【机器学习】第二章模型的评估与选择
A.关键概念
2.1 经验误差和过拟合
-
经验误差与泛化误差:学习器在训练集上的误差为经验误差,在新样本上的误差为泛化误差
-
过拟合:学习器训练过度后,把训练样本自身的一些特点当作所有潜在样本具有一般性质,使得泛化性能下降的现象。过拟合是机器学习面临的关键障碍,无法避免,只能缓和。
2.2 评估方法
-
留出法(hold-out):将训练集分为两个互斥的集合,一个作为训练集,另一个作为测试集的评估方法。
- 划分不同,得到的结果也不同。所以需要采用若干次随机划分取均值的方法
- 若训练集过大,测试集过小,则评估结果不够稳定准确。若测试集过大,训练集过小,则被评估的模型和用完整数据集训练出的模型差别较大,降低了评估结果的保真性。通常将2/3~4/5的样本永远训练,其余的用于测试。
- 分层采样:保留类别比例的采样方式。留出法需要分层采样
-
交叉验证法: 先将数据集划分为k个大小相似的互斥子集,并保证子集由分层采样得到,然后每次选择k-1个子集的并集作为训练集,余下的子集作为测试集,进行训练测试。可进行k次测试,返回k次测试的均值。
- k折交叉验证:k的值影响评估结果,为了强调这一点,进一步把交叉验证法称为 k折交叉验证
- 留一法:k 为样本数时的一个特例。
-
自助法:给定m个样本的数据集D,我们对其采样产生D‘。每次随机从D中抽取一个样本,将其拷贝放入D’,再放回D,重复m次。约有36.8%的样本没有没有出现在D‘,留作训练集
2.3性能度量
1.均方误差 E = 1 m ∑ i = 1 m ( f ( x i ) − y i ) 2 \frac{1}{m} \sum_{i=1}^{m}(f(x_i)-y_i)^2 m1∑i=1m(f(xi)−yi)2
2.混淆矩阵:如下图
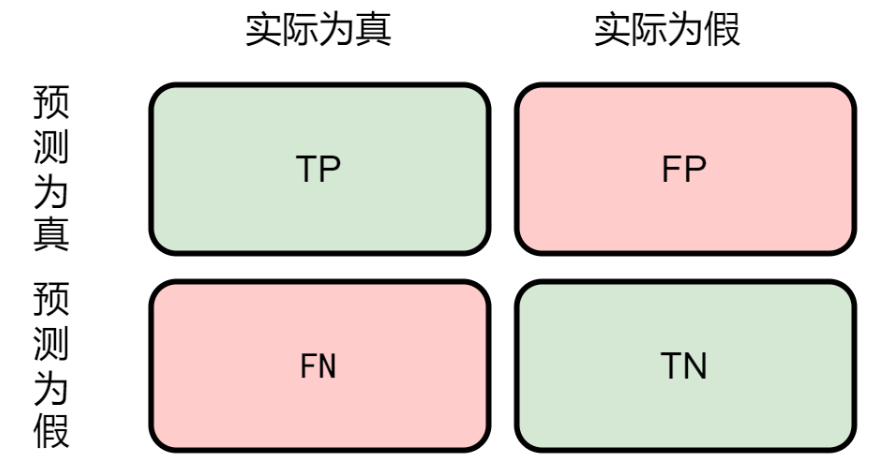
3.查准率: P = TP/(TP+FP)
4.查全率: R = TP/(TP+FN)
5.F1度量: F 1 = 2 P R P + R , F_1 = \frac{2 PR}{P+R}, F1=P+R2PR, F β = ( 1 + β 2 ) P R β 2 P + R F_\beta =\frac{(1+\beta^2)PR}{\beta^2P+R} Fβ=β2P+R(1+β2)PR, β > 1 \beta > 1 β>1查全率影响更大
6.宏查全率,微查全率:宏查全率先算好再平均,微查全率先累加再算
B.例题
西瓜书题目:



其他题目:
对于从数据(0,1),(1,0),(1,2),(2,1)通过最小二乘拟合的不带偏置项的线性模型y=x,其训练误差(均方误差)为____ (保留三位小数)
答案:1.000
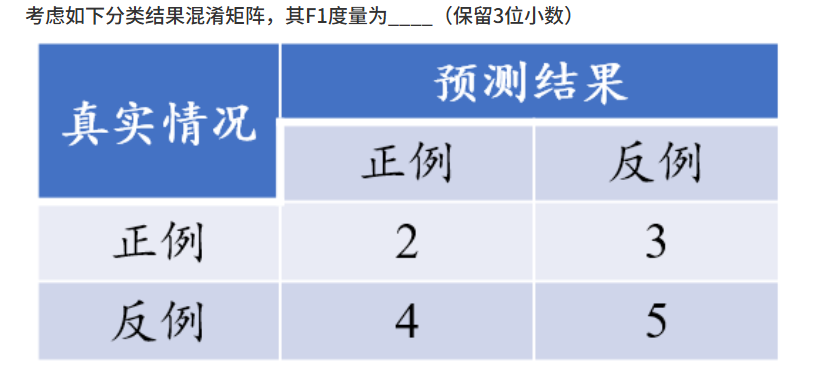
答案:0.364,(4/11)