双向循环神经网络(Bi-RNN)详解
双向循环神经网络(Bidirectional Recurrent Neural Network, Bi-RNN)是一种能够同时利用序列数据过去和未来信息的循环神经网络架构,在许多序列建模任务中表现出色。
1. Bi-RNN基本概念
1.1 核心思想
Bi-RNN通过组合两个独立的RNN层来工作:
- 前向RNN:按时间正序处理输入序列(从t=1到t=T)
- 反向RNN:按时间逆序处理输入序列(从t=T到t=1)
1.2 基本结构
输入序列 → [前向RNN] → 前向隐藏状态→ [反向RNN] → 反向隐藏状态→ 合并层(连接/求和/平均等) → 输出
2. Bi-RNN的数学表达
对于时间步t:
- 前向传播:
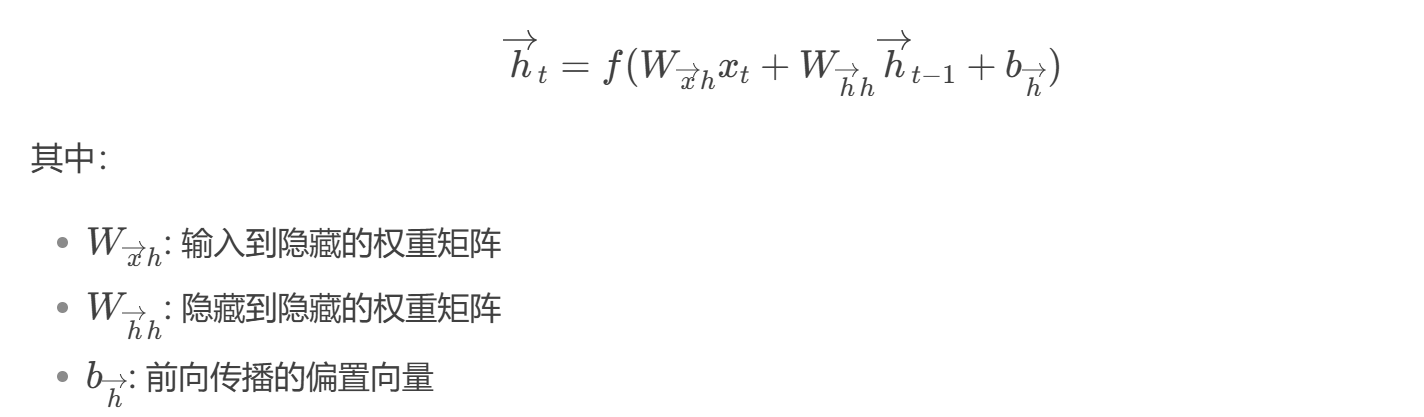
- 反向传播:

- 输出合并:
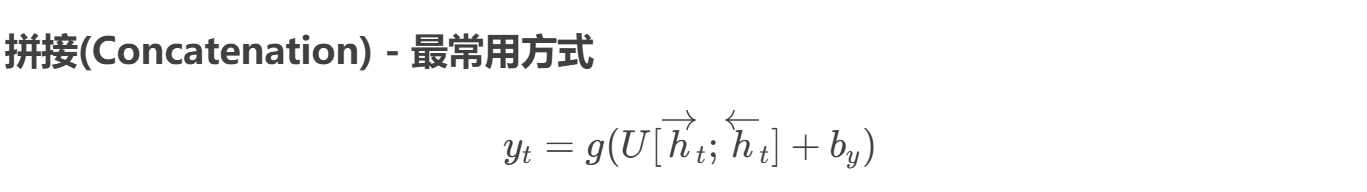
3. Bi-RNN的常见变体
3.1 基础变体
- Bi-SimpleRNN:使用标准RNN单元
- Bi-LSTM:使用LSTM单元
- Bi-GRU:使用GRU单元
3.2 扩展变体
- 多层Bi-RNN:堆叠多个双向层
- 注意力Bi-RNN:结合注意力机制
- CNN-BiRNN:先用CNN提取局部特征,再用Bi-RNN处理
4. Bi-RNN的优势
- 上下文感知:同时利用过去和未来的上下文信息
- 信息更全面:克服了传统RNN只能看到历史信息的局限
- 性能提升:在多数序列任务中优于单向RNN
- 灵活性:可与各种RNN单元(LSTM/GRU等)结合使用
5. Bi-RNN的局限性
- 计算成本:是单向RNN的两倍
- 在线学习限制:不能用于实时流式预测(需要完整序列)
- 内存消耗:需要存储两个方向的中间状态
- 训练复杂度:梯度传播路径更长
6. Bi-RNN的应用场景
-
自然语言处理:
- 命名实体识别
- 机器翻译
- 文本分类
- 情感分析
-
语音处理:
- 语音识别
- 语音合成
-
生物信息学:
- 蛋白质结构预测
- DNA序列分析
-
时间序列分析:
- 股票预测
- 传感器数据分析
7. Bi-RNN的PyTorch实现
import torch
import torch.nn as nnclass BiRNN(nn.Module):def __init__(self, input_size, hidden_size, num_layers, output_size):super(BiRNN, self).__init__()self.hidden_size = hidden_sizeself.num_layers = num_layers# 双向GRU示例(bidirectional=True)self.rnn = nn.GRU(input_size, hidden_size, num_layers, batch_first=True, bidirectional=True)self.fc = nn.Linear(hidden_size*2, output_size) # 双向需要乘以2def forward(self, x):# 初始化隐藏状态h0 = torch.zeros(self.num_layers*2, x.size(0), self.hidden_size).to(x.device)# 前向传播out, _ = self.rnn(x, h0)# 取最后一个时间步的输出(双向拼接)out = self.fc(out[:, -1, :])return out
8. Bi-RNN与Attention的结合
现代架构常将Bi-RNN与注意力机制结合:
class BiRNN_Attention(nn.Module):def __init__(self, input_size, hidden_size, output_size):super().__init__()self.birnn = nn.GRU(input_size, hidden_size, bidirectional=True)self.attention = nn.Linear(hidden_size*2, 1)self.fc = nn.Linear(hidden_size*2, output_size)def forward(self, x):outputs, _ = self.birnn(x) # [seq_len, batch, hid_dim*2]# 计算注意力权重attention_weights = torch.softmax(self.attention(outputs).squeeze(2), dim=0)# 应用注意力权重context = torch.sum(outputs * attention_weights.unsqueeze(2), dim=0)return self.fc(context)
9. 训练Bi-RNN的技巧
- 梯度裁剪:防止梯度爆炸
- 合适的初始化:如正交初始化RNN权重
- 批量归一化:在RNN层间添加BatchNorm
- 学习率调度:使用学习率衰减策略
- 正则化:Dropout(注意RNN的dropout实现方式)
Bi-RNN通过利用双向上下文信息,在多数序列建模任务中都能带来显著提升,特别是在需要全面理解上下文的任务(如实体识别、机器翻译等)中表现尤为突出。