如何设计智慧工地系统的数据库?
如何设计智慧工地系统的数据库
设计智慧工地系统的数据库时,需要考虑系统的核心功能和数据交互需求,确保数据的高效存储、检索和安全性。以下是一些关键步骤和设计原则:
1、数据模型设计
实体识别:首先识别出系统中的核心实体,如工人、设备、项目、环境监测点等。
关系定义:明确实体之间的关系,例如工人与项目的关系(参与项目)、设备与位置的关系(部署位置)等。
属性定义:为每个实体定义属性,如工人的姓名、工号、安全培训记录;设备的型号、状态、维护记录等。
2、数据库架构选择
微服务架构下的数据库设计:如果采用微服务架构,每个服务可能对应一个或多个数据库表,以支持服务的独立扩展和数据隔离。
关系型数据库(如MySQL):适合处理结构化数据,如项目管理、人员信息、设备登记等。
NoSQL数据库:对于非结构化数据,如视频监控的元数据、环境监测的实时数据,NoSQL数据库(如MongoDB)可能更合适。
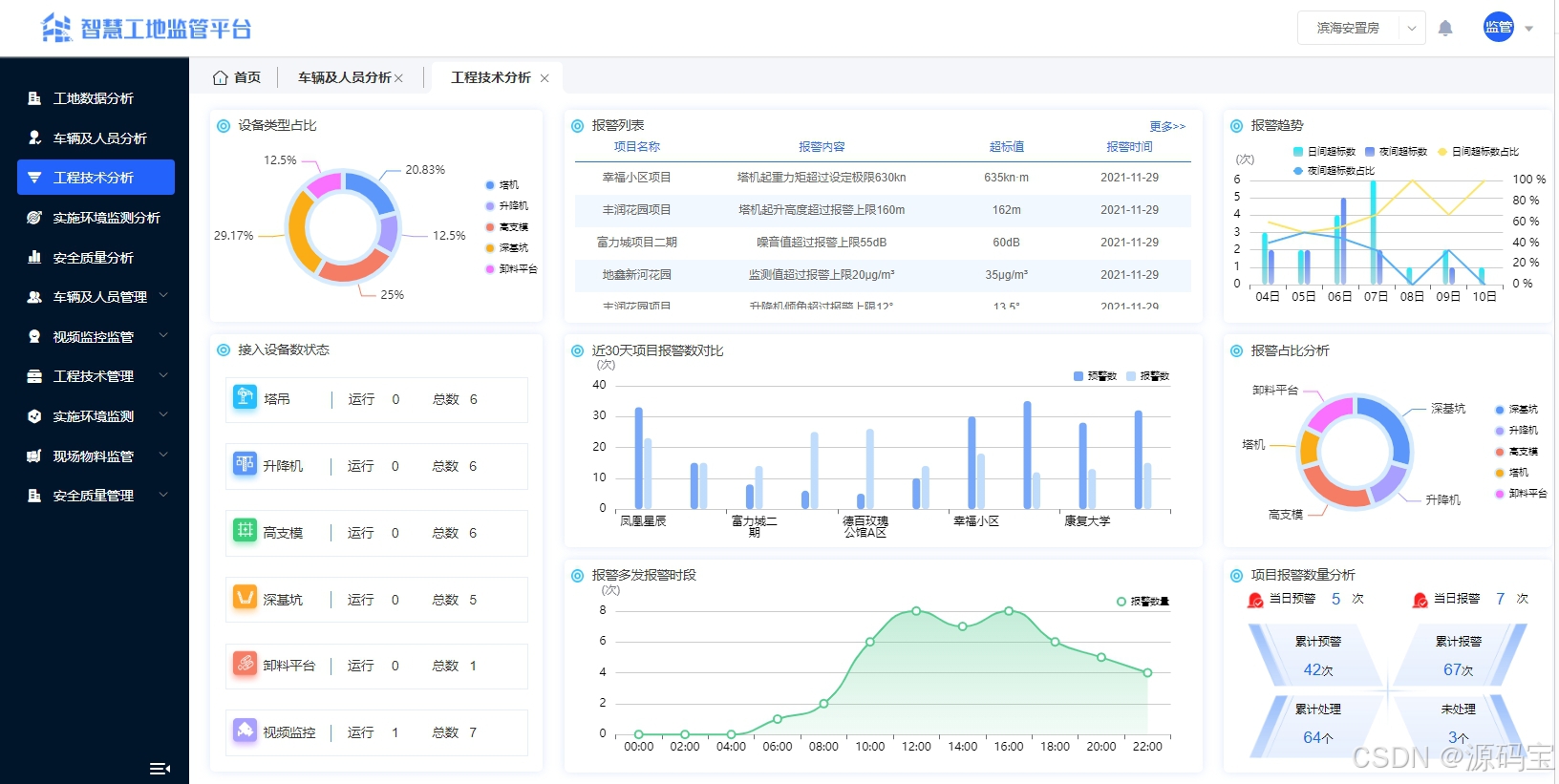
3、表设计
规范化:进行适当的数据库规范化,减少数据冗余,提高数据一致性,但也要注意反规范化以优化查询性能。
索引策略:为频繁查询的字段创建索引,加快查询速度,但过多索引会增加写入成本。
分区和分表:对于大数据量的表,考虑使用分区或分表策略,以优化存储和查询效率。
4、安全性和备份
权限管理:确保只有授权用户可以访问特定数据。
加密敏感数据:如个人信息,应加密存储。
定期备份:制定备份策略,确保数据丢失时能够快速恢复。
5、实时数据处理
流处理:对于环境监测等实时数据,可能需要结合消息队列(如Kafka)和实时处理系统(如Flink)来处理和存储瞬时数据。
缓存策略:使用Redis等缓存系统来存储频繁访问的数据,减少数据库压力。
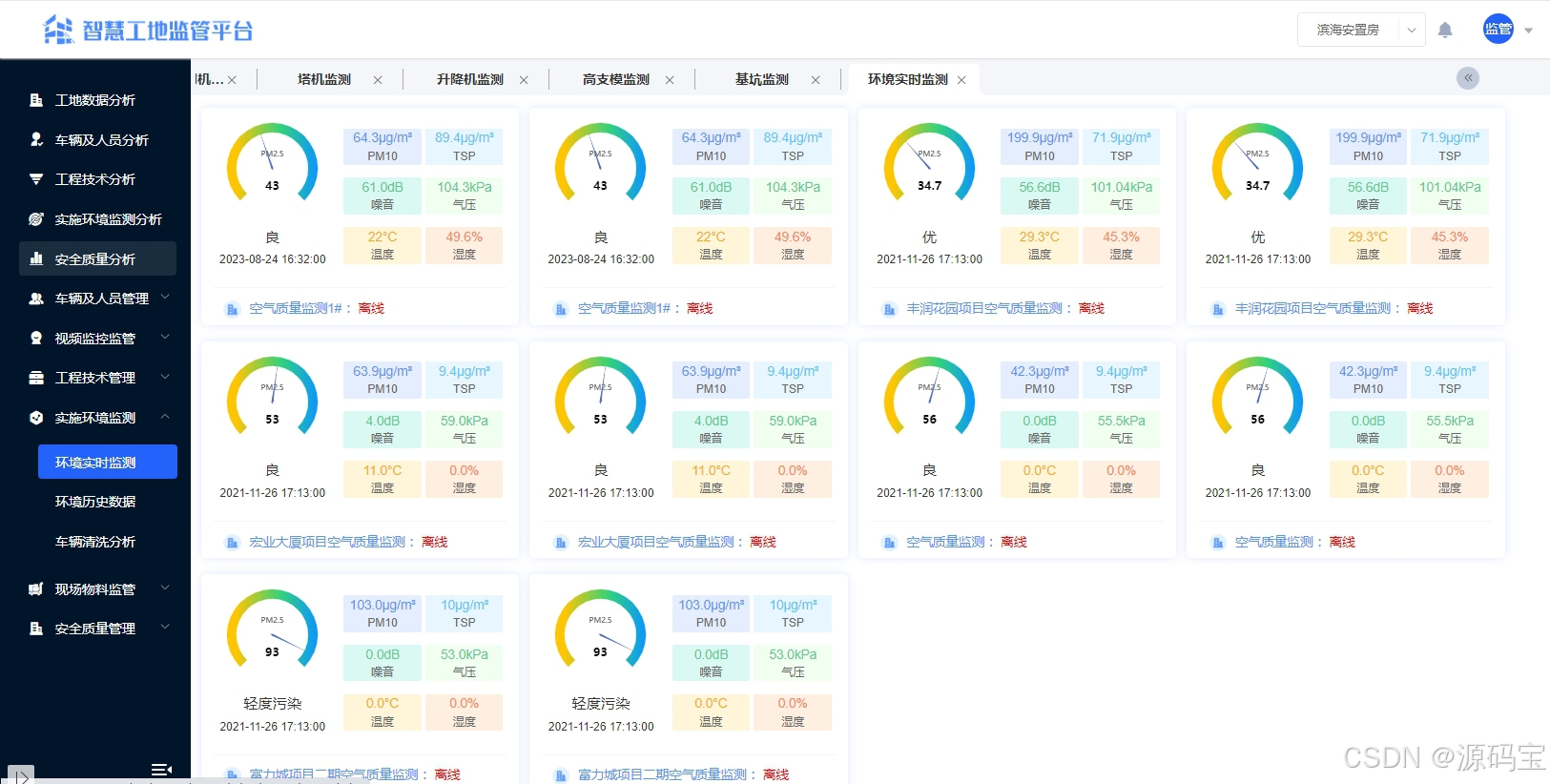
6、数据整合与分析
数据仓库:为了支持数据分析和报告,可以设计一个数据仓库,定期从在线事务处理(OLTP)系统中抽取数据进行汇总和分析。
7、数据一致性
事务处理:确保关键操作的原子性,比如工人考勤记录和工资计算的同步更新。
分布式事务:在微服务架构下,可能需要处理分布式事务,确保跨服务数据的一致性。
设计数据库时,要综合考虑系统的当前需求和未来可能的扩展,保持灵活性和可维护性。同时,随着技术的发展,也应关注新兴的数据库技术和最佳实践,以适应智慧工地系统不断增长的数据处理需求。