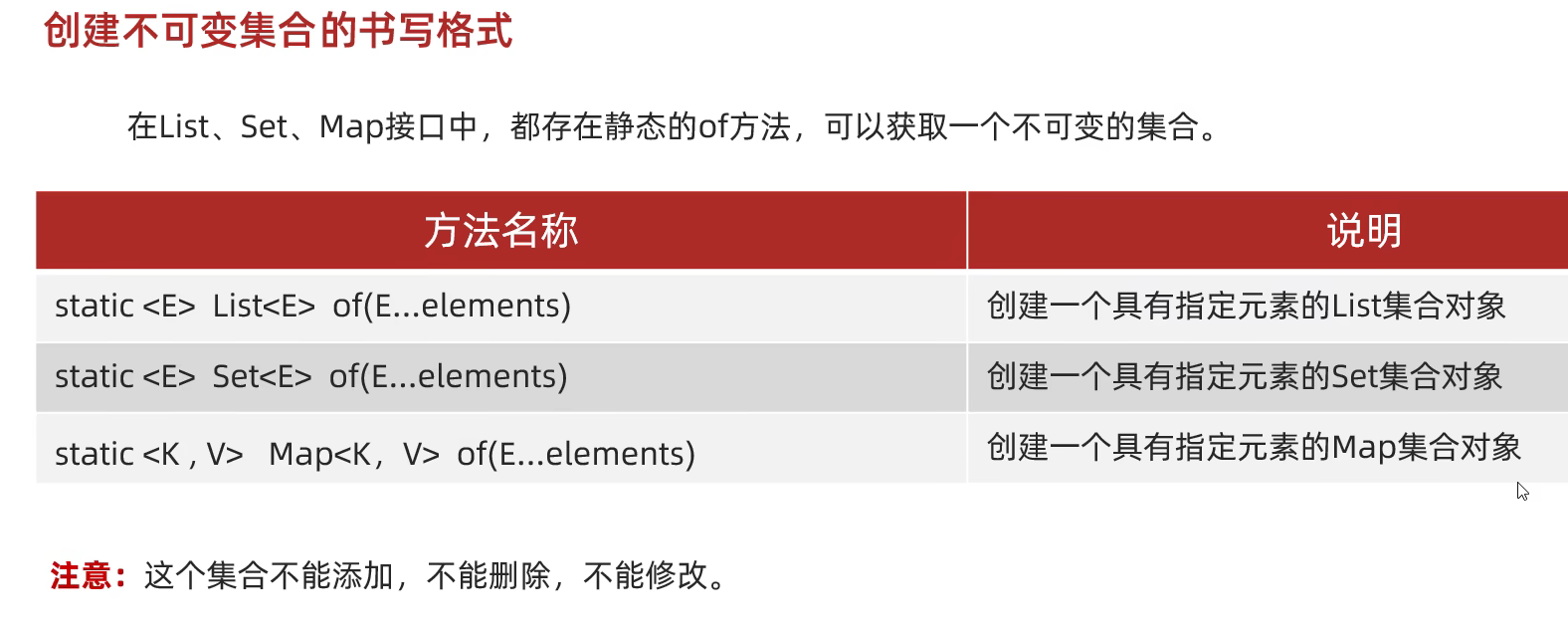



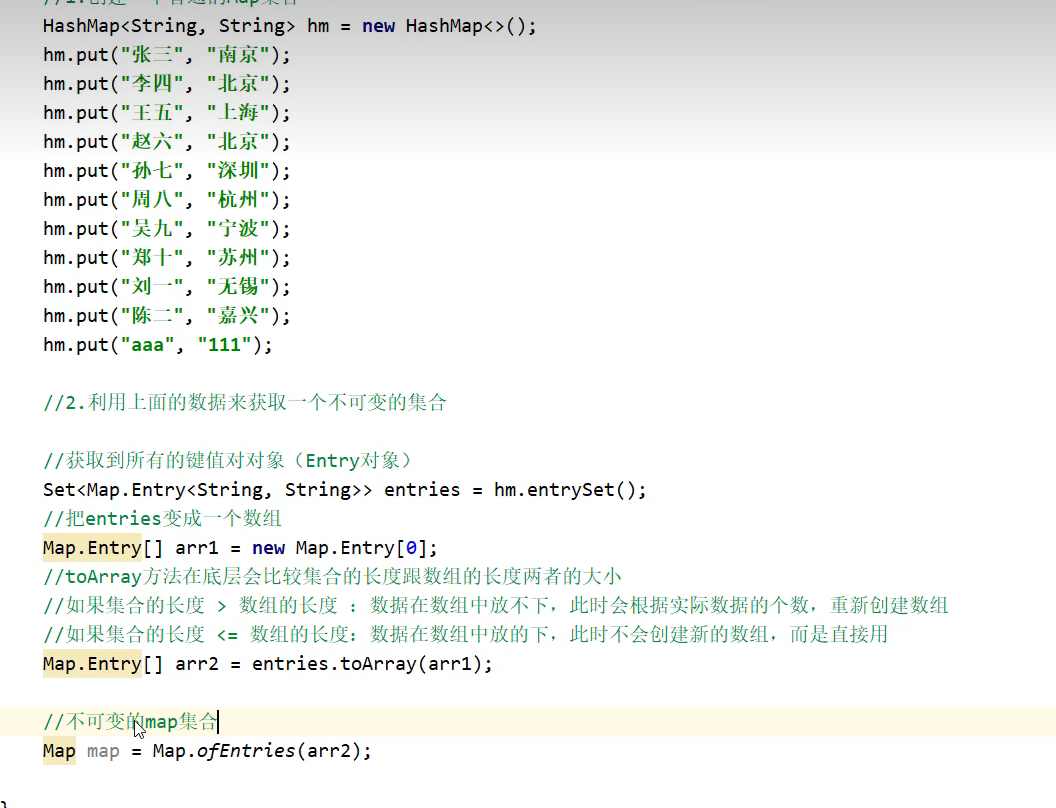


在jdk10+,创建不可变的map集合,可以使用copyof方法传递map集合来创建一个不可变的map集合
Stream流
获取stream流

Stream流的中间方法
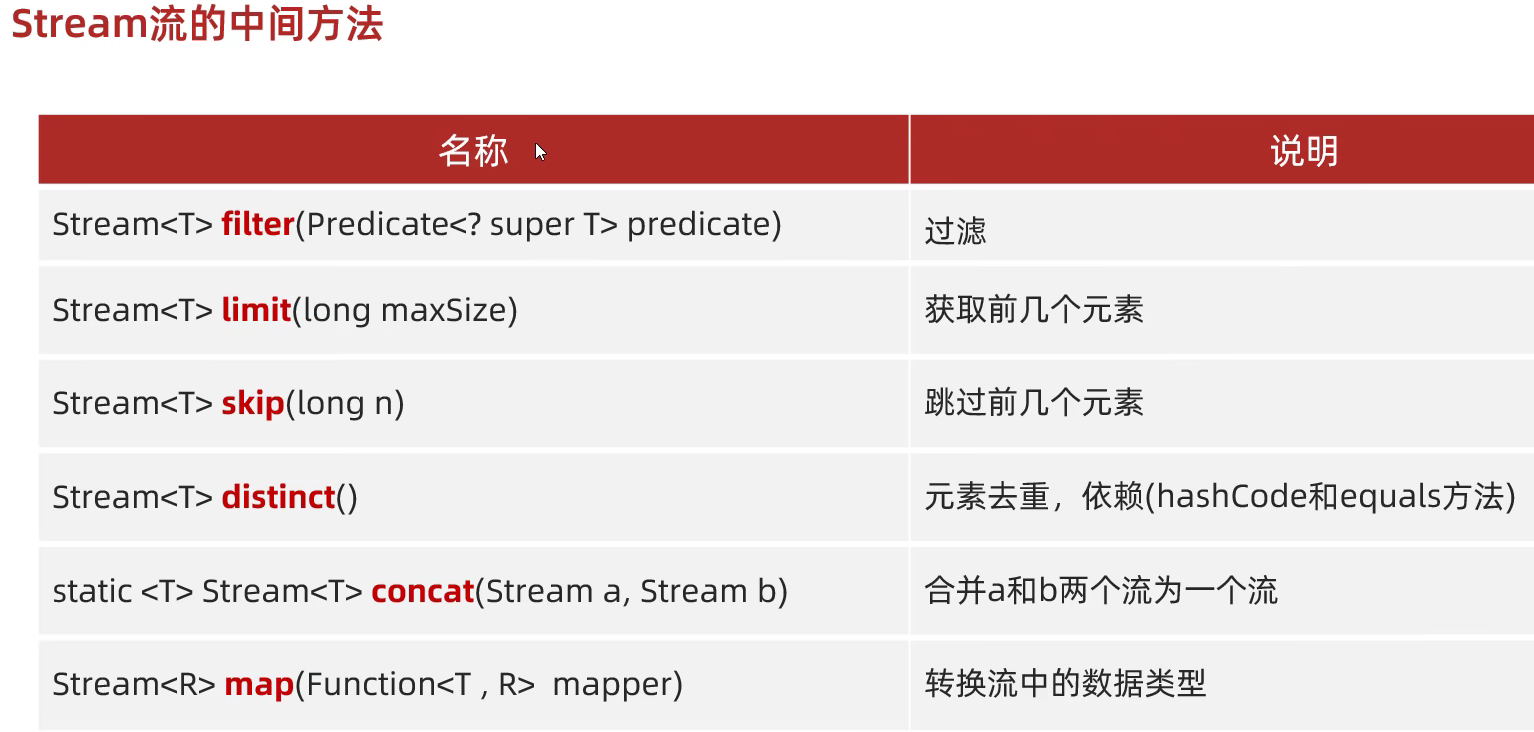
filter:


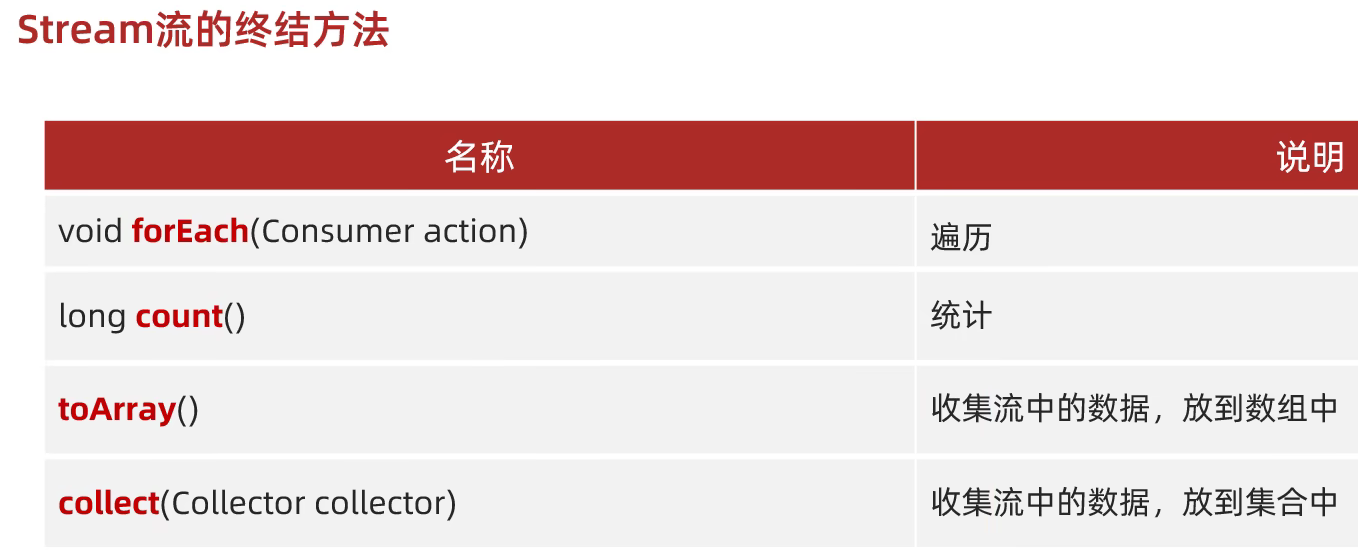
Stream流的终结方法

public static void main(String[] args) {ArrayList<String> list = new ArrayList<>();list.add("zhangsan-23");list.add("zhangsan1-14");list.add("zhangsan2-15");list.add("zhangsan3-16");list.add("zhangsan4-17");list.add("zhangsan5-18");list.add("lisi-24");list.add("wangwu-25");Integer[] ages = list.stream()
// 将list集合转成一个流(list集合不会改变).filter(s -> s.startsWith("z"))
// 过滤,留下以z开头的.skip(1)
// 将上述符合条件的元素跳过前面1个元素,获取后面几个.limit(2)
// 将上述符合条件的元素跳过前1个元素后,在获取剩下元素中前面2个元素.map(item -> Integer.parseInt(item.split("-")[1]))
// 转换,item就是list中的每个符合以z开头的、跳过前面1个的、获取前面2个元素的元素
// 将所有符合条件的元素以“-”分割,获取索引为1的元素转成int类型.toArray(len -> new Integer[len]);
// 将上面转换后的int类型的数据流转成一个数组,
// 这里的len就是上面转换后的int类型数据的个数(len表示个数)Arrays.stream(ages).forEach(System.out::println);
// 数组无法直接获取流对象,通过Arrays.stream()方法获取}收集方法




案例

public static void main(String[] args) {ArrayList<String> boyList = new ArrayList<>();ArrayList<String> girlList = new ArrayList<>();Collections.addAll(boyList, "蔡坤坤,24", "叶齁咸,23", "刘不甜,22", "吴谦,24", "骨架,30", "肖梁梁,27");Collections.addAll(girlList, "赵小颖,35", "杨颖,36", "高圆圆,43", "张天天,31", "刘诗,35", "杨小幂,33");
// 题目1
// boyList.stream()
// .filter(item -> item.split(",")[0].length() == 3)
// .limit(2)
// .forEach(System.out::println);
// 题目2
// girlList.stream()
// .filter(item -> item.split(",")[0].startsWith("杨"))
// .skip(1)
// .forEach(System.out::println);
// 题目3// Stream.concat(
// boyList.stream()
// .filter(item -> item.split(",")[0].length() == 3)
// .limit(2),
// girlList.stream()
// .filter(item -> item.split(",")[0].startsWith("杨"))
// .skip(1)
// ).forEach(System.out::println);
// 题目4List<Actor> list = Stream.concat(boyList.stream().filter(item -> item.split(",")[0].length() == 3).limit(2),girlList.stream().filter(item -> item.split(",")[0].startsWith("杨")).skip(1)).map(item ->Actor.builder().name(item.split(",")[0]).age(Integer.parseInt(item.split(",")[1])).build()).toList();list.forEach(System.out::println);}方法引用

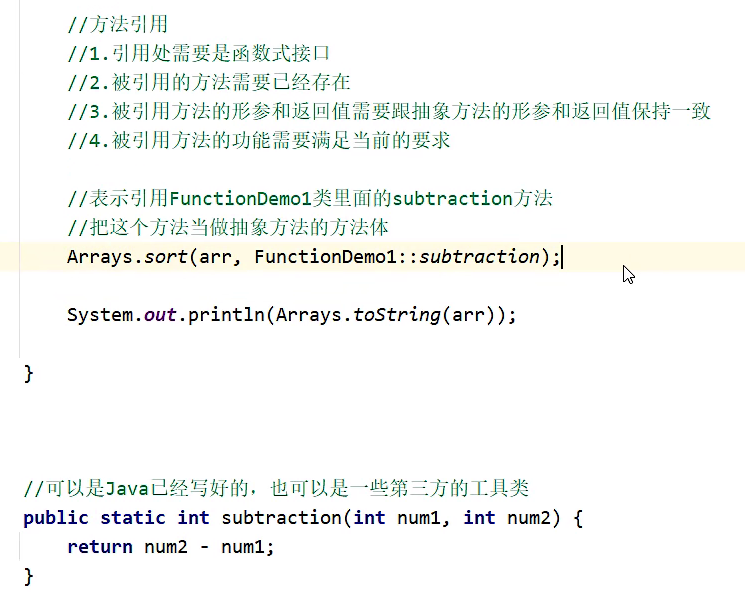

引用静态方法

引用成员方法

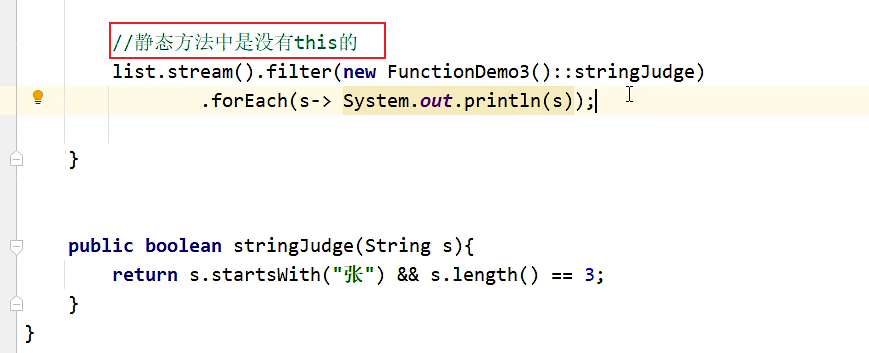
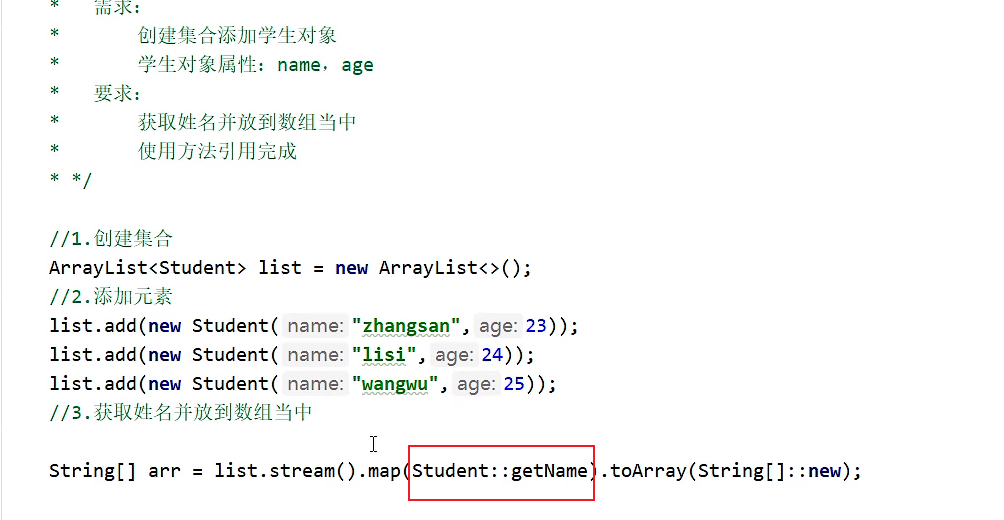
引用构造方法 --> 目的:创建对象

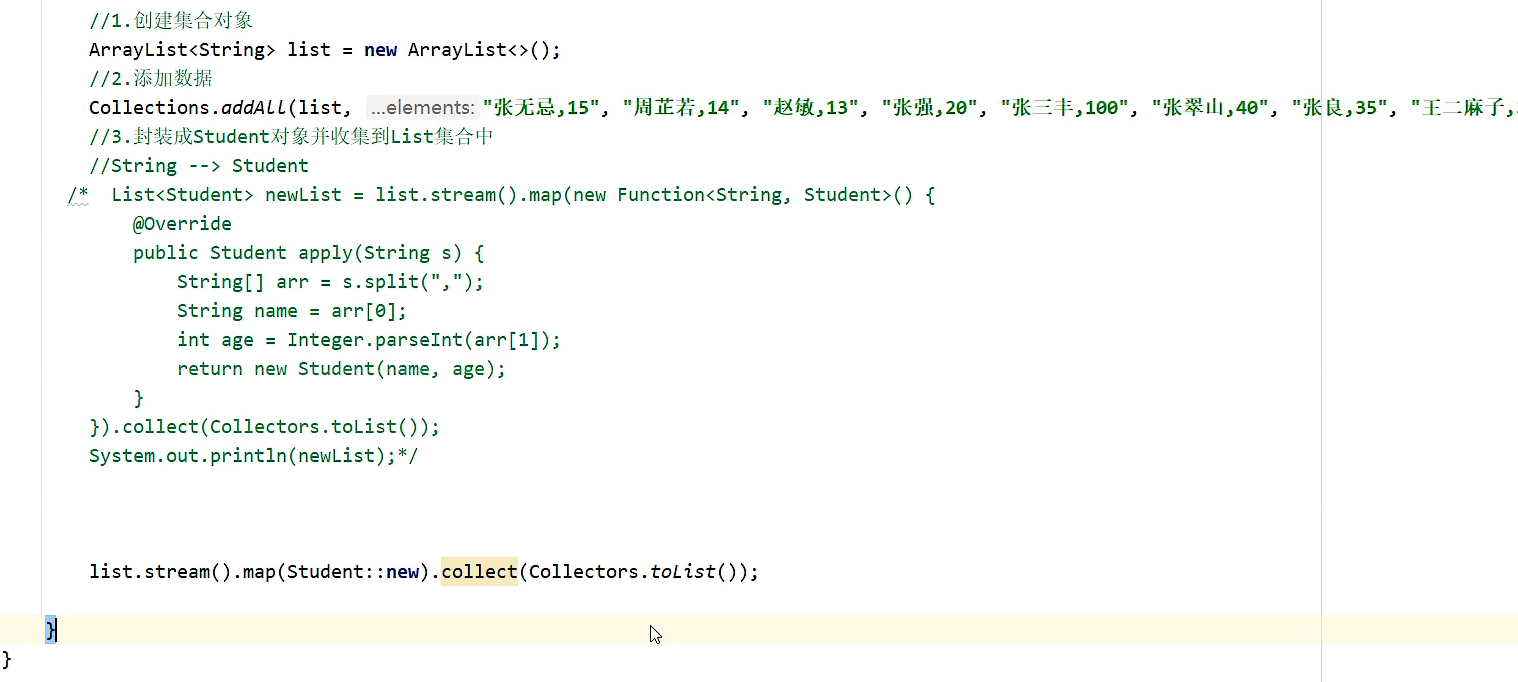
要求,在Student的类中,有一个构造方法是这样的,这样才能引用这个构造

扩展
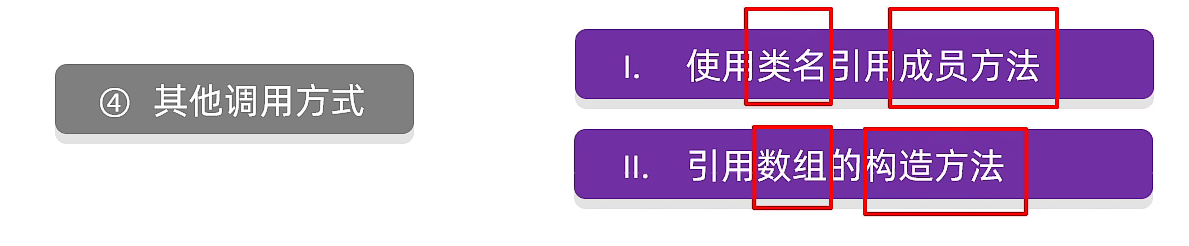
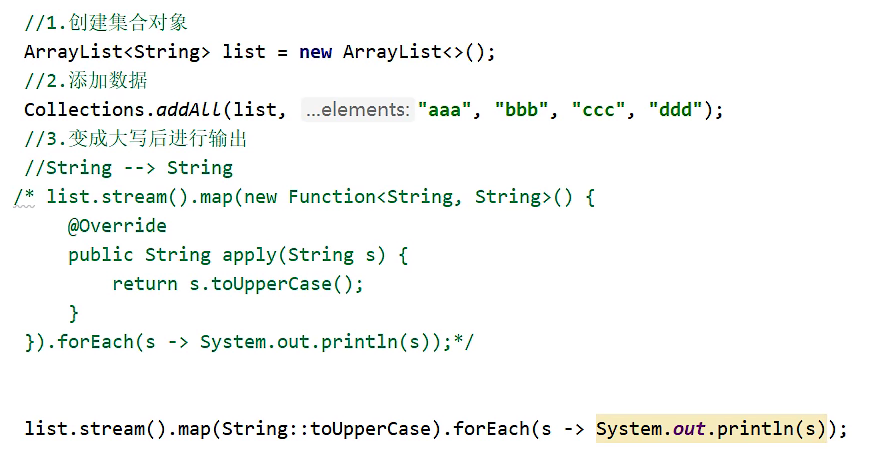
1、使用类名引用成员方法

2、引用数组中的构造方法


总结