分享一些多模态文档解析思路
多模态文档解析思路小记
作者:Arlene
原文:https://zhuanlan.zhihu.com/p/1905635679293122466
多模态文档解析内容涉及:文本、表格和图片
解析思路v1
-
基于mineru框架对pdf文件进行初解析
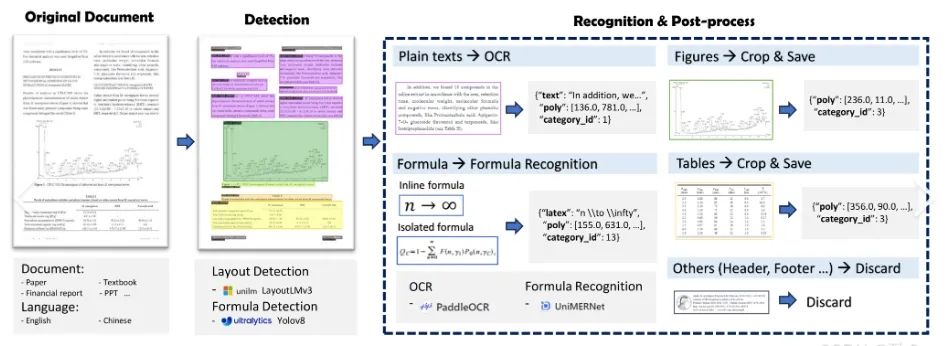
其具备较完整的布局识别和内容识别,并将识别的结果编辑为markdown格式。
-
针对使用场景如合同审核进行二次处理
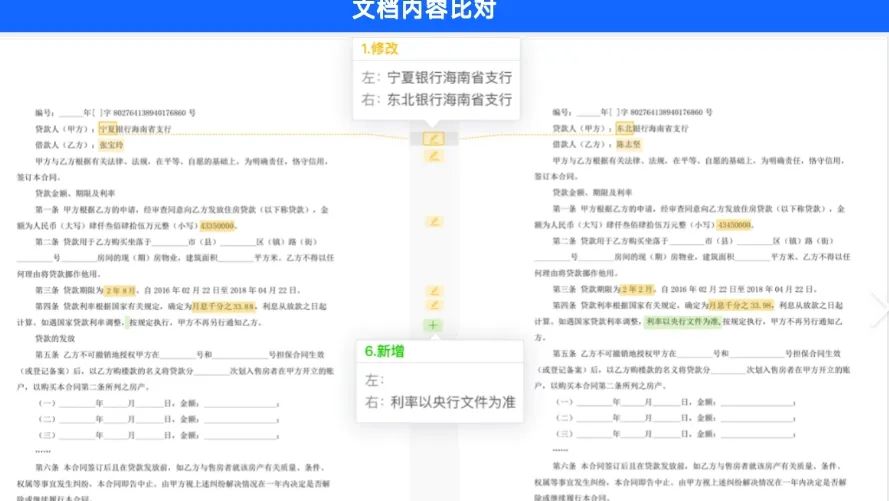
合同审核场景对合同内容的准确性和完整性要求较高,故将解析出的discarded_blocks内容进行复原,重构md文件。
-
多模态内容理解
使用vlm对合同的图像和表格图像进行整体内容分析。经测试,至少qwen 2.5 vl -7b以上的模型方可实现较为准确的内容描述。
v1版问题及解决方案:
-
出现整行内容识别遗漏。(解决:将magic-pdf版本更新至3.11版本,一定程度上解决了现在的问题)
-
discared_blocks中可能包含一些识别准确率较低的内容。(解决:通过score设置阈值&判断文本字数筛选)
-
表格截取不全
参考
-
mineru项目地址:GitHub - opendatalab/MinerU: A high-quality tool for convert PDF to Markdown and JSON.一站式开源高质量数据提取工具,将PDF转换成Markdown和JSON格式。
-
