torch.nn 下的常用深度学习函数
1. 层(Layers)
这些函数用于定义神经网络中的各种层,是构建模型的基础模块。
-
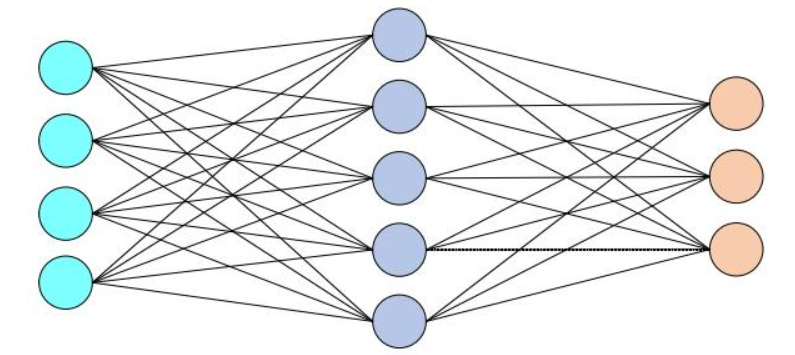
torch.nn.Linear-
用途:全连接层(也称为线性层)。用于将输入数据从一个维度映射到另一个维度,常用于神经网络的隐藏层和输出层。
-
示例:
torch.nn.Linear(in_features=10, out_features=5),将输入维度为10的数据映射到输出维度为5。
-
-
in_features:输入特征的数量,即输入张量的最后一个维度的大小。
-
out_features:输出特征的数量,即输出张量的最后一个维度的大小。
-
bias:可选参数,默认为
True。当设置为True时,会添加一个偏置项。
import torch
import torch.nn as nn# 创建一个线性层,输入特征数为 10,输出特征数为 5
linear_layer = nn.Linear(in_features=10, out_features=5)# 创建一个输入张量,形状为 (batch_size, in_features) = (3, 10)
input_tensor = torch.randn(3, 10)# 通过线性层进行前向传播
output_tensor = linear_layer(input_tensor)print("输入张量形状:", input_tensor.shape)
print("输出张量形状:", output_tensor.shape)输入张量形状: torch.Size([3, 10])
输出张量形状: torch.Size([3, 5])-
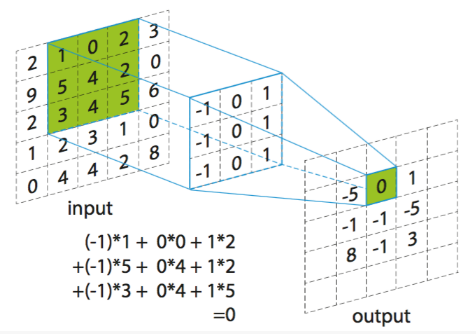
torch.nn.Conv2d-
用途:二维卷积层。用于处理二维数据(如图像),通过卷积核提取局部特征,常用于卷积神经网络(CNN)。
-
示例:
torch.nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3,stride=1,padding=0),输入通道数为3,输出通道数为16,卷积核大小为3×3。
-
-
-
in_channels:输入图像的通道数。
-
out_channels:卷积操作产生的通道数。
-
kernel_size:卷积核的大小,可以是一个整数或一个包含两个整数的元组。
-
stride:卷积操作的步长,默认为1。
-
padding:输入的每一边补充0的层数,默认为0。
-
dilation:卷积核元素之间的间距,默认为1。
-
groups:将输入分成的组数,默认为1。
-
bias:可选参数,默认为
True。当设置为True时,会添加一个偏置项。 -
padding_mode:填充模式,默认为
zeros。
-
import torch
import torch.nn as nn# 创建一个卷积层,输入通道数为 3,输出通道数为 16,卷积核大小为 3x3
conv_layer = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=1, padding=1)# 创建一个输入张量,形状为 (batch_size, in_channels, height, width) = (2, 3, 32, 32)
input_tensor = torch.randn(2, 3, 32, 32)# 通过卷积层进行前向传播
output_tensor = conv_layer(input_tensor)print("输入张量形状:", input_tensor.shape)
print("输出张量形状:", output_tensor.shape)输入张量形状: torch.Size([2, 3, 32, 32])
输出张量形状: torch.Size([2, 16, 32, 32])-
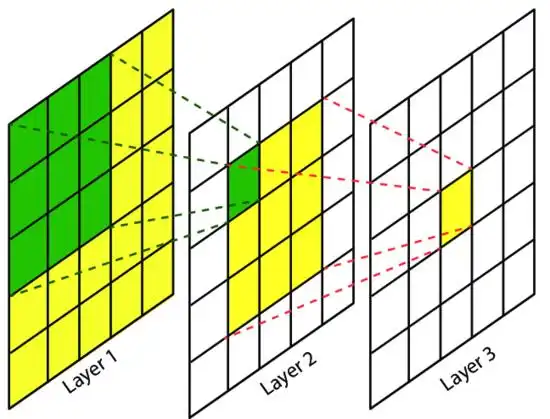
torch.nn.MaxPool2d-
用途:二维最大池化层。用于对特征图进行下采样,减少特征图的尺寸,同时保留重要特征。
-
示例:
torch.nn.MaxPool2d(kernel_size=2),使用2×2的池化窗口进行最大池化。
-
-
-
kernel_size:最大池化的窗口大小,可以是一个整数或一个包含两个整数的元组。
-
stride:窗口移动的步长,默认值是
kernel_size。 -
padding:输入的每一边补充0的层数,默认为0。
-
dilation:控制窗口中元素步幅的参数,默认为1。
-
return_indices:可选参数,默认为
False。当设置为True时,会返回输出最大值的索引。 -
ceil_mode:可选参数,默认为
False。当设置为True时,计算输出形状时会使用向上取整。
-
import torch
import torch.nn as nn# 创建一个最大池化层,窗口大小为 2x2,步长为 2
maxpool_layer = nn.MaxPool2d(kernel_size=2, stride=2)# 创建一个输入张量,形状为 (batch_size, channels, height, width) = (1, 16, 32, 32)
input_tensor = torch.randn(1, 16, 32, 32)# 通过最大池化层进行前向传播
output_tensor = maxpool_layer(input_tensor)print("输入张量形状:", input_tensor.shape)
print("输出张量形状:", output_tensor.shape)输入张量形状: torch.Size([1, 16, 32, 32])
输出张量形状: torch.Size([1, 16, 16, 16])-
torch.nn.BatchNorm2d-
用途:二维批量归一化层。用于对输入数据进行归一化,加速训练过程,提高模型的稳定性和性能。
-
示例:
torch.nn.BatchNorm2d(num_features=16),对16个通道的特征图进行批量归一化。
-
-
-
num_features:输入数据的通道数。
-
eps:分母中添加的一个值,用于计算的稳定性,默认为1e-5。
-
momentum:用于运行过程中均值和方差的估计参数,默认为0.1。
-
affine:可选参数,默认为
True。当设置为True时,此模块具有可学习的仿射参数。 -
track_running_stats:可选参数,默认为
True。当设置为True时,此模块跟踪运行平均值和方差。
-
import torch
import torch.nn as nn# 创建一个批量归一化层,输入通道数为 16
bn_layer = nn.BatchNorm2d(num_features=16)# 创建一个输入张量,形状为 (batch_size, channels, height, width) = (4, 16, 32, 32)
input_tensor = torch.randn(4, 16, 32, 32)# 通过批量归一化层进行前向传播
output_tensor = bn_layer(input_tensor)print("输入张量形状:", input_tensor.shape)
print("输出张量形状:", output_tensor.shape)输入张量形状: torch.Size([4, 16, 32, 32])
输出张量形状: torch.Size([4, 16, 32, 32])-
torch.nn.LSTM-
用途:长短期记忆网络(LSTM)层。用于处理序列数据,能够捕捉长期依赖关系,常用于自然语言处理和时间序列分析。
-
示例:
torch.nn.LSTM(input_size=10, hidden_size=20),输入维度为10,隐藏状态维度为20。
-
2. 激活函数(Activation Functions)
激活函数用于引入非线性,使神经网络能够学习复杂的模式。
-
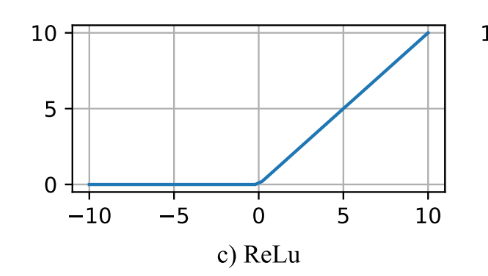
torch.nn.ReLU-
用途:修正线性单元(ReLU)。将所有负值置为0,保留正值,是最常用的激活函数之一,能够加速训练过程。
-
示例:
torch.nn.ReLU()。 -
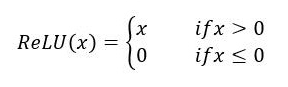
-
-
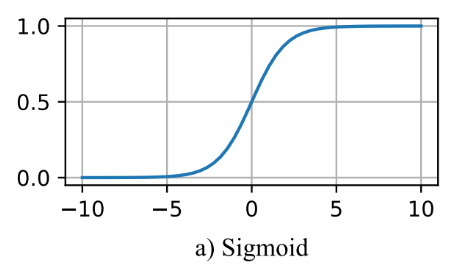
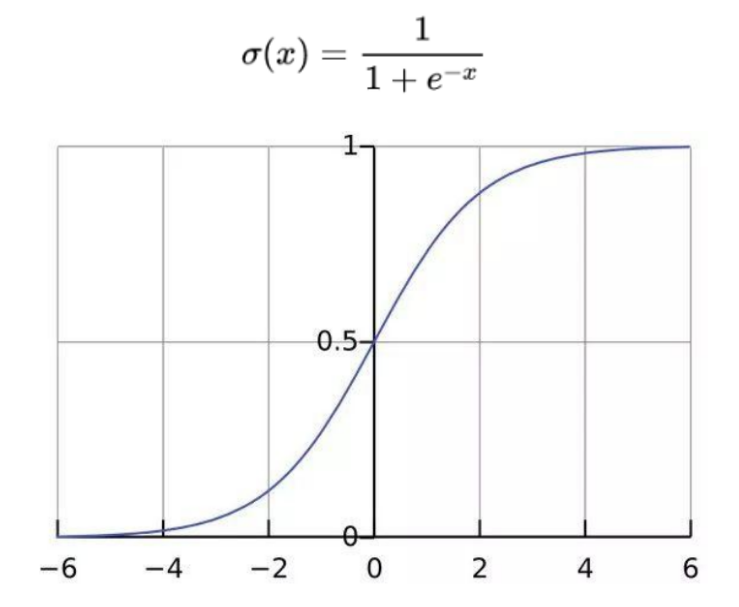
torch.nn.Sigmoid-
用途:Sigmoid 函数。将输入值映射到(0,1)区间,常用于二分类问题的输出层。
-
示例:
torch.nn.Sigmoid()。
-
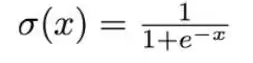
-
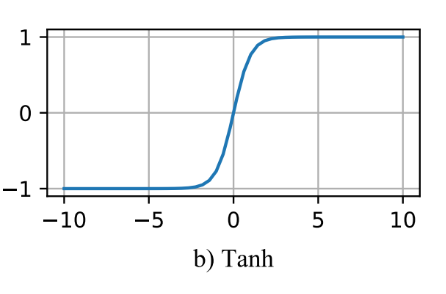
torch.nn.Tanh-
用途:双曲正切函数(Tanh)。将输入值映射到(-1,1)区间,与 Sigmoid 类似,但输出范围更宽。
-
示例:
torch.nn.Tanh()。
-
-
torch.nn.Softmax-
用途:Softmax 函数。将输入值归一化为概率分布,常用于多分类问题的输出层。
-
示例:
torch.nn.Softmax(dim=1),对输入张量的第1维进行Softmax归一化。
-
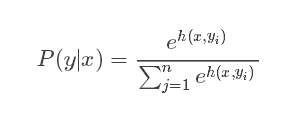
3. 损失函数(Loss Functions)
损失函数用于衡量模型预测值与真实值之间的差异,是训练模型时优化的目标。
- torch.nn.L1Loss
-
用途:L1范数损失函数。计算预测值与真实值之间的绝对值,它对异常值的敏感度较低,适用于回归问题。
-
-
示例:
torch.nn.L1Loss()。
-
import torch
import torch.nn as nn# 创建输入和目标张量
input = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
target = torch.tensor([1.5, 2.5, 3.5])# 初始化 L1Loss
criterion = nn.L1Loss()# 计算损失
loss = criterion(input, target)
print("L1 Loss:", loss.item()) # L1 Loss: 0.5-
torch.nn.MSELoss-
用途:均方误差损失函数。计算预测值与真实值之间的平方差的均值,常用于回归问题。
-
-
示例:
torch.nn.MSELoss()。
-
import torch
import torch.nn as nn# 创建输入和目标张量
input = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
target = torch.tensor([1.5, 2.5, 3.5])# 初始化 MSELoss
criterion = nn.MSELoss()# 计算损失
loss = criterion(input, target)
print("MSE Loss:", loss.item())-
torch.nn.CrossEntropyLoss-
用途:计算输入张量(logits)和目标张量之间的交叉熵损失。常用于多分类问题,输入张量通常是模型的输出,目标张量是类别索引。
-
-
其中:C 是类别数。
是真实标签的 one-hot 编码,即如果样本属于第 i 类,则
是模型预测的第 i 类的概率。
-
在 PyTorch 中,
torch.nn.CrossEntropyLoss的输入是:input:模型的原始输出,形状为 (N,C),其中 N 是样本数,C 是类别数。target:真实标签,形状为 (N),每个元素的值在 [0,C−1] 之间。 -
示例:
torch.nn.CrossEntropyLoss()。
-
import torch
import torch.nn as nn# 创建输入张量(logits)和目标张量
input = torch.tensor([[1.0, 2.0, 3.0], [1.0, 2.0, 3.0]], requires_grad=True) # logits
target = torch.tensor([1, 2]) # 类别索引# 初始化 CrossEntropyLoss
criterion = nn.CrossEntropyLoss()# 计算损失
loss = criterion(input, target)
print("CrossEntropy Loss:", loss.item())-
torch.nn.BCELoss-
用途:二元交叉熵损失函数。计算模型输出的Sigmoid分布与真实标签之间的二元交叉熵,常用于二分类问题。
-
-
是真实标签,取值为 0 或 1 ,
是模型预测的概率,取值在 (0,1) 之间。
-
在 PyTorch 中,
torch.nn.BCELoss的输入是input:模型的预测概率,形状为 (N)。target:真实标签,形状为 (N),每个元素的值为 0 或 1。 -
示例:
torch.nn.BCELoss()。
-
import torch
import torch.nn as nn# 创建输入张量(概率)和目标张量
input = torch.tensor([0.5, 0.3, 0.2], requires_grad=True)
target = torch.tensor([1.0, 0.0, 1.0])# 初始化 BCELoss
criterion = nn.BCELoss()# 计算损失
loss = criterion(torch.sigmoid(input), target)
print("BCE Loss:", loss.item())- torch.nn.KLDivLoss()
- 用途:计算输入张量和目标张量之间的 KL 散度。输入张量需要经过对数处理,目标张量是概率分布。
其中P是真实分布,Q是预测分布,i表示分布中的每个元素,在pytorch中表示为
- 示例:torch.nn.KLDivLoss()
import torch
import torch.nn as nn# 创建输入张量(对数概率)和目标张量(概率分布)
input = torch.tensor([[0.5, 0.3, 0.2], [0.2, 0.3, 0.5]], requires_grad=True).log()
target = torch.tensor([[0.4, 0.3, 0.3], [0.3, 0.3, 0.4]])# 初始化 KLDivLoss
criterion = nn.KLDivLoss(reduction='batchmean')# 计算损失
loss = criterion(input, target)
print("KL Div Loss:", loss.item())-
torch.nn.SmoothL1Loss()
-
用途:平滑版 L1 损失 (SmoothL1Loss),结合了 L1 损失和 L2 损失的优点,对小误差使用 L2 损失,对大误差使用 L1 损失。
-
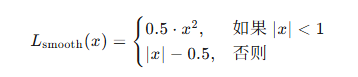
-
在 PyTorch 中,
torch.nn.SmoothL1Loss的公式可以表示为: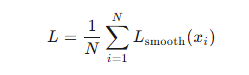
-
import torch
import torch.nn as nn# 创建输入张量和目标张量
input = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
target = torch.tensor([1.5, 2.5, 3.5])# 初始化 SmoothL1Loss
criterion = nn.SmoothL1Loss()# 计算损失
loss = criterion(input, target)
print("SmoothL1 Loss:", loss.item())4. 优化器(Optimizers)
优化器用于更新模型的参数,以最小化损失函数。
虽然优化器不是 torch.nn 模块的一部分,但它们与 torch.nn 模块紧密配合使用,因此也在这里列出。
-
torch.optim.SGD-
用途:随机梯度下降优化器。通过计算梯度来更新模型参数,是最基本的优化器之一。
-
示例:
torch.optim.SGD(model.parameters(), lr=0.01),学习率为0.01。
-
import torch
import torch.nn as nn
import torch.optim as optim# 定义一个简单的模型
model = nn.Linear(10, 2)# 初始化 SGD 优化器
optimizer = optim.SGD(model.parameters(), lr=0.01)# 模拟训练过程
for epoch in range(10):# 假设我们有一个损失函数loss_fn = nn.MSELoss()input = torch.randn(5, 10) # 随机生成输入数据target = torch.randn(5, 2) # 随机生成目标数据# 前向传播output = model(input)loss = loss_fn(output, target)# 反向传播optimizer.zero_grad() # 清除之前的梯度loss.backward() # 计算梯度# 更新参数optimizer.step()print(f"Epoch {epoch+1}, Loss: {loss.item()}")-
torch.optim.Adam-
用途:Adam优化器。结合了动量和自适应学习率的优点,是目前最常用的优化器之一。
-
示例:
torch.optim.Adam(model.parameters(), lr=0.001),学习率为0.001。
-
import torch
import torch.nn as nn
import torch.optim as optim# 定义一个简单的模型
model = nn.Linear(10, 2)# 初始化 Adam 优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)# 模拟训练过程
for epoch in range(10):# 假设我们有一个损失函数loss_fn = nn.MSELoss()input = torch.randn(5, 10) # 随机生成输入数据target = torch.randn(5, 2) # 随机生成目标数据# 前向传播output = model(input)loss = loss_fn(output, target)# 反向传播optimizer.zero_grad() # 清除之前的梯度loss.backward() # 计算梯度# 更新参数optimizer.step()print(f"Epoch {epoch+1}, Loss: {loss.item()}")5. 正则化(Regularization)
Dropout 的主要用途是在训练过程中随机丢弃一部分神经元的输出,从而减少模型对训练数据的过拟合。通过这种方式,模型在训练时会学习到更鲁棒的特征,提高其在测试数据上的泛化能力。
-
torch.nn.Dropout-
用途:Dropout层。在训练过程中随机丢弃一部分神经元,防止模型对训练数据过拟合。
-
示例:
torch.nn.Dropout(p=0.5),丢弃概率为0.5。
-
class SimpleModel(nn.Module):def __init__(self):super(SimpleModel, self).__init__()self.fc1 = nn.Linear(10, 5) # 输入维度为 10,输出维度为 5self.dropout = nn.Dropout(p=0.5) # Dropout 层,丢弃概率为 0.5self.fc2 = nn.Linear(5, 2) # 输入维度为 5,输出维度为 2def forward(self, x):x = self.fc1(x)x = torch.relu(x) # 使用 ReLU 激活函数x = self.dropout(x) # 应用 Dropoutx = self.fc2(x)return x6. 其他
-
torch.nn.Sequential-
用途:用于定义一个顺序模型,可以将多个层按顺序堆叠起来,简化模型的定义过程。
-
示例:
-
model = torch.nn.Sequential(torch.nn.Linear(10, 5),torch.nn.ReLU(),torch.nn.Linear(5, 2)
)