从代码学习深度学习 - 实战Kaggle比赛:狗的品种识别(ImageNet Dogs)PyTorch版
文章目录
- 前言
- 1. 获取和整理数据集
- 1.1 读取标签
- 1.2 整理数据集:划分训练集和验证集
- 1.3 整理测试集
- 1.4 执行数据重组
- 2. 图像增广
- 3. 读取数据集
- 3.1 创建Dataset实例
- 3.2 创建DataLoader实例
- 4. 微调预训练模型
- 4.1 定义网络结构
- 4.2 定义损失函数和评估函数
- 5. 定义训练函数
- 6. 训练和验证模型
- 7. 对测试集分类并保存结果
- 附录:工具代码
- `utils_for_train.py`
- `utils_for_huitu.py`
- 总结
前言
欢迎来到“从代码学习深度学习”系列!本次我们将通过一个实际的Kaggle竞赛项目——“狗的品种识别”(Dog Breed Identification)来深入学习如何使用PyTorch进行图像分类。这个项目的数据集源自著名的ImageNet,但专注于识别不同品种的狗。
与我们之前可能接触过的CIFAR-10等数据集相比,ImageNet中的图像尺寸更大、宽高不一,这为数据预处理和模型选择带来了新的挑战。我们将一步步完成数据获取、整理、图像增广、模型微调、训练、验证以及最终的预测与提交。
通过这个实战项目,你将学习到:
- 如何处理实际竞赛中不规整的图像数据集。
- 如何有效地组织和划分训练、验证、测试数据。
- 图像增广技术在提升模型泛化能力中的应用。
- 利用预训练模型进行迁移学习(微调)的核心思想和PyTorch实现。
- 完整的模型训练、评估和预测流程。
让我们开始吧!
完整代码:下载链接
1. 获取和整理数据集
比赛数据集分为训练集和测试集。训练集包含10222张RGB(彩色)JPEG图像,涵盖120个犬种;测试集包含10357张图像。我们的目标是正确识别这些犬种。
首先,我们需要一个辅助函数来读取包含图像文件名和对应标签的CSV文件。
1.1 读取标签
以下代码定义了read_csv_labels函数,它会读取一个CSV文件,跳过表头,然后将每一行解析为(文件名,标签)对,并存储在一个字典中。
import os# 定义数据目录路径
data_dir = 'kaggle_dog_tiny'def read_csv_labels(fname):"""读取CSV文件并返回文件名到标签的映射字典参数:fname (str): CSV文件路径返回:dict: 包含文件名到标签的映射字典- 键 (str): 图像文件名- 值 (str): 对应的类别标签"""with open(fname, 'r') as f:# 跳过CSV文件的第一行(列名)lines = f.readlines()[1:]# 将每行按逗号分割成tokens# tokens是一个列表,每个元素是[文件名, 标签]形式的列表# 维度: tokens - list[list[str, str]], 长度为样本数量tokens = [l.rstrip().split(',') for l in lines]# 构建字典,将文件名映射到对应的标签# 维度: 返回的字典 - dict{str: str}, 键为文件名,值为标签return dict(((name, label) for name, label in tokens))# 读取训练标签文件
# 维度: labels - dict{str: str}, 键为文件名,值为标签
labels = read_csv_labels(os.path.join(data_dir, 'labels.csv'))# 打印训练样本数量(即字典中键值对的数量)
# len(labels) - int, 表示训练样本的数量
print('# 训练样本:', len(labels))# 打印类别数量(即标签种类的数量)
# len(set(labels.values())) - int, 表示不同类别的数量
print('# 类别:', len(set(labels.values())))
执行上述代码,我们会得到训练样本的数量和类别的数量。对于示例的kaggle_dog_tiny数据集:
# 训练样本: 1000
# 类别: 120
1.2 整理数据集:划分训练集和验证集
为了评估模型的性能并进行调优,我们需要从原始训练集中划分出一部分作为验证集。下面的函数 reorg_train_valid 会将原始训练数据复制到新的目录结构中,按类别分文件夹存放,并根据给定的valid_ratio(验证集比例)将一部分数据同时复制到验证集目录。这个比例是基于数据集中样本数量最少的那个类别来计算的,确保每个类别在验证集中至少有一个样本。
copyfile 是一个辅助函数,用于将单个文件复制到目标目录,如果目标目录不存在则创建它。
import shutil
import collections
import mathdef copyfile(filename, target_dir):"""将文件复制到目标目录参数:filename (str): 源文件路径target_dir (str): 目标目录路径"""# 创建目标目录(如果不存在)# target_dir - str, 目标目录路径os.makedirs(target_dir, exist_ok=True)# 复制文件到目标目录# filename - str, 源文件路径# target_dir - str, 目标目录路径shutil.copy(filename, target_dir)def reorg_train_valid(data_dir, labels, valid_ratio):"""将验证集从原始的训练集中拆分出来参数:data_dir (str): 数据集目录路径labels (dict): 文件名到标签的映射字典valid_ratio (float): 验证集比例,取值范围[0, 1]返回:int: 每个类别中分配给验证集的样本数量"""# 获取样本数最少的类别中的样本数# collections.Counter(labels.values()) - Counter{str: int}, 统计每个标签出现的次数# most_common() - list[(str, int)], 按出现次数降序排列的(标签, 出现次数)列表# most_common()[-1] - tuple(str, int), 出现次数最少的(标签, 出现次数)对# most_common()[-1][1] - int, 出现次数最少的标签的出现次数# n - int, 样本数最少的类别中的样本数n = collections.Counter(labels.values()).most_common()[-1][1]# 计算验证集中每个类别应有的样本数# math.floor(n * valid_ratio) - int, 向下取整的验证集样本数# max(1, math.floor(n * valid_ratio)) - int, 确保每个类别至少有1个样本# n_valid_per_label - int, 每个类别分配给验证集的样本数n_valid_per_label = max(1, math.floor(n * valid_ratio))# 用于跟踪每个类别已分配到验证集的样本数# label_count - dict{str: int}, 键为标签,值为该标签在验证集中的样本数label_count = {}# 遍历训练目录中的所有文件# train_file - str, 训练集中的文件名for train_file in os.listdir(os.path.join(data_dir, 'train')):# 获取文件对应的标签# train_file.split('.')[0] - str, 去除文件扩展名的文件名# label - str, 文件对应的类别标签base_name = train_file.split('.')[0]if base_name and base_name in labels: # 确保文件名有效且在标签字典中label = labels[base_name]# 构建完整的源文件路径# fname - str, 训练文件的完整路径fname = os.path.join(data_dir, 'train', train_file)# 将所有文件复制到train_valid目录下对应类别目录中# (这个目录用于后续合并训练集和验证集进行最终模型训练)# os.path.join(data_dir, 'train_valid_test', 'train_valid', label) - str, 目标目录路径copyfile(fname, os.path.join(data_dir, 'train_valid_test','train_valid', label))# 如果该类别在验证集中的样本数未达到目标数量,则将文件添加到验证集if label not in label_count or label_count[label] < n_valid_per_label:# 复制文件到验证集目录对应类别文件夹下# os.path.join(data_dir, 'train_valid_test', 'valid', label) - str, 验证集目标目录路径copyfile(fname, os.path.join(data_dir, 'train_valid_test','valid', label))# 更新该类别在验证集中的样本计数# label_count.get(label, 0) - int, 当前类别已有的验证集样本数,如果不存在则为0# label_count[label] - int, 更新后该类别在验证集中的样本数label_count[label] = label_count.get(label, 0) + 1else:# 如果该类别在验证集中的样本数已达到目标数量,则将文件添加到新的训练集目录# os.path.join(data_dir, 'train_valid_test', 'train', label) - str, 训练集目标目录路径copyfile(fname, os.path.join(data_dir, 'train_valid_test','train', label))else:print(f"跳过文件名有问题的文件: {train_file}") # 捕获一些特殊文件如 .ipynb_checkpoints# 返回每个类别中分配给验证集的样本数量# n_valid_per_label - intreturn n_valid_per_label
1.3 整理测试集
测试集也需要整理。ImageFolder 通常期望每个类别的图像在各自的子文件夹中。对于测试集,我们通常不知道它们的真实标签,因此可以将所有测试图像放入一个名为 “unknown”(或其他任意名称)的子文件夹下。
import os
import shutil # copyfile 函数依赖 shutil.copy# def copyfile(filename, target_dir): ... (已在上面定义)def reorg_test(data_dir):"""在预测期间整理测试集,以方便读取该函数将测试集图像文件复制到组织化的目录结构中,所有测试图像都归为"unknown"类别参数:data_dir (str): 数据集根目录路径"""# 遍历测试目录中的所有文件# data_dir - str, 数据集根目录路径# os.path.join(data_dir, 'test') - str, 测试集目录的完整路径# os.listdir(...) - list[str], 测试集目录中的所有文件名列表# test_file - str, 当前处理的测试文件名for test_file in os.listdir(os.path.join(data_dir, 'test')):# 构建源文件路径# os.path.join(data_dir, 'test', test_file) - str, 测试文件的完整源路径# 构建目标目录路径,所有测试文件都放在'unknown'类别文件夹下# os.path.join(data_dir, 'train_valid_test', 'test', 'unknown') - str, 目标目录的完整路径# 将测试文件复制到组织化的目录结构中# 源文件: 原始测试集目录下的测试文件# 目标位置: train_valid_test/test/unknown/文件名copyfile(os.path.join(data_dir, 'test', test_file),os.path.join(data_dir, 'train_valid_test', 'test','unknown'))
1.4 执行数据重组
reorg_dog_data 函数将上述步骤整合起来,完成整个数据集的重组。
import os
# import pandas as pd # pandas 未在此函数中使用
import shutil# def read_csv_labels(fname): ... (已在上面定义)
# def reorg_train_valid(data_dir, labels, valid_ratio): ... (已在上面定义)
# def reorg_test(data_dir): ... (已在上面定义)def reorg_dog_data(data_dir, valid_ratio):"""重组狗狗数据集,将数据分为训练集和验证集参数:data_dir (str): 数据目录的路径valid_ratio (float): 验证集占总训练数据的比例"""# 读取CSV标签文件# labels (dict): 文件名(不含扩展名)到标签的映射字典labels = read_csv_labels(os.path.join(data_dir, 'labels.csv'))# 重组训练和验证数据集reorg_train_valid(data_dir, labels, valid_ratio)# 重组测试数据集reorg_test(data_dir)# 批量大小
# batch_size (int): 训练时的批量大小
batch_size = 32 # 验证集比例
# valid_ratio (float): 验证集占总训练数据的比例,范围[0,1]
valid_ratio = 0.1# 执行数据重组函数
# data_dir (str): 数据目录的路径
reorg_dog_data(data_dir, valid_ratio)
执行后,如果kaggle_dog_tiny/train目录下存在如.ipynb_checkpoints这样的隐藏文件夹,可能会打印:
跳过文件名有问题的文件: .ipynb_checkpoints
这不影响正常图像文件的处理。数据将被整理到kaggle_dog_tiny/train_valid_test目录下,包含train, valid, train_valid, 和 test/unknown这些子目录。
2. 图像增广
为了增加训练数据的多样性,防止模型过拟合,并提高其泛化能力,我们采用图像增广技术。
对于训练集,我们应用一系列随机变换:
RandomResizedCrop: 随机裁剪图像并缩放到224x224。裁剪面积为原图的0.08到1.0之间,高宽比在3/4到4/3之间。RandomHorizontalFlip: 以50%的概率水平翻转图像。ColorJitter: 随机调整图像的亮度、对比度和饱和度。ToTensor: 将PIL图像或NumPy数组转换为PyTorch张量,并将像素值从[0, 255]缩放到[0.0, 1.0]。Normalize: 使用ImageNet数据集的均值和标准差对图像进行标准化。
import torchvision
import torch# 定义训练数据的图像变换流程
# transform_train (torchvision.transforms.Compose): 一系列图像变换的组合
transform_train = torchvision.transforms.Compose([# 随机裁剪图像,所得图像为原始面积的0.08~1之间,高宽比在3/4和4/3之间# 然后,缩放图像以创建224x224的新图像# 输入: 任意大小的PIL图像# 输出: 224x224的PIL图像torchvision.transforms.RandomResizedCrop(224, scale=(0.08, 1.0),ratio=(3.0/4.0, 4.0/3.0)),# 以0.5的概率水平翻转图像# 输入: PIL图像# 输出: 相同大小的PIL图像torchvision.transforms.RandomHorizontalFlip(),# 随机更改亮度,对比度和饱和度,每个参数的调整范围为[0.6, 1.4]# 输入: PIL图像# 输出: 相同大小的PIL图像torchvision.transforms.ColorJitter(brightness=0.4,contrast=0.4,saturation=0.4),# 将PIL图像或numpy.ndarray转换为张量,并将像素值范围从[0, 255]缩放到[0.0, 1.0]# 输入: PIL图像或numpy.ndarray,大小为(H, W, C)# 输出: 张量,大小为(C, H, W)torchvision.transforms.ToTensor(),# 使用ImageNet数据集的均值和标准差对图像进行标准化# 输入: 张量,大小为(3, H, W),值范围[0.0, 1.0]# 输出: 标准化后的张量,大小为(3, H, W)torchvision.transforms.Normalize(# 3个通道(RGB)的均值,每个元素对应一个通道mean=[0.485, 0.456, 0.406],# 3个通道(RGB)的标准差,每个元素对应一个通道std=[0.229, 0.224, 0.225])
])
对于测试集(和验证集),我们不应进行随机增广,以保证评估的一致性。变换包括:
Resize: 将图像的短边缩放到256像素,保持高宽比。CenterCrop: 从图像中心裁剪出224x224的区域。ToTensor: 同上。Normalize: 同上。
import torchvision
import torch# 定义测试数据的图像变换流程
# transform_test (torchvision.transforms.Compose): 测试阶段使用的图像变换序列
transform_test = torchvision.transforms.Compose([# 将图像的短边缩放为256像素,保持宽高比不变# 输入: 任意大小的PIL图像# 输出: 短边为256像素的PIL图像torchvision.transforms.Resize(256),# 从图像中心裁切224x224大小的图片# 输入: 宽和高都大于等于224的PIL图像# 输出: 224x224大小的PIL图像torchvision.transforms.CenterCrop(224),# 将PIL图像转换为张量,并将像素值范围从[0, 255]缩放到[0.0, 1.0]# 输入: PIL图像,大小为(H, W, C)# 输出: 张量,大小为(C, H, W)torchvision.transforms.ToTensor(),# 使用ImageNet数据集的均值和标准差对图像进行标准化# 输入: 张量,大小为(3, 224, 224),值范围[0.0, 1.0]# 输出: 标准化后的张量,大小为(3, 224, 224)torchvision.transforms.Normalize(# 3个通道(RGB)的均值,每个元素对应一个通道mean=[0.485, 0.456, 0.406],# 3个通道(RGB)的标准差,每个元素对应一个通道std=[0.229, 0.224, 0.225])
])
3. 读取数据集
数据整理和增广策略定义好后,我们使用torchvision.datasets.ImageFolder来创建PyTorch的Dataset对象,它会自动从按类别组织的文件夹结构中加载图像和标签。然后,使用torch.utils.data.DataLoader创建数据迭代器,用于在训练和评估时按批次提供数据。
3.1 创建Dataset实例
我们为之前创建的train、train_valid、valid和test目录分别创建Dataset对象。
import os
import torchvision
import torch
# from torch.utils.data import Dataset # Dataset 基类在这里没有直接使用,ImageFolder是它的子类# data_dir, transform_train, transform_test 需已定义# 创建训练集和训练验证集 (train_valid用于最终模型训练)
# train_ds (torchvision.datasets.ImageFolder): 仅包含训练数据的数据集对象
# train_valid_ds (torchvision.datasets.ImageFolder): 包含训练和验证数据的合并数据集对象
# 每个数据集对象返回元组 (image, label),其中:
# - image (torch.Tensor): 形状为 (3, 224, 224) 的图像张量
# - label (int): 表示图像类别的整数
train_ds, train_valid_ds = [torchvision.datasets.ImageFolder(# os.path.join 返回字符串,表示文件夹的完整路径os.path.join(data_dir, 'train_valid_test', folder),# 应用之前定义的训练数据变换transform=transform_train) for folder in ['train', 'train_valid']
]# 创建验证集和测试集
# valid_ds (torchvision.datasets.ImageFolder): 只包含验证数据的数据集对象
# test_ds (torchvision.datasets.ImageFolder): 只包含测试数据的数据集对象
# 每个数据集对象返回元组 (image, label),其中:
# - image (torch.Tensor): 形状为 (3, 224, 224) 的图像张量
# - label (int): 表示图像类别的整数
valid_ds, test_ds = [torchvision.datasets.ImageFolder(# os.path.join 返回字符串,表示文件夹的完整路径os.path.join(data_dir, 'train_valid_test', folder),# 应用之前定义的测试数据变换(无随机增强)transform=transform_test) for folder in ['valid', 'test']
]
3.2 创建DataLoader实例
DataLoader将Dataset包装起来,提供数据批处理、打乱、并行加载等功能。
import torch
from torch.utils.data import DataLoader# batch_size, train_ds, train_valid_ds, valid_ds, test_ds 需已定义# 创建训练集和训练验证集的数据加载器
# train_iter (torch.utils.data.DataLoader): 纯训练数据的加载器
# train_valid_iter (torch.utils.data.DataLoader): 训练和验证合并数据的加载器
# 每个批次返回:
# - images (torch.Tensor): 形状为 (batch_size, 3, 224, 224) 的图像批次
# - labels (torch.Tensor): 形状为 (batch_size,) 的标签批次
train_iter, train_valid_iter = [torch.utils.data.DataLoader(# dataset: ImageFolder实例,提供(图像, 标签)对dataset, # batch_size (int): 每个批次包含的样本数量batch_size, # shuffle=True: 每个epoch随机打乱数据顺序 (适用于训练)shuffle=True, # drop_last=True: 如果最后一个批次不足batch_size,则丢弃 (适用于训练,保证批次大小一致)drop_last=True)for dataset in (train_ds, train_valid_ds)
]# 创建验证集的数据加载器
# valid_iter (torch.utils.data.DataLoader): 验证数据的加载器
# 每个批次返回:
# - images (torch.Tensor): 形状为 (batch_size, 3, 224, 224) 的图像批次
# - labels (torch.Tensor): 形状为 (batch_size,) 的标签批次
valid_iter = torch.utils.data.DataLoader(# valid_ds: 验证集的ImageFolder实例valid_ds, # batch_size (int): 每个批次包含的样本数量batch_size, # shuffle=False: 不打乱验证数据的顺序,保持一致性 (适用于验证/测试)shuffle=False,# drop_last=True: 保持与训练时相似的处理,或者可以设为Falsedrop_last=True # 同样,对于某些评估场景,设为False可能更合适
)# 创建测试集的数据加载器
# test_iter (torch.utils.data.DataLoader): 测试数据的加载器
# 每个批次返回:
# - images (torch.Tensor): 形状为 (batch_size或更少, 3, 224, 224) 的图像批次
# - labels (torch.Tensor): 形状为 (batch_size或更少,) 的标签批次
test_iter = torch.utils.data.DataLoader(# test_ds: 测试集的ImageFolder实例test_ds, # batch_size (int): 每个批次包含的样本数量batch_size, # shuffle=False: 不打乱测试数据的顺序 (适用于验证/测试)shuffle=False,# drop_last=False: 保留最后一个不完整批次,确保所有测试数据都被评估drop_last=False
)
注意,训练时shuffle=True以增加随机性,drop_last=True可以保证所有批次的形状一致。测试和验证时shuffle=False,drop_last对于测试集通常设为False以确保所有样本都被评估。
4. 微调预训练模型
由于本次实战的数据集是ImageNet数据集的子集,并且我们可能没有足够的计算资源从头训练一个大型卷积神经网络,因此一个有效的策略是使用在完整ImageNet数据集上预训练的模型。我们加载预训练模型的权重,并将其作为特征提取器,然后在其之上添加一个新的小型分类网络,只训练这个新添加的部分。这个过程称为微调(Fine-tuning)或迁移学习(Transfer Learning)。
我们选择预训练的ResNet-34模型。
4.1 定义网络结构
get_net函数负责加载预训练的ResNet-34模型,替换其原始的1000类输出层为一个新的两层全连接网络(1000 -> 256 -> 120类),并冻结预训练部分的参数,这样在训练时只有新添加的分类器参数会被更新。
import os
import torch
import torchvision
import torch.nn as nn# 设置预训练模型权重的下载路径
# download_path (str): 存储预训练模型权重的目录路径
download_path = './model_weights' # 替换为你想要的路径# 确保下载目录存在
os.makedirs(download_path, exist_ok=True)# 使用 torch.hub.set_dir() 设置下载缓存目录
torch.hub.set_dir(download_path)def get_net(devices):"""创建一个基于ResNet34的微调网络模型参数:devices (list of torch.device): 用于计算的设备列表返回:finetune_net (nn.Sequential): 微调后的网络模型"""# 创建一个顺序模型容器# finetune_net (nn.Sequential): 包含特征提取和分类器的顺序模型finetune_net = nn.Sequential()# 加载预训练的ResNet34模型及其权重# weights (torchvision.models.ResNet34_Weights): 预训练模型的权重weights = torchvision.models.ResNet34_Weights.IMAGENET1K_V1 # 预训练权重# 将预训练的ResNet34模型设置为特征提取器# finetune_net.features (torchvision.models.ResNet): ResNet34模型,其原始输出维度为(batch_size, 1000)finetune_net.features = torchvision.models.resnet34(weights=weights)# 检查模型是否成功加载print(f"模型加载成功:ResNet34 预训练模型已加载")print(f"模型权重保存在:{download_path}") # 或 torch.hub.get_dir()# 定义一个新的输出网络,共有120个输出类别# finetune_net.output_new (nn.Sequential): 自定义分类器,输入维度为1000,输出维度为120finetune_net.output_new = nn.Sequential(# 全连接层,将ResNet34的1000维输出特征降至256维# 输入: (batch_size, 1000)# 输出: (batch_size, 256)nn.Linear(1000, 256),# ReLU激活函数,增加非线性# 输入/输出形状保持不变: (batch_size, 256)nn.ReLU(),# 输出层,将256维特征映射到120个类别# 输入: (batch_size, 256)# 输出: (batch_size, 120)nn.Linear(256, 120))# 将模型参数分配给用于计算的CPU或GPU# 输入/输出形状保持不变,但模型参数被移动到指定设备finetune_net = finetune_net.to(devices[0])# 冻结特征提取器的所有参数,仅训练新添加的分类器部分# param.requires_grad (bool): 表示参数是否需要计算梯度for param in finetune_net.features.parameters():param.requires_grad = Falsereturn finetune_net
4.2 定义损失函数和评估函数
我们使用交叉熵损失函数。evaluate_loss函数用于在给定的数据迭代器上计算模型的平均损失,这在验证阶段非常有用。
import torch
import torch.nn as nn# 定义交叉熵损失函数,不进行批次维度上的平均 (reduction='none')
# 这样可以得到每个样本的损失,之后可以手动求和或求平均
# loss (nn.CrossEntropyLoss): 交叉熵损失函数对象
# 输入: (batch_size, num_classes), (batch_size)
# 输出 (若 reduction='none'): (batch_size) 每个样本的损失值
loss = nn.CrossEntropyLoss(reduction='none')def evaluate_loss(data_iter, net, devices):"""计算给定数据集上的平均损失参数:data_iter (torch.utils.data.DataLoader): 数据加载器net (nn.Module): 神经网络模型devices (list of torch.device): 用于计算的设备列表返回:avg_loss (torch.Tensor): 标量张量,表示整个数据集上的平均损失"""# l_sum (torch.Tensor): 累积的损失总和,初始化为0.0,形状为标量# n (int): 样本总数,初始化为0l_sum, n = 0.0, 0net.eval() # 设置为评估模式with torch.no_grad(): # 关闭梯度计算# 遍历数据集中的每个批次# features (torch.Tensor): 形状为(batch_size, 3, 224, 224)的图像批次# labels (torch.Tensor): 形状为(batch_size)的标签批次for features, labels in data_iter:# 将数据移动到指定设备(通常是GPU)# features, labels的形状保持不变,但张量被移动到设备上features, labels = features.to(devices[0]), labels.to(devices[0])# 前向传播计算模型输出# outputs (torch.Tensor): 形状为(batch_size, 120)的预测结果outputs = net(features)# 计算每个样本的损失# l (torch.Tensor): 形状为(batch_size)的损失值张量l_batch = loss(outputs, labels) # loss对象已定义为reduction='none'# 累加批次中所有样本的损失# l_batch.sum() (torch.Tensor): 标量张量,当前批次的损失总和l_sum += l_batch.sum()# 累加样本数量# labels.numel() (int): 当前批次中的样本数量n += labels.numel()net.train() # 恢复为训练模式# 计算平均损失并移动到CPU# (l_sum / n) (torch.Tensor): 标量张量,平均损失# 返回值 (torch.Tensor): 标量张量,平均损失(CPU上)return (l_sum / n).to('cpu')
5. 定义训练函数
train函数是核心的训练逻辑。它接收网络、数据迭代器、训练轮数、学习率、权重衰减等参数。
主要步骤包括:
- 如果有多GPU,使用
nn.DataParallel包装模型。 - 定义SGD优化器,只优化
requires_grad=True的参数(即我们新添加的分类器层)。 - 定义学习率调度器
StepLR,用于在训练过程中周期性地降低学习率。 - 初始化计时器(
Timer)、累加器(Accumulator)和绘图器(Animator)(这些来自我们提供的utils_for_train.py和utils_for_huitu.py)。 - 主训练循环(按epoch):
- 将模型设为训练模式 (
net.train())。 - 遍历训练数据批次:
- 数据上载到设备。
- 梯度清零 (
trainer.zero_grad())。 - 前向传播 (
net(features))。 - 计算损失。
- 反向传播 (
l.backward())。 - 更新参数 (
trainer.step())。 - 累加损失和样本数。
- 更新动画绘图。
- 如果提供了验证集,则调用
evaluate_loss计算验证损失并更新绘图。 - 学习率调度器步进 (
scheduler.step())。
- 将模型设为训练模式 (
- 打印最终的训练/验证损失和训练速度。
import torch
import torch.nn as nn
import utils_for_huitu # 假设 utils_for_huitu.py 在同一目录或PYTHONPATH
import utils_for_train # 假设 utils_for_train.py 在同一目录或PYTHONPATH# loss 函数需已定义 (nn.CrossEntropyLoss(reduction='none'))
# evaluate_loss 函数需已定义def train(net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period, lr_decay):"""训练神经网络模型参数:net (nn.Module): 待训练的神经网络模型train_iter (torch.utils.data.DataLoader): 训练数据加载器valid_iter (torch.utils.data.DataLoader): 验证数据加载器,可以为Nonenum_epochs (int): 训练轮数lr (float): 学习率wd (float): 权重衰减系数devices (list of torch.device): 用于训练的设备列表lr_period (int): 学习率调整周期lr_decay (float): 学习率衰减系数"""# 如果设备数量大于1且存在多个GPU设备,则使用DataParallelif len(devices) > 1 and all(d.type == 'cuda' for d in devices):net = nn.DataParallel(net, device_ids=devices).to(devices[0])else:net = net.to(devices[0]) # 单设备或CPU# 仅优化需要梯度的参数(即未冻结的参数,通常是新添加的分类器层)# trainer (torch.optim.SGD): SGD优化器实例trainer = torch.optim.SGD(# 筛选需要计算梯度的参数(param for param in net.parameters() if param.requires_grad), lr=lr, # 学习率momentum=0.9, # 动量系数weight_decay=wd # 权重衰减系数(L2正则化))# 学习率调度器,按指定周期调整学习率# scheduler (torch.optim.lr_scheduler.StepLR): 学习率调度器实例scheduler = torch.optim.lr_scheduler.StepLR(trainer, lr_period, lr_decay)# 训练准备工作# num_batches (int): 每个epoch中的批次总数# timer (utils_for_train.Timer): 计时器,用于统计训练速度num_batches, timer = len(train_iter), utils_for_train.Timer()# 图例设置,用于绘图# legend (list of str): 图例标签列表legend = ['train loss']if valid_iter is not None:legend.append('valid loss')# 创建动画器,用于实时可视化训练过程# animator (utils_for_huitu.Animator): 动画器实例animator = utils_for_huitu.Animator(xlabel='epoch', # x轴标签xlim=[1, num_epochs], # x轴范围legend=legend # 图例标签)# 开始训练循环for epoch in range(num_epochs):# 创建累加器,用于统计损失和样本数# metric (utils_for_train.Accumulator): 累加器实例,大小为2# metric[0] (float): 累积的损失总和# metric[1] (int): 累积的样本总数metric = utils_for_train.Accumulator(2)net.train() # 设置为训练模式# 遍历训练数据集中的每个批次# features (torch.Tensor): 形状为(batch_size, 3, 224, 224)的图像批次# labels (torch.Tensor): 形状为(batch_size)的标签批次for i, (features, labels) in enumerate(train_iter):timer.start()# 将数据移动到指定设备features, labels = features.to(devices[0]), labels.to(devices[0])# 清除之前的梯度trainer.zero_grad()# 前向传播# output (torch.Tensor): 形状为(batch_size, 120)的预测输出output = net(features)# 计算损失并求和# l (torch.Tensor): 标量张量,表示当前批次的总损失l_batch = loss(output, labels) # loss对象已定义为reduction='none'l = l_batch.sum()# 反向传播计算梯度l.backward()# 更新模型参数trainer.step()# 累加损失和样本数metric.add(l.item(), labels.shape[0]) # 使用.item()获取标量值timer.stop()# 每处理约1/5的批次或处理完最后一个批次时,更新图表if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:animator.add(# x坐标: 当前epoch进度epoch + (i + 1) / num_batches,# y坐标: (训练损失, 验证损失),此处验证损失为None(metric[0] / metric[1], None))# 计算并记录训练损失# measures (str): 描述训练结果的字符串train_loss_epoch = metric[0] / metric[1]measures = f'train loss {train_loss_epoch:.3f}'# 如果有验证集,计算验证损失if valid_iter is not None:# valid_loss (torch.Tensor): 标量张量,表示验证集上的平均损失valid_loss = evaluate_loss(valid_iter, net, devices)# 更新图表,添加验证损失点animator.add(epoch + 1, (None, valid_loss.detach().cpu()))measures += f', valid loss {valid_loss.item():.3f}' # 使用 .item()# 更新学习率scheduler.step()# 打印最终训练结果# (在循环外打印最终的整体指标)# 计算并打印训练速度和使用的设备# 训练速度 = 总样本数 / 总时间print(measures + f'\n{metric[1] * num_epochs / timer.sum():.1f}'f' examples/sec on {str(devices)}')
6. 训练和验证模型
现在,我们设置好所有参数,调用get_net获取模型,然后调用train函数开始训练。
我们将首先使用训练集(train_iter)进行训练,并在验证集(valid_iter)上评估模型。
import torch
import utils_for_train # 确保 utils_for_train.py 可用
# from torch import nn # 已在train函数和get_net中导入
# from torch.utils.data import DataLoader # 已在创建迭代器时导入# get_net, train, train_iter, valid_iter, loss, evaluate_loss 等函数需已定义# 设置训练参数和初始化模型
# devices (list of torch.device): 可用的GPU设备列表,如果没有GPU则为CPU
devices = utils_for_train.try_all_gpus()# num_epochs (int): 训练的轮数
num_epochs = 10# lr (float): 初始学习率
lr = 1e-4# wd (float): 权重衰减系数,用于L2正则化
wd = 1e-4# lr_period (int): 学习率调整周期,每隔lr_period个epoch调整一次学习率
lr_period = 2# lr_decay (float): 学习率衰减系数,每次调整时将学习率乘以lr_decay
lr_decay = 0.9# net (nn.Module): 神经网络模型
# get_net() 返回一个预训练的ResNet34模型,其中特征提取部分参数被冻结
# 只有新添加的分类器部分(输出层)会被训练
net = get_net(devices)# 开始训练模型
# train_iter (DataLoader): 训练数据集的数据加载器,每个批次返回(images, labels)
# - images (torch.Tensor): 形状为(batch_size, 3, 224, 224)的图像批次
# - labels (torch.Tensor): 形状为(batch_size,)的标签批次
# valid_iter (DataLoader): 验证数据集的数据加载器,格式与train_iter相同
train(net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period, lr_decay)
训练过程中的损失变化会通过Animator动态绘制出来。训练结束后,会打印出最终的训练/验证损失和训练速度。
这是一个示例输出和对应的图表(实际图表会动态更新):
模型加载成功:ResNet34 预训练模型已加载
模型权重保存在:./model_weights
train loss 1.266, valid loss 1.519
896.5 examples/sec on [device(type='cuda', index=0), device(type='cuda', index=1)]
(如果使用多GPU,设备列表可能会不同。如果是CPU,则是[device(type='cpu')])
… 训练结束后,会打印出最终的训练/验证损失和训练速度。
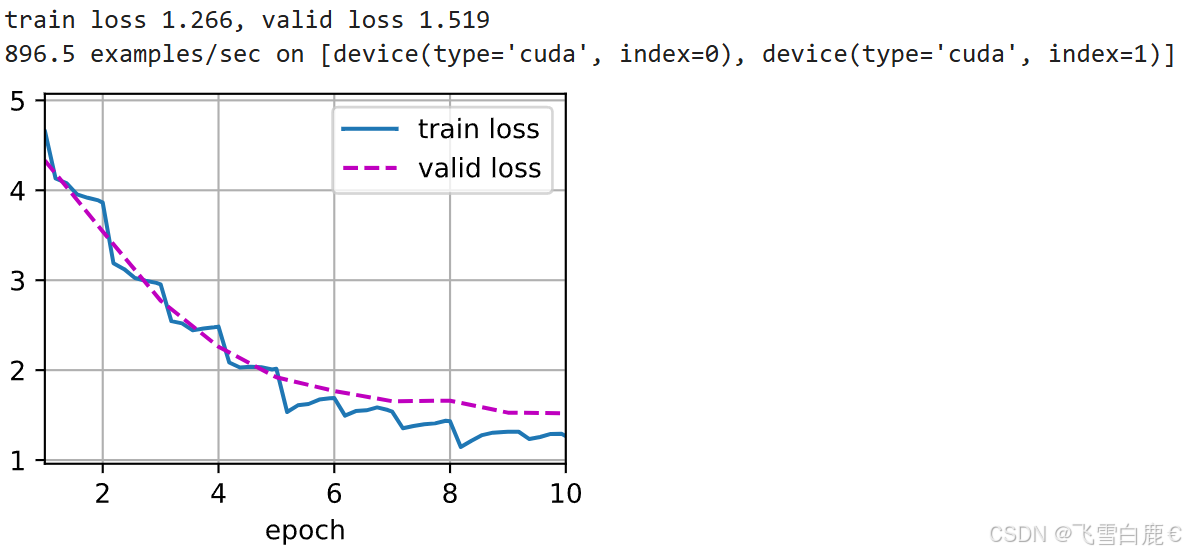
模型加载成功:ResNet34 预训练模型已加载
模型权重保存在:./model_weights
train loss 1.266, valid loss 1.519
896.5 examples/sec on [device(type='cuda', index=0), device(type='cuda', index=1)]
(如果使用多GPU,设备列表可能会不同。如果是CPU,则是[device(type='cpu')])
7. 对测试集分类并保存结果
模型训练(并可选地在验证集上验证)完成后,我们用它来对测试集进行预测。
首先,我们会使用**全部的训练数据(包括之前划分出的验证集部分)**来重新训练模型。这是因为在提交最终结果时,我们希望模型能够利用所有可用的有标签数据。所以,我们再次调用get_net来获取一个全新的、权重未被第一次训练修改的模型,然后使用train_valid_iter(它包含了所有原始训练数据)进行训练。这次训练时,valid_iter参数设为None,因为我们不再进行中间验证。
训练完毕后,模型进入评估模式 (net.eval(),虽然在 train 函数内部评估时会自动切换,但这里明确一下概念,预测时也是评估模式)。我们遍历测试数据迭代器 (test_iter),对每个批次的图像进行预测。模型的输出是每个类别的原始分数(logits),我们需要通过torch.nn.functional.softmax将其转换为概率分布。然后,将这些概率保存下来。
最后,我们将预测结果按照Kaggle竞赛要求的格式写入一个CSV文件(通常名为submission.csv)。该文件需要包含两列:id(测试图像的文件名,不含扩展名)和每个类别的预测概率。测试集图像的文件名需要按字母顺序排序。
import os
import torch
import torch.nn.functional as F # 使用 softmax
import numpy as np# get_net, train, train_valid_iter, test_iter, devices 等需已定义
# num_epochs, lr, wd, lr_period, lr_decay 训练参数需已定义
# data_dir 和 train_valid_ds (用于获取类别名称) 需已定义# 初始化网络模型 (重新获取一个干净的模型)
# net (nn.Module): 神经网络模型,基于ResNet34的迁移学习模型
net = get_net(devices)# 使用全部训练和验证数据进行最终训练
# train_valid_iter (DataLoader): 合并的训练和验证数据集的数据加载器
# None: 没有单独的验证集,此时不计算验证损失
# num_epochs, lr, wd, devices, lr_period, lr_decay: 训练参数,含义同之前定义
print("开始在完整的 train_valid 数据集上训练最终模型...")
train(net, train_valid_iter, None, num_epochs, lr, wd, devices, lr_period, lr_decay)
print("最终模型训练完成。")# 创建空列表存储测试集预测结果
# preds (list): 存储模型在测试集上的预测概率,每个元素是一个形状为(120,)的numpy数组
preds = []
net.eval() # 确保模型在评估模式
print("开始在测试集上进行预测...")
with torch.no_grad(): # 预测时不需要计算梯度# 遍历测试数据集# data (torch.Tensor): 形状为(batch_size, 3, 224, 224)的图像批次# label (torch.Tensor): 形状为(batch_size,)的标签批次(测试阶段的label是ImageFolder自动生成的,通常是0,我们不使用它)for data, _ in test_iter: # _ 表示我们不使用测试集的标签# 将数据移至设备并进行前向传播计算# output (torch.Tensor): 形状为(batch_size, 120)的模型输出logits# 我们需要应用softmax得到概率output_logits = net(data.to(devices[0]))output_probs = torch.nn.functional.softmax(output_logits, dim=1)# 将预测结果转为numpy数组并添加到列表# output_probs.cpu().detach().numpy() (numpy.ndarray): 形状为(batch_size, 120)的numpy数组preds.extend(output_probs.cpu().numpy()) # .detach()不是必须的,因为在no_grad()块内print("预测完成。准备写入提交文件...")# 获取测试集中的文件ID列表(按字母顺序排序)
# ids (list of str): 测试集图像文件名列表
# 注意:路径是之前 reorg_test 函数整理后的路径
ids = sorted(os.listdir(os.path.join(data_dir, 'train_valid_test', 'test', 'unknown')))# 将预测结果写入CSV文件
# 'submission.csv': 提交文件名
submission_file = 'submission.csv'
with open(submission_file, 'w') as f:# 写入CSV文件头,包含 'id' 和所有类别名称# train_valid_ds.classes (list of str): 所有类别名称的列表,长度为120f.write('id,' + ','.join(train_valid_ds.classes) + '\\n')# 遍历每个测试样本及其预测结果# i (str): 文件名,如'dog1.jpg'# output_p (numpy.ndarray): 形状为(120,)的概率分布数组for i, output_p in zip(ids, preds):# 将文件名(不含扩展名)和对应的预测概率写入CSV文件# i.split('.')[0] (str): 文件名去除扩展名,如'dog1'# [str(num) for num in output_p] (list of str): 将概率值转换为字符串f.write(i.split('.')[0] + ',' + ','.join([f"{num:.4f}" for num in output_p]) + '\\n') # 格式化概率输出print(f"提交文件 '{submission_file}' 已生成。")
执行完这段代码后,会在当前目录下生成submission.csv文件,你可以将此文件提交到Kaggle竞赛平台。
示例输出可能如下:
模型加载成功:ResNet34 预训练模型已加载
模型权重保存在:./model_weights
开始在完整的 train_valid 数据集上训练最终模型...
train loss 1.188
920.2 examples/sec on [device(type='cuda', index=0), device(type='cuda', index=1)]
最终模型训练完成。
开始在测试集上进行预测...
预测完成。准备写入提交文件...
提交文件 'submission.csv' 已生成。
(实际的损失值和训练速度会根据你的硬件和数据有所不同)
附录:工具代码
本项目中使用了一些辅助工具函数,分别位于utils_for_train.py和utils_for_huitu.py。
utils_for_train.py
这个文件包含了一些通用的训练辅助工具,如获取可用GPU、计时器类和累加器类。
import torch
import torch.nn as nn
import torch.nn.functional as F
import time
import numpy as np
import utils_for_huitu # 这个是你自己的工具包def try_all_gpus():"""返回所有可用的GPU,如果没有GPU,则返回[cpu(),]"""devices = [torch.device(f'cuda:{i}')for i in range(torch.cuda.device_count())]return devices if devices else [torch.device('cpu')]class Timer:"""记录多次运行时间"""def __init__(self):"""Defined in :numref:`subsec_linear_model`"""self.times = []self.start()def start(self):"""启动计时器"""self.tik = time.time()def stop(self):"""停止计时器并将时间记录在列表中"""self.times.append(time.time() - self.tik)return self.times[-1]def avg(self):"""返回平均时间"""return sum(self.times) / len(self.times)def sum(self):"""返回时间总和"""return sum(self.times)def cumsum(self):"""返回累计时间"""return np.array(self.times).cumsum().tolist()class Accumulator:"""在 n 个变量上累加"""def __init__(self, n):"""初始化 Accumulator 类输入:n: 需要累加的变量数量 # 输入参数:变量数量输出:无返回值 # 方法无显式返回值"""self.data = [0.0] * n # 初始化一个长度为 n 的浮点数列表,初始值为 0.0def add(self, *args):"""向累加器中添加多个值输入:*args: 可变数量的数值,用于累加 # 输入参数:可变参数,表示要累加的值输出:无返回值 # 方法无显式返回值"""self.data = [a + float(b) for a, b in zip(self.data, args)] # 将输入值累加到对应位置的数据上def reset(self):"""重置累加器中的所有值为 0 输入:无 # 方法无输入参数输出:无返回值 # 方法无显式返回值"""self.data = [0.0] * len(self.data) # 重置数据列表,所有值设为 0.0def __getitem__(self, idx):"""获取指定索引处的值 输入:idx: 索引值 # 输入参数:要访问的数据索引输出:float: 指定索引处的值 # 返回指定位置的累加值"""return self.data[idx] # 返回指定索引处的数据值
utils_for_huitu.py
这个文件主要包含了用于绘图和可视化的工具,特别是Animator类,它能够在Jupyter Notebook中动态地绘制训练过程中的损失曲线。
# 导入必要的包
import matplotlib.pyplot as plt # 用于创建和操作 Matplotlib 图表
from matplotlib_inline import backend_inline # 修复导入 (确保Jupyter中SVG正常显示)
from IPython import display # 用于后续动态显示(如 Animator)
import torch # 导入PyTorch库,用于处理张量类型的图像 (虽然在此文件中torch本身未直接用于图像处理,但常与此工具包配合使用)def use_svg_display():"""使用 SVG 格式在 Jupyter 中显示绘图输入:无输出:无返回值定义位置::numref:`sec_calculus`"""backend_inline.set_matplotlib_formats('svg') # 设置 Matplotlib 使用 SVG 格式def set_axes(axes, xlabel, ylabel, xlim, ylim, xscale, yscale, legend):"""设置 Matplotlib 的轴 输入:axes: Matplotlib 的轴对象 # 输入参数:轴对象xlabel: x 轴标签 # 输入参数:x 轴标签ylabel: y 轴标签 # 输入参数:y 轴标签xlim: x 轴范围 # 输入参数:x 轴范围ylim: y 轴范围 # 输入参数:y 轴范围xscale: x 轴刻度类型 # 输入参数:x 轴刻度类型yscale: y 轴刻度类型 # 输入参数:y 轴刻度类型legend: 图例标签列表 # 输入参数:图例标签输出:无返回值 # 函数无显式返回值"""axes.set_xlabel(xlabel) # 设置 x 轴标签axes.set_ylabel(ylabel) # 设置 y 轴标签axes.set_xscale(xscale) # 设置 x 轴刻度类型axes.set_yscale(yscale) # 设置 y 轴刻度类型axes.set_xlim(xlim) # 设置 x 轴范围axes.set_ylim(ylim) # 设置 y 轴范围if legend: # 检查是否提供了图例标签axes.legend(legend) # 如果有图例,则设置图例axes.grid() # 为轴添加网格线class Animator:"""在动画中绘制数据,仅针对一张图的情况"""def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,ylim=None, xscale='linear', yscale='linear',fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,figsize=(3.5, 2.5)):"""初始化 Animator 类 输入:xlabel: x 轴标签,默认为 None # 输入参数:x 轴标签ylabel: y 轴标签,默认为 None # 输入参数:y 轴标签legend: 图例标签列表,默认为 None # 输入参数:图例标签xlim: x 轴范围,默认为 None # 输入参数:x 轴范围ylim: y 轴范围,默认为 None # 输入参数:y 轴范围xscale: x 轴刻度类型,默认为 'linear' # 输入参数:x 轴刻度类型yscale: y 轴刻度类型,默认为 'linear' # 输入参数:y 轴刻度类型fmts: 绘图格式元组,默认为 ('-', 'm--', 'g-.', 'r:') # 输入参数:线条格式nrows: 子图行数,默认为 1 # 输入参数:子图行数ncols: 子图列数,默认为 1 # 输入参数:子图列数figsize: 图像大小元组,默认为 (3.5, 2.5) # 输入参数:图像大小输出:无返回值 # 方法无显式返回值定义位置::numref:`sec_softmax_scratch` # 指明定义的参考位置"""if legend is None: # 检查 legend 是否为 Nonelegend = [] # 如果为 None,则初始化为空列表use_svg_display() # 设置绘图显示为 SVG 格式self.fig, self.axes = plt.subplots(nrows, ncols, figsize=figsize) # 创建绘图对象和子图if nrows * ncols == 1: # 判断是否只有一个子图self.axes = [self.axes, ] # 如果是单个子图,将 axes 转为列表,方便统一处理# config_axes 是一个lambda函数,调用时会配置第一个子图 self.axes[0]self.config_axes = lambda: set_axes(self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)self.X, self.Y, self.fmts = None, None, fmts # 初始化数据和格式属性def add(self, x, y):"""向图表中添加多个数据点 输入:x: x 轴数据点 # 输入参数:x 轴数据y: y 轴数据点 # 输入参数:y 轴数据 (可以是单个值或列表/元组)输出:无返回值 # 方法无显式返回值"""if not hasattr(y, "__len__"): # 检查 y 是否具有长度属性(是否可迭代,如列表或元组)y = [y] # 如果不可迭代(例如单个浮点数),将其转为单元素列表n = len(y) # 获取 y 中包含的曲线数量if not hasattr(x, "__len__"): # 检查 x 是否具有长度属性# 如果 x 是单个值,则为每条曲线都使用这个 x 值x = [x] * nif not self.X: # 检查 self.X 是否已初始化 (第一次调用 add 时)self.X = [[] for _ in range(n)] # 为每条曲线创建空列表存储 x 值if not self.Y: # 检查 self.Y 是否已初始化self.Y = [[] for _ in range(n)] # 为每条曲线创建空列表存储 y 值for i, (a, b) in enumerate(zip(x, y)): # 遍历 x 和 y 的数据对 (a是x值, b是y值)if a is not None and b is not None: # 检查数据点是否有效 (允许传入None来跳过某条线的某个点)self.X[i].append(a) # 将 x 数据点添加到对应曲线的列表self.Y[i].append(b) # 将 y 数据点添加到对应曲线的列表self.axes[0].cla() # 清除当前轴的内容,以便重绘for x_data, y_data, fmt in zip(self.X, self.Y, self.fmts): # 遍历所有曲线的数据和格式self.axes[0].plot(x_data, y_data, fmt) # 绘制每条线self.config_axes() # 调用 lambda 函数配置坐标轴display.display(self.fig) # 显示当前图形display.clear_output(wait=True) # 清除上一次的输出,等待下一次display来刷新,实现动画效果
总结
通过本次Kaggle实战项目,我们从零开始,一步步完成了狗狗品种识别任务。主要流程和关键技术点回顾如下:
- 数据准备:我们学会了如何读取CSV标签,并根据竞赛需求和模型训练的最佳实践,将原始数据整理成结构化的训练集、验证集和测试集目录。
reorg_train_valid和reorg_test函数是这一步的核心。 - 图像增广:利用
torchvision.transforms,我们为训练集设计了一套图像增广策略(随机裁剪、翻转、颜色抖动等),以提高模型的泛化能力;为验证集和测试集则采用了确定性的预处理流程。 - 数据加载:通过
ImageFolder和DataLoader,我们高效地加载了图像数据,并将其组织成适合模型训练的批次。 - 模型微调(迁移学习):我们选择了预训练的ResNet-34模型,冻结了其大部分层,只替换并训练了顶部的分类头。这是一种在数据量相对不足时,利用大型预训练模型知识的有效方法。
get_net函数实现了模型的加载和修改。 - 训练与评估:我们定义了训练循环
train函数,其中包含了损失计算(交叉熵)、优化器(SGD)、学习率调度以及使用Animator进行训练过程的可视化。evaluate_loss函数用于在验证集上评估模型性能。 - 预测与提交:在用全部训练数据重新训练模型后,我们对测试集进行了预测,并将结果(每个类别的概率)保存为Kaggle要求的CSV格式。
这个项目不仅让我们熟悉了PyTorch在图像分类任务中的应用,更重要的是,它展示了一个完整的机器学习项目从数据到结果的pipeline。希望通过这个实战案例,你能对深度学习项目的实践有更深入的理解!