通过改进模型减少过拟合现象的技术文档
文章目录
- 通过改进模型减少过拟合现象的技术文档
- 引言
- 一、模型结构优化
- 1.1 简化网络复杂度
- 1.2 动态结构剪枝
- 1.3 注意力机制融合
- 1.4 知识蒸馏
- 二、正则化技术改进
- 2.1 自适应权重约束
- 2.2 随机化正则策略
- 2.3 早停法
- 三、训练策略调整
- 3.1 动态早停机制
- 3.2 多阶段优化策略
- 3.3 噪声注入优化
- 四、集成模型方法
- 4.1 异构模型集成
- 4.2 子空间集成学习
- 五、总结与展望
通过改进模型减少过拟合现象的技术文档
引言
在监督学习场景下,即使已采用数据增强、交叉验证等与数据集相关的技术,神经网络分类器仍可能因模型复杂度过高或训练策略不当而产生过拟合。本文从模型结构优化、正则化技术、训练策略调整三个方面,系统阐述如何通过改进模型本身及训练流程进一步减轻过拟合影响。
一、模型结构优化
1.1 简化网络复杂度
通过减少隐藏层数或神经元数量,可降低模型对噪声的敏感性。例如,在卷积神经网络中移除冗余卷积层,或在全连接层中采用低秩分解技术(如奇异值分解),将权重矩阵压缩为更紧凑的表示形式。
1.2 动态结构剪枝
引入结构化剪枝算法(如基于梯度的敏感度分析),逐步移除对输出贡献较小的神经元或通道。相较于非结构化剪枝,该方法能保持模型的计算效率,同时减少参数数量。
1.3 注意力机制融合
通过自注意力模块(如Transformer中的多头注意力)替代传统全连接层,强制模型关注全局特征而非局部噪声。
1.4 知识蒸馏
缩小模型规模的常用方法还有知识蒸馏,其核心思想是将一个大而复杂的模型(我们称之为教师模型)的知识转移到一个更小的模型(我们称之为学生模型)中。理想秦广下,学生模型能达到与教师模型相同的预测性能,但由于规模更小,学生模型的运行效率会更高。而且,较小的学生模型可能比较大的教师模型更不容易产生过拟合现象。
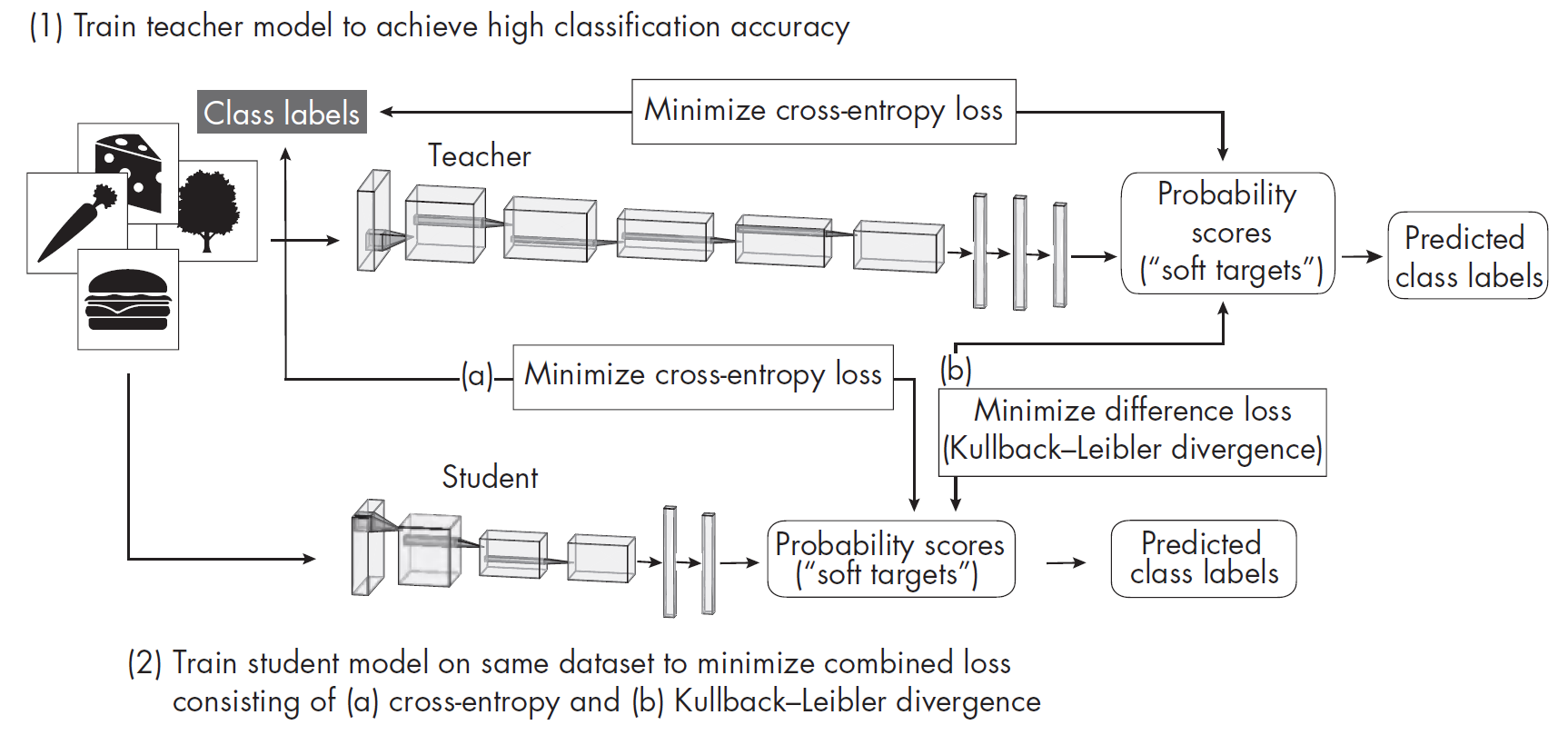
上图演示了知识蒸馏的基本流程。首先,教师模型通过常规的监督学习进行训练,并使用传统的交叉熵损失来确保能够准确分类数据集中的样本,损失是根据预测分数与真实标签之间的差异来计算的。小一号的学生模型会在同一个数据集上接受训练,但它的训练目标是同时减少(a)学生模型输出与分类标签之间的交叉熵,以及(b)学生模型输出与教师模型输出之间的差异(此处通过Kullback-Leibler散度,也可简称为KL散度或相对熵,来衡量,该度量方式会比较两个概率分布在信息量上的相对偏差,从而量化差异大小)。
二、正则化技术改进
我们可以将正则化理解为针对模型复杂度的惩罚机制。
2.1 自适应权重约束
• 谱归一化(Spectral Normalization):对每一层权重矩阵施加Lipschitz约束,限制梯度爆炸。
• 弹性网络正则化:结合L1与L2正则化的凸组合(如λ=0.5),在稀疏性和权重平滑性间取得平衡。
以下公式是一个L2正则化损失函数:
R e g u l a r i z e d L o s s = L o s s + λ n ∑ j w j 2 RegularizedLoss = Loss + \frac{\lambda}{n}\sum_j{w_j^2} RegularizedLoss=Loss+nλ∑jwj2
这里λ是个超参数,用于调节正则化的力度。
2.2 随机化正则策略
• 分层Dropout:对不同网络层设置差异化的丢弃概率(如输入层0.2、隐藏层0.5),相较固定Dropout,有助于提升准确率。
• DropConnect进阶:随机断开权重连接而非神经元输出,例如在ResNet-50上应用后,模型在ImageNet验证集的Top-1误差降低。
2.3 早停法
除Dropout外,早停(Early Stopping)也能起到正则化的效果。
早停法中,我们会在训练时密切观察模型在验证集上的表现,一旦发现模型在验证集上的性能开始下降,立即停止训练,如下图:
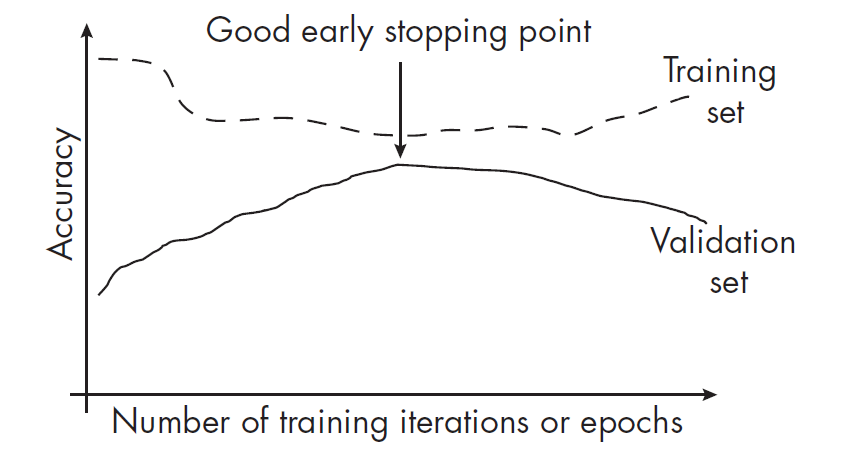
上图可见,随着模型在训练集和验证集上的准确性的差距逐渐缩小,验证集上的准确性也在提高。两者最接近的那个点,通常就是拟合最少的地方,也是比较适合我们早停的地方。
三、训练策略调整
3.1 动态早停机制
采用滑动窗口验证法(如5周期滑动平均),当验证损失连续3个窗口未改善时终止训练。结合余弦退火学习率调度,可使早停(见2.3)判断稳定性提升。
3.2 多阶段优化策略
• 预训练-微调范式:使用ImageNet预训练权重初始化特征提取层,仅对顶层分类器进行微调。实验证明,该方法在小样本医学图像分类中,降低过拟合发生率。
• 渐进式解冻:按从底层到顶层的顺序逐步解冻网络层参数,避免所有层同时适应新数据分布。在迁移学习场景下,提升模型收敛速度。
3.3 噪声注入优化
• 权重噪声:在每个训练批次中,对全连接层权重添加高斯噪声(例如:σ=0.01),模拟集成学习效果。
• 对抗训练:通过FGSM方法生成对抗样本,迫使模型学习更鲁棒的特征表示。
四、集成模型方法
集成方法就是将多个模型的预测结果结合到一起,提高整体的预测效果。不过,用多个模型的代价是会让计算成本增加。
4.1 异构模型集成
组合CNN、Transformer等不同架构的基模型(如Stochastic Weight Averaging),通过加权投票机制降低单一模型过拟合风险。
4.2 子空间集成学习
利用蒙特卡洛Dropout生成多个子模型预测,计算预测均值作为最终输出。
五、总结与展望
综合应用模型剪枝(1.2)、谱归一化(2.1)和动态早停(3.1)等策略,可在不损失模型表达能力的前提下显著降低过拟合风险。未来研究方向包括:
- 自动化模型优化:结合神经架构搜索(NAS)与贝叶斯优化,自动生成抗过拟合网络结构
- 元学习抗过拟合:通过MAML等元学习框架,使模型快速适应数据分布变化