【SFT监督微调总结】大模型SFT全解析:从原理到工具链,解锁AI微调的核心密码
文章目录
- 一. 什么是监督微调(SFT)?
- 二. SFT的核心原理与流程
- 2.1 基本原理
- 2.2 训练流程
- 三、SFT训练的常用方法
- 四、SFT训练用的数据格式
- 4.1、基础单轮指令格式
- 1. Alpaca 格式
- 2. 单轮QA格式
- 3. 代码-注释对
- 4.2、多轮对话格式
- 1. ShareGPT 格式
- 2. 层次化对话格式
- 3. 角色扮演对话
- 4.3、跨模态格式
- 1. 图文对齐格式
- 2. 文本-图像配对
- 4.4、专业领域格式
- 1. 法律文书格式
- 4.5、增强训练格式
- 1. 思维链(CoT)格式
- 4.6、混合格式
- 1. 多任务混合格式
- 4.7、长文本与分块格式
- 关键处理技术
- 实践建议
- 五、SFT训练的核心特点
- 六、SFT训练与预训练的区别
- 七、SFT的优势与挑战
- 7.1 优势
- 7.2 挑战
- 八. SFT与其他技术的结合
- 8.1 SFT + 强化学习(RL)
- 8.2 多模态SFT
- 九、大模型SFT(监督微调)工具
- 9.1、框架与库
- 9.2、平台与服务
- 9.3、专用工具
- 9.4、其他工具
一. 什么是监督微调(SFT)?
监督微调(Supervised Fine-Tuning, SFT)是一种在预训练语言模型(LLM)基础上,使用高质量标注数据进一步优化模型以适应特定任务或领域的技术。其核心是通过输入-输出对的标注数据(如指令、问题与答案),调整模型参数,使其在特定场景下生成更符合人类期望的响应。
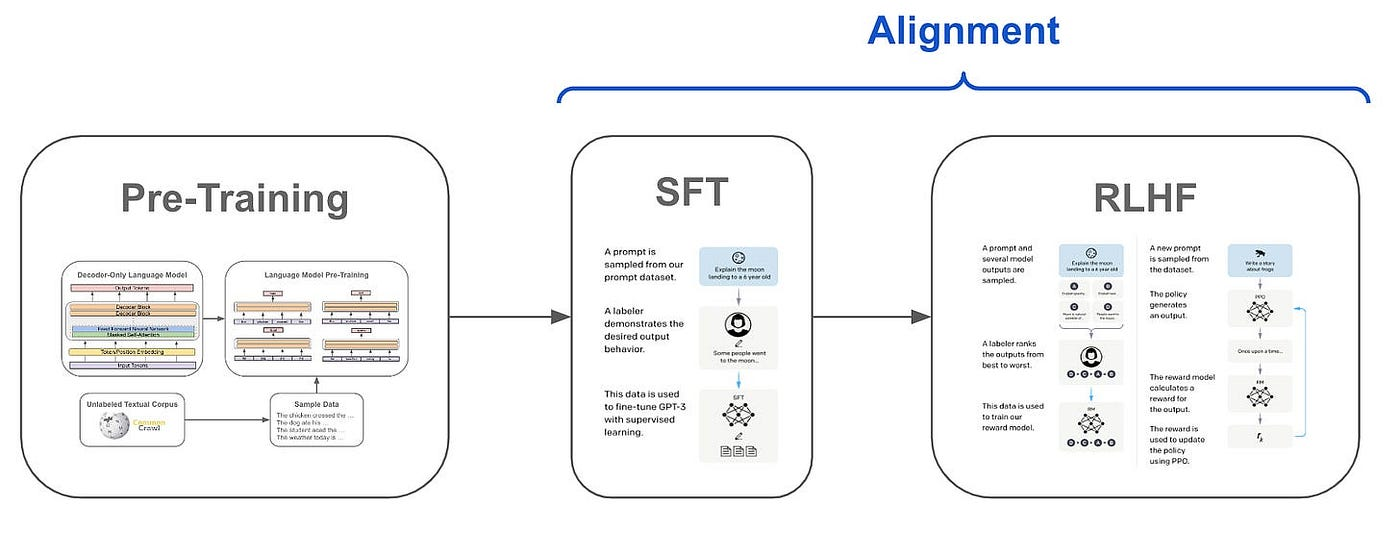
与预训练(PT)的区别:
- 数据需求:PT依赖大规模未标注数据,而SFT需要标注数据(如指令、答案对)。
- 目标:PT旨在学习语言的通用表示,SFT则针对具体任务优化模型性能(如对话生成、数学推理)。
- 训练成本:SFT的计算成本通常远低于预训练。