MySQL初阶:sql事务和索引
索引(index)
可以类似理解为一本书的目录,一个表可以有多个索引。
索引的意义和代价
在MySQL中使用select进行查询时会经过:
1.先遍历表
2.将条件带入每行记录中进行判断,看是否符合
3.不符合就跳过
但当表中的数据量非常大,这样的操作开销就会非常大,因为数据库是存储在硬盘上的,每次读取都会从硬盘上读取。
因此索引就是针对查询进行的优化手段,索引可以避免表进行遍历,加快查询的速度。
索引可以加快查询的速度但是有一定代价:
1.创建索引需要占用更多的空间,因为生成索引需要一定数据结构,以及一些额外的数据,来存储在硬盘中。
2.索引可能会使插入和删除降低速度,因为插入删除数据需要修改索引的内容,需要进行得工作更多。
索引的基本操作
1)查看索引
show index from 表名;

如果没有索引查看就是空。
当没加索引的列和加了索引的列一起进行查询时,效率会比单独查询索引列低。
2)创建索引
create index 索引名 on 表名(列名);

创建索引要在表名后设置列名,否则会报错。
当指定多行列时,此时创建的就是复合索引,复合索引采用最左边匹配,就是最左边的列,查询时要是id或id,name才能进行效率提升。
3)删除索引
drop index 索引名 on 表名;
删除索引只能删除自己创建的索引,而不能删除系统创建的索引。
索引不仅可以自己创建,系统也可以自动生成索引,例如primary key ,unique ,foreign key(主键,unique因为其中涉及到一些查找操作来判断是否重复存在相同的约束数据,外键则要判断父表中和子表中被约束数据的一致)
索引的创建是危险的操作,当数据量比较大的时候,创建索引,可能会使数据库卡死。
索引的实现原理
索引实质上也是基于数据结构实现的。
不同于二叉搜索树和哈希表,数据库要进行模糊匹配,而哈希表进行的是准确匹配;二叉搜索树的每一个节点都是只能有两个子树,这样就会增加遍历时的时间复杂度。
因此索引是由B+树这个N叉搜索树来实现的。
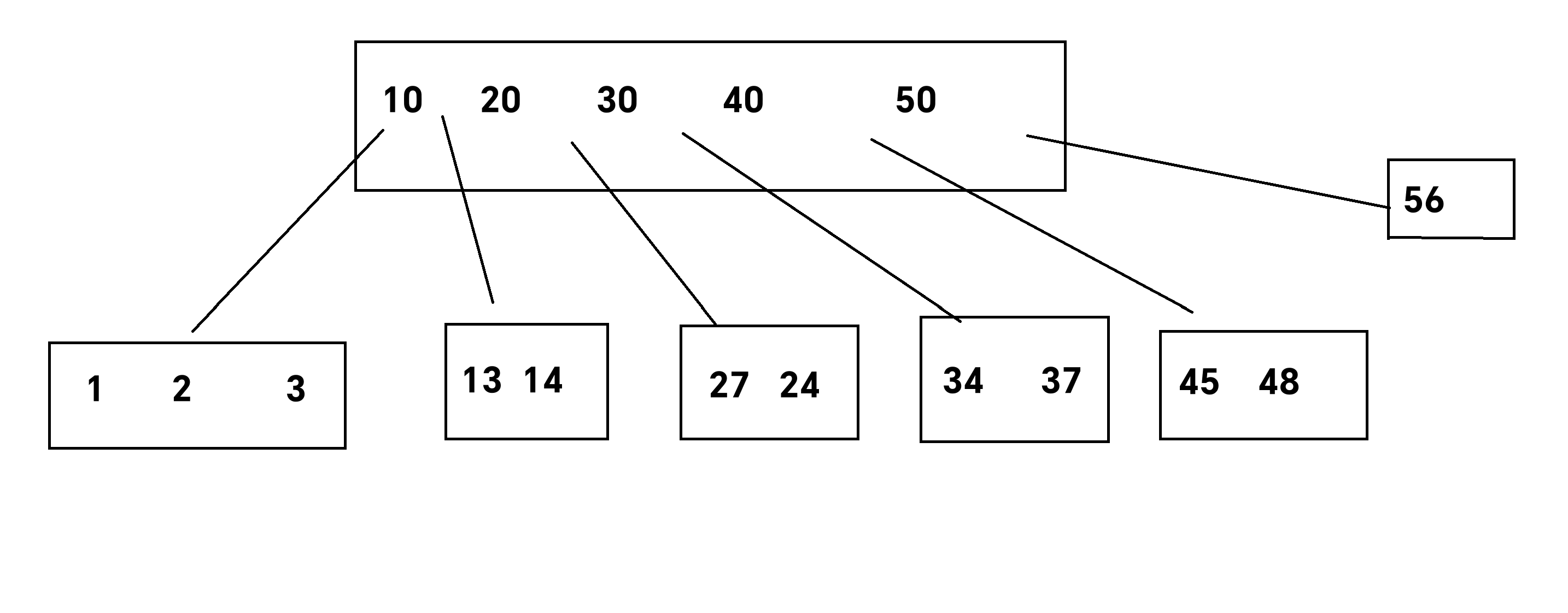
B树:B树的每个结点的度都是不确定的,一个结点的可以有N个key,因此可以划分成N+1个区间,这些区间又会划分出一系列的区间,这样就会减少树的高度,减少读硬盘的次数。
一个节点的数不是无限的,当达到一定数量就会分裂,同样的,当减少到一定数量就会触发合并。
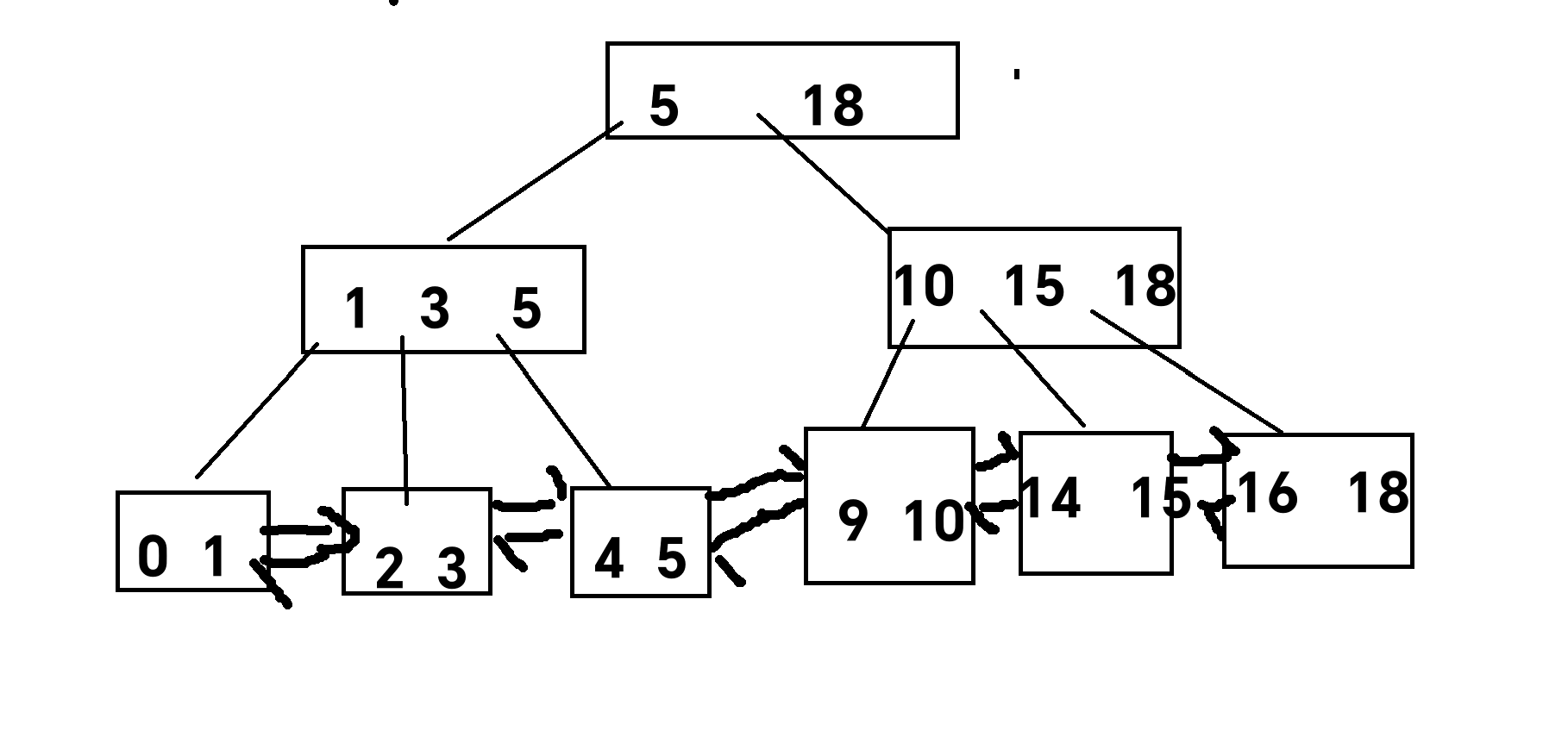
B+树:B+树也是一个N叉树,每个节点有M个节点,可以划分成M个区间。
每一个节点中的最后一个数,相当于当前节点的最大值。
父节点上的每一个数都会以最大值的身份在子节点中出现,最终的叶子节点这一层会包含所有数。
B+树会使用链表这样的数据结构将叶子节点穿起来。
B+树:
 B+树相比B树,哈希表红黑树的优点:
B+树相比B树,哈希表红黑树的优点:
1)N叉搜索树,降低了树的高度,降低了IO的次数。
2)擅长范围查询。
3)最终要落到叶子节点,时间开销稳定。
这里讨论的是最经典的B+树,但实际上MySQL数据库对此进行了一些优化。
事务
事务的特点
事务可以把多个sql打包成一个整体,可以保证这些sql要么全部执行,要么“一个都不执行”,这里的一个都不执行是指当一条sql执行错误时,数据库会进行一个回滚(rollback),回到一开始执行的时候。
事务将sql打包到一起,作为一个整体来执行,这样的特点叫做“原子性”。
事务使用
stat transation:开启事务,单独执行的sql是没有原子性的。
执行各种事务
commit:事务结束了
rollback:回滚(可以指定回滚)
事务的特性(重要)
1.原子性:通过回滚的方式让事务进行正确的执行,不然就回退到开始。
2.一致性:事务执行前后数据不能离谱,通常需要数据库约束和一些列检查机制来完成。
3.持久性:事务做出的修改,要持久保存在硬盘上。重启服务器,数据仍然存在。
4.隔离性(重要):数据库并发执行的时候涉及到的问题(并发执行:一个服务器连接多个客户端,当多个客户端发来请求,服务器就要同时处理两个请求)。
。
1)脏读问题:
一个事务A写数据,事务B读取数据,接下来A事务修改了数据,但是事务B没有改变,导致事务B读取的是一个无效的数据。
解决脏读问题的思路是:对写操作进行加锁。
此时并发性降低,隔离性提高,效率降低,准确性提高。
2)不可重复读
事务A在多次读取同一个数据时,读取出现不一样的情况,可能是在两次读操作之间事务B进行了修改,此时叫做不可重复读。
解决思路:将读操作进行加锁。
此时并发性降低,隔离性提高,效率降低,准确性提高。
3)幻读
事务A进行两次读操作,数据内容没变,但是结果集变了。
结果集:select * 表,查询到的临时表就是结果集。
例如第一次查询到的记录是1.张三,2.李四;但是第二次查询结果是1.张三,2.李四,3.赵六;
原来数据虽然没变,但是结果集变了,叫做幻读。
隔离级别
隔离级别就是在效率和数据正确性之间进行选择
mysql可以在配置文件中修改隔离级别,四种隔离级别可以解决上面的三种问题,可以根据实际需要更改配置文件。
1)read uncommitted(读未提交):并发程度最高,隔离性最低,准确性最低。
2)read committed (读以提交):引入了读加锁,并发程度降低,隔离性提高。
3)repeattable read(可重复读):引入了读加锁和写加锁,并发降低,隔离性提高。
4)serializable(串行化):一个一个执行事务,没有并发,隔离性最高。