从代码学习深度学习 - 词嵌入(word2vec)PyTorch版
文章目录
- 前言
- 1. 为什么需要词嵌入?
- 2. 早期尝试:独热向量 (One-Hot Vectors)
- 独热向量的局限性
- 3. 自监督的 word2vec
- 4. 跳元模型 (Skip-Gram Model)
- 4.1. 训练
- 5. 连续词袋 (CBOW) 模型
- 5.1. 训练
- 总结
前言
自然语言处理(NLP)是人工智能领域中一个充满活力和挑战的分支。要让计算机理解和处理人类语言,首要任务之一就是如何表示词汇。传统的独热编码(One-Hot Encoding)虽然简单直观,但在表达词与词之间的语义关系时显得力不从心。为了克服这一局限性,词嵌入(Word Embeddings)技术应运而生,其中 word2vec 是最具里程碑意义的模型之一。
本篇博客将深入探讨 word2vec 的核心思想和两种主要模型:Skip-Gram 和 CBOW(Continuous Bag-of-Words)。虽然标题提及 “PyTorch版”,但理解这些模型背后的数学原理和机制是进行任何框架(包括 PyTorch)实现的基础。因此,本文将重点放在理论阐述上,为后续的实践打下坚实的基础。
完整代码:下载链接
1. 为什么需要词嵌入?
自然语言是用来表达人脑思维的复杂系统。 在这个系统中,词是意义的基本单元。顾名思义, 词向量_是用于表示单词意义的向量, 并且还可以被认为是单词的特征向量或表示。 将单词映射到实向量的技术称为_词嵌入。 近年来,词嵌入逐渐成为自然语言处理的基础知识。
2. 早期尝试:独热向量 (One-Hot Vectors)
假设词典中不同词的数量(词典大小)为N,每个词对应一个从0到N−1的不同整数(索引)。为了得到索引为i的任意词的独热向量表示,需要创建一个全为0的长度为N的向量,并将位置i的元素设置为1。这样,每个词都被表示为一个长度为N的向量,可以直接由神经网络使用。
(示意图:假设词典大小为5,"猫"的索引为2,则其独热向量为[0,0,1,0,0])
独热向量的局限性
虽然独热向量很容易构建,但它们通常不是一个好的选择。一个主要原因是独热向量不能准确表达不同词之间的相似度,比如我们经常使用的“余弦相似度”。对于向量 x , y ∈ R d \mathbf{x},\mathbf{y}\in\mathbb{R}^d x,y∈Rd,它们的余弦相似度是它们之间角度的余弦:
x ⊤ y ∥ x ∥ ∥ y ∥ ∈ [ − 1 , 1 ] . \frac{\mathbf{x}^\top\mathbf{y}}{\|\mathbf{x}\|\|\mathbf{y}\|}\in[-1,1]. ∥x∥∥y∥x⊤y∈[−1,1].
由于任意两个不同词的独热向量之间的余弦相似度为0,所以独热向量不能编码词之间的相似性。例如,“猫”和“狗”在语义上是相关的,但它们的独热向量的点积为0,无法体现这种相关性。此外,当词典非常大时,独热向量会变得非常稀疏且维度极高,带来“维度灾难”问题。
3. 自监督的 word2vec
word2vec工具将每个词映射到一个固定长度的向量,这些向量能更好地表达不同词之间的相似性和类比关系。word2vec工具包含两个模型,即_跳元模型_(skip-gram)和_连续词袋_(CBOW)。对于在语义上有意义的表示,它们的训练依赖于条件概率,条件概率可以被看作使用语料库中一些词来预测另一些单词。由于是不带标签的数据,因此跳元模型和连续词袋都是自监督模型。
“自监督”意味着模型从数据本身创建标签。例如,在word2vec中,我们不是用人工标注的“情感类别”或“主题”来训练,而是利用词语在文本中的共现关系。模型试图根据一个词(中心词)预测其上下文词,或者根据上下文词预测中心词。
4. 跳元模型 (Skip-Gram Model)
跳元模型假设一个词可以用来在文本序列中生成其周围的单词。以文本序列“the”“man”“loves”“his”“son”为例。假设中心词选择“loves”,并将上下文窗口设置为2,如下图所示,给定中心词“loves”,跳元模型考虑生成上下文词“the”“man”“him”“son”的条件概率:
P ( "the" , "man" , "his" , "son" ∣ "loves" ) . P(\text{"the"},\text{"man"},\text{"his"},\text{"son"}|\text{"loves"}). P("the","man","his","son"∣"loves").
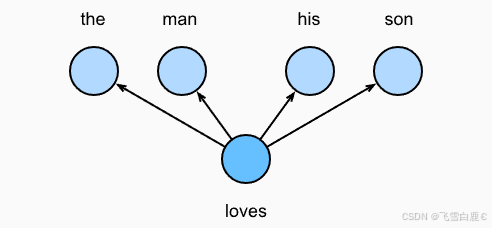
假设上下文词是在给定中心词的情况下独立生成的(即条件独立性)。在这种情况下,上述条件概率可以重写为:
P ( " t h e " ∣ " l o v e s " ) ⋅ P ( " m a n " ∣ " l o v e s " ) ⋅ P ( " h i s " ∣ " l o v e s " ) ⋅ P ( " s o n " ∣ " l o v e s " ) . P(\mathrm{"the"}\mid\mathrm{"loves"})\cdot P(\mathrm{"man"}\mid\mathrm{"loves"})\cdot P(\mathrm{"his"}\mid\mathrm{"loves"})\cdot P(\mathrm{"son"}\mid\mathrm{"loves"}). P("the"∣"loves")⋅P("man"∣"loves")⋅P("his"∣"loves")⋅P("son"∣"loves").
在跳元模型中,每个词都有两个d维向量表示,用于计算条件概率。更具体地说,对于词典中索引为i的任何词,分别用 v i ∈ R d \mathbf{v}_i\in\mathbb{R}^d vi∈Rd 和 u i ∈ R d \mathbf{u}_i\in\mathbb{R}^d ui∈Rd 表示其用作_中心词_和_上下文词_时的两个向量。给定中心词 w c w_{c} wc (词典中的索引c),生成任何上下文词 w o w_{o} wo (词典中的索引o)的条件概率可以通过对向量点积的softmax操作来建模:
P ( w o ∣ w c ) = exp ( u o ⊤ v c ) ∑ i ∈ V exp ( u i ⊤ v c ) , P(w_o\mid w_c)=\frac{\exp(\mathbf{u}_o^\top\mathbf{v}_c)}{\sum_{i\in\mathcal{V}}\exp(\mathbf{u}_i^\top\mathbf{v}_c)}, P(wo∣wc)=∑i∈Vexp(ui⊤vc)exp(uo⊤vc),
其中词表索引集 V = { 0 , 1 , … , ∣ V ∣ − 1 } \mathcal{V}=\{0,1,\ldots,|\mathcal{V}|-1\} V={0,1,…,∣V∣−1}。给定长度为T的文本序列,其中时间步t处的词表示为 w ( t ) w^{(t)} w(t)。假设上下文词是在给定任何中心词的情况下独立生成的。对于上下文窗口m,跳元模型的似然函数(Likelihood Function,用于度量在给定参数的情况下,观测数据出现的“可能性”有多大)是在给定任何中心词的情况下生成所有上下文词的概率:
∏ t = 1 T ∏ − m ≤ j ≤ m , j ≠ 0 P ( w ( t + j ) ∣ w ( t ) ) , \prod_{t=1}^T\prod_{-m\leq j\leq m,j\neq0}P(w^{(t+j)}\mid w^{(t)}), ∏t=1T∏−m≤j≤m,j=0P(w(t+j)∣w(t)),
其中可以省略小于1或大于T的任何时间步。
其中:
- 外层乘积是对整个句子(时间序列)中每一个词进行迭代;
- 内层乘积是对每个词周围的 2m 个邻近词(上下文)进行预测(排除自身 j ≠ 0 j\neq0 j=0);
- 即“每个词都作为中心词,预测它的上下文”。
这实际上是训练 Skip-Gram 模型时的目标函数(最大化这个联合概率,或最小化其负对数)。
4.1. 训练
跳元模型参数是词表中每个词的中心词向量和上下文词向量。在训练中,通过最大化似然函数(即极大似然估计)来学习模型参数。这相当于最小化以下损失函数: