bitmap/hyperloglog/GEO详解与案例实战
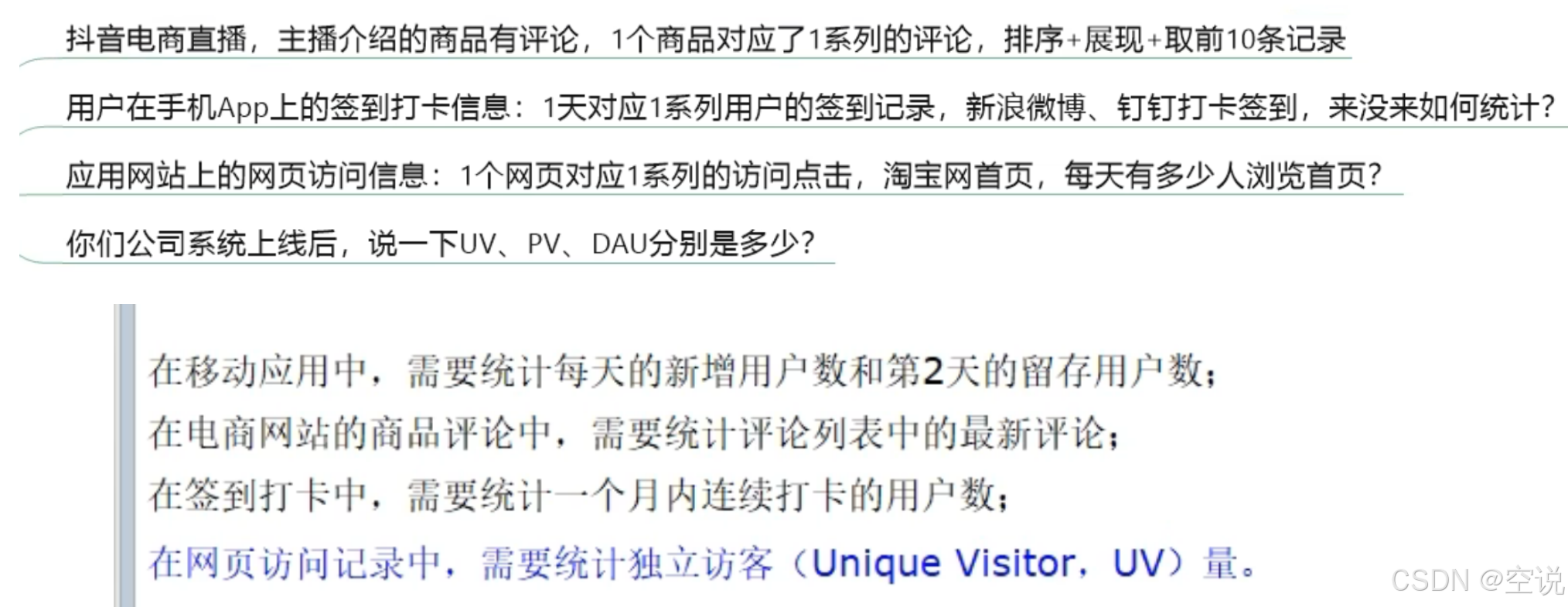
痛点:类似今日头条,抖音这样的用户访问级别都是亿级别,请问如何处理?
一句话 存的进+取得快+多维度,真正有价值的是统计…
大数据统计
聚合统计:
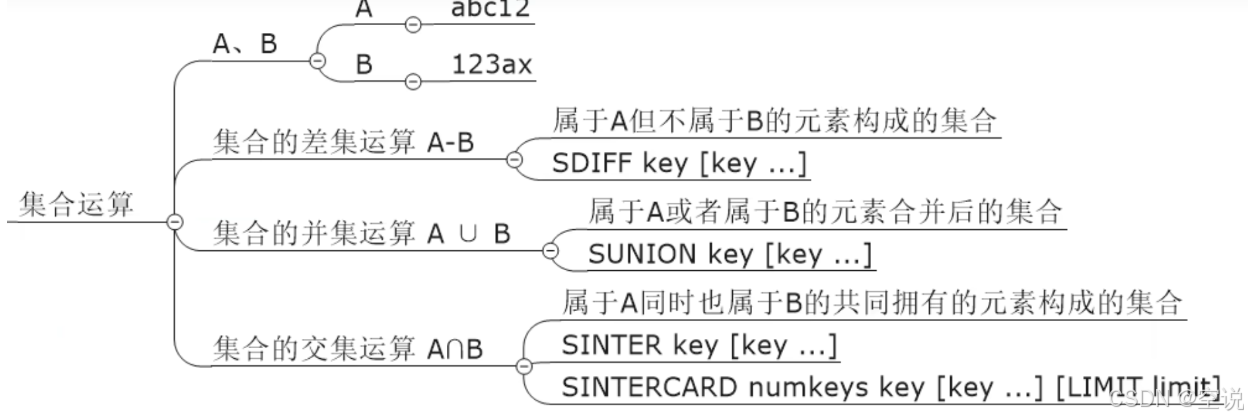
统计多个集合元素的聚合结果,就是前面讲解过的交差并等集合统计。可以用Set实现
排序统计:
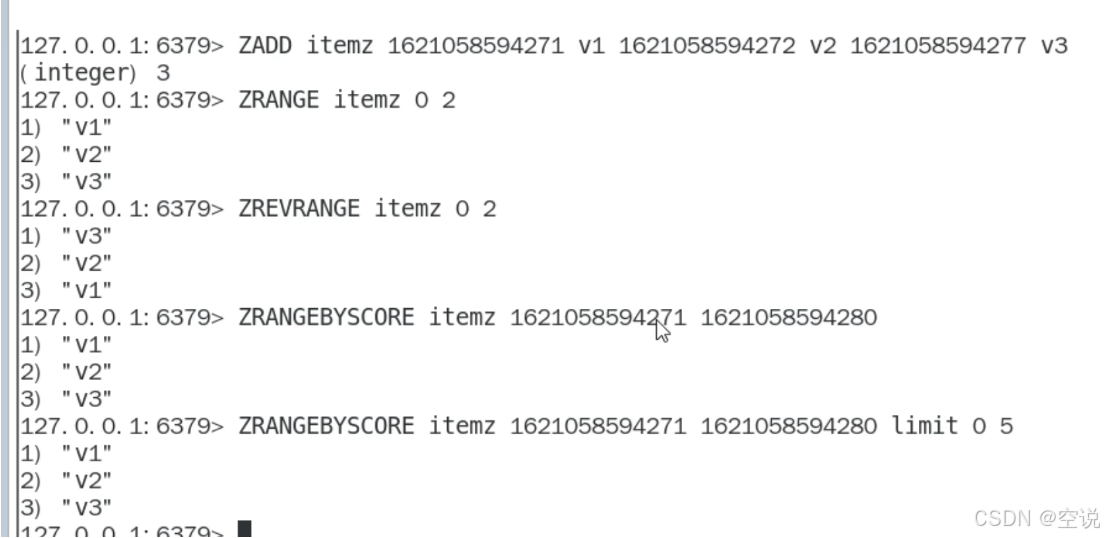
抖音短视频最新评论留言的场景,设计一个展现列表。可以用Zset实现
二值统计
集合的取值就只有0和1两种。比如钉钉打卡上班,我们只用记录有签到和没签到。可以使用bitmap实现
基数统计
hyperloglog:指统计一个集合中不重复的元素个数
基本术语:
-
UV(Unique View):多少个用户点击,独立访客,理解为客户端ip
-
PV(Page View):页面浏览量(不用去重)
-
DAU((Daily Active User):日活跃用户量(登陆或使用了某个产品的用户数)
-
MAU(Monthly Active User):月活跃用户量
-
基数:是一种数据集,去重后的真实个数
需求:
很多计数类场景,比如每日注册IP数、每日访问IP数、页面实时访问数PV、访问用户数UV等。因为主要的目标高效、巨量地进行计数,所以对存储的数据的内容并不太关心。
也就是说它只能用于统计巨量数量,不太涉及具体的统计对象的内容和精准性。
- 统计单日一个页面的访问量(PV),单次访问就算一次。
- 统计单日一个页面的用户访问量(UV),即按照用户维度计算,单个用户一天内多次访问也只算一次。多个key的合并统计,某个门户网站的所有模块的PV聚合统计就是整个网站的总PV。
hyperloglog基本命令:
| 命令 | 作用 |
|---|---|
| pfadd key element… | 将所有元素添加到key中 |
| pfcount key | 统计key的估算值 |
| pgmerge new_key key1 key2… | 合并key至新key |
原理:
对于亿级数据 bitmap去重:
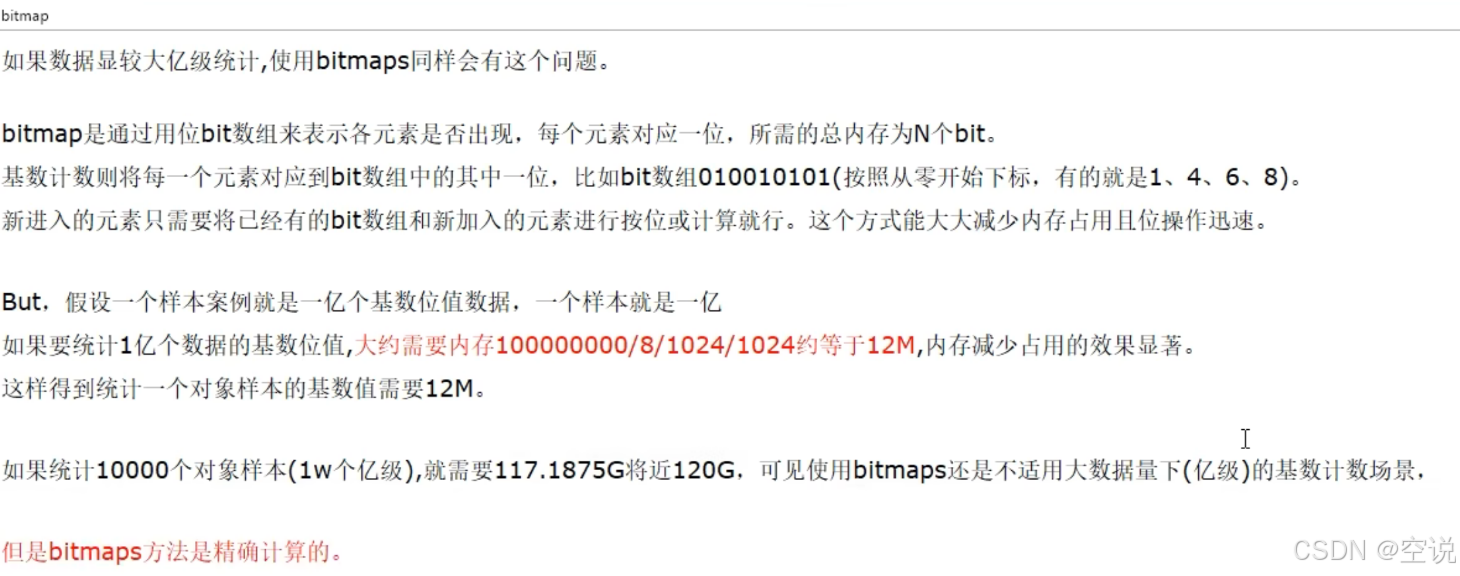
概率算法:通过牺牲准确率来换取空间,对于不要求绝对准确率的场景下可以使用,因为概率算法不直接存储数据本身,通过一定的概率统计方法预估基数值,同时保证误差在一定范围内,由于又不储存数据故此可以大大节约内存。
HyperLogLog就是一种概率算法的实现,误差仅仅只是0.81%左右
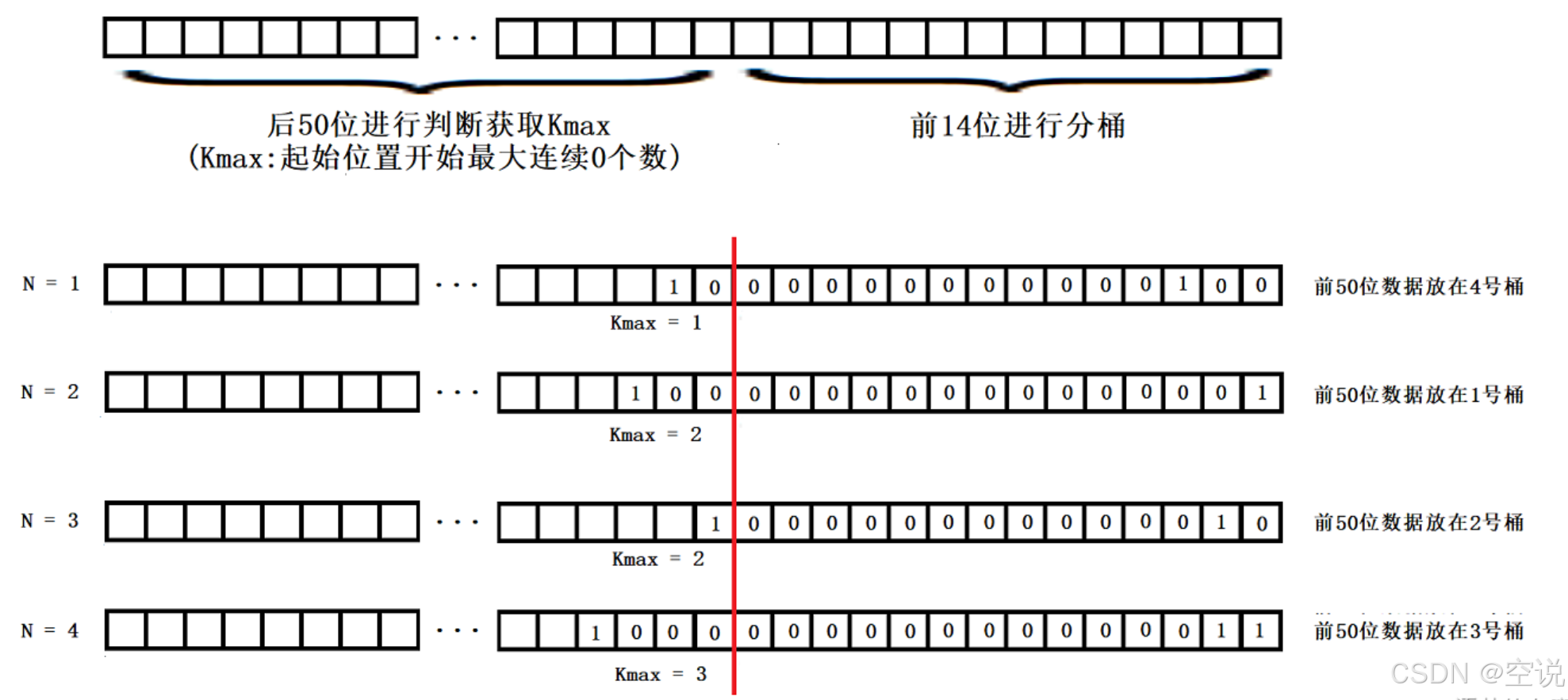
 Redis中Hyperloglog前14位进行分桶,后50位进行获取Kmax
Redis中Hyperloglog前14位进行分桶,后50位进行获取Kmax
3.1 将数据转化为bit串
通过Hash函数,将数据转为64位的比特串,例如输入5,便转为:101。为什么要这样转化呢?
是因为要和抛硬币对应上,比特串中,0 代表了反面,1 代表了正面,如果一个数据最终被转化了 10010000,那么从右往左,从低位往高位看,我们可以认为,首次出现 1 的时候,就是正面。
那么基于上面的估算结论,我们可以通过多次抛硬币实验的最大抛到正面的次数来预估总共进行了多少次实验,同样也就可以根据存入数据中,转化后的出现了 1 的最大的位置 Kmax 来估算存入了多少数据。
3.2 分桶
分桶就是分多少轮。在抛硬币中我们可以将三次实验分为一组,用这一组的Kmax求平均值当作一次的Kmax,这样可以减少误差。
抽象到计算机存储中去,就是存储的是一个以单位是比特(bit),长度为 L 的大数组 S ,将 S 平均分为 m 组,注意这个 m 组,就是对应多少轮,然后每组所占有的比特个数是平均的,设为 P。容易得出下面的关系:
L = S.length
L = m * p
以 K 为单位,S 占用的内存 = L / 8 / 1024
为什么Hyperloglog大小为12K?
-
前14位用于分桶,也就是需要2^14 = 16384个桶(016383,也就是14位全0全1)
-
每个桶子需要存储后50位得到的Kmax值(起始开始最多连续零个数),而50位最多有50个0,因此Kmax最大取到50,2^6 = 64 > 50,因此每个桶只需要6个bit位就可以保存Kmax
-
每8个bit位为1字节,每1024字节为1K
-
综合以上两点:Hyperloglog的大小 = 16384 * 6 / 8 * 1024 = 12KB
-
Redis将这种情况称为密集(dense)存储。
-
核心点:hyperloglog不存数据,可以理解为每个元素添加进去,一样的元素kmax不变,最后根据kmax估计所有桶去重个数 加和即可
案例实战
-
UV的统计需要去重,一个用户一天内的多次访问只能算作一次
-
淘宝、天猫首页的UV,平均每天是1~1.5个亿左右
-
每天存1.5个亿的IP,访问者来了后先去查是否存在,不存在加入
方案讨论:
- 用mysql
- 用 redis的hash结构存储
- hyperloglog
代码实现:
//实现三层架构controller service redisTemplete 即可
地理位置计算

GEO相关命令:
redis-cli --raw解决中文乱码问题
| 命令 | 作用 |
|---|---|
| GEOADD key longitude latitude member [longitude latitude member …] | GEOADD 添加位置坐标 |
| GEOPOS key member [member …] | 获取指定位置的坐标 |
| GEOHASH key member [member …] | 返回坐标的geohash表示32位编码值 从三维编程二进制 |
| GEODIST key member1 member2 [m\km\ft\mi] | 两个位置之间的距离 |
| georadius key longitude latitude dist [m\km\ft\mi] withcoord count 10 desc | 以给定经纬度为中心,查找半径内附近的XXX |
| georadiusbymember key member dist [m\km\ft\mi] withlist withcoord count 10 withhash | 找出给定指定范围内的元素,中心点是由给定的位置元素决定 |
代码实例
//geoController
controller层调sevice层的方法
//geoService调用redisTemplete层的对应geo方法写在service层下的方法即可//如geoadd()方法//注意点:整合springboot整合redis后 会有一个point类型,里面存经纬度public String geoadd(){Map<String,Point> map=new HashMap<>();map.put("天安门",new Point(116.403963,39.915119));...redisTemplete.opsForGeo().add(CITY,map);return map.toString();
}
//获得经纬度坐标public Point position(String member){ //key,member,如输入meber天安门,则返回天安门的经纬度坐标List<Point>list=redisTemplete.opsForGeo().position(CITY,member)}
//找出给定指定范围内的元素,中心点是由给定的位置元素决定
public GeoResults radiusByxy(){//北京王府井位置 116.418017,39.914402 //以千米为单位给出半径Circle circle=new Circle(116.418017,39.914402,Metrics.KILOMETERS.getMultipler());//返回50条 RedisGeoCommands.GeoRadiusCommandArgs args= 半径 距离 伴随经纬度 降序 50条记录 RedisGeoCommands.GeoRadiusCommandArgs.newGeoRadiusArgs().includeDistance.includeCoordinates().sortDescending().limit(50)reidsTemple.opsForGeo().radius(CITY,circle,args).var;return geoResults;
}