无需大规模重训练!GraspCorrect:VLM赋能机器人抓取校正,抓取成功率提升18.3%
导读
尽管机器人控制技术已取得显著进展,但实现稳定可靠的抓取操作仍是一个核心难题,这一问题直接影响了机器人在执行复杂任务时的可靠性。即便是当前最先进的策略模型,仍存在明显的抓取失稳现象,这些已成为制约机器人技术实际应用的瓶颈。
©️【深蓝AI】编译
论文题目:GraspCorrect: Robotic Grasp Correction via Vision-Language Model-Guided Feedback
论文作者:Sungjae Lee, Yeonjoo Hong, Kwang In Kim
论文地址:https://arxiv.org/pdf/2503.15035
针对上述挑战,这篇研究提出GraspCorrect创新解决方案——一种基于视觉语言模型(Vision-Language Model, VLM)反馈机制的即插即用式性能增强模块。通过迭代生成渐进式视觉目标,并转化为关节空间运动轨迹,GraspCorrect在RLBench与CALVIN基准测试中展现出显著优势:不仅有效提升现有策略模型的抓取稳定性,更使综合任务成功率获得系统性提升。该方法创新性地实现了语义安全机制与物理约束建模的多维度融合,为机器人操控系统的可靠性增强提供了新范式。
引言
机器人操作是一项涉及多方面的复杂任务,需要实现环境感知、动作规划与关节驱动技术的无缝协同8。无论是抓取精致的酒杯、执行复杂的显微外科手术,还是组装精密电子元件,机器人都必须具备精准且适应性强的控制能力,才能有效应对不同物体和环境的多样化需求。
深度学习技术的突破性进展正推动机器人操作领域实现革命性跨越,催生出多样化且高度复杂的智能策略体系。例如,R3M模型通过利用人类视频数据进行视觉表征预训练,为海量机器人交互数据收集提供了一种经济高效的替代方案。然而,该系统在空间操作任务中的精度受限,主要源于其缺乏显式的三维几何推理能力69。为突破这一瓶颈,PerAct创新性地将三维体素块融入Transformer架构,显著增强了空间认知能力。值得关注的是,Ke等人最新提出的三维扩散执行器(3D Diffuser Actor),通过融合扩散策略与三维场景表征,实现了机器人状态条件动作分布空间的直接学习,在多项操作任务中刷新了性能记录。
尽管技术不断进步,但核心问题依然存在:操控难题真的被彻底攻克了吗?研究结果给出了否定答案。即便如3D扩散执行器这类顶尖模型,在关键任务中的表现也远未达到理想水平。具体而言,在RLBench测试平台中,积木堆叠(68.3%)、插钉入孔(65.6%)和形状分类(44.0%)等场景下的任务成功率,仍显著低于80%的基准线。
在完成各类复杂操作任务时,稳定可靠的抓取能力始终是成功实现精准操控的底层基石。研究发现,抓取动作的不稳定性正是制约任务表现的持续性瓶颈。为验证这一观点,研究人员设计了一项对比实验:在前序动作中预设稳定抓取轨迹直至抓取临界点,仅由策略模型自主规划后续操作。实验数据显示,该方法使任务成功率最高提升26.4个百分点(图1),成效显著。
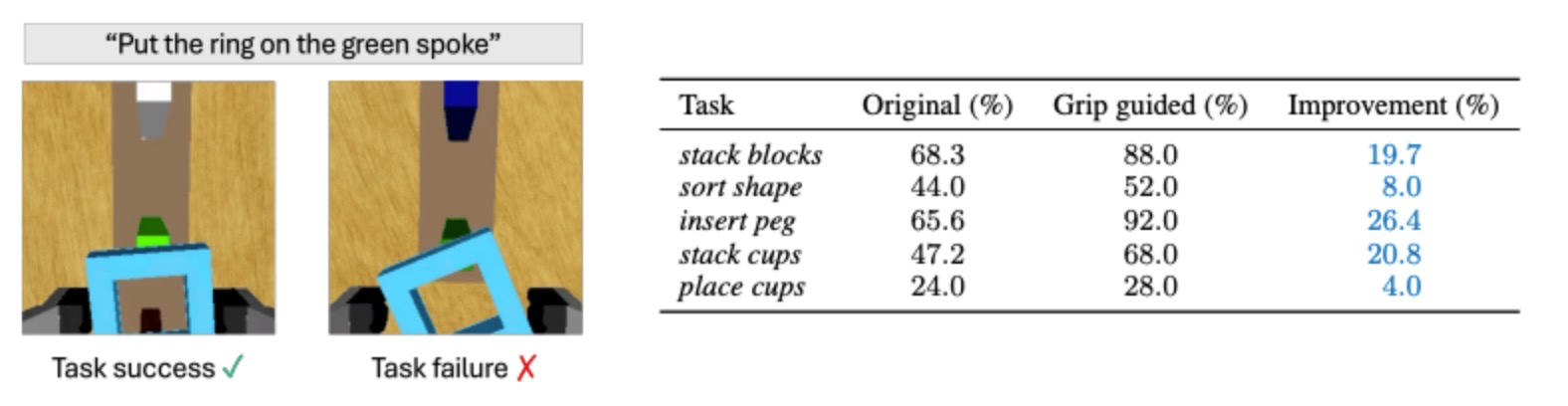
图片 1 精准抓取动作的重要性:左图展示了RLBench插桩任务中成功与失败的案例对比,右图则呈现了RLBench高难度任务中的性能提升情况。通过复现直至抓取点的稳定抓取位姿,我们观察到任务成功率(%)的显著提升。这一初步实验结果有力印证了稳健抓取机制对端到端机器人策略模型整体性能的重要影响。
针对上述技术瓶颈,学界主要形成了两条攻关路径。其一旨在构建覆盖多维度参数的机器人示范数据集,囊括物体属性、抓取形态及环境变量等要素。但该方案存在显著局限性:不仅需要耗费大量算力进行模型重训练,其应用边界更受限于数据集覆盖范围。另一路径则依托GraspNet和Contact-GraspNet等预训练抓取基模型,这类模型可直接基于三维点云生成高效抓取姿态分布。尽管在高密度点云场景表现优异,但面对经济型稀疏三维表征时性能明显衰减。更关键的是,其强依赖于训练阶段的场景学习特性,导致模型难以泛化至未见过的物体类别与任务形态。
视觉语言模型(VLM)的零样本学习能力带来了新的突破,这类模型凭借卓越的场景解构、逻辑推理及语义生成优势,正在重塑机器人操控范式。最新实证研究显示,VLM在复杂操作任务与长周期规划场景中展现出独特价值。通过海量跨模态数据预训练,VLM具备跨领域适应能力,为实现稳健的泛化性能提供了新可能。
通过深度解析视觉语境并智能生成抓取校正方案,研究人员开创性地将VLM融入抓取校正体系,在不依赖大规模数据重训练的前提下实现性能跃升。基于此,研究人员自主研发了GraspCorrect一个即插即用模块——该创新组件专为提升机器人操作策略中的抓取可靠性设计,其核心技术架构包含三阶段处理流程:(1)基于VLM的多模态引导机制,综合语义与几何特征精准定位稳定抓取位姿;(2)通过图像合成技术生成目标状态图像,将VLM的语义理解转化为可执行的视觉目标;(3)目标导向行为克隆算法(Goal-Conditioned Behavioral Cloning, GCBC)将这些视觉目标解码为关节级控制指令,确保抓取动作的毫米级精准执行。
GraspCorrect采用不依赖于模型架构的创新设计,可与各类操作策略实现即插即用式融合。该模块在不破坏原有系统核心功能、无需额外训练开销的前提下,通过抓取动作的智能优化显著提升可靠性。其核心价值体现在关键抓取阶段的实时校正预测能力,最终达成机器人操作精度的突破性提升,创下该领域性能新标杆。
机器人抓取修正架构
假设考虑一个机器人控制学习的场景,其中策略模型从一条带有文本指令的轨迹示例中进行学习,每个时间步t的观测是由RGB-D图像构成,以及每个action
策略模型旨在学习一种映射关系,能够根据当前观测状态预测出合适的动作
。GraspCorrect作为现有策略模型的即插即用模块,会在夹持器接触目标物体(由指令l指定)的抓取时刻t(g)激活。该模块通过分析当前抓取数据对(ot(g), at(g))和时间窗口W内的预抓取观测
![]() (详见后文),预测出优化的末端执行器抓取位姿a'o,从而提升抓取操作的执行效果。
(详见后文),预测出优化的末端执行器抓取位姿a'o,从而提升抓取操作的执行效果。
GraspCorrect模块通过三个阶段实现抓取校正(如图2所示)。首先在(VLM引导的)抓取检测阶段,该模块基于视觉语言模型的感知能力识别稳定抓取位点;随后在(视觉)目标生成阶段,将抓取目标转化为图像形式的视觉表征;最后通过动作生成阶段,将视觉目标解析为精准的关节级控制指令。
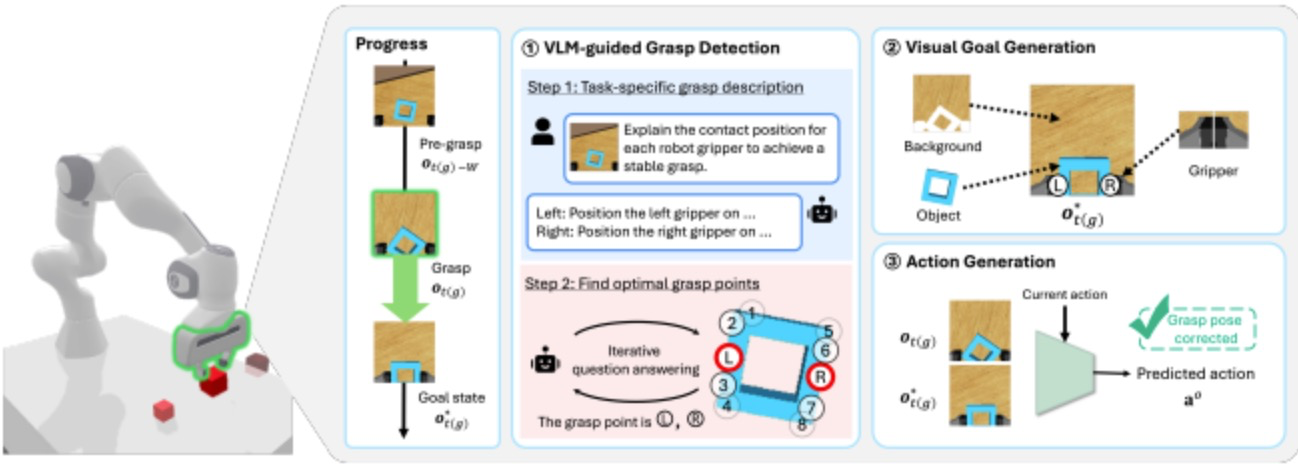
图片 2 GraspCorrect流程全景解析:该模块通过确立稳定抓取这一关键里程碑,显著提升机器人操作性能。在抓取检测阶段,依托任务定制的视觉语言模型(VLM)引导,通过迭代式问答过程预测理想夹爪位姿;随后在视觉目标生成阶段,采用图像合成技术生成表征理想抓取状态的目标图像;最终通过动作生成阶段预测并执行校正动作,从而提升抓取可靠性。
VLM引导的抓取检测方法
本阶段将当前观测数据与任务描述l转化为任务导向的机械夹爪接触点
,以实现稳定抓取。该过程借助视觉语言模型(VLM),将抓取定位问题构建为空间视觉问答(VQA)任务——相较于传统VQA任务(如识别物体或属性,例如"汽车是什么颜色?"),此类空间VQA任务新增了空间推理能力,例如判断机器人应在物体的哪个位置施力才能实现稳定抓举。
预训练视觉语言模型(VLM)为此任务提供了丰富的常识知识宝库,然而将其直接应用于空间推理时仍面临两大挑战。首先,VLM主要针对文本输出进行优化,难以直接生成坐标值或动作参数等连续数值。其次,即便是最先进的VLM模型,在处理复杂空间推理任务时仍存在显著局限性。
为突破这些限制,研究人员采用了迭代式视觉问答方法——该方法通过渐进式优化而非直接生成精确坐标的方式筛选抓取候选方案。在PIVOT框架的迭代优化策略基础上,研究人员重点实现了两项关键改进:(1)抓取引导提示机制,通过融入任务专属约束条件提升目标导向性;(2)物体感知采样策略,通过几何特征分析确保生成方案具备物理可行性。
研究人员提出的方法包括抓取时刻前W帧(默认设定W=10)获取的俯视视角2D观测图像![]() 。该早期帧能完整呈现物体几何特征,相较之下抓取时刻t(g)的特写镜头可能仅能捕捉局部信息。通过根据任务需求定制的提示模板,VLM生成稳定抓取配置的文本描述,该描述将作为后续迭代优化过程的先验知识。
。该早期帧能完整呈现物体几何特征,相较之下抓取时刻t(g)的特写镜头可能仅能捕捉局部信息。通过根据任务需求定制的提示模板,VLM生成稳定抓取配置的文本描述,该描述将作为后续迭代优化过程的先验知识。
为确保精准定位,研究人员采用LangSAM¹——该零样本文本-分割掩模框架融合了GroundingDINO和Segment Anything两大模型。此分割步骤通过生成目标物体的精确掩膜,将抓取建议限定在实际物体区域内,从而有效规避可能指向背景元素的虚影干扰。
抓取候选点的生成过程分为多轮迭代(如图3所示):首先沿物体轮廓进行初始采样(图中圆圈标记),视觉语言模型(VLM)评估这些采样点并筛选出具有稳定抓取潜力的优质候选点(红色圆圈标记);随后沿物体轮廓,以这些优质点为中心构建一维高斯分布进行二次采样生成新候选点。迭代次数T固定为4次,末轮迭代将确定最终抓取点。
视觉目标生成方法
本阶段基于输入观测数据集![]() 及抓取检测阶段(Grasp Detection)确定的接触点,通过多源数据融合合成目标抓取位姿图像
及抓取检测阶段(Grasp Detection)确定的接触点,通过多源数据融合合成目标抓取位姿图像。该图像精准呈现左右机械夹爪组件、目标物体及其空间位姿关系,构建出理想抓取状态的视觉表征,为后续动作生成提供可视化基准。
本阶段图像合成流程包含三个关键步骤:首先运用LaMa修复模型重建被遮挡的背景区域,生成完整背景基底;随后通过多层融合技术将修复后的背景、机械夹爪及经几何变换的前景物体组合成合成图像;最终依托抓取检测阶段提供的接触点信息,采用旋转平移等经典图像变换技术实现物体-夹爪精准位姿匹配。生成的视觉目标图像不仅真实呈现理想抓取状态,更为后续动作生成步骤奠定执行基准。
动作生成方法
为实现底层关节精准驱动,研究人员采用目标条件行为克隆(GCBC)框架。作为模仿学习的一种实现形式,行为克隆通过最小化预测动作与专家示范动作的偏差,训练智能体精确复现专家操作策略。本研究基于Walke等人的研究范式,采用去噪扩散概率模型(DDPM)实现该框架——该模型通过迭代优化,将高斯噪声分布逐步转化为数据生成分布。
GCBC策略模型πϕ由ResNet-34编码器与三层多层感知机(MLP)构成,模型参数由权重φ定义。由于观测图像采用自我中心俯视视角采集,我们通过将当前动作状态作为条件变量融入模型,有效增强了系统的空间感知能力。这一设计使得生成的控制指令能够与机器人当前运动轨迹实现无缝衔接,确保动作执行的连贯性。
DDPM的训练loss由下式定义:
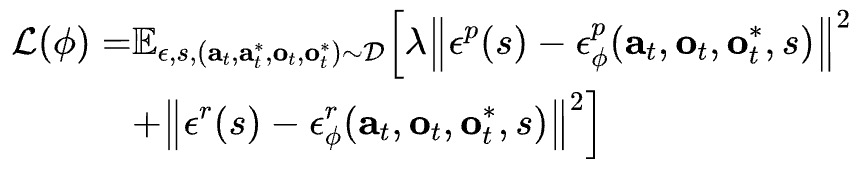
式中,s表示扩散时间步长,t代表抓取时刻t(g)。其中为观测图像,
为动作向量(如公式(1)所示),
是目标图像,
为专家示范动作。策略模型
通过预测位置噪声向量
与旋转噪声向量
,分别逼近与专家动作相关联的真实位置噪声项和旋转噪声项。加权超参数λ经实验验证设为0.2。损失函数L中的期望值计算涵盖动作a(包含平移分量
与旋转分量
)及噪声ϵ(包含位置噪声
和旋转噪声
)的联合分布。
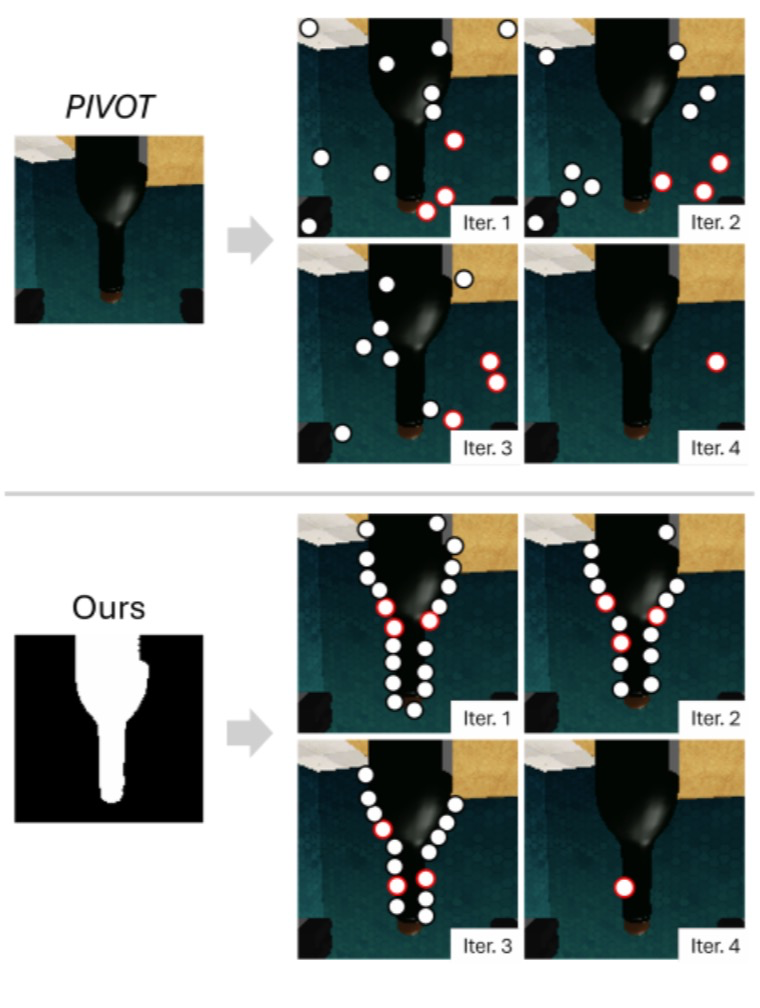
图片 3 迭代抓取点优化效果对比可视化:上图展示基于PIVOT框架的优化过程,下图呈现本方法改进方案。圆形标记代表各算法生成的候选抓取点,红色标记表示进入下一优化阶段的优选点。由于缺乏目标对象情境感知,PIVOT框架常生成无法实际接触物体的虚触点(如左图杯体边缘空触点);相较而言,本方法通过物理约束建模确保所有优选点均具备物理可实现性。考虑到左右夹爪在相机成像平面内的对称布局(如图1左所示),算法仅需在图像边界区域生成候选点即可满足抓取需求。
讨论
视觉语言模型与行为控制机制的互补性作用:改研究创新性地将视觉语言模型(VLM)的抓取检测能力与目标条件行为克隆(GCBC)的动作生成功能相结合,这一架构设计源于对VLM直接生成精确抓取动作存在固有局限性的深刻认知。视觉语言模型虽在场景语义解析与高层任务规划方面表现卓越,却难以满足具身操控所需的毫末级动作控制精度。因此,通过构建VLM-GCBC协同框架,实现了高层认知与底层执行的有机统一。
在初步实验中,研究人员发现直接基于当前观测数据、动作序列及任务描述,通过视觉语言模型(VLM)进行动作预测(a∈R^8)时,输出结果往往不切实际且违反物理规律。这一发现验证了我们的方案设计合理性——将操作流程分解为不同阶段:利用VLM进行环境感知与任务规划,同时依托专用GCBC模块实现精准控制,从而有效规避端到端模型存在的物理约束缺失问题。
基于图像的中间目标表示优势解析:GraspCorrect采用图像作为中间目标表征载体,这一设计决策基于多重优势考量。首先,视觉表征能完整保留抓取场景的空间语义与上下文信息,而这些信息在文本描述中往往存在信息损耗或表达歧义。例如空间位姿关系、物体朝向、抓取构型等关键操作特征,通过图像表征得以具体化、无歧义地编码。
其次,视觉语言模型经过海量视觉数据的预训练,在处理图像信息及视觉推理方面展现出显著优势。这种特性契合度使GraspCorrect的系统既能充分利用VLM的先进视觉认知能力,又能通过直观的视觉接口维持高层决策的可追溯性——在实现复杂空间推理的同时,维持高层决策的透明性与可解释性。
第三,近期机器人操控领域的研究突破(如SuSIE合成目标图像方法;GR-MG多模态生成框架)进一步验证了基于图像表征的技术路径的有效性。这些成功案例表明,视觉中间表征能有效桥接高层规划与底层执行,显著提升复杂操作任务的完成度。
但需注意的是,图像表征方式仍存在固有缺陷:其一,在应对动态遮挡场景时感知受限;其二,难以准确捕捉物体的动态物理属性(如弹性形变、摩擦系数等)。未来的研究可探索融合3D点云的空间拓扑信息与力反馈传感器的触觉数据,构建多模态目标表征体系。这种增强型表征方式将更全面刻画目标状态,为复杂物理交互任务提供更丰富的环境认知基础。
替代性视觉目标生成策略深度解析:理想的目标抓取位姿通常只需在预训练策略模型提供的当前位姿基础上进行微调。虽然快速扩展随机树等路径规划算法看似适用,但由于其需要精确的目标坐标——这在自中心机器人相机坐标系与机械臂本体坐标系存在映射偏差时难以准确获取——导致此类方法在本应用场景中实际不可行。
另一技术路径尝试结合视觉语言模型生成的抓取描述与图像生成/编辑扩散模型。我们在RLBench环境中测试了四类典型模型:DALL-E图像生成模型、SuSIE框架、DiffEdit编辑模型以及Imagic图像编辑模型。最终基于SuSIE方法论,采用专为操控任务优化的InstructPix2Pix调优版本。
如图4所示,这些模型存在显著缺陷:DALL-E生成的夹爪结构过度复杂且偏离真实设计;DiffEdit与SuSIE无法正确表征方块的目标朝向;Imagic甚至产生非真实的人手形态。相较之下,采用基础的图像融合技术反而能生成精确可靠的目标状态合成图像,该方法在保持目标物体结构完整性的同时,精准维持对操作成功率至关重要的空间位姿关系。

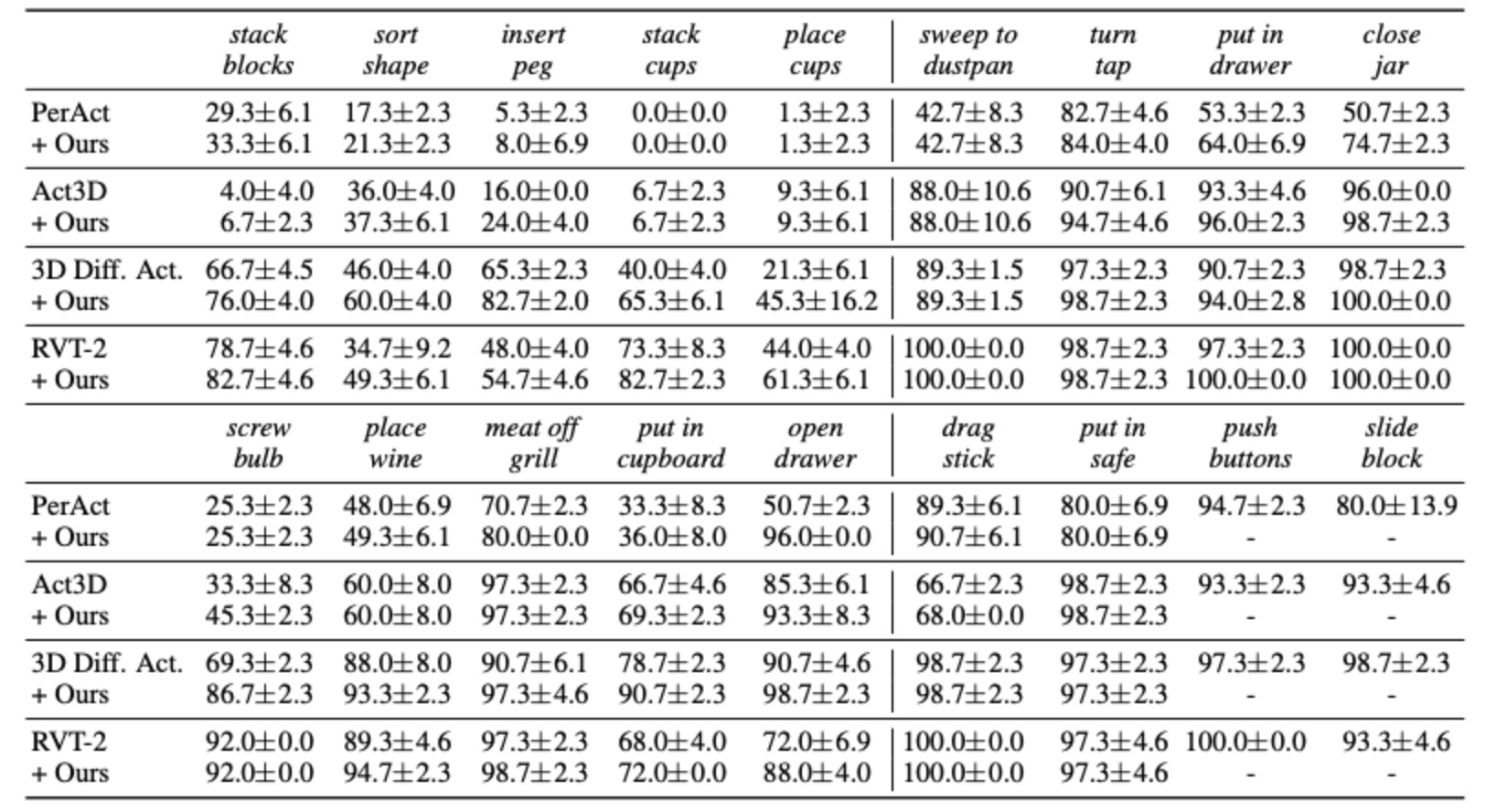
表格 1 基于RLBench数据集的18项操作任务性能评估:每个任务的所有测试案例中,目标物体的初始位姿(包括位置与朝向)均进行三次独立随机生成。最终性能指标通过以下方式计算:在每个任务内部,综合所有测试案例及随机物体摆放组合,计算得出平均任务成功率(%)±标准差。注:表格中短横线(-)表示该任务未涉及物体抓取操作,故GraspCorrect模块未激活。
结论
该研究提出了GraspCorrect——一种即插即用的增强型机器人操作模块,通过提供精准抓取引导机制有效提升现有策略模型的操控性能。该创新方案通过三重技术融合实现突破:首先,整合视觉语言模型(VLM)的语义理解能力;其次,借助目标条件行为克隆(GCBC)实现动作轨迹优化;最后,通过视觉目标生成技术建立操作闭环。这种"高层语义引导-底层动作优化"的协同架构,在RLBench与CALVIN基准测试的多样化操作任务中展现出显著优势。特别值得强调的是,GraspCorrect采用架构无关性设计,无需大规模模型重训练即可实现抓取优化,为机器人柔性部署提供了创新解决方案。