nn.Module 与 nn.functional
在PyTorch中,torch.nn.Module 和 torch.nn.functional 通常一起使用来定义神经网络模型
-
torch.nn.Module主要用于定义可学习的模型参数和组织神经网络的结构 -
torch.nn.functional提供了一系列的函数,这些函数可以用于构建前向传播的各个组件,但它们不包含可学习的参数。
1. torch.nn.functional
torch.nn.functional模块包含了一系列的函数,这些函数不包含可学习的参数。它们是纯函数,只处理输入数据并返回输出。- 这个模块中的函数可以用于构建自定义网络的前向传播操作,但是不同于
torch.nn.Module,torch.nn.functional中的函数没有可学习参数(parameters) - 通常
torch.nn.functional中的函数被用于在torch.nn.Module的前向传播方法中执行一些非学习的操作,例如激活函数、池化等。
1)以 torch.nn.functional.linear 举例
output = torch.nn.functional.linear(input, weight, bias=None)-
input:输入张量,形状为
(N, in_features) -
weight:权重矩阵,形状为
(out_features, in_features) -
bias:偏置向量,形状为
(out_features)。 如果不提供偏置,可以将此参数设为None。
2)使用举例
import torch
import torch.nn.functional as Ftorch.manual_seed(11)
output = F.linear(torch.rand(1, 10), weight=torch.rand(5, 10))
print(output) # tensor([[2.8882, 2.9767, 2.3277, 2.3751, 2.8311]])-
weight 为必填参数,为不可学习参数,需要人为指定 对应尺寸的确定值。
-
bias 为选填值,为不可学习参数,需要人为指定 对应尺寸的确定值。
3)内部实现
import torchdef linear(input, weight, bias=None):if input.dim() == 2 and bias is not None:# 使用torch.addmm()函数实现矩阵相乘和加法return torch.addmm(bias, input, weight.t())output = input.matmul(weight.t())if bias is not None:# 使用torch.add()函数实现加法output += biasreturn output2.torch.nn.Module
torch.nn.Module类是 PyTorch 中构建神经网络模型的基类,具有如下功能与特点:
参数管理:
torch.nn.Module提供了方便的方法来管理模型中的可学习参数。模型中的每个可学习的参数都是torch.nn.Parameter对象,并且这些参数在模型的parameters()方法中进行追踪。这样,优化器就能够找到所有需要更新的参数。子模块组织:
torch.nn.Module支持嵌套的子模块,这使得模型可以被分解成更小的、可管理的组件。子模块可以通过self.add_module()方法添加,这样它们的参数也会被正确地注册。前向传播定义: 在
torch.nn.Module的子类中,可以通过实现forward方法来定义模型的前向传播逻辑。这种明确的前向传播定义使得 PyTorch 能够自动构建计算图状态管理:
torch.nn.Module能够跟踪模型的状态,例如模型是否处于训练模式(model.train())或评估模式(model.eval())。这对于某些层来说尤为重要(例如Dropout层、BatchNorm层)模型保存和加载:
torch.nn.Module提供了方便的方法来保存和加载整个模型或其部分。这对于在训练期间保存模型、迁移学习以及模型的部署都是重要的。
-
torch.nn模块提供的Module类,是PyTorch中构建神经网络模型的基类 -
torch.nn.Module类提供了一种方便的方式来组织和管理模型的参数 -
用户可以通过继承
torch.nn.Module来创建自定义的神经网络模型。 支持将层(layers)、激活函数等组件构建成计算图 ,然后 通过 forward 方法 实现前向传播,在反向传播的时候,也可以自动的帮我们去 更新相关的参数
1)内部实现
class Linear(Module):__constants__ = ['in_features', 'out_features']in_features: intout_features: intweight: Tensordef __init__(self, in_features: int, out_features: int, bias: bool = True,device=None, dtype=None) -> None:factory_kwargs = {'device': device, 'dtype': dtype}super().__init__()self.in_features = in_featuresself.out_features = out_featuresself.weight = Parameter(torch.empty((out_features, in_features), **factory_kwargs))if bias:self.bias = Parameter(torch.empty(out_features, **factory_kwargs))else:self.register_parameter('bias', None)self.reset_parameters()def reset_parameters(self) -> None:init.kaiming_uniform_(self.weight, a=math.sqrt(5))if self.bias is not None:fan_in, _ = init._calculate_fan_in_and_fan_out(self.weight)bound = 1 / math.sqrt(fan_in) if fan_in > 0 else 0init.uniform_(self.bias, -bound, bound)def forward(self, input: Tensor) -> Tensor:return F.linear(input, self.weight, self.bias)def extra_repr(self) -> str:return 'in_features={}, out_features={}, bias={}'.format(self.in_features, self.out_features, self.bias is not None)2)使用举例
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchinfoclass MyModel(nn.Module):def __init__(self):super(MyModel, self).__init__()self.fc = nn.Linear(10, 5)self.relu = nn.ReLU()def forward(self, x):x = self.fc(x)x = self.relu(x)x = F.linear(x, torch.rand(3, 5))return xnet = MyModel()
print(net)torchinfo.summary(net, (1, 10))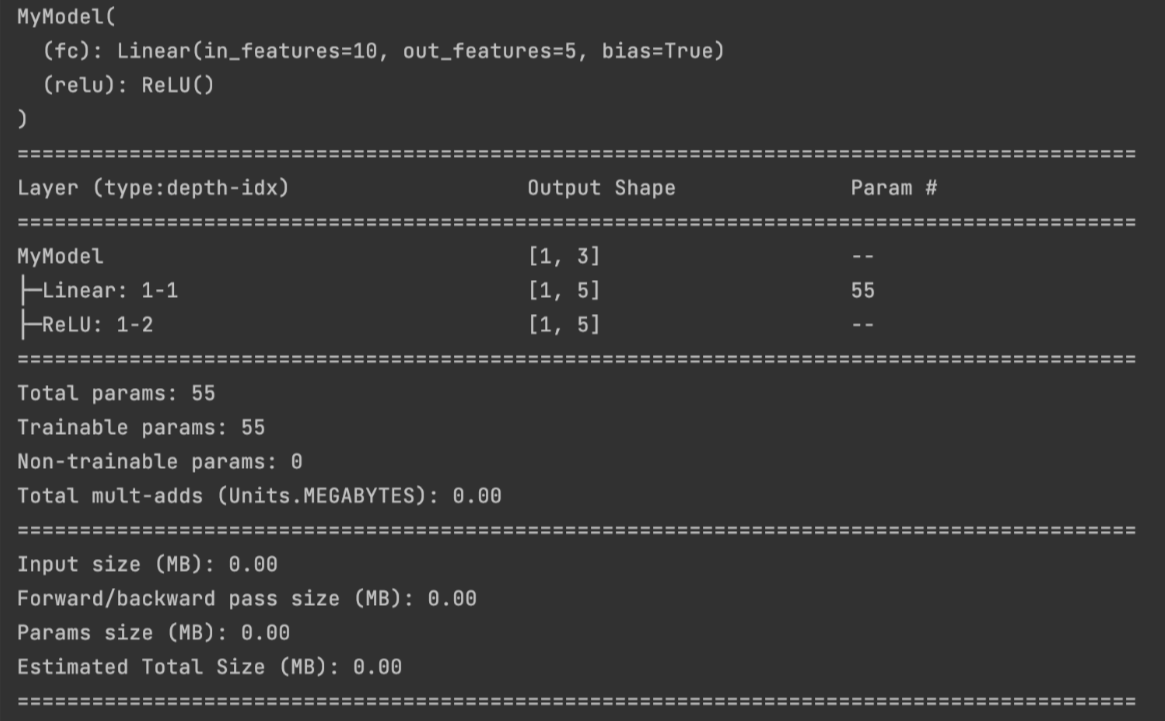
但是在当你 打印模型 的时候,只能打印出 模型初始化函数中定义的层, 这是因为打印模型实际上是 nn.Module 类的repr方法的输出,该方法默认打印模型类的结构(也就是在初始化函数中定义的类似 nn.Linear 的类)。F.linear(x) 不是类,它只是一个函数,所以无法被打印出。
对于像类似 ReLU 激活函数这种本身没有参数的操作,使用torch.nn.functional.relu(x) 和 torch.nn.ReLU 的效果是一样的。这两者的选择通常取决于个人偏好。但建议还是使用 torch.nn.ReLU,因为在直接 print 网络的时候,可以打印出来,进行观察