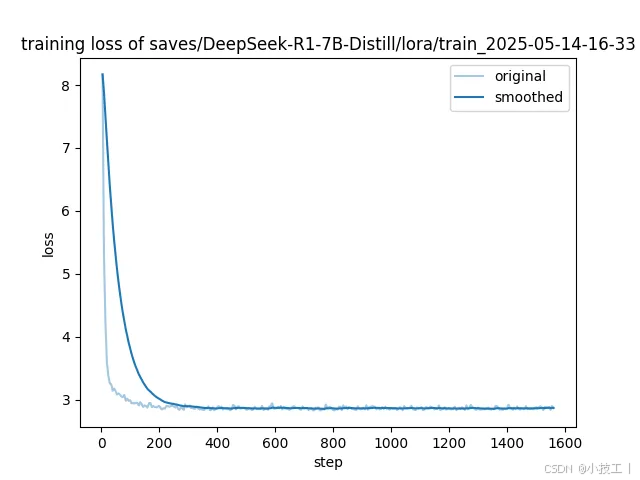
LLaMA-Factory:准备模型和数据集
话接上回《LLaMA-Factory:环境准备》,由于咱用的是 RTX 4090 笔记本的 16GB VRAM 限制,建议选择较小的模型(如 LLaMA 3.1 8B、DeepSeek-R1-Distill-Qwen-7B)并使用量化。
⚠️注意:我没用LLaMA 3.1 8B,因为需要申请,人家META许了你权限,你才能用,我就被拒绝了。
一、下载模型
模型可以从Hugging Face下载或者也可以从魔搭社区modelscope下载。我这里是从Hugging Face(HF)下载的。没错申请LLaMA访问权限也是在这申请被拒的,那咱就用国产的。
直接访问HF需要梯子,但咱可以从hf镜像网站下载(https://hf-mirror.com/)。
0、下载LLaMA模型
LLaMA 模型需要通过 Hugging Face 或 Meta AI 申请访问权限:
-
申请 LLaMA 模型访问权限:https://ai.meta.com/resources/models-and-libraries/llama-downloads/
-
从 Hugging Face 下载量化模型(如 LLaMA 3.1 8B GGUF 格式):
pip install huggingface_hub huggingface-cli download meta-llama/Llama-3.1-8B-Instruct --local-dir ./models/llama-3.1-8b推荐模型: LLaMA 3.1 8B(4-bit 量化,约需 6-8GB VRAM)或 13B(8-bit 量化,约需 12-14GB VRAM)。
》〉》〉》〉》〉如果不顺利可以跳过这部分。〈《〈《〈《〈《
1、下载DeepSeek-R1-Distill-Qwen-7B模型
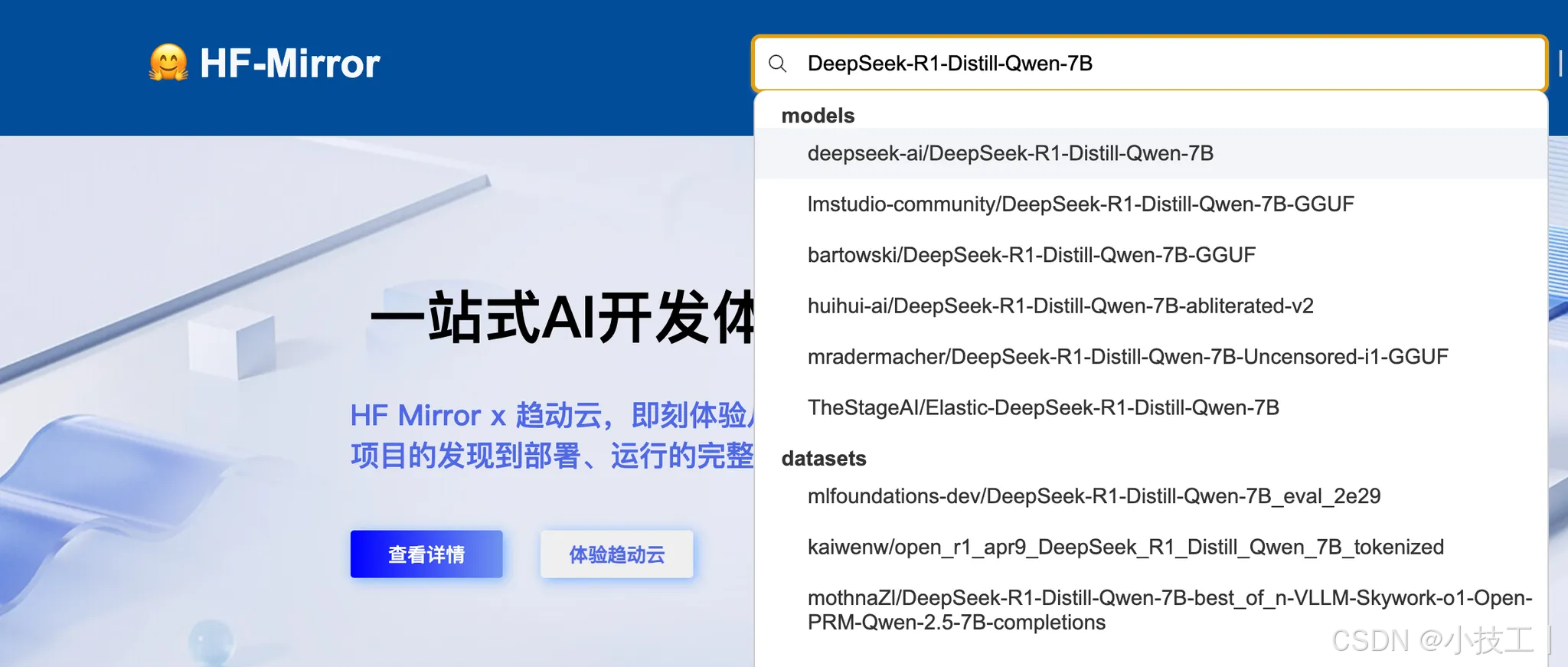
按照提示,先安装lfs,再下载:
# Make sure git-lfs is installed (https://git-lfs.com)
git lfs install
git clone https://hf-mirror.com/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
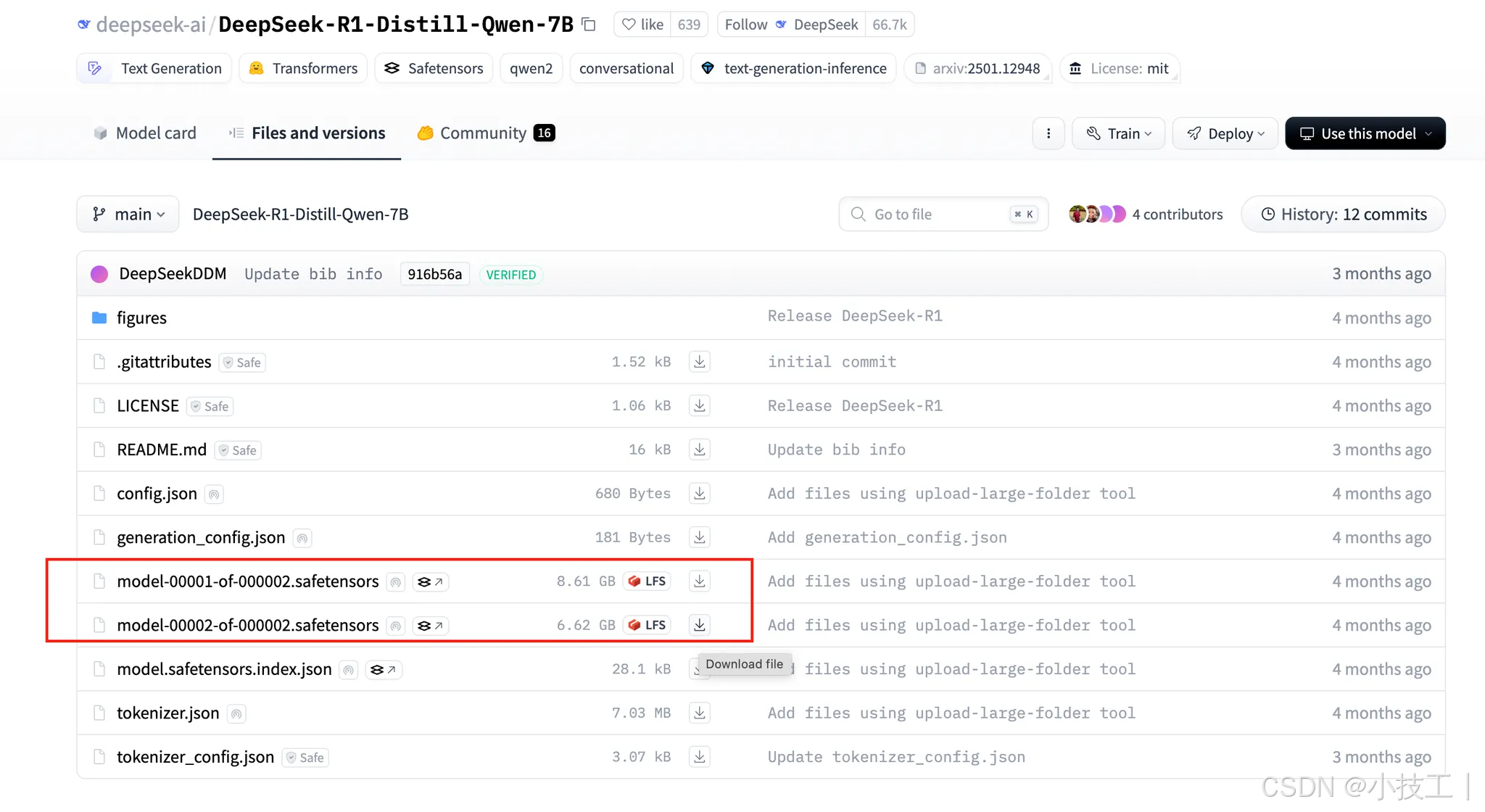
查看文件可以看到safetensors 模型权重文件文件比较大,完整的下载会比较慢,可以通过:
# If you want to clone without large files - just their pointers
GIT_LFS_SKIP_SMUDGE=1 git clone https://hf-mirror.com/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
下载的safetensors文件只有指针信息,但是微调需要完整权重文件,可以把这个指针文件删掉,在目标模型的safetensors文件后,右键点击"Download"复制链接地址,利用aria2来快速下载这些大文件。
先安装aria2
sudo apt install aria2
利用aria2下载safetensors文件
# aria2c -o 保存文件名 文件URL
#下载保存model-00001-of-000002.safetensors
aria2c -o model-00001-of-000002.safetensors https://hf-mirror.com/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B/resolve/main/model-00001-of-000002.safetensors?download=true
#下载保存model-00002-of-000002.safetensors
aria2c -o model-00002-of-000002.safetensors https://hf-mirror.com/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B/resolve/main/model-00002-of-000002.safetensors?download=true
二、准备数据集
也是在HF中下载数据集。或者直接用LLaMA-Factory/data目录下提供的demo数据集。如果自己下载数据集,请务必在 dataset_info.json 文件中添加数据集描述,并通过修改 dataset: 数据集名称 配置来使用数据集。
这是LLaMA-Factory/data目录下README_zh.md文件关于Alpaca 格式-指令监督微调数据集的描述。
Alpaca 格式
指令监督微调数据集
- 样例数据集(alpaca_zh_demo.json)
[{"instruction": "识别并解释给定列表中的两个科学理论:细胞理论和日心说。","input": "","output": "细胞理论是生物科学的一个理论,它认为所有生命体都是由微小的基本单元——细胞所构成。这是生物学的一个基础理论,认为细胞是所有生物的基本结构和功能单位,所有的生物都是由一个或多个细胞组成,细胞只能通过细胞分裂产生新的细胞。这一理论由薛定谔、施瓦内和雪莱于1839年首次提出。\n\n日心说是指太阳是太阳系的中心,也就是说,行星围绕太阳旋转的理论。这个理论打破了传统的地心说观点,认为地球并不是宇宙的中心。日心说的提出者是尼古拉·哥白尼,他在16世纪初发表了他的著作《天体运行论》,阐述了太阳系行星围绕太阳运行的模型,为天文学的发展做出了巨大贡献。"},...
在指令监督微调时,instruction 列对应的内容会与 input 列对应的内容拼接后作为人类指令,即人类指令为 instruction\ninput。而 output 列对应的内容为模型回答。
如果指定,system 列对应的内容将被作为系统提示词。
history 列是由多个字符串二元组构成的列表,分别代表历史消息中每轮对话的指令和回答。注意在指令监督微调时,历史消息中的回答内容也会被用于模型学习。
[{"instruction": "人类指令(必填)","input": "人类输入(选填)","output": "模型回答(必填)","system": "系统提示词(选填)","history": [["第一轮指令(选填)", "第一轮回答(选填)"],["第二轮指令(选填)", "第二轮回答(选填)"]]}
]
对于上述格式的数据,dataset_info.json 中的数据集描述应为:
"数据集名称": {"file_name": "data.json","columns": {"prompt": "instruction","query": "input","response": "output","system": "system","history": "history"}
}
预训练数据集
- 样例数据集(c4_demo.jsonl)
{"text": "Don’t think you need all the bells and whistles? No problem. McKinley Heating Service Experts Heating & Air Conditioning offers basic air cleaners that work to improve the quality of the air in your home without breaking the bank. It is a low-cost solution that will ensure you and your family are living comfortably.\nIt’s a good idea to understand the efficiency rate of the filters, which measures what size of molecules can get through the filter. Basic air cleaners can filter some of the dust, dander and pollen that need to be removed. They are 85% efficient, and usually have a 6-inch cleaning surface.\nBasic air cleaners are not too expensive and do the job well. If you do want to hear more about upgrading from a basic air cleaner, let the NATE-certified experts at McKinley Heating Service Experts in Edmonton talk to you about their selection.\nEither way, now’s a perfect time to enhance and protect the indoor air quality in your home, for you and your loved ones.\nIf you want expert advice and quality service in Edmonton, give McKinley Heating Service Experts a call at 780-800-7092 to get your questions or concerns related to your HVAC system addressed."}
{"text": ...
在预训练时,只有 text 列中的内容会用于模型学习。
[{"text": "document"},{"text": "document"}
]
对于上述格式的数据,dataset_info.json 中的数据集描述应为:
"数据集名称": {"file_name": "data.json","columns": {"prompt": "text"}
}
至此数据集和模型都准备好了。
三、使用webUI
web ui中的path,比如Model path路径是基于LLaMA-Factory相对路径。
比如Model path:

选择模型、数据集就可以开始训练了。训练结果在saves目录下。