[前端高频]数组转树、数组扁平化、深拷贝、JSON.stringifyJSON.parse等手撕
N叉树
var preorder = function(root) {//递归let res=[];//要将结果加入一个数组中,不要直接递归整个函数,要不每次都会重新重置res,需在写一个内部函数var dfs=function(root){//递归if(!root)return;//中res.push(root.val);//判断是否为null,null.forEach会报错TypeErrorif(root.children){//子root.children.forEach((child)=>{dfs(child);})}}dfs(root)return res;// 迭代// 用stacklet res=[];if(!root)return res;let stack=[root];while(stack.length>0){let cur=stack.pop();res.push(cur.val);if(cur.children){//要翻转一下,前序遍历二叉树的话应该是将右节点先压入栈!!!cur.children.reverse();cur.children.forEach((child)=>{stack.push(child);})}}return res;//层次遍历
var levelOrder = function(root) {const res=[];if(!root)return res;const queue=[root];while(queue.length){let size=queue.length;const levelRes=[];while(size--){let curNode=queue.shift();levelRes.push(curNode.val);if(curNode.children){curNode.children.forEach(node=>queue.push(node));}}res.push(levelRes);}return res;
};数组转N叉树并遍历
要将给定的树形结构数据中的所有节点ID提取到数组中,可以采用递归遍历或广度优先遍历的方式。以下是两种常见实现方法及示例:
树深度遍历(递归和迭代[栈])、广度遍历(队列)

方法一:递归遍历(深度优先)
递归遍历的核心逻辑是先处理当前节点的ID,再递归处理其子节点,适用于层级较深但数据量适中的场景。
function getAllIds(treeArray) {const ids = [];function traverse(node) {ids.push(node.id);if (node.children && node.children.length > 0) {node.children.forEach(child => traverse(child));}}treeArray.forEach(root => traverse(root));return ids;
}// 示例输入
const input = [{id: 1,name: 'Root',children: [{ id: 2, name: 'Child1', children: [ { id:4, name:'Grandchild', children:[] } ] },{ id: 3, name: 'Child2', children: [] }]}
];console.log(getAllIds(input)); // 输出: [1, 2, 4, 3]
关键点:
- 递归函数:定义内部函数
traverse,依次处理当前节点的ID和子节点。 - 深度优先:优先遍历到最深层的子节点(如示例中的
id:4),再回溯处理兄弟节点。
方法二:广度优先遍历(非递归)
通过队列(Queue)实现层级遍历,先处理父节点,再按层级依次处理子节点,适合需要按层级顺序输出ID的场景。
function getAllIdsBFS(treeArray) {const ids = [];const queue = [...treeArray]; // 初始化队列为根节点数组while (queue.length > 0) {const node = queue.shift(); // 取出队首节点ids.push(node.id);if (node.children && node.children.length > 0) {queue.push(...node.children); // 将子节点加入队列}}return ids;
}console.log(getAllIdsBFS(input)); // 输出: [1, 2, 3, 4]
关键点:
- 队列机制:使用队列按层级顺序遍历节点,根节点先入队,子节点依次入队。
- 非递归:避免递归可能导致的内存溢出问题,适合处理大规模树数据。
处理多个树形数组
如果存在多个独立的树形数组(例如多个根节点),只需遍历每个树并合并结果:
const multiTreeInput = [// 第一个树{ id: 1, children: [ { id: 2 } ] },// 第二个树{ id: 5, children: [ { id: 6 } ] }
];const combinedIds = multiTreeInput.flatMap(tree => getAllIds([tree]));
console.log(combinedIds); // 输出: [1, 2, 5, 6]
适用场景
- 权限系统:获取角色树中的所有权限ID。
- 组织架构:提取部门层级中的全部成员ID。
- 数据统计:分析树状结构的节点分布。
边界条件与优化
• 空值处理:若节点无children字段或children为空数组,需避免遍历错误。
• 去重:若树中存在重复ID,可通过Set去重(如[...new Set(ids)])。
• 性能优化:对超大规模数据,广度优先遍历内存占用更低。
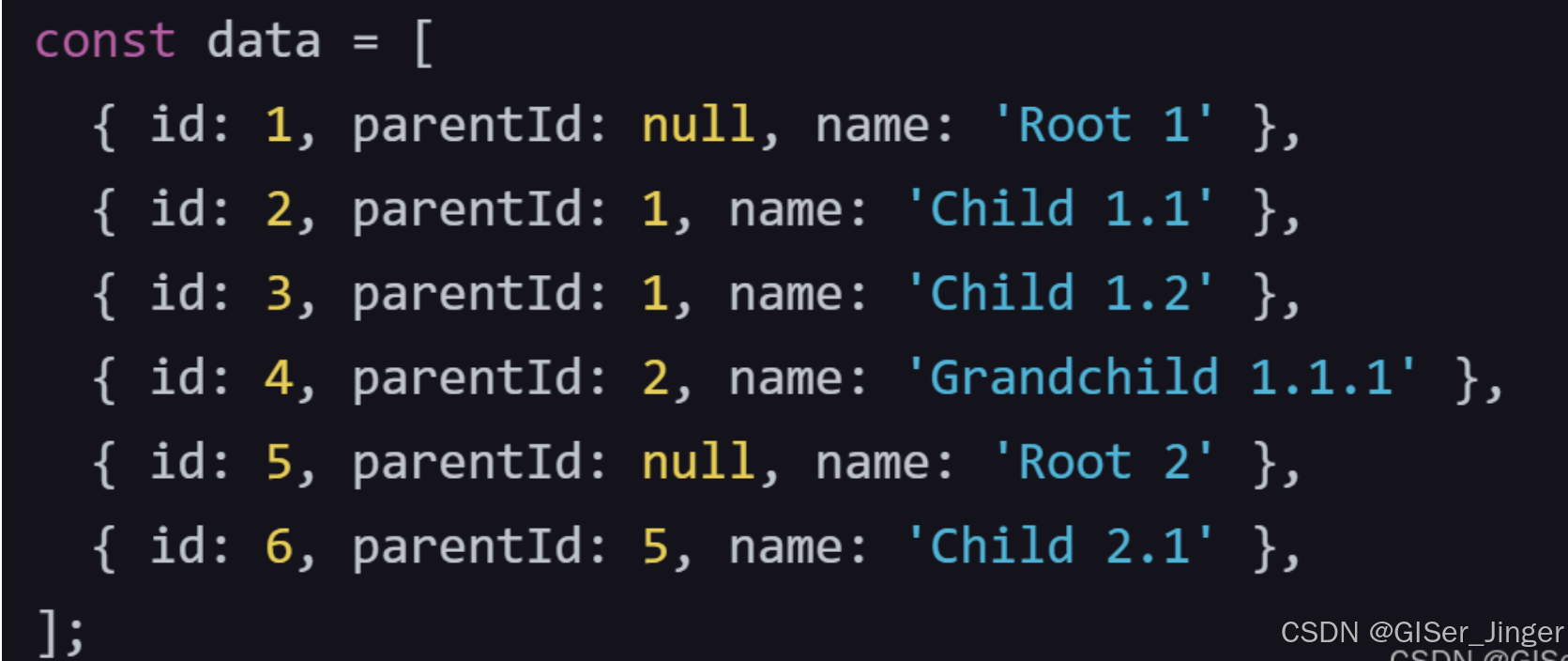
//3.处理较大数据集
// 示例数据 - 较大的数据集
const largeData = [{ id: 1, name: "Root", parentId: null },{ id: 2, name: "Child 1", parentId: 1 },{ id: 3, name: "Child 2", parentId: 1 },{ id: 4, name: "Grandchild 1", parentId: 2 },{ id: 5, name: "Grandchild 2", parentId: 2 },{ id: 6, name: "Grandchild 3", parentId: 3 },{ id: 7, name: "Great Grandchild", parentId: 4 }
];// 构建优化后的树形结构
const optimizedTree = buildTreeWithMap(largeData);// 输出结果
console.log(JSON.stringify(optimizedTree, null, 2));//推荐使用!!!
function buildTreeWithMap(data){const itemMap=new Map();let tree=[];// 第一次遍历:将所有项存入Map并初始化children数组for (const item of data) {itemMap.set(item.id, { ...item, children: [] });if(item.parentId!==null){if(!itemMap.get(item.parentId)) {itemMap.set(item.parentId,{children:[]});}//push的是itemMap.get(item.id),push进去的是子对象的引用itemMap.get(item.parentId).children.push(itemMap.get(item.id));}else{tree.push(itemMap.get(item.id));}}for(let item of data){const node=itemMap.get(item.id);if(node.children && node.children.length===0){//删除属性delete node.children;}}return tree;
}// //递归形式(推荐)
function buildTree2(flatData,parentId=null) {const tree=[];for(let item of flatData){if(item.parentId===parentId) {//递归调用子节点const children=buildTree2(flatData,item.id);//如果有children则才新增属性if(children.length) {item.children=children;}tree.push(item);}}return tree;
}