小土堆pytorch--神经网路-卷积层池化层
神经网路-卷积层&池化层
- 一级目录
- 二级目录
- 三级目录
- 1. 神经网路-卷积层
- 2. 神经网路最大池化的应用
一级目录
二级目录
三级目录
1. 神经网路-卷积层

在PyTorch中,torch.nn.Conv2d函数定义了一个二维卷积层,其常用参数包括:
in_channels:输入图像的通道数,例如RGB图像为3。
out_channels:经过卷积运算后,输出特征映射的数量,即卷积核的数量。
kernel_size:卷积核的大小,可以是一个整数或一个元组指定高度和宽度,例如3或(3, 3)。
stride:卷积核在输入特征图上滑动的步长,控制输出特征图的大小。
padding:在输入特征图的边缘添加的像素数,用于控制输出特征图的大小。
dilation:卷积核元素之间的间距,影响卷积核覆盖的区域大小,也称为空洞卷积。
groups:分组卷积中的组数,可以减少参数数量和计算量。
bias:布尔值,指定是否添加偏置项,默认为True。
padding_mode:指定填充类型,例如’zeros’、‘reflect’等,默认为’zeros’。
其中前五个参数比较常用,后四个一般使用默认值就可以了
这些在我上一个博客中也有所解释

import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter#准备测试集
dataset = torchvision.datasets.CIFAR10("./das", train=False, transform=torchvision.transforms.ToTensor(),download = True)dataloader = DataLoader(dataset, batch_size=64)class Test(nn.Module):def __init__(self):super(Test, self).__init__()self.conv1 = Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)def forward(self, x):x = self.conv1(x)return xtest = Test()
print(test)
writer = SummaryWriter("logs")
step = 0
for data in dataloader:imgs, targets = dataoutput = test(imgs)# print(output.shape)writer.add_images("input",imgs, step)writer.add_images("output", output, step)step = step + 1
如果运行上述代码的话会发现这样的报错
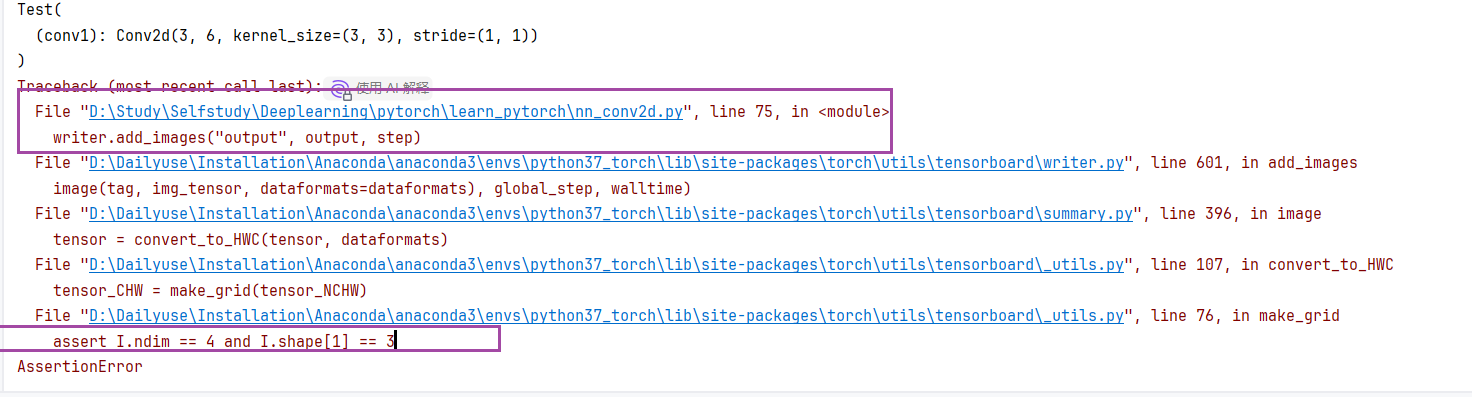
就是通道数不符造成的,因此我们可以使用reshape操作
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter#准备测试集
dataset = torchvision.datasets.CIFAR10("./das", train=False, transform=torchvision.transforms.ToTensor(),download = True)dataloader = DataLoader(dataset, batch_size=64)class Test(nn.Module):def __init__(self):super(Test, self).__init__()self.conv1 = Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)def forward(self, x):x = self.conv1(x)return xtest = Test()
print(test)
writer = SummaryWriter("logs")
step = 0
for data in dataloader:imgs, targets = dataoutput = test(imgs)# print(output.shape)writer.add_images("input",imgs, step)output = torch.reshape(output, (-1,3,30,30)) # 根据错误提示进行修改writer.add_images("output", output, step)step = step + 1
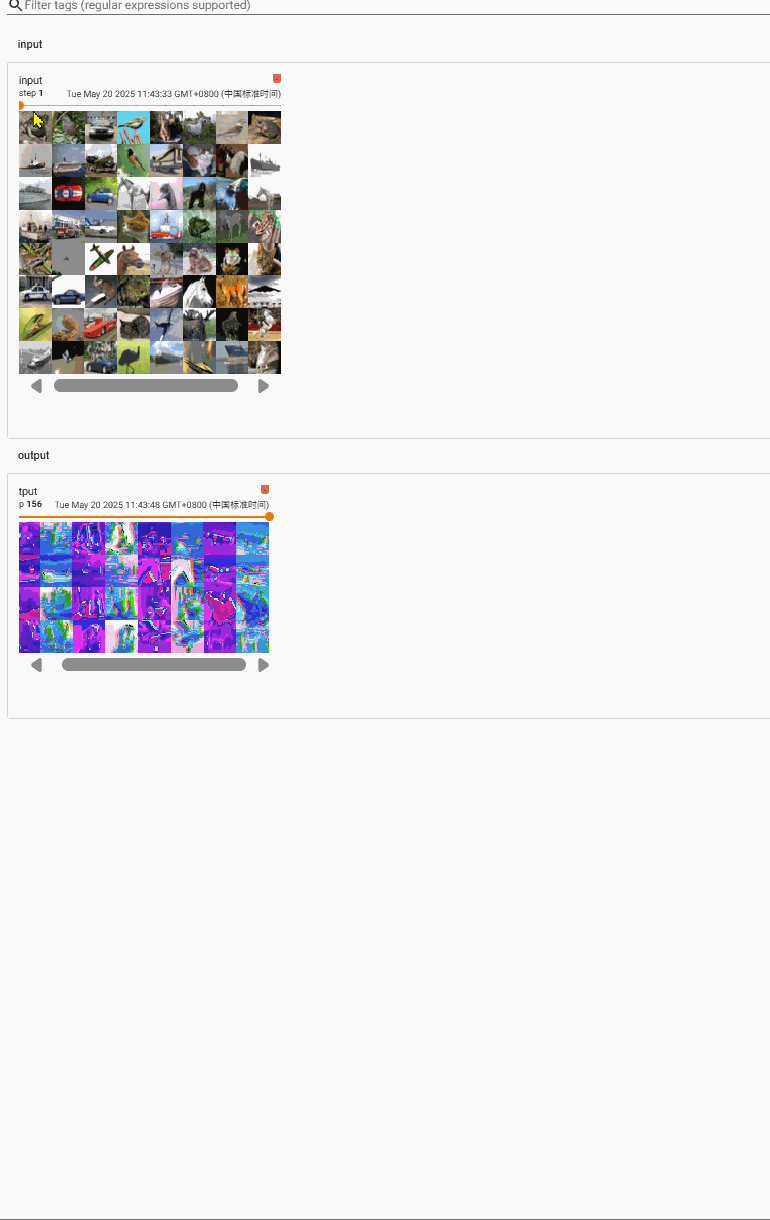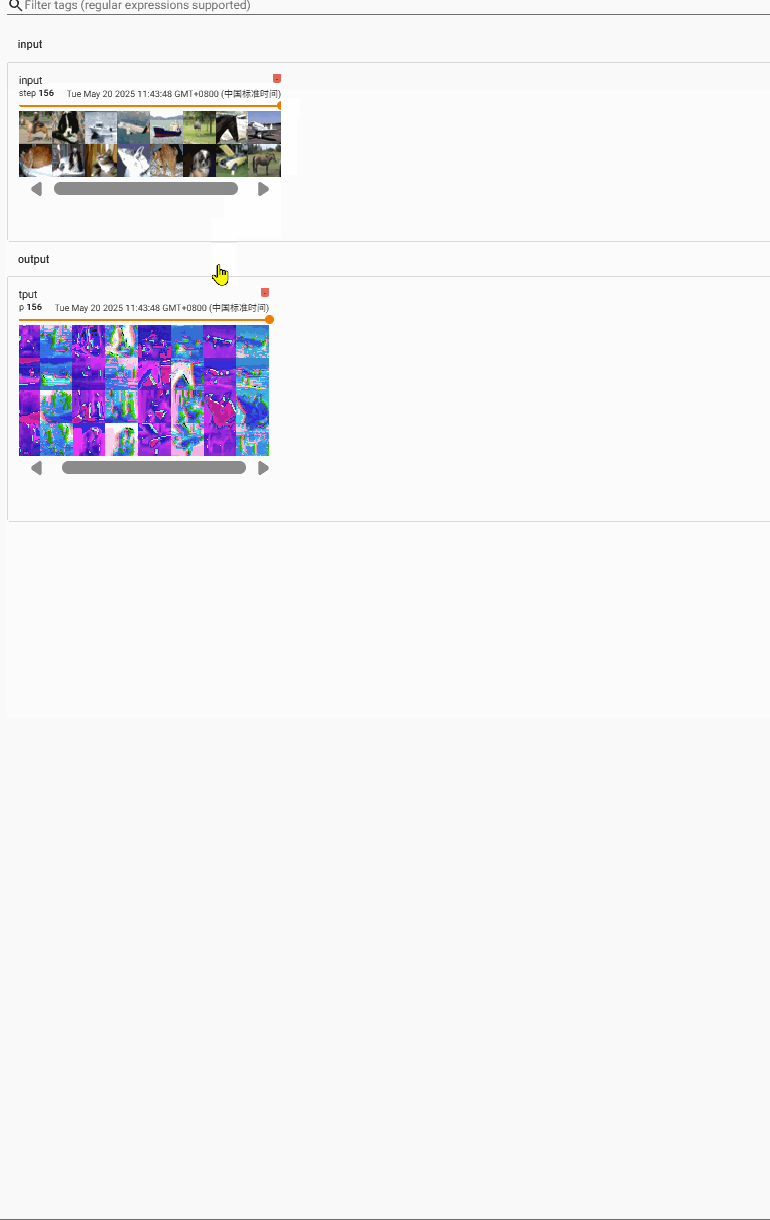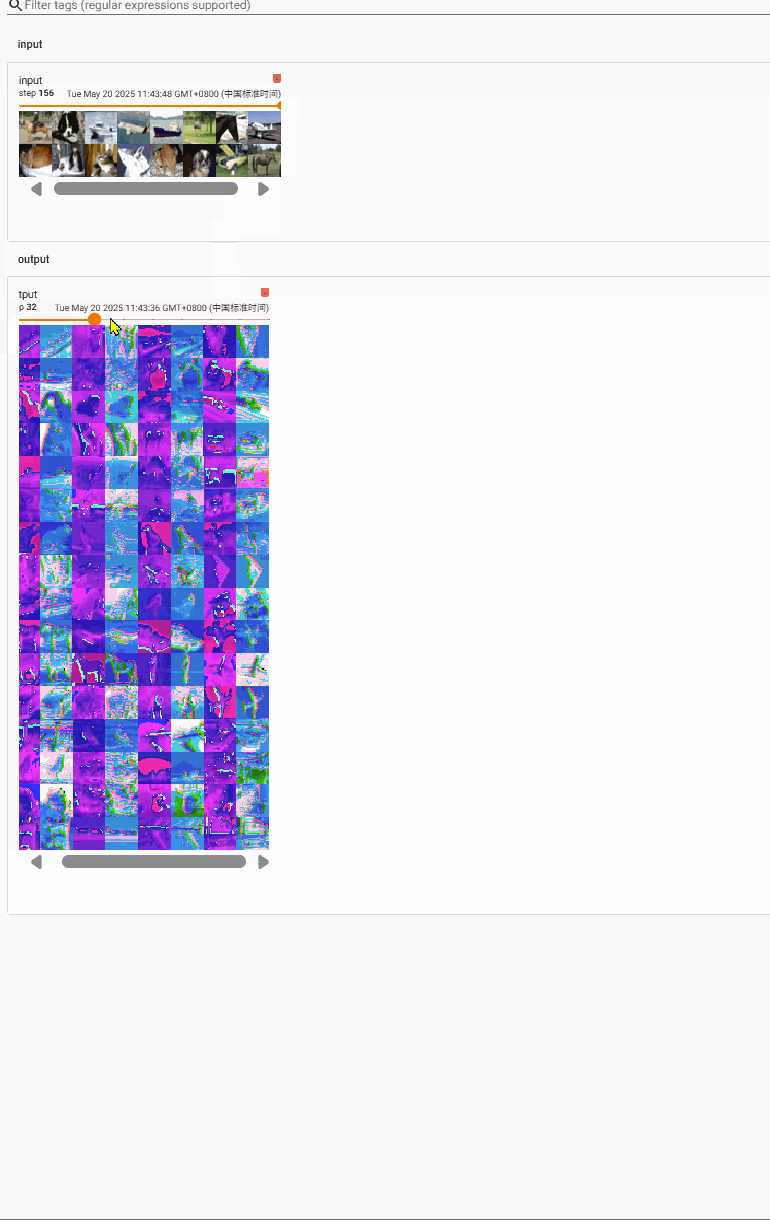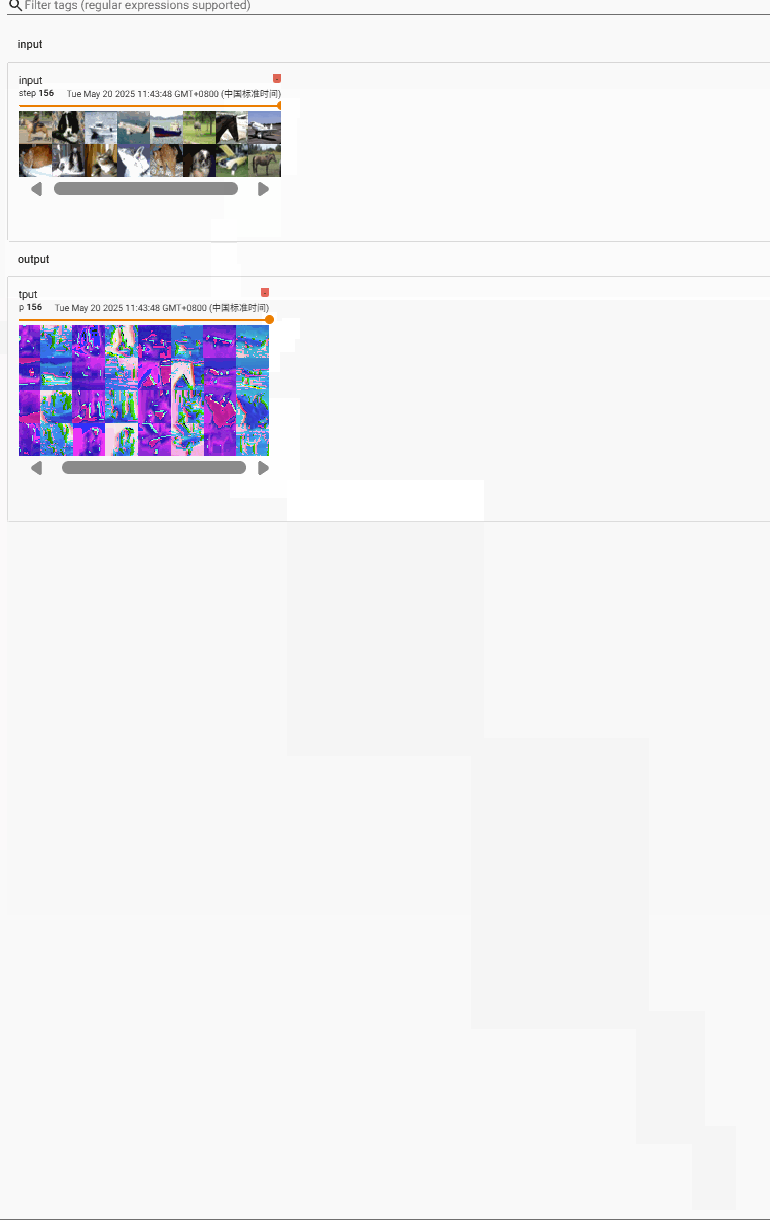
我们来看一下size的变化
input[64,3,32,32]
output[64,6,30,30]–(经过reshape)–>[xxx, 3, 30,30]
我们在pytorch官网上面可以找到input/output的形状的计算方法

input[64,3,32,32]
output[64,6,30,30]
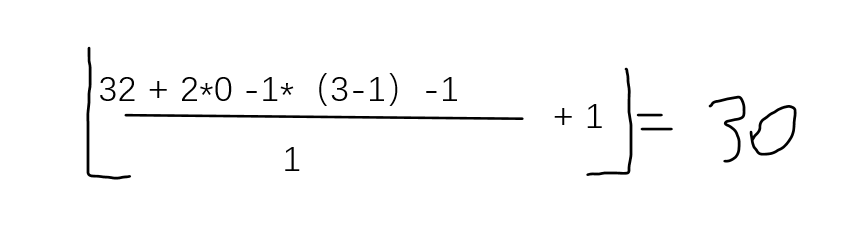
利用上述公式确实得到了output的Hout,Wout为30
2. 神经网路最大池化的应用

在PyTorch中,torch.nn.MaxPool2d是一个二维最大池化层,用于对输入信号进行下采样。以下是该操作的主要参数及其作用:
-
kernel_size:池化窗口的大小,可以是单个整数或两个整数的元组,分别指定高度和宽度。
-
stride:池化窗口滑动的步长,控制输出特征图的大小。可以是单个整数或两个整数的元组,分别对应高度和宽度。默认值为
kernel_size。 -
padding:在输入特征图的边缘添加的零填充的数量,用于控制输出特征图的大小。可以是单个整数或两个整数的元组,分别对应高度和宽度。默认值为0。
-
dilation:控制池化窗口中元素之间的间距,影响池化窗口覆盖的区域大小。可以是单个整数或两个整数的元组,分别对应高度和宽度。默认值为1。
-
return_indices:如果设置为True,则会返回每个最大值的索引,这在后续使用
torch.nn.MaxUnpool2d时非常有用。默认值为False。 -
ceil_mode:当设置为True时,输出形状的计算会使用向上取整而不是向下取整。默认值为False。
这些参数共同决定了池化操作的行为和输出特征图的大小。例如,kernel_size和stride决定了池化窗口的大小和移动步长,而padding和dilation则影响输出特征图的大小和池化窗口的覆盖范围。通过合理设置这些参数,可以在保持重要特征的同时减小数据的空间维度,从而降低计算复杂度。

图片展示了一个5x5的输入图像经过最大池化操作后的结果。使用的池化核大小为3x3,并且kernel_size参数被设置为3。最大池化操作在图像处理中用于降低特征的空间维度,同时保留最重要的特征信息。
图片中还展示了两种不同情况下池化操作的结果,分别是ceil_mode=True和ceil_mode=False(默认值)。当ceil_mode=True时,池化窗口被允许越界,即如果窗口起始于左侧填充或输入区域,则窗口可以超出边界,而起始于右侧填充区域的窗口将被忽略。这会导致输出特征图的尺寸可能与默认情况下不同。
当ceil_mode=False时,输出特征图的大小是向下取整计算得到的。而当ceil_mode=True时,输出特征图的大小是向上取整计算得到的。这种设置对于输出特征图的尺寸有影响,尤其是在输入特征图的尺寸不能被池化窗口整除的情况下。
然后我们可以编写代码验证一下
import torch
from torch import nn
from torch.nn import MaxPool2dinput = torch.tensor([[1,2,0,3,1],[0,1,2,3,1],[1,2,1,0,0],[5,2,3,1,1],[2,1,0,1,1]], dtype = torch.float32)
input = torch.reshape(input, (-1,1,5,5))
print(input.shape)class Test(nn.Module):def __init__(self):super(Test, self).__init__()self.maxpool1 = MaxPool2d(3, ceil_mode=True)def forward(self, input):output = self.maxpool1(input)return outputtest = Test()
output = test(input)
print(output)
运行结果是:

然后我们可以更改ceil_mode
class Test(nn.Module):def __init__(self):super(Test, self).__init__()self.maxpool1 = MaxPool2d(3, ceil_mode=False) # 更改ceil_modedef forward(self, input):output = self.maxpool1(input)return output
运行结果是:

在tensorboard中打开


池化操作不会减少图片数量,但会通过下采样减小图片尺寸,从而降低后续层的计算量和参数数量。