C++中String类
1.String学习前的了解
1.1范围for和auto关键字
范围 for 循环
范围 for 循环是 C++11 引入的一种语法糖,用于简化遍历容器或序列的代码。其基本语法如下:
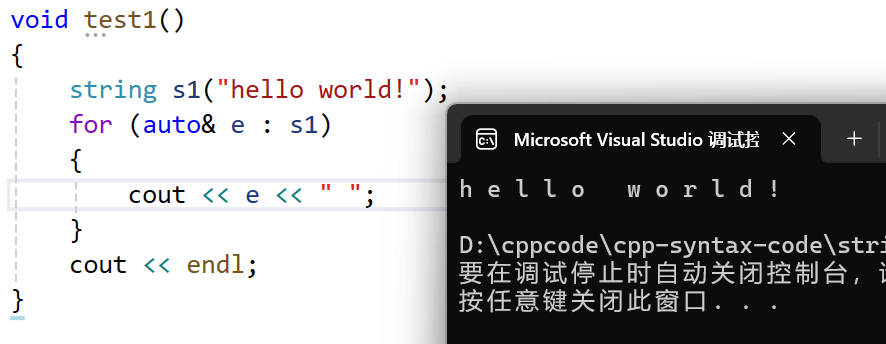


迭代器版本:

- 范围for主要用来遍历一个容器(数据结构).
- 范围for的()中的“auto,char,int,自定义类型string等”都是e的类型,'e'是变量名可以更换为任何其他名。
- ‘:’右边为容器对象。
- 可以理解为e从容器中依次取元素,并且自动迭代(自动++)
原理:
- 范围for的底层实现其实就是编译器无脑替换成迭代器。
- 首先通过
std::begin()和std::end()获取序列的迭代器。 - 然后使用迭代器遍历序列,将每个元素赋值给 e 变量。
auto关键字
auto 是 C++11 引入的类型推导关键字,用于让编译器自动推导变量的类型,而不需要显式指定。
工作原理:
auto 的类型推导基于模板实参推导规则,编译器会根据初始化表达式的类型来推导 auto 的实际类型。
auto x = 42; // x的类型是int
auto y = 3.14; // y的类型是double
auto z = "hello"; // z的类型是const char*与范围 for 循环结合使用:
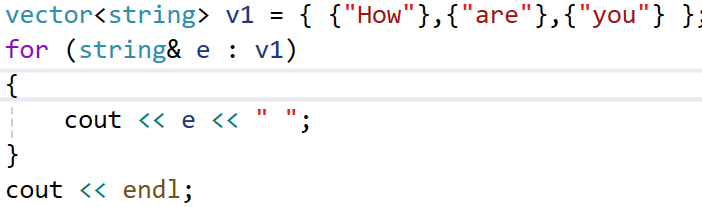
在范围 for 循环中,auto 可以极大简化代码,避免手动指定元素类型:
vector<string> v1 = { {"How"},{"are"},{"you"} };
for (auto& e : v1)
{cout << e << " ";
}
cout << endl;引用和 const 限定:
- 使用
auto&可以获取元素的引用,允许修改元素。 - 使用
const auto&可以避免拷贝,同时防止修改元素。
std::vector<int> nums = {1, 2, 3};// 拷贝元素(不修改原容器)
for (auto num : nums) {num *= 2; // 修改的是副本
}// 引用元素(修改原容器)
for (auto& num : nums) {num *= 2; // 修改原容器中的元素
}// 常量引用(只读访问,避免拷贝)
for (const auto& num : nums) {std::cout << num << " "; // 安全且高效
}总结
- 范围 for 循环通过迭代器简化了序列遍历,提高了代码可读性。
- auto 关键字通过类型推导减少了冗余代码,使代码更加简洁灵活。
- 两者结合使用可以编写出更现代、更高效的 C++ 代码。
2.string接口(使用前包含string头文件)
2.1默认成员函数
构造函数:

(1)默认构造函数
string s1;
cout << "Length of s1: " << s1.length() << endl;(2)拷贝构造
string s2 = "hello world!";string s3(s2);cout << s3 << endl;(3)从原字符串指定位置开始拷贝指定长度
string s2 = "hello world!";string s3(s2, 0, 5);cout << s3 << endl;如果不显示传第二个参数,会把从传入的下标位置到结束拷贝到目标对象:

本质与类型
npos本质是size_t类型,size_t是一种无符号整型,在不同系统架构下可能对应不同的底层类型(如 32 位系统下可能是unsigned int ,64 位系统下可能是unsigned long ),用于表示内存中对象的大小、数组索引等,而npos表示size_t能表示的最大值 ,其定义通常类似static const size_t npos = static_cast<size_t>(-1); ,由于size_t是无符号类型,-1经转换后就是其最大值。
string s2 = "hello world!";string s3(s2, 0);cout << s3 << endl;//输出hello world!(4)使用const char*类型构造
const char* str = "hello world!";string s4(str);cout << s4 << endl;//输出hello world!(5)从 C 风格字符串的前 n 个字符构造
const char* str = "hello world!";string s4(str,5);cout << s4 << endl;//输出hello(6)用指定字符填充指定长度
string s5(10, '*');cout << s5 << endl;//输出**********(7)从输入迭代器范围构造
vector<char> v;v.push_back('a');v.push_back('b');v.push_back('c');v.push_back('d');string s6(v.begin(), v.end());cout << s6 << endl;//输出abcd(8)从初始化列表构造
#include <iostream>
#include <string>
int main() {std::string str = {"g", "o", "o", "d"}; // 从初始化列表构造std::cout << "String: " << str << std::endl; return 0;
}(9)移动构造函数
std::string source = "move me";std::string target(std::move(source)); // 使用移动构造函数std::cout << "Target: " << target << std::endl;//输出move mestd::cout << "Source: " << source << std::endl;//输出""- 把source中的数据移动到target中
- source就变为了空字符串
赋值重载:

(1)拷贝赋值
string s1("hello world!");string s2("how are you");s1 = s2;cout << s1 << endl;//输出how are you(2)从 C 风格字符串赋值
const char* str = { "hello world!" };string s3("how are you");s3 = str;cout << s3 << endl;(3)使用单个字符赋值
string s4("hello world!");s4 = '!';cout << s4 << endl;//输出!(4)使用初始化列表赋值
string s5("hello world!");s4 = { "how are you" };cout << s4 << endl;//输出how are you(5)移动赋值
#include <iostream>
#include <string>int main() {std::string source = "move me";std::string target;target = std::move(source); // 使用移动赋值运算符std::cout << "Target: " << target << std::endl;std::cout << "Source: " << source << std::endl; return 0;
}2.2迭代器介绍
begin():
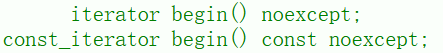
- 在string中的迭代器是一个类,并非原生指针,说成指针只是能够更好的理解
- begin()返回其实位置的指针,可以通过解引用对字符串第一个元素进行访问或修改。
- const_iterator只能访问不能修改
string s1("hello world!");string::iterator it = s1.begin();while (it != s1.end()){(*it)++;it++;}cout << s1 << endl;//输出ifmmp!xpsme" const string s2("hello world!");string::const_iterator it1 = s2.begin();while (it1 != s2.end()){cout << *it1 << " ";it1++;}cout << endl;//输出h e l l o w o r l d !end():
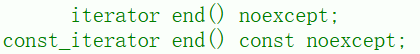
- 返回字符串最后一个字符的下一个位置的指针
rbegin():

- 反向迭代器,返回最后一个字符位置的指针
string s3("hello world!");auto it2 = s3.rbegin();while (it2 != s3.rend()){cout << *it2 << " ";it2++;}cout << endl;//输出! d l r o w o l l e hrend():

- 返回第一个字符位置的指针
cbegin(),cend(),crbegin(),crend():

- 这些接口都是在原接口的基础上加上const
- 只是c++11为了能够更好的区分新添加的接口,但是人们都习惯使用原接口。
2.3容量接口
size():
![]()
- 返回字符串中字符的个数。
string s1("hello world!");cout << s1.size() << endl;//12length():
- length返回的也是字符串中字符的个数。
- string出现的比stl早,length是被先实现出来的,但是stl中表示容器中数据的个数都使用size()接口,所以string也就实现了size()接口。
max_size:
在std::string中,max_size()接口的作用是返回字符串对象在当前系统或库实现限制下,能够保存的最大字符数量 。
这是一个受系统资源(如可用内存、编译器及标准库实现等因素)约束的值 。例如在常见的 32 位系统中,std::string::max_size()返回值通常接近2^32 ,因为std::string内部用于记录大小等信息的类型(如size_t )常基于 32 位无符号整型实现 ,但实际值可能因具体实现有所不同 。
实际上这个接口在实际项目中使用的很少,不需要着重记,使用时查一下档案即可。
resize():

1. resize(size_type n)
- 作用:将字符串的长度调整为
n个字符。- 若
n小于当前长度,字符串会被截断至前n个字符。 - 若
n大于当前长度,新增字符默认用空字符'\0'填充。
- 若
s1.resize(15);cout << s1.size() << endl;//15,'0'不可见2. resize(size_type n, char c)
- 作用:将字符串的长度调整为
n个字符,新增字符用指定字符c填充。- 若
n小于当前长度,行为与第一种重载相同(截断)。 - 若
n大于当前长度,新增字符用c填充。
- 若
s1.resize(15, '#');cout << s1 << endl;//hello world!###注意事项
str.resize(10); // 调整长度为10
str.shrink_to_fit(); // 释放多余容量,使 capacity() 等于 length()-
性能开销:
- 若
n大于当前容量(capacity()),resize()会触发内存重新分配,可能导致性能开销。 - 若
n小于当前容量,不会释放内存,仅调整字符串长度。
- 若
-
填充字符的影响:
- 使用默认填充(
'\0')时,字符串可能包含不可见字符,打印时会提前终止(因为'\0'是 C 风格字符串的终止符)。
- 使用默认填充(
-
容量与长度:
resize()只改变字符串的长度(length()),不直接影响容量(capacity())。- 若需优化内存,可在
resize()后调用shrink_to_fit()释放多余容量。
预分配空间
在已知字符串最终大小时,提前调用resize()避免多次内存重新分配。
std::string data;
data.resize(1000); // 预分配1000个字符的空间截断字符串
std::string message = "Hello, world!";
message.resize(5); // 截断为 "Hello"capacity()
返回容器的容量
reserve()
![]()
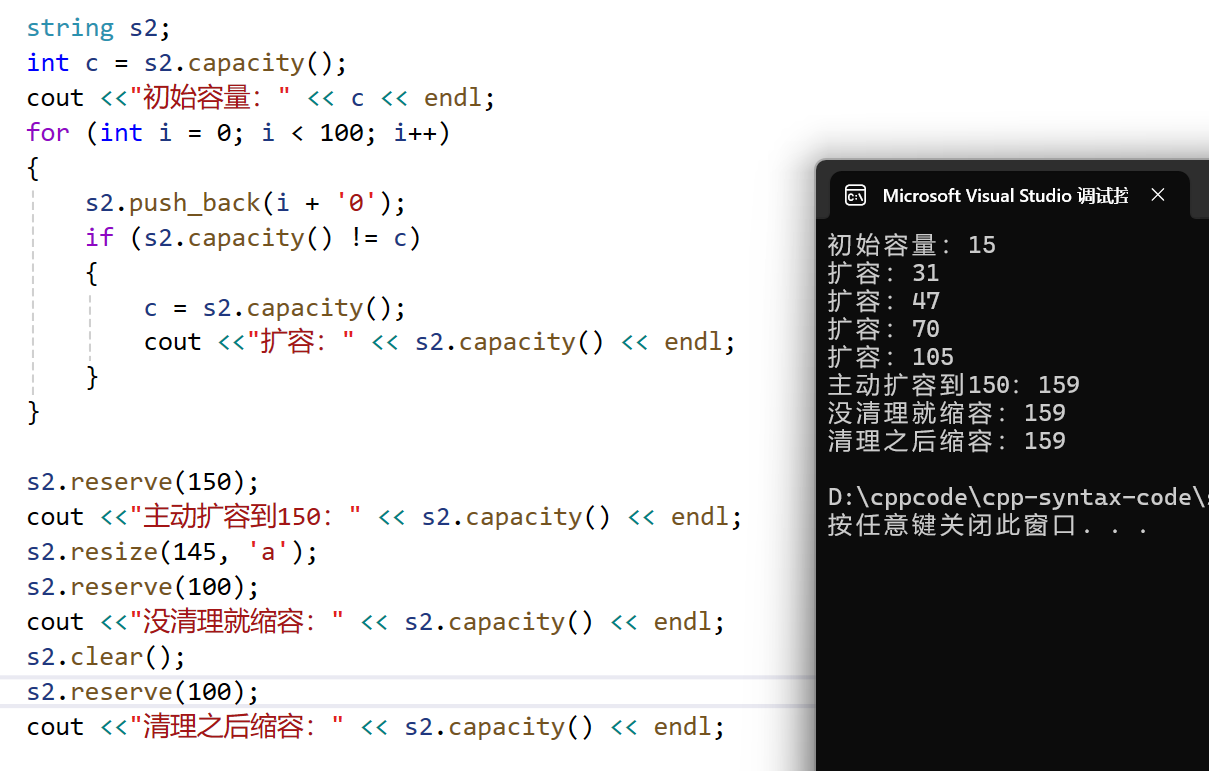
在 C++ 里,std::string 的 reserve() 是一个很实用的成员函数,其功能是预先分配内存,以此避免字符串在后续操作时反复进行内存重新分配,从而提升性能。
- reserve会把容量扩容到输入的“n”
- 扩容规则:
- 由上图可知:在vs中string的初始容量为15(实际上是16,因为'\0'占了一个容量)
- 第一次扩容为2倍扩容
- 其余各次扩容为1.5倍扩容
- 当输入的n>capacity时reserve会扩容到n
- 当输入的n<capacity时,即使对容器清理后也不会缩容,缩容的代价比较大,在当今的机器上空间并没有时间更值,所以尽量要以空间换时间。
string s2;int c = s2.capacity();cout <<"初始容量:" << c << endl;for (int i = 0; i < 100; i++){s2.push_back(i + '0');if (s2.capacity() != c){c = s2.capacity();cout <<"扩容:" << s2.capacity() << endl;}}s2.reserve(150);cout <<"主动扩容到150:" << s2.capacity() << endl;s2.resize(145, 'a');s2.reserve(100);cout <<"没清理就缩容:" << s2.capacity() << endl;s2.clear();s2.reserve(100);cout <<"清理之后缩容:" << s2.capacity() << endl;clear()

清除容器中的数据。
empty()

判断容器是否为空
shrink_to_fit

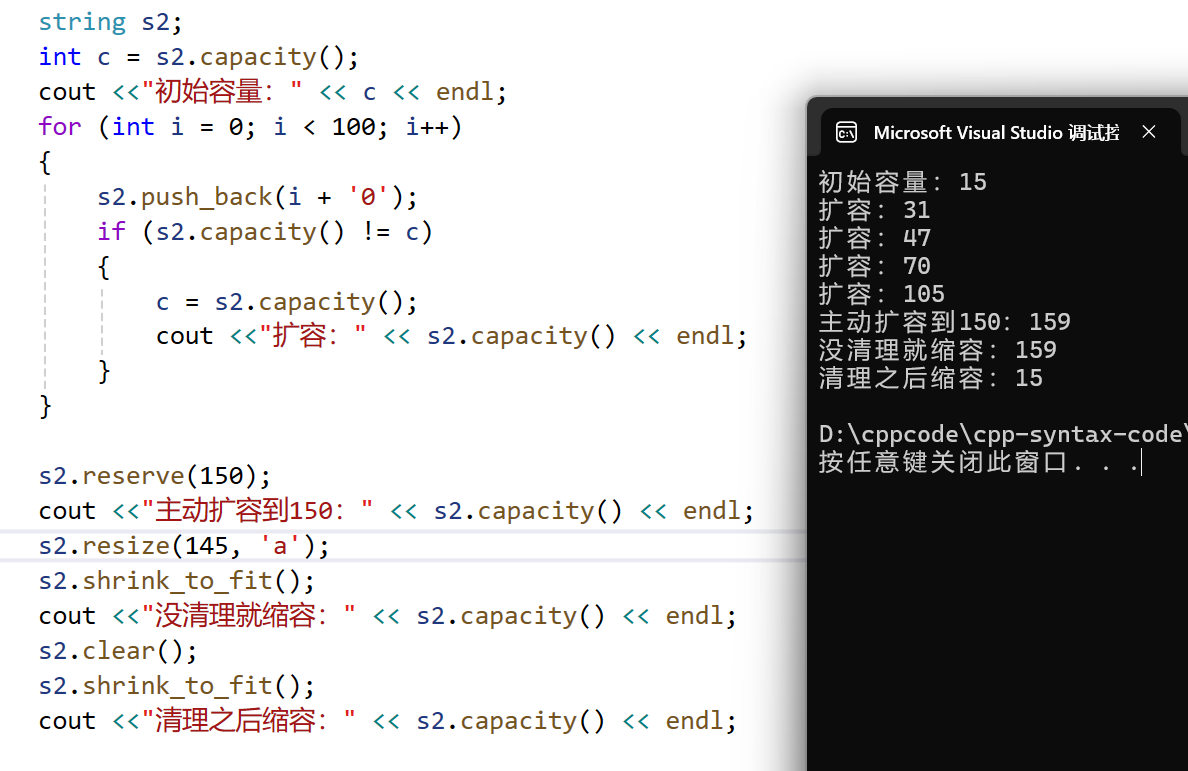

- 该接口是对容器缩容
- 由上可知:
- 当数据个数与实际容量相距较小时,编译器不会缩容
- 当数据个数与实际个数相距较大时,会缩容
- 清理数据后,会缩容,但并不会缩容到0
2.4元素的存取
重载[]

string s1("hello world");
for (int i = 0; i < s1.size(); i++)
{s1[i]++;cout << s1[i] << " ";
}
cout << endl;//输出i f m m p ! x p s m econst string s2("hello world");
for (int i = 0; i < s2.size(); i++)
{cout << s2[i] << " ";
}
cout << endl;//h e l l o w o r l d- 该重载[]检查越界是使用了assert()
- 而c语言的[]只在容器的前后一小段内存空间设置了检查点,如果直接越很大一部分去访问,并不会报错。
at

string s1("hello world");for (int i = 0; i < s1.size(); i++){s1.at(i)++;cout << s1.at(i) << " ";}cout << endl;//输出i f m m p ! x p s m econst string s2("hello world");for (int i = 0; i < s2.size(); i++){cout << s2.at(i) << " ";}cout << endl;//h e l l o w o r l d- at的使用和[]类似,都可以读写
back&front


string s3("hello world");cout << s3.front() << endl;//hcout << s3.back() << endl;//ds3.front()++;s3.back()++;cout << s3 << endl;//iello worle- front返回第一个字符,back返回最后一个字符
2.5容器数据的增删
重载+=
string s1("hello");string s2(" world");s1 += s2;cout << s1 << endl;//hello worldconst char* arr = { " how" };s1 += arr;cout << s1 << endl;//hello world hows1 += ' ';s1 += 'a';cout << s1 << endl;//hello world how as1 += {"re you"};cout << s1 << endl;//hello world how are you- +=一个sring类型的对象
- +=一个const char*的常量字符串
- +=一个字符
- +=一个初始化列表
append

//(1)将一个string对象追加到目标字符串后面string s1("hello");string s2(" world");s1.append(s2);cout << s1 << endl;//(2)从给定 std::string 对象的指定位置 subpos 开始// ,取长度为 sublen 的子串追加到当前字符串后面。//如果未指定 sublen ,则追加从 subpos 开始到末尾的子串。string s3("hello world");string s4("hello");s4.append(s3, 6, 6);cout << s4 << endl;s4.append(s3, 0);cout << s4 << endl;//(3)在目标字符串结尾追加const char*字符串const char* str = " world";string s5("hello");s5.append(str);cout << s5 << endl;//(4)是追加const char*的前n个字符//(5)追加n个字符cstring s6("hello world");s6.append(3, '!');cout << s6 << endl;//(6)追加迭代器范围内的元素string s7("hello");vector<char> v = { ' ', 'w', 'o', 'r', 'l', 'd' };s7.append(v.begin(), v.end());cout << s7 << endl;//(7)追加初始化列表string s8 = "Hello";s8.append({ ' ', 'W', 'o', 'r', 'l', 'd' });cout << s8 << endl;push_back
![]()
尾插一个字符。
assign

//(1)把一个string对象复制并赋值给目标string s1 = "hello world";string s2 = "how are you";s1.assign(s2);cout << s1 << endl;cout << s2 << endl;//(2)从给定 std::string 对象的指定位置 subpos 开始// ,取长度为 sublen 的子串赋值给当前字符串。// 如果未指定 sublen ,则取从 subpos 开始到末尾的子串。//(3)将以空字符结尾的 C 风格字符串(const char*)赋值给当前字符串。//(4)将 C 风格字符串 s 的前 n 个字符赋值给当前字符串。//(5)将n个字符c赋值给当前字符串//(6)将迭代器范围内的元素赋值给当前字符串//(7)使用初始化列表赋值//(8)将一个右值引用的 std::string 对象的内容移动赋值给当前字符串,原对象变为有效但未指定状态。string str1 = "Source";string str2 = move(str1);cout << "str2: " << str2 << endl;//str2: Sourcecout << "str1: " << str1 << endl;//str1:相比于使用assign赋值,人们更喜欢使用重载‘=’,更方便。
insert

1.常用:在指定下标位置插入一个string对象
string s1("how you");string s2(" are");s1.insert(3, s2);cout << s1 << endl;//how are you2.从给定 std::string 对象 str 的指定位置 subpos 开始,取长度为 sublen 的子串,插入到当前字符串的 pos 位置处。如果未指定 sublen ,则插入从 subpos 开始到末尾的子串。
3.常用:在当前字符串的指定位置 pos 处插入一个以空字符结尾的 C 风格字符串 s 。
string s3("how you");const char* str = " are";s3.insert(3, str);cout << s3 << endl;//how are you4.在当前字符串的指定位置 pos 处插入 C 风格字符串 s 的前 n 个字符。
5.在当前字符串的指定位置 pos 处插入 n 个字符 c 。
string s4("hello world");s4.insert(5, 1, '!');cout << s4 << endl;//hello! world6.在迭代器 p 指向的位置前插入单个字符 c 。
7.在迭代器 p 指向的位置前插入由迭代器 first 到 last 范围内的元素。
8.在迭代器 p 指向的位置前插入初始化列表 il 中的字符。
erase

-
从当前字符串的指定位置
pos开始,删除长度为len的子串。如果未指定len,则删除从pos开始到字符串末尾的内容。 -
删除迭代器
p指向的单个字符,并返回一个指向被删除字符之后元素的迭代器。 -
删除迭代器
first到last范围内的字符(不包括last指向的字符),并返回一个指向被删除字符之后元素的迭代器。
replace
(1)从当前字符串的位置 pos 开始,删除长度为 len 的子串,然后插入字符串 str 。
#include <iostream>
#include <string>int main() {std::string str = "HelloWorld";str.replace(5, 5, "Beautiful");std::cout << str << std::endl; return 0;
}(1)删除迭代器 i1 到 i2 (不包含 i2 )范围内的字符,然后插入字符串 str 。
#include <iostream>
#include <string>int main() {std::string str = "HelloWorld";auto i1 = str.begin() + 2;auto i2 = str.begin() + 5;str.replace(i1, i2, "XYZ");std::cout << str << std::endl; return 0;
}(2)从当前字符串的位置 pos 开始,删除长度为 len 的子串,然后从字符串 str 的 subpos 位置开始,取长度为 sublen (若未指定 sublen 则取到末尾 )的子串插入。
(3)从当前字符串的位置 pos 开始,删除长度为 len 的子串,然后插入 C 风格字符串 s 。
#include <iostream>
#include <string>int main() {std::string str = "HiThere";const char* toInsert = "Everyone";str.replace(2, 5, toInsert);std::cout << str << std::endl; return 0;
}(3)删除迭代器 i1 到 i2 (不包含 i2 )范围内的字符,然后插入 C 风格字符串 s 。
#include <iostream>
#include <string>int main() {std::string str = "HiThere";const char* toInsert = "All";auto i1 = str.begin() + 1;auto i2 = str.begin() + 3;str.replace(i1, i2, toInsert);std::cout << str << std::endl; return 0;
}(4)从当前字符串的位置 pos 开始,删除长度为 len 的子串,然后插入 C 风格字符串 s 的前 n 个字符。
(4)删除迭代器 i1 到 i2 (不包含 i2 )范围内的字符,然后插入 C 风格字符串 s 的前 n 个字符。
(5)从当前字符串的位置 pos 开始,删除长度为 len 的子串,然后插入 n 个字符 c 。
#include <iostream>
#include <string>int main() {std::string str = "Test";str.replace(1, 1, 3, '*'); std::cout << str << std::endl; return 0;
}(5)删除迭代器 i1 到 i2 (不包含 i2 )范围内的字符,然后插入 n 个字符 c 。
#include <iostream>
#include <string>int main() {std::string str = "Test";auto i1 = str.begin() + 1;auto i2 = str.begin() + 2;str.replace(i1, i2, 2, '#'); std::cout << str << std::endl; return 0;
}(6)删除迭代器 i1 到 i2 (不包含 i2 )范围内的字符,然后插入由迭代器 first 到 last 范围内的元素
#include <iostream>
#include <string>
#include <vector>int main() {std::string str = "Read";std::vector<char> vec = {'A', 'B', 'C'};auto i1 = str.begin() + 1;auto i2 = str.begin() + 2;str.replace(i1, i2, vec.begin(), vec.end());std::cout << str << std::endl; return 0;
}(7)删除迭代器 i1 到 i2 (不包含 i2 )范围内的字符,然后插入初始化列表 il 中的字符。
#include <iostream>
#include <string>int main() {std::string str = "Car";auto i1 = str.begin() + 1;auto i2 = str.begin() + 2;str.replace(i1, i2, {'X', 'Y'});std::cout << str << std::endl; return 0;
}pop_back
尾删
2.6字符串操作
c_str/data
![]()

返回对象第一个字符的指针
copy

std::string 的 copy 成员函数用于将当前字符串的部分内容复制到指定的字符数组中。
#include <iostream>
#include <string>int main() {std::string str = "Hello, World!";char buffer[20];// 从字符串str的第7个位置开始,最多复制5个字符到buffer中size_t numCopied = str.copy(buffer, 5, 7); buffer[numCopied] = '\0'; // 手动添加字符串结束符std::cout << buffer << std::endl; return 0;
}find/rfind

(1)从当前字符串的 pos 位置开始查找子字符串 str ,返回首次找到的起始位置;若未找到,返回 std::string::npos 。
#include <iostream>
#include <string>int main() {std::string str = "HelloWorld";std::string subStr = "World";size_t pos = str.find(subStr);if (pos != std::string::npos) {std::cout << "子串首次出现位置: " << pos << std::endl;} else {std::cout << "未找到子串" << std::endl;}return 0;
}(2)从当前字符串的 pos 位置开始查找 C 风格字符串 s ,返回首次找到的起始位置;若未找到,返回 std::string::npos 。
string s1("hello world");const char* str = "world";cout << s1.find(str) << endl;(3)从当前字符串的 pos 位置开始,查找 C 风格字符串 s 的前 n 个字符组成的子串,返回首次找到的起始位置;若未找到,返回 std::string::npos 。
#include <iostream>
#include <string>int main() {std::string str = "HelloWorld";const char* cStr = "Worl";size_t pos = str.find(cStr, 0, 4);if (pos != std::string::npos) {std::cout << "指定长度的C风格字符串首次出现位置: " << pos << std::endl;} else {std::cout << "未找到指定长度的C风格字符串" << std::endl;}return 0;
}(4)从当前字符串的 pos 位置开始查找字符 c ,返回首次找到的位置;若未找到,返回 std::string::npos 。
#include <iostream>
#include <string>int main() {std::string str = "HelloWorld";char ch = 'l';size_t pos = str.find(ch);if (pos != std::string::npos) {std::cout << "字符首次出现位置: " << pos << std::endl;} else {std::cout << "未找到字符" << std::endl;}return 0;
}rfind和find使用方法一样,不过是从后往前找
find_first_of/find_last_of

(1)从指定位置 pos 开始查找目标字符串 str 中任意字符首次出现的位置。
string s2("hello world how are you");string s3("aeiou");size_t pos = 0;while (pos!=string::npos){pos = s2.find_first_of(s3);if (pos != string::npos)s2[pos] = '*';elsebreak;}cout << s2 << endl;(2)从指定位置 pos 开始查找目标字符串,返回常量字符串中任意字符首次出现的位置。
(3)从pos位置开始查找,找与字符串s前n个字符对应的字符返回其下标
(4)从pos位置开始找字符c,返回第一个找到的位置

- 与find_first_of一样,但从后往前找
- 这两个接口如果没找到都返回npos
find_first_not_of/find_last_not_of


- 与find_first_of/find_last_of逻辑一样,但是找与s字符串中所含字符不同的字符,返回其下标
- find_last_not_of就是从后往前找不同的
substr
![]()
从调用该函数的std::string对象中提取子串。
- pos为调用该函数的对象的下标,提取子串的起始位置
- len为从pos位置提取长度为len子字符串
域名解析IRL
#include <iostream>
#include <string>
#include <vector>struct ParsedURL {std::string protocol;std::string subdomain;std::string domain;std::string tld;std::string port;std::string path;
};ParsedURL parseDomain(const std::string& url) {ParsedURL result;size_t pos = 0;// 解析协议size_t protocolPos = url.find("://");if (protocolPos != std::string::npos) {result.protocol = url.substr(0, protocolPos);pos = protocolPos + 3;}// 解析域名和端口size_t hostEnd = url.find_first_of("/:?", pos);std::string host = (hostEnd != std::string::npos) ? url.substr(pos, hostEnd - pos) : url.substr(pos);// 解析端口size_t portPos = host.find(':');if (portPos != std::string::npos) {result.port = host.substr(portPos + 1);host = host.substr(0, portPos);}// 解析子域名、主域名和TLDstd::vector<std::string> parts;size_t start = 0;size_t dotPos;while ((dotPos = host.find('.', start)) != std::string::npos) {parts.push_back(host.substr(start, dotPos - start));start = dotPos + 1;}parts.push_back(host.substr(start));int partsCount = parts.size();if (partsCount >= 2) {result.tld = parts[partsCount - 1];result.domain = parts[partsCount - 2];if (partsCount > 2) {for (int i = 0; i < partsCount - 2; ++i) {if (!result.subdomain.empty()) result.subdomain += ".";result.subdomain += parts[i];}}}// 解析路径if (hostEnd != std::string::npos) {result.path = url.substr(hostEnd);}return result;
}int main() {std::string url = "https://www.example.co.uk:8080/path/to/resource?query=param";ParsedURL parsed = parseDomain(url);std::cout << "Protocol: " << parsed.protocol << std::endl;std::cout << "Subdomain: " << parsed.subdomain << std::endl;std::cout << "Domain: " << parsed.domain << std::endl;std::cout << "TLD: " << parsed.tld << std::endl;std::cout << "Port: " << parsed.port << std::endl;std::cout << "Path: " << parsed.path << std::endl;return 0;
}
compare

(1)调用该函数的对象与string类型的对象进行(ASCll码方式)比较
(2.1)从调用该函数的字符串的 pos 位置开始,取长度为 len 的子串,与 str 进行字典序比较,返回值规则同上
(2.2)从调用该函数的字符串的 pos 位置开始,取长度为 len 的子串,与 str 从 subpos 位置开始、长度为 sublen 的子串进行字典序比较,返回值规则同上。
(3.1)将当前字符串与 C 风格字符串 s 进行字典序比较,返回值规则同上。
(3.2)从当前字符串的 pos 位置开始,取长度为 len 的子串,与 C 风格字符串 s 进行字典序比较,返回值规则同上。
(4)从当前字符串的 pos 位置开始,取长度为 len 的子串,与 C 风格字符串 s 的前 n 个字符进行字典序比较,返回值规则同上。
非成员函数
operator+

(1)字符串+字符串,以string形式返回相加的结果(重载的是+,不是+=,不会改变调用该函数的两个对象)
(2.1)字符串+const char*类型的字符串
(2.2)const char*类型的字符串+string字符串
(3.1)string字符串+单个字符
(3.2)把(3.1)反过来
如果重载为成员函数就无法实现(2.2)和(3.2)类型
relational operators

ASCll码方式比较
重载流插入和流提取
整行获取字符串

istream& getline(istream& is, string& str, char delim);:从输入流is中读取数据,直到遇到分隔符delim(该分隔符被读取但不存储到str中 ),将读取的内容存储到str。istream& getline(istream& is, string& str);:默认分隔符为换行符'\n',从输入流is中读取数据,直到遇到换行符(换行符被读取但不存储到str中 ),将读取的内容存储到str。
输入的数据不受‘ ’(空格)和‘\n’(换行符)的限制,会读入整行的数据
库string类的实现
#pragma once#include<iostream>
#include<string>
#include<assert.h>
#include<algorithm>using namespace std;namespace wx
{class string{public:typedef char* iterator;typedef const char* const_iterator;static const size_t npos;string(const char* str = "");string(const string& s);template<class inputiterator>string(inputiterator begin, inputiterator end){auto it = begin;while(it!=end){push_back(*it);it++;}}~string();iterator begin();iterator end();const_iterator begin() const;const_iterator end() const;const char* c_str() const;void reserve(size_t n);const size_t capacity() const;const size_t size() const;char& operator[](size_t pos);const char& operator[](size_t pos) const;void push_back(char c);string& append(const char* str);string& operator+=(char c);string& operator+=(const char* str);void pop_back();string& insert(size_t pos, char c);string& insert(size_t pos, const char* str);string& operator=(string s);void swap(string& s);string& erase(size_t pos = 0, size_t len = npos);size_t find(char c, size_t pos = 0) const;size_t find(const char* sub, size_t pos = 0) const;string substr(size_t pos, size_t len = npos) const;bool operator<(const string& s) const;bool operator<=(const string& s) const;bool operator>(const string& s) const;bool operator>=(const string& s) const;bool operator==(const string& s) const;bool operator!=(const string& s) const;void clear();private:char* _arr = new char[16];size_t _size = 0;size_t _capacity = 16;};std::ostream& operator<<(std::ostream& os, const string& s);std::istream& operator>>(std::istream& is, string& s);
}
#define _CRT_SECURE_NO_WARNINGS 1
#include<algorithm>#include"mystring.h"namespace wx
{const size_t string::npos = -1;string::string(const char* str){size_t len = strlen(str);reserve(len + 1);for (size_t i = 0; i < len; i++){_arr[i] = str[i];}_size = len;_arr[_size] = '\0';}//string::string(string& s)//{// reserve(s.capacity());// for (size_t i = 0; i < s.size(); i++)// {// _arr[i] = s[i];// }// _size = s.size();// _arr[_size] = '\0';// _capacity = s.capacity();//}string::string(const string& s){string tem(s.begin(), s.end());swap(tem);}string::~string(){delete[] _arr;_arr = nullptr;_capacity = _size = 0;}string::iterator string::begin(){return _arr;}string::iterator string::end(){return _arr + _size;}string::const_iterator string::begin() const{return _arr;}string::const_iterator string::end() const{return _arr + _size;}const char* string::c_str() const{return _arr;}char& string::operator[](size_t pos){assert(pos < _size);return _arr[pos];}const char& string::operator[](size_t pos) const{assert(pos < _size);return _arr[pos];}const size_t string::capacity() const{return _capacity;}const size_t string::size() const{return _size;}void string::push_back(char c){if (_size >= _capacity - 1){reserve(2 * _capacity);}_arr[_size] = c;_size++;_arr[_size] = '\0';}string& string::append(const char* str){size_t len = strlen(str);if ((_size + len) >= (_capacity*2)){reserve(_size + len + 1);}if((_size+len)>=_capacity && (_size + len)<(2 * _capacity)){reserve(2 * _capacity);}for (size_t i = _size; i < (_size + len); i++){_arr[i] = str[i - _size];}_size = _size + len;_arr[_size] = '\0';return *this;}void string::reserve(size_t n){//不支持缩容if (n <= _capacity){return;}//n>_capacitychar* newarr = new char[n];for (size_t i = 0; i < _size; i++){newarr[i] = _arr[i];}delete[] _arr;_arr = newarr;newarr = nullptr;_capacity = n;}string& string::operator+=(char c){push_back(c);return *this;}string& string::operator+=(const char* str){append(str);return *this;}void string::pop_back(){assert(_size > 0);_size--;_arr[_size] = '\0';}string& string::insert(size_t pos, char c){assert(pos <= _size);if (_size >= _capacity){reserve(2 * _capacity);}size_t end = _size + 1;while (end > pos){_arr[end] = _arr[end - 1];end--;}_arr[pos] = c;_size++;return *this;}string& string::insert(size_t pos, const char* str){assert(pos <= _size);size_t len = strlen(str);if (_size + len >= _capacity){if (_size + len >= 2 * _capacity){reserve(_size + len + 1);}else{reserve(2 * _capacity);}}size_t end = _size + len;while (end > pos + len-1){_arr[end] = _arr[end - len];end--;}for (size_t i = pos; i < pos + len; i++){_arr[i] = str[i - pos];}_size += len;_arr[_size] = '\0';return *this;}void string::swap(string& s){std::swap(_arr, s._arr);std::swap(_size, s._size);std::swap(_capacity, s._capacity);}string& string::operator=(string s){swap(s);return *this;}string& string::erase(size_t pos , size_t len){if (len == npos){_size = pos;_arr[_size] = '\0';}else{size_t end = pos + len;while (end <= _size){_arr[end - len] = _arr[end];end++;}_size = _size - len;}return *this;}size_t string::find(char c, size_t pos ) const{assert(pos < _size);for (size_t i = pos; i < _size; i++){if (_arr[i] == c){return i;}}return string::npos;}size_t string::find(const char* sub, size_t pos) const{assert(pos < _size);const char* p = strstr(_arr, sub);if (p == nullptr){return npos;}else{return p - _arr;}}string string::substr(size_t pos, size_t len) const{if (len == string::npos){string tem(begin() + pos, end());return tem;}string tem(_arr + pos, _arr + pos + len);return tem;}bool string::operator<(const string& s) const{size_t len1 = _size;size_t len2 = s._size;size_t i1 = 0, i2 = 0;while (i1 < len1 && i2 < len2){if (_arr[i1] < s._arr[i2]){return true;}else if (_arr[i1] > s._arr[i2]){return false;}else{++i1;++i2;}}return i1 == len1 && i2 < len2;}bool string::operator<=(const string& s) const{return (*this < s && *this == s);}bool string::operator>(const string& s) const{return !(*this <= s);}bool string::operator>=(const string& s) const{return (*this > s && *this == s);}bool string::operator==(const string& s) const{size_t len1 = _size;size_t len2 = s._size;size_t i1 = 0, i2 = 0;while (i1 < len1 && i2 < len2){if (_arr[i1] != s._arr[i2]){return false;}else{++i1;++i2;}}return i1 == len1 && i2 == len2;}bool string::operator!=(const string& s) const{return !(*this == s);}void string::clear(){_size = 0;_arr[_size] = '\0';}std::ostream& operator<<(std::ostream& os, const string& s){for (size_t i = 0; i < s.size(); i++){os << s[i];}return os;}std::istream& operator>>(std::istream& is, string& s){s.clear();char buff[256];size_t i = 0;char ch = is.get();while (ch != ' ' && ch != '\n'){buff[i++] = ch;ch = is.get();if (i == 255){buff[i] = '\0';s += buff;i = 0;}}if (i > 0){buff[i] = '\0';s += buff;}return is;}
}