世界模型+大模型+自动驾驶 论文小汇总
最近看了一些论文,懒得一个个写博客了,直接汇总起来
文章目录
- 大模型
- VLM-AD
- VLM-E2E
- OpenDriveVLA
- FASIONAD:自适应反馈的类人自动驾驶中快速和慢速思维融合系统
- 快系统
- 慢系统
- 快慢结合
- 世界模型
- End-to-End Driving with Online Trajectory Evaluation via BEV World Model
大模型
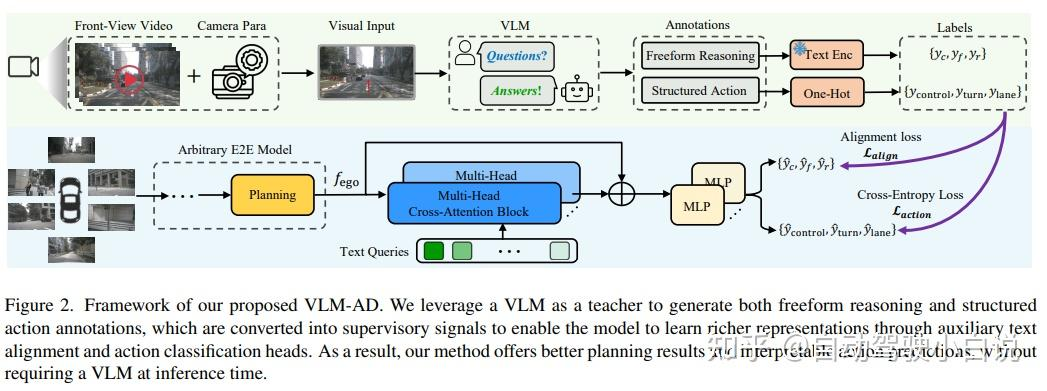
VLM-AD
用大模型做E2E的监督
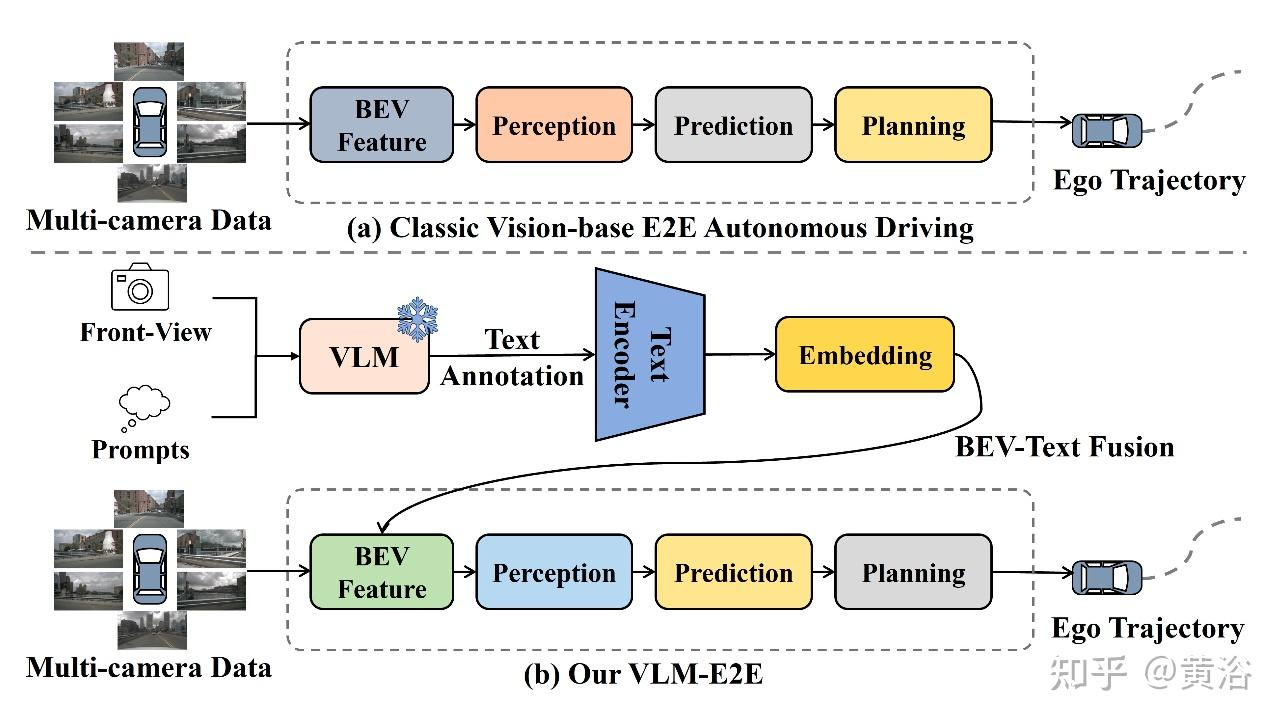
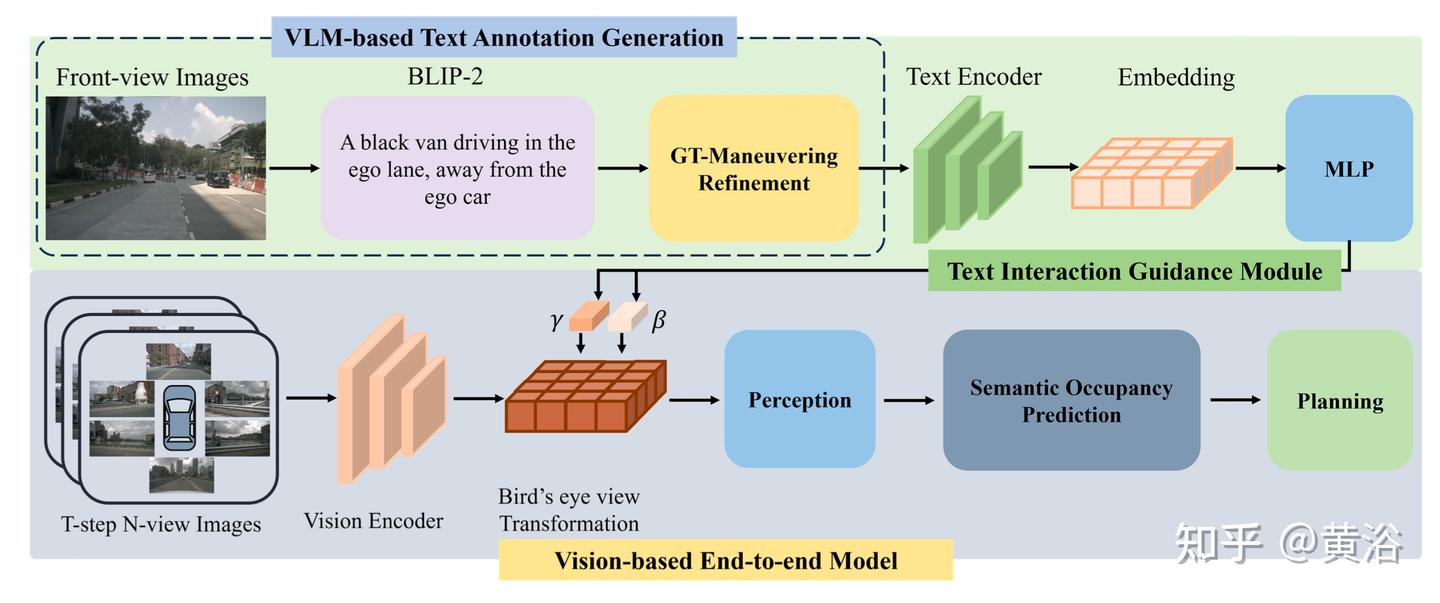
VLM-E2E
VLM-E2E:通过多模态驾驶员注意融合增强端到端自动驾驶 - 黄浴的文章 - 知乎
https://zhuanlan.zhihu.com/p/27467075299
利用大模型增强BEV的信息
也是我的思路
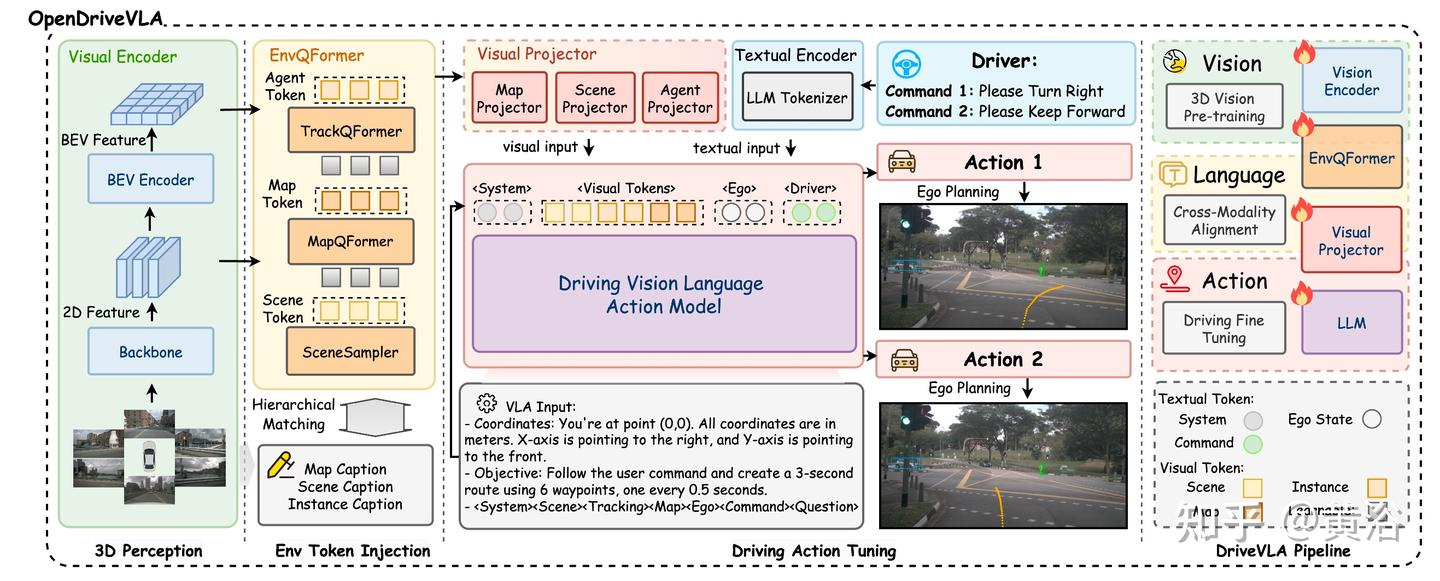
OpenDriveVLA
OpenDriveVLA 以预训练的视觉编码器开始,该编码器从多视图图像中提取 token 化的环境表示。然后通过跨模态学习将这些视觉 token 对齐到文本域中。对齐后,OpenDriveVLA 进行驾驶指令调整,然后进行智体-自我-环境的交互建模。最后,OpenDriveVLA 进行端到端训练,以预测自车的未来轨迹,由对齐的视觉-语言 token 和驾驶指令引导。
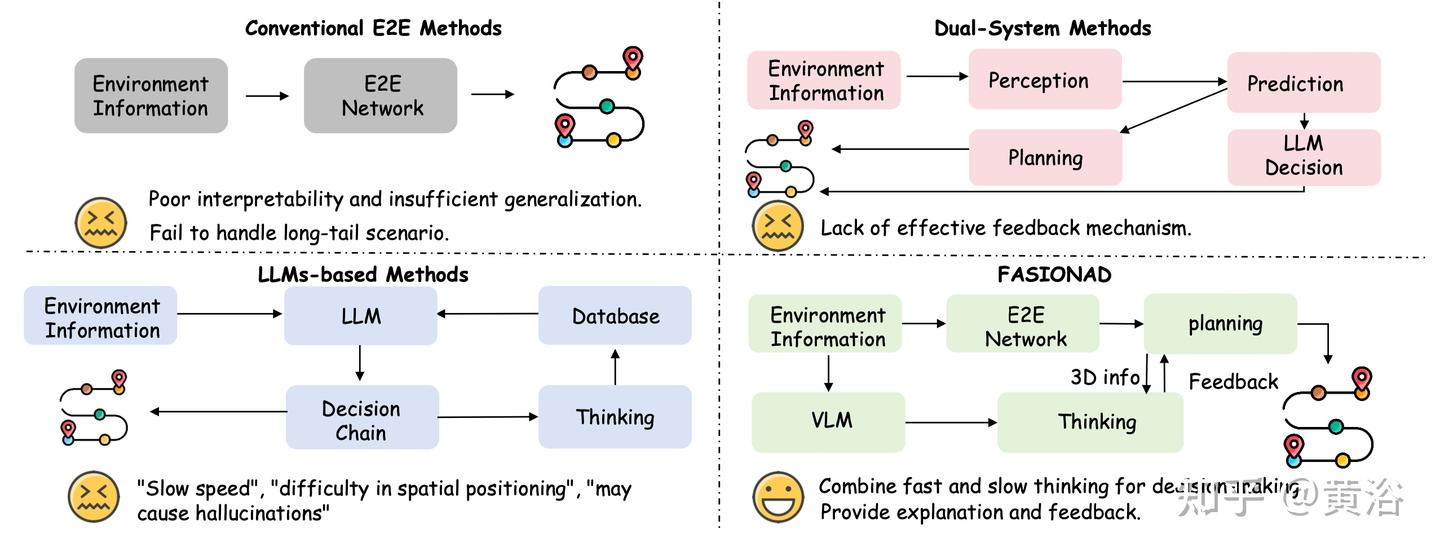
FASIONAD:自适应反馈的类人自动驾驶中快速和慢速思维融合系统
FASIONAD:自适应反馈的类人自动驾驶中快速和慢速思维融合系统 - 黄浴的文章 - 知乎
https://zhuanlan.zhihu.com/p/26228280907
快慢系统
FASIONAD 的动机:传统的 E2E 方法在可解释性和泛化方面存在困难,基于 LLM 的方法面临决策速度慢、空间定位问题和潜在的幻觉。双-系统流水线 [51] 使用 LLM 来融合规划,但缺乏安全反馈机制。如图比较不同的自动驾驶运动规划方法,展示该方法能够自适应上下文-觉察决策,提供更好的解释和反馈
FASIONAD 框架采用双-路径架构:快速路径用于快速实时响应,慢速路径用于在不确定或具有挑战性的驾驶场景中进行全面分析和复杂决策
快速路径:(图像,导航)->路点轨迹
慢速路径:(图像)->(规划状态,高级元动作),为复杂场景中的决策提供更详细的评估和战略指导
为了协调快速路径和慢速路径,引入基于不确定性的航点预测和轨迹奖励。该机制根据环境背景和复杂性动态,激活任一路径,优化响应性与准确性,从而在需要时实现即时反应和彻底分析
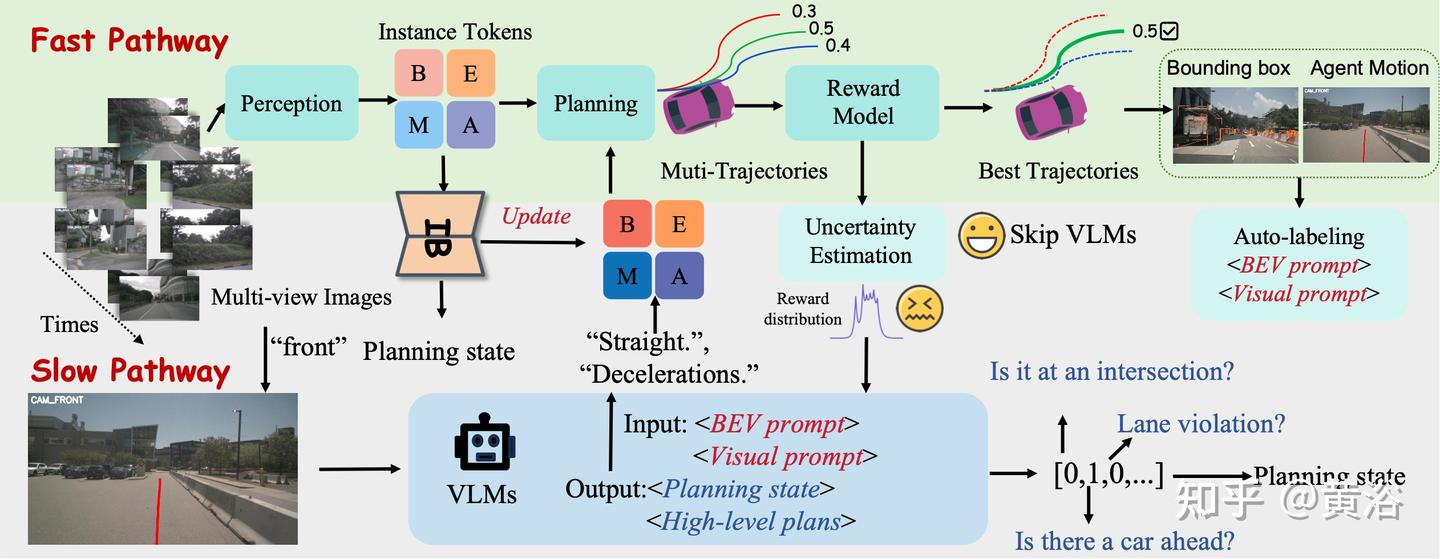
快系统
e2e+输出多条路径+奖励模型选择最佳路径+损失函数(规划损失 L_plan、辅助 3D 检测损失 L_det 和地图分割损失 L_seg 组成)
慢系统
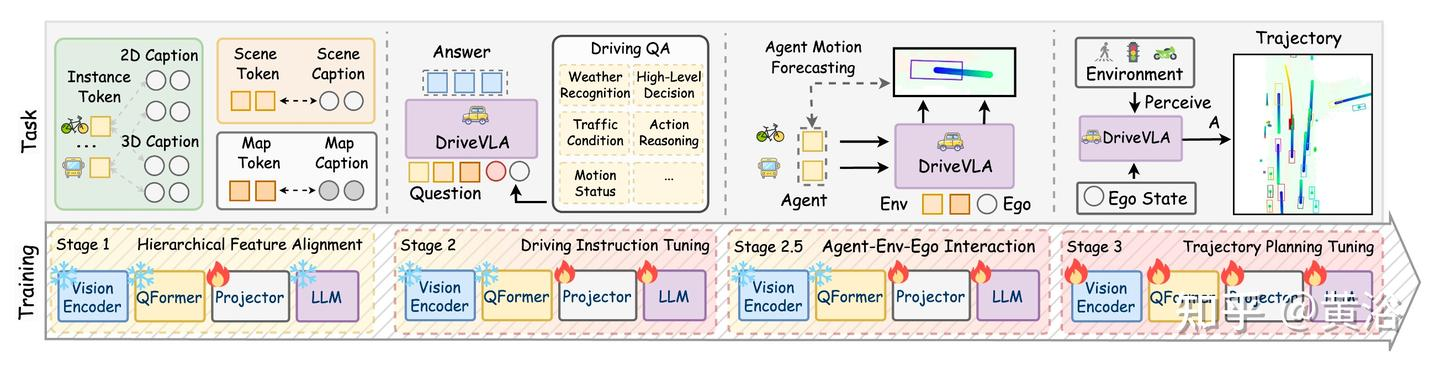
提出一系列面向决策的问答 (QA) 任务,以促进自动驾驶系统中的类人推理。如图说明 QA 问题的类型。
给VLM输入预测轨迹和bev特征,然后利用一系列面向决策的问答(QA)任务,来让大模型最终输出Planning State(规划状态)和High-level plans(高级计划)
规划状态表示为二进制向量,通过 “是 / 否” 决策流程确定
提出高级计划编码器(E_A),将 VLM 的高级决策转换为元动作特征(A_t)
最后,规划状态和元动作特征输入到快速路径以重新生成轨迹,提供类似人类决策的反馈。(相当于把大模型的结果和原本e2e的结果融合重新生成路径)
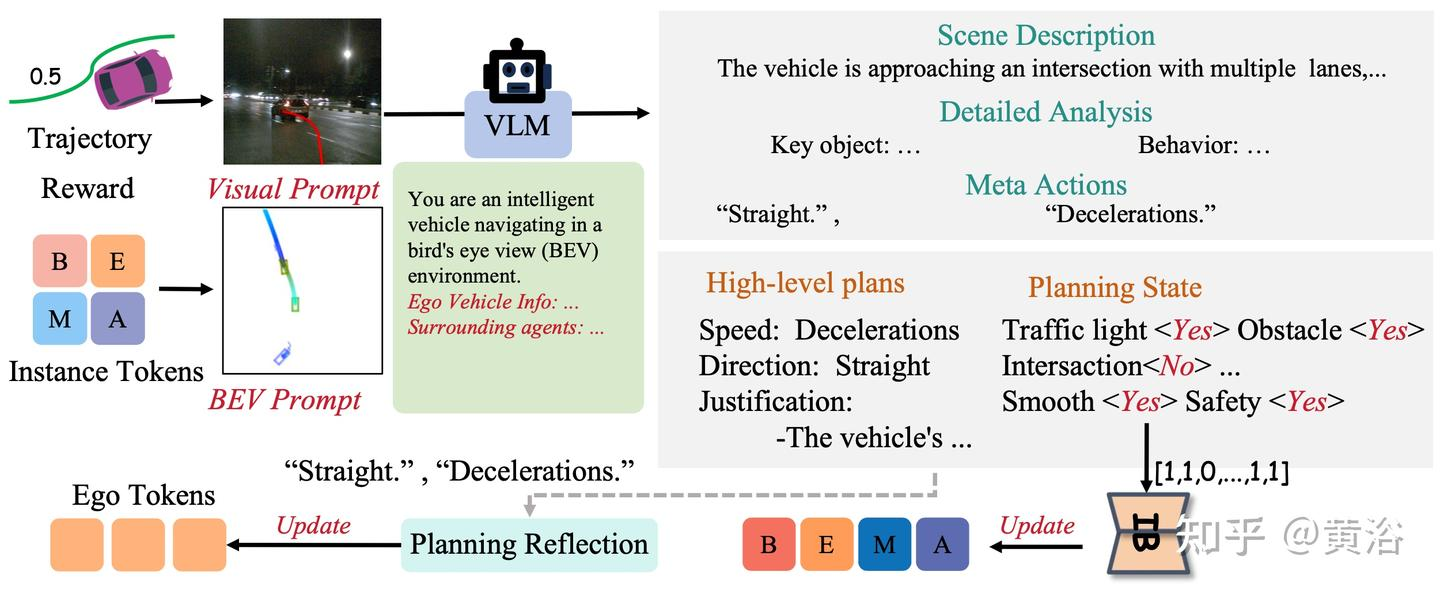
快慢结合
当快速系统生成的轨迹奖励分数(综合安全、舒适、效率)超过预设阈值,且预测不确定性(基于拉普拉斯分布估计)较低时,直接采用快速系统输出s
奖励值低或不确定性高,需要高层级推理的场景时,激活慢速系统辅助推理,融合慢速系统反馈,调整轨迹
世界模型
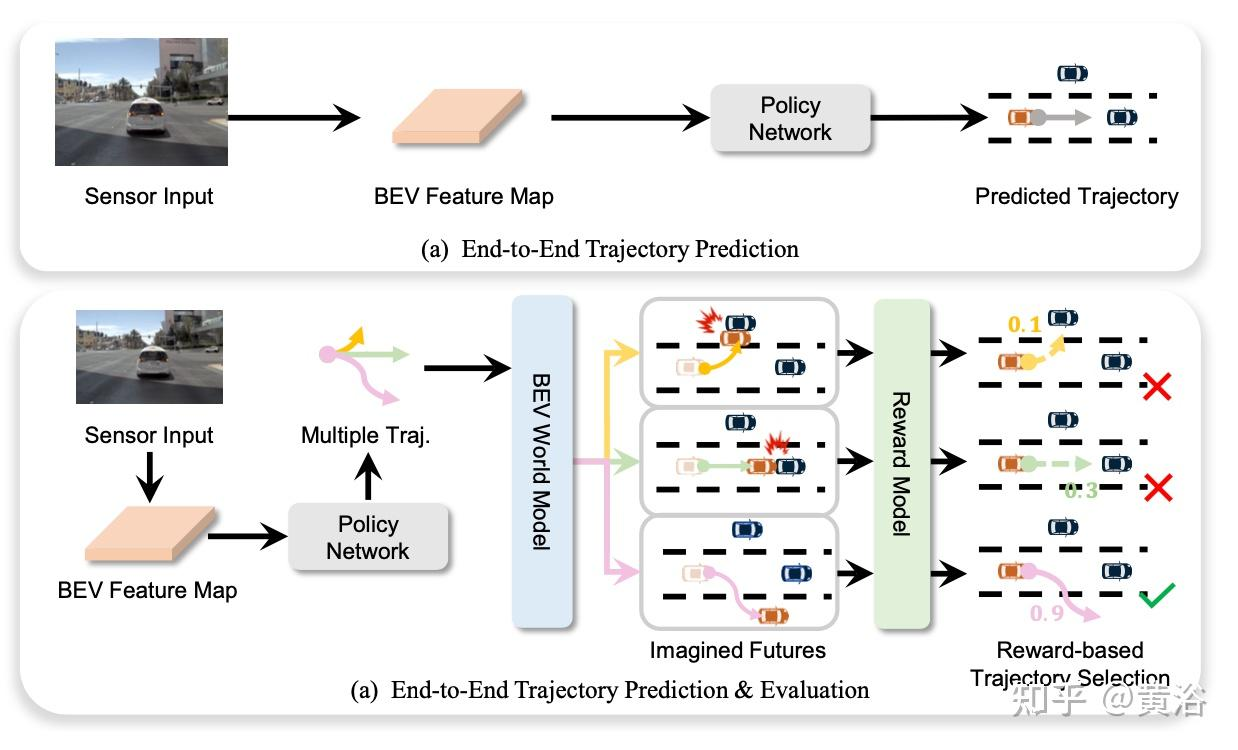
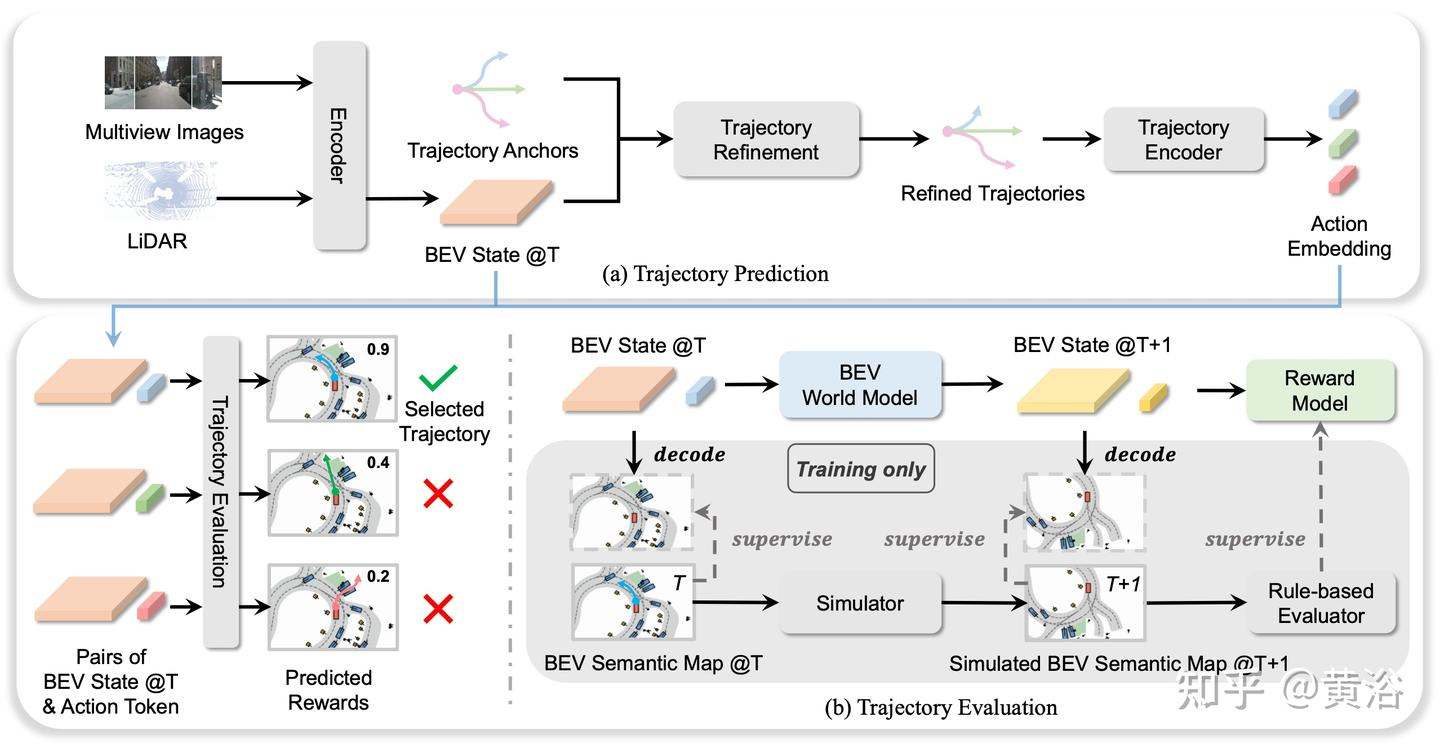
End-to-End Driving with Online Trajectory Evaluation via BEV World Model
e2e预测多个轨迹,然后利用世界模型进行模拟,选出奖励分最高的轨迹
提出一个端到端驾驶框架 WoTE,它利用 BEV 世界模型来预测未来的 BEV 状态以进行轨迹评估。与图像级世界模型相比,所提出的 BEV 世界模型具有延迟效率,并且可以使用现成的 BEV 空间交通模拟器进行无缝监督